南京建设网站排名广告设计公司
深度解析BERT:从架构设计到实战应用
BERT(Bidirectional Encoder Representations from Transformers)自2018年提出以来,彻底改变了自然语言处理的技术范式。本文将从核心原理、架构细节、训练机制、代码实现到版本演进,全面解析这一里程碑模型。
一、BERT的核心突破
1. 双向语境建模
通过Masked Language Model(MLM) 和 Next Sentence Prediction(NSP) 的联合训练,首次实现了:
- 真正的双向语义理解(区别于传统单向模型)
- 上下文敏感的词向量表示
2. 预训练-微调范式
开创了"大规模无监督预训练+任务特定微调"的新范式,使模型能迁移至各类下游任务。
二、架构深度解析
1. 嵌入层(Embedding Layer)
输入由三部分动态融合:
Input = E t ⏟ 词嵌入 + P p ⏟ 位置嵌入 + S s ⏟ 段嵌入 \text{Input} = \underbrace{E_t}_{\text{词嵌入}} + \underbrace{P_p}_{\text{位置嵌入}} + \underbrace{S_s}_{\text{段嵌入}} Input=词嵌入 Et+位置嵌入 Pp+段嵌入 Ss
- 词嵌入:30,522维词表映射到768/1024维空间
- 位置嵌入:解决Transformer的无序性缺陷
- 段嵌入:区分句子对(如问答任务中的Q&A)
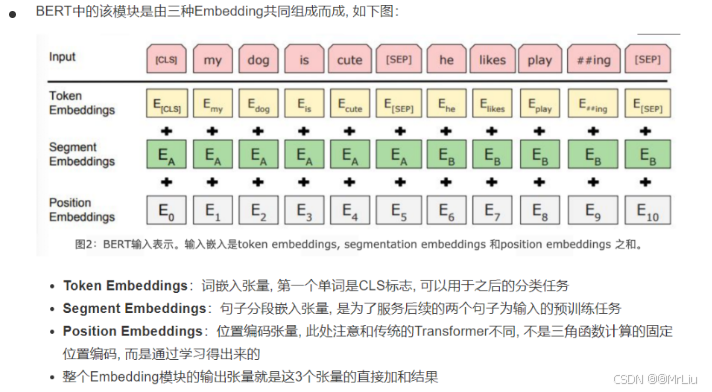
2. Transformer编码器
采用多层(12/24层)Transformer架构,每层包含:
(1) 多头自注意力(Multi-Head Attention)
Attention ( Q , K , V ) = softmax ( Q K ⊤ d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQK⊤)V
- 多头机制:12个并行注意力头,增强模型表达能力
- 计算优化:通过矩阵分解实现高效并行计算
(2) 前馈神经网络(FFN)
FFN ( x ) = GELU ( x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = \text{GELU}(xW_1 + b_1)W_2 + b_2 FFN(x)=GELU(xW1+b1)W2+b2
- 维度扩展:中间层维度达4倍隐藏层大小(3072/4096)
- 激活函数:使用GELU替代传统ReLU
3. 层归一化与残差连接
x out = LayerNorm ( x + Sublayer ( x ) ) x_{\text{out}} = \text{LayerNorm}(x + \text{Sublayer}(x)) xout=LayerNorm(x+Sublayer(x))
- 残差连接:缓解梯度消失,支持深层网络训练
- 层归一化:加速收敛,提升模型稳定性
三、预训练机制详解
1. MLM(Masked Language Model)
- 掩码策略:随机遮蔽15% token(80%→[MASK], 10%→随机词, 10%→保留原词)
- 损失函数:
L MLM = − ∑ m ∈ M log P ( w m ∣ context ) L_{\text{MLM}} = -\sum_{m \in M} \log P(w_m | \text{context}) LMLM=−m∈M∑logP(wm∣context)
2. NSP(Next Sentence Prediction)
- 任务目标:判断句子B是否为句子A的下一句
- 损失函数:
L NSP = − [ y log y ^ + ( 1 − y ) log ( 1 − y ^ ) ] L_{\text{NSP}} = -\left[ y \log \hat{y} + (1-y) \log(1-\hat{y}) \right] LNSP=−[ylogy^+(1−y)log(1−y^)]
3. 优化策略
- AdamW优化器:带权重衰减的自适应学习率
- 学习率调度:
η t = η base ⋅ min ( t − 0.5 , t ⋅ warmup − 1.5 ) \eta_t = \eta_{\text{base}} \cdot \min(t^{-0.5}, t \cdot \text{warmup}^{-1.5}) ηt=ηbase⋅min(t−0.5,t⋅warmup−1.5)
四、版本演进与对比
| 版本 | 层数 | 隐藏层 | 参数量 | 注意力头 | 适用场景 |
|---|---|---|---|---|---|
| BERT-Base | 12 | 768 | 110M | 12 | 常规任务 |
| BERT-Large | 24 | 1024 | 340M | 16 | 复杂任务(如机器阅读) |
| ALBERT | 12+ | 768 | 12M | 12 | 资源受限场景 |
| RoBERTa | 24 | 1024 | 355M | 16 | 高精度需求任务 |
| DistilBERT | 6 | 768 | 66M | 12 | 速度优先场景 |
关键改进点:
- ALBERT:参数共享 + 因子分解嵌入
- RoBERTa:动态掩码 + 更大训练数据
- DistilBERT:知识蒸馏技术
五、代码实现与应用示例
1. 文本分类任务(HuggingFace实现)
from transformers import BertTokenizer, BertForSequenceClassification
import torch# 加载预训练模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')# 输入处理
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
labels = torch.tensor([1]).unsqueeze(0) # 批次维度# 前向传播
outputs = model(**inputs, labels=labels)
loss = outputs.loss
logits = outputs.logitsprint(f"预测类别: {torch.argmax(logits).item()}")
2. 应用场景
- 文本分类:情感分析、垃圾邮件检测
- 序列标注:命名实体识别(NER)
- 问答系统:SQuAD数据集上的机器阅读理解
- 语义相似度:句子对匹配任务
六、架构图建议
输入层 → 词/位置/段嵌入 →
[Transformer层 ×N]
├─ 多头自注意力
└─ 前馈网络
→ 池化层 → 输出层
七、总结与展望
BERT的突破性在于:
- 双向语境建模:超越传统单向模型的语义理解能力
- 预训练范式:降低NLP任务门槛,提升模型泛化性
未来方向:
- 模型轻量化:如知识蒸馏(DistilBERT)
- 多模态融合:结合视觉、语音信息
- 持续学习:动态更新模型知识
附录:架构图建议使用Lucidchart绘制,可参考本文描述构建可视化示意图。