微信小程序网站建设公司什么软件可以推广
遇到的问题:
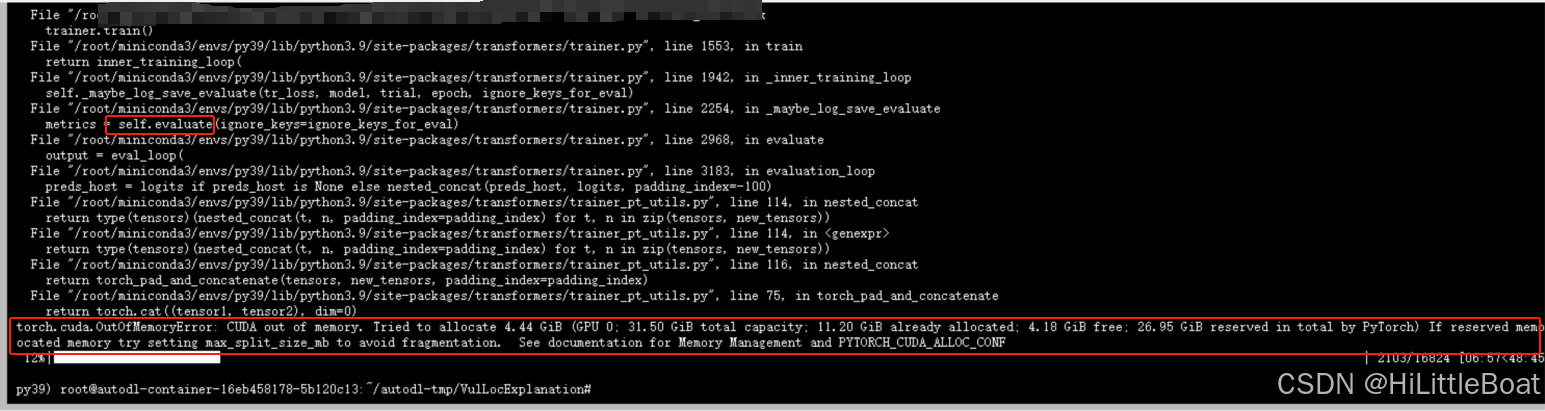
在使用hugging face封装的Trainer的时候,使用了自定义的compute_metric函数,但是会出现OOM的情况。
我的transformer版本是:
经过验证,发现哪怕compute_metrics里的内容写的再简单,只有一个print,也不行,根本就执行不到这个函数内部。才发现,原来不是这个东西的内部的问题。
原因:
经过探究发现,Trainer会把所有 logits、label都算好,拼在一起后,再从CUDA传到内存,然后,再给compute_metrics计算指标。这样导致需要特别大的内存。直接就报错了。
有一些解决思路是:
1. 调节per_device_eval_batch_size=1, eval_accumulation_steps 这俩参数来解决。
经过尝试,确实会好一点,但是速度非常慢,但是对于较大的验证集,还是不行,治标不治本。原理就是:
per_device_eval_batch_size 用来 设置验证的时候的batchsize,但是不能解决,拼接了很大的数据量的问题。
eval_accumulation_steps 是分步骤累积评估结果,减少显存峰值,可能对于 GPU的oom 会有点用吧。但是同样还是没有解决计算所有logits之后,拼接的问题。
training_args = TrainingArguments(# 其他的参数设置# .....# 这两个参数的使用per_device_eval_batch_size=1,eval_accumulation_steps=100)最优解:preprocess_logits_for_metrics 函数
使用 preprocess_logits_for_metrics 函数 ,这个函数就是用于在每个评估步骤中缓存 logits之前对其进行预处理。
使用方法如下,注意搭配的compute_metrics 可能需要进一步修改,因为,已经在preprocess_logits_for_metrics计算出来需要使用的东西了。
def compute_metrics(pred):labels_ids = pred.label_idspred_ids = pred.predictions[0]pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)labels_ids[labels_ids == -100] = tokenizer.pad_token_idlabel_str = tokenizer.batch_decode(labels_ids, skip_special_tokens=True)rouge_output = rouge.compute(predictions=pred_str,references=label_str,rouge_types=["rouge1", "rouge2", "rougeL", "rougeLsum"],)return {"R1": round(rouge_output["rouge1"], 4),"R2": round(rouge_output["rouge2"], 4),"RL": round(rouge_output["rougeL"], 4),"RLsum": round(rouge_output["rougeLsum"], 4),}def preprocess_logits_for_metrics(logits, labels):"""Original Trainer may have a memory leak. This is a workaround to avoid storing too many tensors that are not needed."""pred_ids = torch.argmax(logits[0], dim=-1)return pred_ids, labelstrainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=test_dataset,compute_metrics=compute_metrics,# 关键函数preprocess_logits_for_metrics=preprocess_logits_for_metrics
)
参考的:
https://discuss.huggingface.co/t/cuda-out-of-memory-when-using-trainer-with-compute-metrics/2941/13
https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Trainer.preprocess_logits_for_metrics