网站里的滚动怎么做中山网站建设公司
经典数仓架构深度解析与演进:从离线处理到新型架构对比
在数据驱动决策的时代,经典数仓作为企业数据管理与分析的核心基础设施,承载着从数据存储到价值挖掘的重要使命。本文将深入剖析经典数仓的架构、数据处理流程、主流架构模式及其对比,同时展望数仓的未来发展方向。
一、经典数仓的数据源与导入方式
经典数仓的数据源往往通过离线方式导入到关系型数据库中。这种方式适用于对数据实时性要求不高,但数据量庞大的场景,例如企业的历史订单数据、财务报表数据等。
1、常见的离线数据导入流程,会借助 ETL(Extract, Transform, Load)工具,如 Kettle、Informatica 等,将数据从文件系统、业务数据库等数据源抽取出来,经过清洗、转换后,最终加载到像 DB2、Sybase、Or
acle 样的关系型数据库中。
以 Kettle 工具为例,在一个简单的 CSV 文件数据导入到 Oracle 数据库的场景中,操作步骤如下:
在 Kettle 中创建一个新的转换任务。
使用 “文本文件输入” 组件读取 CSV 文件,配置好文件路径、分隔符等参数。
通过 “字段选择” 组件对数据进行格式转换和字段筛选。这利用 “表输出” 组件,配置好 Oracle 数据库的连接信息,将处理后的数据写入到对应的表中。
二、经典数仓的数据处理技术
2.1 关系型数据库的应用
经典数仓的数据处理主要依赖 DB2、Sybase、Oracle 等关系型数据库。这些数据库具备强大的事务管理和 SQL 查询能力,能够处理复杂的数据操作。
例如,在 Oracle 数据库中,使用 SQL 语句进行数据聚合查询:
SELECT product_id, SUM(sales_amount) AS total_sales
FROM sales_data
GROUP BY product_id;
上述 SQL 语句可以计算出每个产品的总销售额。
2.2 离线大数据架构的特点
随着数据量的爆发式增长,离线大数据架构逐渐成为经典数仓的重要组成部分。其特点在于数据源依旧以离线方式导入到离线数仓中,但数据处理采用了 MapReduce、Hive、SparkSQL、Impala 等离线计算引擎。
以 Hive 为例,它将 SQL 语句转换为 MapReduce 任务进行分布式计算,极大提升了大数据处理效率。比如,在 Hive 中执行如下查询:
SELECT year, month, COUNT(*) AS order_count
FROM orders
GROUP BY year, month;
该语句能够统计出每个月的订单数量,借助 Hive 的分布式计算能力,即使面对海量订单数据也能高效完成计算。
三、离线数仓分层架构
离线数仓通常采用分层架构设计,以提高数据管理和处理的效率,一般分为以下几个层次:
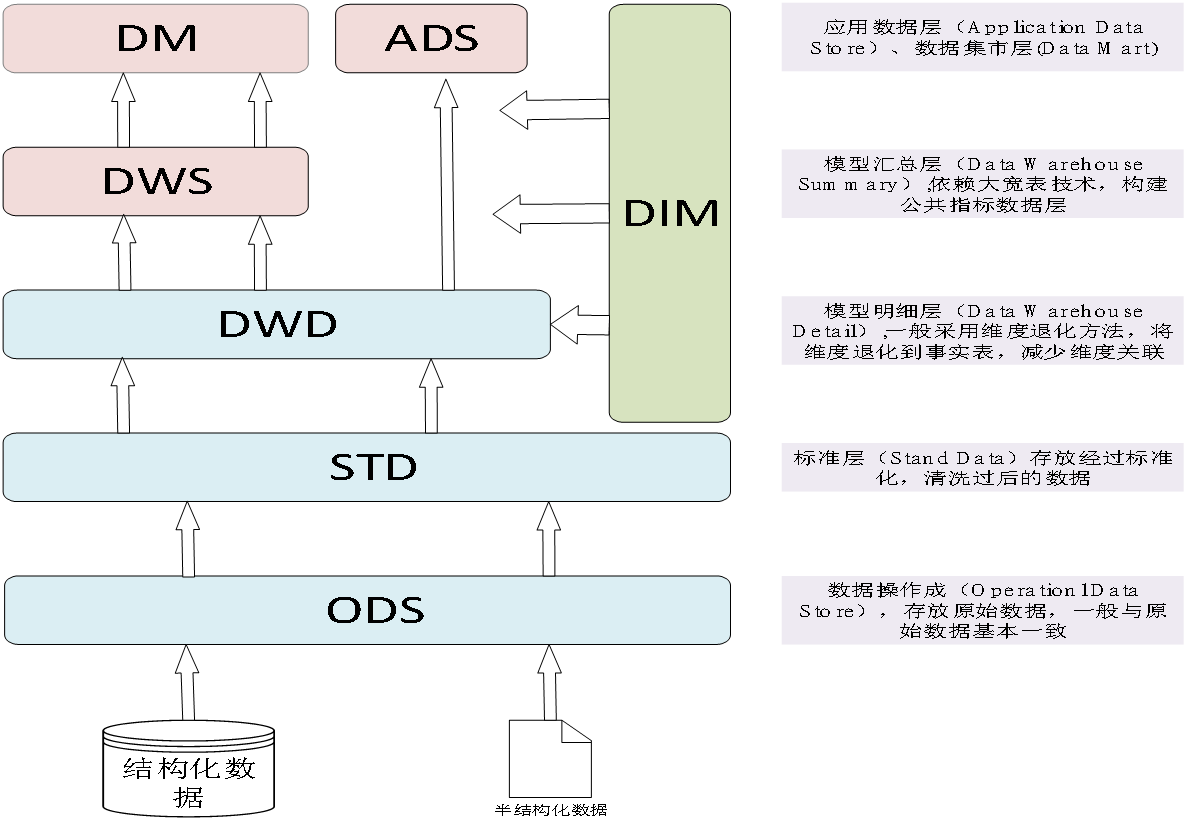
3.1 数据源层(ODS,Operational Data Store)
数据源层直接从业务系统抽取原始数据,保持数据的原貌,不做过多处理。它的作用类似于数据的临时存储区,为后续的数据清洗和转换提供原始数据基础。
3.2 数据仓库层(DW,Data Warehouse)
数据仓库层对 ODS 层的数据进行清洗、转换和集成。按照业务主题,如销售、库存、客户等,对数据进行重新组织和存储。这一层的数据是经过处理的、高质量的、面向分析的数据。
3.3 数据集市层(DM,Data Mart)
数据集市层是根据特定业务部门或主题的需求,从数据仓库层抽取数据构建而成。它是一种小型的、面向特定业务的数仓,能够快速响应业务部门的分析需求,例如财务数据集市、销售数据集市等。
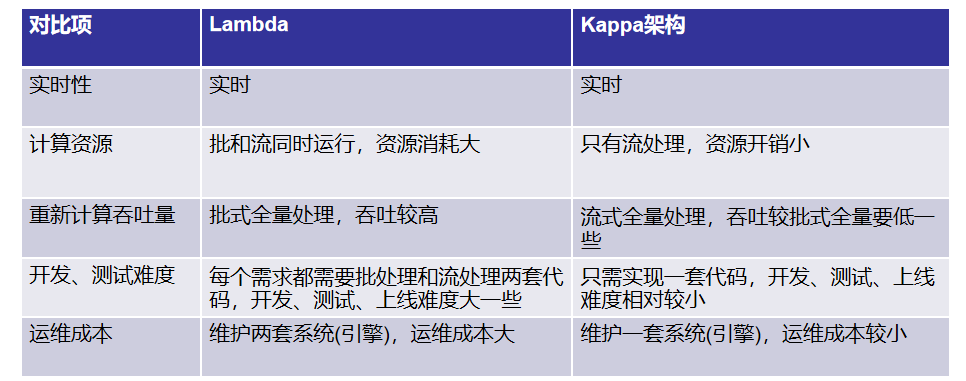
四、Lambda 架构
Lambda 架构由 Nathan Marz 提出,旨在解决大数据处理中实时性和准确性的平衡问题。它主要由以下三个部分组成:
4.1 批处理层(Batch Layer)
批处理层负责处理全量历史数据,使用 MapReduce、Hive 等离线计算引擎对数据进行批量处理,生成不可变的数据集。批处理层的优势在于能够保证数据的准确性,但处理数据存在一定的延迟。
4.2 速度层(Speed Layer)
速度层处理实时流入的数据,使用 Storm、Flink 等流处理引擎,以低延迟的方式对数据进行处理,生成近似的查询结果。速度层弥补了批处理层实时性不足的问题。
4.3 服务层(Serving Layer)
服务层将批处理层和速度层的结果进行整合,对外提供统一的查询接口。用户的查询请求会从服务层获取最终的结果,服务层会根据查询需求,选择合适的数据源返回数据。
五、Kappa 架构
Kappa 架构是对 Lambda 架构的改进,它取消了批处理和速度层的分离,所有数据均通过流处理管道写入数据湖。Kappa 架构的核心流程如下:
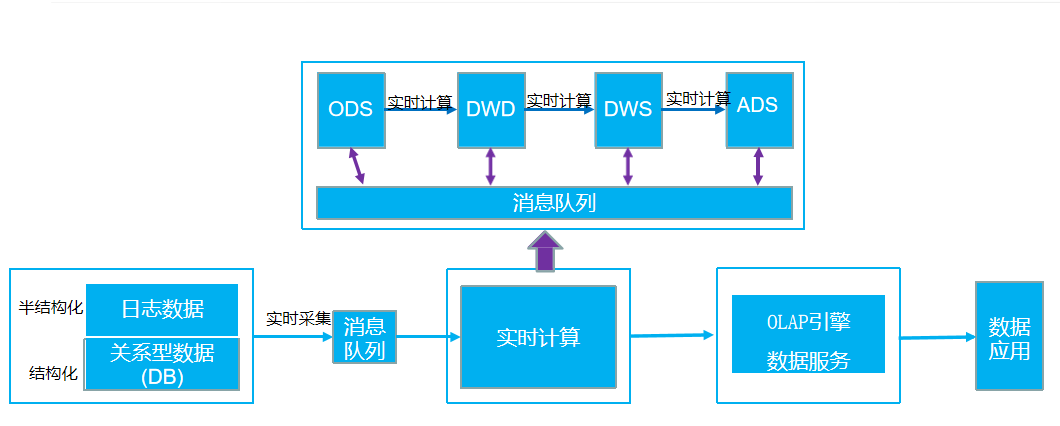
1、数据源的数据实时流入流处理引擎,如 Flink、Spark Streaming。
流处理引擎对数据进行实时处理,并将处理后的数据写入数据湖。
2、当需要重新处理历史数据时,通过重新消费数据湖中的数据,使用相同的流处理逻辑进行处理,从而避免了 Lambda 架构中批处理和流处理逻辑不一致的问题。
六、Lambda 架构与 Kappa 架构对比
七、未来数仓展望
随着技术的不断发展,数仓也在持续演进,未来数仓将呈现以下发展趋势:
7.1 智能化
结合人工智能和机器学习技术,实现自动化的数据管理、智能数据分析和预测,帮助企业更好地挖掘数据价值。
7.2 实时化
实时数仓将成为主流,满足企业对实时决策的需求,从数据产生到分析结果输出实现秒级响应。
7.3 云化
云数仓凭借其弹性扩展、低成本、高可用性等优势,将被越来越多的企业采用,成为数仓建设的重要方向。
总结
经典数仓从数据源的离线导入,到关系型数据库与离线计算引擎的数据处理,再到分层架构设计,以及 Lambda 和 Kappa 架构的不断演进,在企业数据管理和分析中发挥着关键作用。了解经典数仓的架构和技术,有助于我们把握数据处理的核心逻辑,同时也为探索未来数仓的发展提供了坚实的基础。
如果你在经典数仓的学习和实践过程中有任何问题或想法,欢迎在评论区留言交流!