保定网站优化最新域名查询
深度学习模型组件之优化器-自适应学习率优化方法(Adagrad、RMSprop)
文章目录
- 深度学习模型组件之优化器-自适应学习率优化方法(Adagrad、RMSprop)
- 1. 传统梯度下降的局限性
- 2. Adagrad(Adaptive Gradient Algorithm)
- 3. RMSprop(Root Mean Square Propagation)
- 4.总结
在深度学习模型的训练过程中,选择合适的优化算法对于模型的收敛速度和性能至关重要。 自适应学习率优化方法通过根据梯度信息动态调整学习率,能够更有效地处理稀疏数据和非平稳目标函数。本文将介绍两种常用的自适应学习率优化方法: Adagrad(Adaptive Gradient Algorithm)和RMSprop(Root Mean Square Propagation),并提供相应的代码示例。
1. 传统梯度下降的局限性
在传统的梯度下降算法中,所有参数共享相同的学习率。然而,在实际应用中,不同参数可能具有不同的频率和重要性,使用相同的学习率可能导致以下问题:
- 收敛速度慢:对于稀疏数据或不常更新的参数,固定的学习率可能导致收敛缓慢。
- 震荡:对于频繁更新的参数,固定的学习率可能导致在最优解附近震荡,难以收敛。
为了解决这些问题,自适应学习率优化方法应运而生。
2. Adagrad(Adaptive Gradient Algorithm)
基本原理:
Adagrad 通过对每个参数的梯度平方和进行累积,根据累积的梯度信息调整每个参数的学习率。其核心思想是:对频繁更新的参数降低学习率,对不常更新的参数提高学习率,从而适应稀疏数据的训练。
更新公式:
-
累积梯度平方和:
对于第
t次迭代,第i个参数的梯度平方和累积为: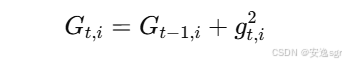
其中:
Gt,i表示第t次迭代时,第i个参数的梯度平方和;gt,i为第t次迭代时,第i个参数的梯度。
-
更新参数:
使用调整后的学习率更新参数:
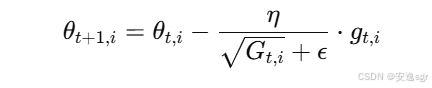
其中:
θt,i为第t次迭代时,第i个参数的值;η为全局学习率;ϵ为一个小常数,防止分母为零。
代码示例:
以下是使用 PyTorch 实现 Adagrad 优化器的示例代码:
import torch# 创建模型参数
params = [torch.tensor([1.0, 2.0], requires_grad=True)]# 创建 Adagrad 优化器
optimizer = torch.optim.Adagrad(params, lr=0.1)# 模拟一个损失函数
loss_fn = lambda: (params[0] ** 2).sum()# 进行一次优化步骤
optimizer.zero_grad()
loss = loss_fn()
loss.backward()
optimizer.step()
3. RMSprop(Root Mean Square Propagation)
基本原理:
RMSprop 通过引入梯度平方的指数加权移动平均,动态调整每个参数的学习率,以解决 Adagrad 中学习率持续下降的问题。其核心思想是:对每个参数的梯度平方进行指数加权移动平均,以此调整学习率,适应非平稳目标函数的优化。
更新公式:
-
计算梯度平方的指数加权移动平均:
对于第
t次迭代,第i个参数的梯度平方的指数加权移动平均计算如下:
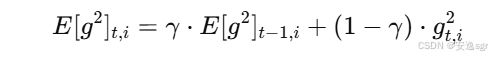
其中:
E[g2]t,i表示第t次迭代时,第i个参数的梯度平方的指数加权移动平均;γ为衰减率,通常取值在 0.9 左右;gt,i为第t次迭代时,第i个参数的梯度。
-
更新参数:
使用调整后的学习率更新参数:
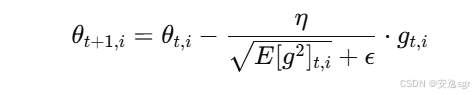
其中:
θt,i为第t次迭代时,第i个参数的值;η为全局学习率;ϵ为一个小常数,防止分母为零。
代码示例:
以下是使用 PyTorch 实现 RMSprop 优化器的示例代码:
import torch# 创建模型参数
params = [torch.tensor([1.0, 2.0], requires_grad=True)]# 创建 RMSprop 优化器
optimizer = torch.optim.RMSprop(params, lr=0.1, alpha=0.9)# 模拟一个损失函数
loss_fn = lambda: (params[0] ** 2).sum()# 进行一次优化步骤
optimizer.zero_grad()
loss = loss_fn()
loss.backward()
optimizer.step()
4.总结
| 优化器 | 核心思想 | 优点 | 适用场景 |
|---|---|---|---|
| SGD with Momentum | 在梯度下降过程中加入动量,减少震荡,加速收敛 | 加速收敛,减少震荡 | 通用优化,适用于大部分深度学习任务 |
| NAG | 在更新前进行梯度预测,减少震荡,提高优化效率 | 提高优化效率,减少不必要的震荡 | 适用于复杂优化问题,如 CNN |
| Adagrad | 自适应调整学习率,频繁更新的参数学习率较小,不常更新的参数学习率较大 | 对稀疏数据特别有效,自适应调整学习率 | 适用于稀疏数据,如 NLP 和推荐系统等 |
| RMSprop | 通过指数加权平滑梯度平方,避免 Adagrad 学习率持续下降的问题 | 学习率保持稳定,适合非平稳目标函数 | 适用于 RNN、时序数据等训练任务 |