湖北分行建设银行网站网站流量分析报告
文章目录
- 1. 前言
- 2. ReputMessageService 简介
- 3. doReput 执行重放
- 4. checkMessageAndReturnSize 检查消息是否合法并返回消息大小
- 5. 计算消息长度 calMsgLength
- 6. rollNextFile 获取当前 offset 所在的 MappedFile 的下一个 MappedFile 的偏移量
- 7. 小结
本文章基于 RocketMQ 4.9.3
1. 前言
RocketMQ 存储部分系列文章:
- 【RocketMQ 存储】- RocketMQ存储类 MappedFile
- 【RocketMQ 存储】- 一文总结 RocketMQ 的存储结构-基础
- 【RocketMQ 存储】- broker 端存储单条消息的逻辑
- 【RocketMQ 存储】- broker 端存储批量消息的逻辑
- 【RocketMQ 存储】- 同步刷盘和异步刷盘
- 【RocketMQ 存储】- 同步刷盘服务 GroupCommitService
- 【RocketMQ 存储】- 异步刷盘服务 FlushRealTimeService
- 【RocketMQ 存储】- 异步提交服务 CommitRealTimeService
- 【RocketMQ 存储】RocketMQ 如何高效创建 MappedFile
2. ReputMessageService 简介
ReputMessageService 是 RocketMQ 中的消息重放服务,在这个服务中会为 ConsumeQueue、 IndexFile 构建索引,同时也会构建 构建 SQL92 布隆过滤器,加快消费者的消费性能,当然了我们这个系列的文章主要还是 RocketMQ 存储,所以主要讲解的还是 ConsumeQueue 和 IndexFile 索引的构建。
那当然了,既然需要进行消息重放,那么重放的就是 CommitLog,ReputMessageService 会每 1ms 重放一次消息,相当于不停进行消息重放了,重放的起点就是当前 CommitLog 的最小偏移量。
下面我们就看下这个服务里面的一些参数和方法。
首先就是这个类的定义,ReputMessageService 继承自 ServiceThread,也是一个线程任务类。
class ReputMessageService extends ServiceThread {...
}
ReputMessageService 中定义的一个参数是 reputFromOffset,就是重放服务的偏移量,意思就是重复到哪个位置了。我们来看下这个参数是怎么初始化的。
首先我们可以自己想一下,既然重放服务是用这个参数来构建 ConsumeQueue、 IndexFile 索引的,自然这个参数就不能小于 ConsumeQueue 里面的索引物理偏移量最大值(也就是在 CommitLog 中偏移量),超过了那不就重复重放了吗,IndexFile 和 ConsumeQueue 是一样的,因为是一起构建,且 RocketMQ 中使用了 consumeQueueTable 来存放了所有的 ConsumeQueue,只看 ConsumeQueue 就行。
/*** 1. Make sure the fast-forward messages to be truncated during the recovering according to the max physical offset of the commitlog;* 2. DLedger committedPos may be missing, so the maxPhysicalPosInLogicQueue maybe bigger that maxOffset returned by DLedgerCommitLog, just let it go;* 3. Calculate the reput offset according to the consume queue;* 4. Make sure the fall-behind messages to be dispatched before starting the commitlog, especially when the broker role are automatically changed.*/
long maxPhysicalPosInLogicQueue = commitLog.getMinOffset();
for (ConcurrentMap<Integer, ConsumeQueue> maps : this.consumeQueueTable.values()) {for (ConsumeQueue logic : maps.values()) {if (logic.getMaxPhysicOffset() > maxPhysicalPosInLogicQueue) {// 求出 ConsumeQueue 中的最大物理偏移量maxPhysicalPosInLogicQueue = logic.getMaxPhysicOffset();}}
}
这部分逻辑是在 DefaultMessageStore 这个服务被创建出来的时候就开始执行的。当然了,上面求出 ConsumeQueue 中索引的最大物理偏移量之后,如果这个最大偏移量比 commitLog 的最小偏移量都要小,那肯定是以 commitLog 为主了。
if (maxPhysicalPosInLogicQueue < 0) {maxPhysicalPosInLogicQueue = 0;
}
// 和 commitLog 的最小偏移量做比较
if (maxPhysicalPosInLogicQueue < this.commitLog.getMinOffset()) {maxPhysicalPosInLogicQueue = this.commitLog.getMinOffset();
}
当然,如果发生上面这种情况,有两种可能:
- 用户把 ConsumeQueue 文件删掉
- 当启动新的 Broker 并使用从其他 Broker 复制过来的 CommitLog 文件时,由于消费队列文件与 CommitLog 文件的关联可能会被破坏,就造成了 maxPhysicalPosInLogicQueue 比 commitLog 的最小偏移量要小。
这里就是初始化 reputFromOffset 的逻辑,那么下面我们就看下里面的 run 方法的逻辑。
3. doReput 执行重放
doReput 方法是该服务 run 方法里面的核心逻辑,和前面的几个线程服务一样都是如果没有停止就一直执行 doReput 重放,重放的时间间隔是 1ms。
@Override
public void run() {DefaultMessageStore.log.info(this.getServiceName() + " service started");while (!this.isStopped()) {try {Thread.sleep(1);this.doReput();} catch (Exception e) {DefaultMessageStore.log.warn(this.getServiceName() + " service has exception. ", e);}}DefaultMessageStore.log.info(this.getServiceName() + " service end");
}
doReput 方法就是对 CommitLog 里面的消息进行重放,这里就直接给出全部代码,然后下面再慢慢解析。
/*** 对 CommitLog 里面的数据执行重放*/
private void doReput() {// 如果 reputFromOffset 比 commitLog 的最小偏移量都要小if (this.reputFromOffset < DefaultMessageStore.this.commitLog.getMinOffset()) {log.warn("The reputFromOffset={} is smaller than minPyOffset={}, this usually indicate that the dispatch behind too much and the commitlog has expired.",this.reputFromOffset, DefaultMessageStore.this.commitLog.getMinOffset());// 这时候把 reputFromOffset 设置成 commitLog 的最小偏移量this.reputFromOffset = DefaultMessageStore.this.commitLog.getMinOffset();}// 开始进行重复,这里的条件是 reputFromOffset < commitLog 的最大偏移量 maxOffsetfor (boolean doNext = true; this.isCommitLogAvailable() && doNext; ) {// 如果允许重复重放(默认不允许),这里就是判断 reputFromOffset 是不是大于 confirmOffsetif (DefaultMessageStore.this.getMessageStoreConfig().isDuplicationEnable()&& this.reputFromOffset >= DefaultMessageStore.this.getConfirmOffset()) {break;}// 根据 reputFromOffset 获取这个 reputFromOffset 属于哪一个 MappedFile// 然后再根据 reputFromOffset % mappedFileSize 获取 reputFromOffset 的相对偏移量// 最后返回一个 SelectMappedBufferResult,这个 result 里面包装了从相对偏移量开始的一段 ByteBuffer// 所以这个方法其实就是: 根据 reputFromOffset 获取要重放的 ByteBufferSelectMappedBufferResult result = DefaultMessageStore.this.commitLog.getData(reputFromOffset);if (result != null) {try {// 将截取的 ByteBuffer 的起始偏移量设置为 reputFromOffsetthis.reputFromOffset = result.getStartOffset();// 开始读取这个 ByteBuffer 中的数据,进行重放for (int readSize = 0; readSize < result.getSize() && doNext; ) {// 首先校验这个 ByteBuffer 中的下一条消息的属性DispatchRequest dispatchRequest =DefaultMessageStore.this.commitLog.checkMessageAndReturnSize(result.getByteBuffer(), false, false);// Dledger 模式下 bufferSize 是 -1,这时候直接取消息大小,否则就获取 buffer 大小int size = dispatchRequest.getBufferSize() == -1 ? dispatchRequest.getMsgSize() : dispatchRequest.getBufferSize();// 判断下消息属性校验是否通过了if (dispatchRequest.isSuccess()) {// 这里表示消息属性校验通过了,如果有消息就可以进行分发if (size > 0) {// 分发请求// 1.CommitLogDispatcherBuildConsumeQueue 构建 ConsumeQueue 索引// 2.CommitLogDispatcherBuildIndex 构建 IndexFile 索引// 3.CommitLogDispatcherCalcBitMap 构建 SQL92 布隆过滤器DefaultMessageStore.this.doDispatch(dispatchRequest);// 当前 broker 是 master,同时支持长轮询以及设置了消息送达监听器if (BrokerRole.SLAVE != DefaultMessageStore.this.getMessageStoreConfig().getBrokerRole()&& DefaultMessageStore.this.brokerConfig.isLongPollingEnable()&& DefaultMessageStore.this.messageArrivingListener != null) {// 有新的消息被构建,就唤醒 messageArrivingListener 监听器去拉取消息,这里是消费者的逻辑了DefaultMessageStore.this.messageArrivingListener.arriving(dispatchRequest.getTopic(),dispatchRequest.getQueueId(), dispatchRequest.getConsumeQueueOffset() + 1,dispatchRequest.getTagsCode(), dispatchRequest.getStoreTimestamp(),dispatchRequest.getBitMap(), dispatchRequest.getPropertiesMap());// 设置了多个消息队列,遍历这些队列,拉取消息notifyMessageArrive4MultiQueue(dispatchRequest);}// 消息重放过后,重放的偏移量加上消息大小this.reputFromOffset += size;// 读取的消息大小加上消息大小readSize += size;// 如果是 slave 节点,记录下一些最新的统计数据if (DefaultMessageStore.this.getMessageStoreConfig().getBrokerRole() == BrokerRole.SLAVE) {DefaultMessageStore.this.storeStatsService.getSinglePutMessageTopicTimesTotal(dispatchRequest.getTopic()).add(1);DefaultMessageStore.this.storeStatsService.getSinglePutMessageTopicSizeTotal(dispatchRequest.getTopic()).add(dispatchRequest.getMsgSize());}} else if (size == 0) {// 读到文件结尾了,获取下一个文件的起始索引this.reputFromOffset = DefaultMessageStore.this.commitLog.rollNextFile(this.reputFromOffset);// readSize 设置成获取的 byteBuffer 的大小,这样下次就会退出循环了,其实这里可以直接 break 吧readSize = result.getSize();}} else if (!dispatchRequest.isSuccess()) {// 消息校验不通过消息只是消息头记录的长度和实际求出来的真实长度不一样if (size > 0) {// 可以忽略本条消息,继续往后面跟构建log.error("[BUG]read total count not equals msg total size. reputFromOffset={}", reputFromOffset);// 直接加上消息大小,表示跳过这条消息的重放this.reputFromOffset += size;} else {// size < 0 表示 比较严重的情况doNext = false;// dledger 模式是 RocketMQ 的一种高可用性模式,通过 Raft 协议保证数据的一致性和可靠性。如果启用了 dledger 模式,系统会更加严格地处理错误,不会忽略异常// 如果当前 broker 节点是主节点,也会严格处理错误,因为主节点负责写入数据,任何错误都需要被记录和处理if (DefaultMessageStore.this.getMessageStoreConfig().isEnableDLegerCommitLog() ||DefaultMessageStore.this.brokerConfig.getBrokerId() == MixAll.MASTER_ID) {log.error("[BUG]dispatch message to consume queue error, COMMITLOG OFFSET: {}",this.reputFromOffset);// readSize 就是已经重放过的消息字节数// result.getSize() 是总共需要重放的消息字节数// 这里意思就是让 reputFromOffset 加上剩下没有重放的字节,意思就是当前的 MappedFile 都跳过重放this.reputFromOffset += result.getSize() - readSize;}}}}} finally {// 重放完后释放 reputFromOffset 对应的 MappedFile 资源result.release();}} else {// 这里就是没找到下一个 MappedFile 了doNext = false;}}
}
这个方法里面首先处理下 reputFromOffset,还是和 commitLog 的 getMinOffset 做比较并进行校正。
// 如果 reputFromOffset 比 commitLog 的最小偏移量都要小
if (this.reputFromOffset < DefaultMessageStore.this.commitLog.getMinOffset()) {log.warn("The reputFromOffset={} is smaller than minPyOffset={}, this usually indicate that the dispatch behind too much and the commitlog has expired.",this.reputFromOffset, DefaultMessageStore.this.commitLog.getMinOffset());// 这时候把 reputFromOffset 设置成 commitLog 的最小偏移量this.reputFromOffset = DefaultMessageStore.this.commitLog.getMinOffset();
}
下面就开始在 for 循环里面进行重放,来看下 for 循环的条件。
// 开始进行重放,这里的条件是 reputFromOffset < commitLog 的最大偏移量 maxOffset
for (boolean doNext = true; this.isCommitLogAvailable() && doNext; ) {...
}
isCommitLogAvailable 就是判断当前还有没有消息需要重放,比较的逻辑就是用 reputFromOffset 和 commitLog 里面的 maxOffset 进行比较,这个 getMaxOffset 是一个方法,主要通过 MappedFileQueue#getMaxOffset 来得到,下面来看下里面的逻辑。
public long getMaxOffset() {// 获取最后一个 MappedFileMappedFile mappedFile = getLastMappedFile();if (mappedFile != null) {// 获取这个文件的起始偏移量 + ByteBuffer 中最大的有效偏移量return mappedFile.getFileFromOffset() + mappedFile.getReadPosition();}return 0;
}
关键就是 mappedFile.getFileFromOffset() + mappedFile.getReadPosition(),fileFromOffset 就是 CommitLog 文件的名字,readPosition 里面返回的是当前 MappedFile 提交到 Page Cache 的最大偏移量,加起来就是 CommitLog 的最大偏移量。
继续回到 doReput 方法,继续看里面 for 循环的内容。
// 如果允许重复重放(默认不允许),这里就是判断 reputFromOffset 是不是大于 confirmOffset
if (DefaultMessageStore.this.getMessageStoreConfig().isDuplicationEnable()&& this.reputFromOffset >= DefaultMessageStore.this.getConfirmOffset()) {break;
}
上面的方法就是在判断是否允许重复重放,如果允许就判断下这个 reputFromOffset 如果超过了 confirmOffset 就直接退出不重放。这个 confirmOffset 在 4.9.3 版本没有明确的设置,也就是 set 方法没有明确调用,但是在 5.x 的版本这个 confirmOffset 会被更新为有效消息的最大物理偏移量,在当前版本初始值是 -1,所以这里是会成立的。而在 5.x 版本上面这个逻辑也从 doReput 中删掉了,可能有其他用途,不过这里我们还是先以 4.9.3 为主,后面再慢慢过渡到 5.x。
// 根据 reputFromOffset 获取这个 reputFromOffset 属于哪一个 MappedFile
// 然后再根据 reputFromOffset % mappedFileSize 获取 reputFromOffset 的相对偏移量
// 最后返回一个 SelectMappedBufferResult,这个 result 里面包装了从相对偏移量开始的一段 ByteBuffer
// 所以这个方法其实就是: 根据 reputFromOffset 获取要重放的 ByteBuffer(一个文件)
SelectMappedBufferResult result = DefaultMessageStore.this.commitLog.getData(reputFromOffset);
接着看上面的逻辑,主要根据 reputFromOffset 获取这个 reputFromOffset 属于哪一个 MappedFile,接着再根据 reputFromOffset % mappedFileSize 获取 reputFromOffset 的相对偏移量,最后返回一个 SelectMappedBufferResult,这个 result 里面包装了从相对偏移量开始到这个 MappedFile 结尾的一段 ByteBuffer,所以这个方法其实就是: 根据 reputFromOffset 获取要重放的 ByteBuffer(MappedFile 要么写满,要么没写满)。
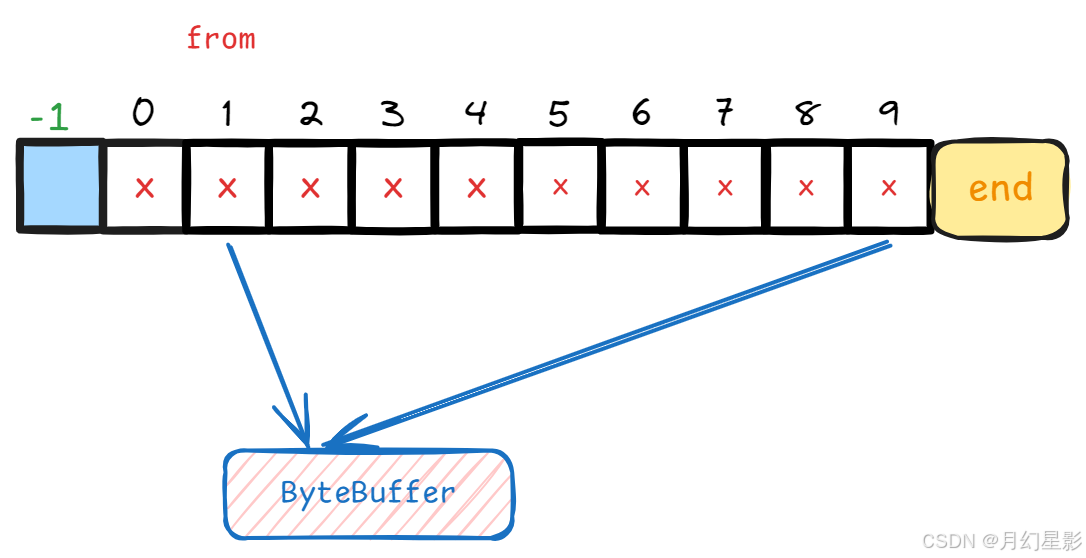
那接下来就判断下这个 result 是不是空,也就是说还有没有数据要重放。
if (result != null) {try{...} finally {// 重放完后释放 reputFromOffset 对应的 MappedFile 资源result.release();}
} else {// 这里就是没找到下一个 MappedFile 了doNext = false;
}
上面如果没找到要重放的数据,那就说明已经重放到最新位置了,不需要再重放了,这时候就可以退出 for 循环。否则就走 if 里面的重放逻辑,也就是剩余全部代码都在这个 if 里面,在 if 中使用 try-finally 来释放资源。
当然这里的释放资源不是说直接删掉这个 MappedFile 了,而是会释放这个 result 对 MappedFile 的引用。
在获取 result 的时候,也就是 DefaultMessageStore.this.commitLog.getData(reputFromOffset) 方法,在这个方法的底层 MappedFile#selectMappedBuffer 方法中会通过 this.hold() 持有当前 MappedFile 文件资源,所以要在 finally 里面释放资源。所谓的释放资源,就是讲文件被持有数 -1,同时判断要不要释放这个 MappedFile 背后的堆外内存。
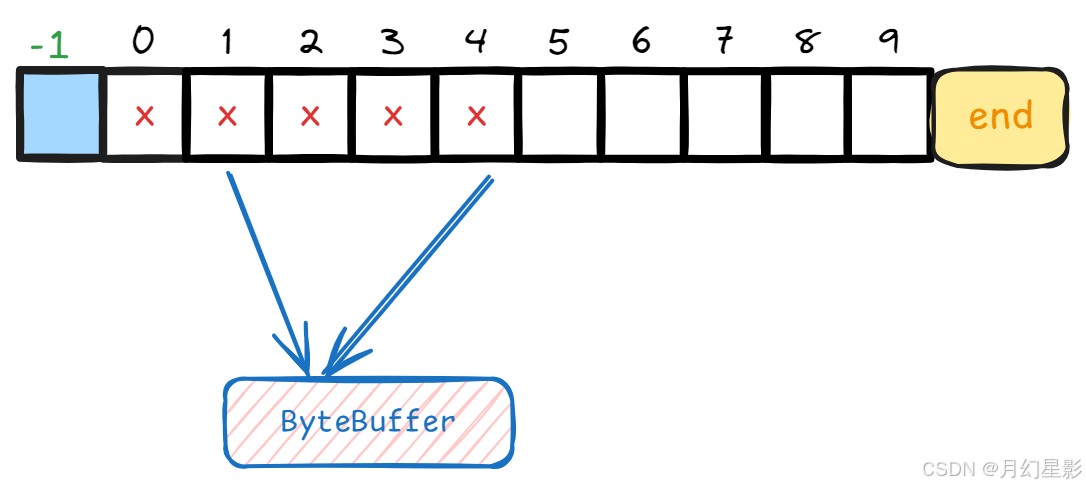
好了,继续来看下 try 里面的逻辑,首先就是在一个 for 循环里面一条一条消息处理,我们知道 result 是获取从 reputFromOffset 开始的一段 ByteBuffer,这个 ByteBuffer 里面可能包括多条消息,所以需要在 for 循环里面处理。
但是在处理 for 循环之前,我们会重新设置下 reputFromOffset 为 ByteBuffer 的起始偏移量。
// 将截取的 ByteBuffer 的起始偏移量设置为 reputFromOffset
this.reputFromOffset = result.getStartOffset();// 开始读取这个 ByteBuffer 中的数据,进行重放
for (int readSize = 0; readSize < result.getSize() && doNext; ) {...
}
在 for 循环中,首先校验这个 ByteBuffer 中的下一条消息的属性是否合法,这里我们后面再解析。
// 首先校验这个 ByteBuffer 中的下一条消息的属性
DispatchRequest dispatchRequest =DefaultMessageStore.this.commitLog.checkMessageAndReturnSize(result.getByteBuffer(), false, false);
然后获取消息的大小,这里 BufferSize 在 Dledger 模式下不是 -1,Dledger 模式是 RocketMQ 引入的一种高可用解决方案,主要用于解决主从模式下主节点单点故障的问题。我们这里默认就是 -1,所以返回的是消息 Msg 的大小 msgSize。
int size = dispatchRequest.getBufferSize() == -1 ? dispatchRequest.getMsgSize() : dispatchRequest.getBufferSize();
如果属性校验通过了,就说明有可能有消息可以分发。
// 判断下消息属性校验是否通过了
if (dispatchRequest.isSuccess()) {...
}
在 if 中的判断如下,如果消息大小大于 0,说明有消息可以进行分发。通过 DefaultMessageStore.this.doDispatch(dispatchRequest) 进行消息的分发,分发完成之后如果当前 broker 是 master,同时支持长轮询以及设置了消息送达监听器,那么就唤醒 messageArrivingListener 监听器去拉取消息,这里是消费者的逻辑了,我们这里不赘述。
最后当消息重放完了,将 reputFromOffset 的大小加上消息大小 size,最后判断如果是 slave 节点,记录下一些最新的统计数据。
// 这里表示消息属性校验通过了,如果有消息就可以进行分发
if (size > 0) {// 分发请求// 1.CommitLogDispatcherBuildConsumeQueue 构建 ConsumeQueue 索引// 2.CommitLogDispatcherBuildIndex 构建 IndexFile 索引// 3.CommitLogDispatcherCalcBitMap 构建 SQL92 布隆过滤器DefaultMessageStore.this.doDispatch(dispatchRequest);// 当前 broker 是 master,同时支持长轮询以及设置了消息送达监听器if (BrokerRole.SLAVE != DefaultMessageStore.this.getMessageStoreConfig().getBrokerRole()&& DefaultMessageStore.this.brokerConfig.isLongPollingEnable()&& DefaultMessageStore.this.messageArrivingListener != null) {// 有新的消息被构建,就唤醒 messageArrivingListener 监听器去拉取消息,这里是消费者的逻辑了DefaultMessageStore.this.messageArrivingListener.arriving(dispatchRequest.getTopic(),dispatchRequest.getQueueId(), dispatchRequest.getConsumeQueueOffset() + 1,dispatchRequest.getTagsCode(), dispatchRequest.getStoreTimestamp(),dispatchRequest.getBitMap(), dispatchRequest.getPropertiesMap());// 设置了多个消息队列,遍历这些队列,拉取消息notifyMessageArrive4MultiQueue(dispatchRequest);}// 消息重放过后,重放的偏移量加上消息大小this.reputFromOffset += size;// 读取的消息大小加上消息大小readSize += size;// 如果是 slave 节点,记录下一些最新的统计数据if (DefaultMessageStore.this.getMessageStoreConfig().getBrokerRole() == BrokerRole.SLAVE) {DefaultMessageStore.this.storeStatsService.getSinglePutMessageTopicTimesTotal(dispatchRequest.getTopic()).add(1);DefaultMessageStore.this.storeStatsService.getSinglePutMessageTopicSizeTotal(dispatchRequest.getTopic()).add(dispatchRequest.getMsgSize());
}
那如果 size == 0,就说明读到这个文件的尾部了,这时候获取下一个文件的起始索引。
else if (size == 0) {// 读到文件结尾了,获取下一个文件的起始索引this.reputFromOffset = DefaultMessageStore.this.commitLog.rollNextFile(this.reputFromOffset);// readSize 设置成获取的 byteBuffer 的大小,这样下次就会退出循环了,其实这里可以直接 break 吧readSize = result.getSize();
}
上面是消息校验成功的情况,那么如果消息校验不成功呢就需要判断如果上面获取的 size > 0 就表示情况没有那么严重,比如在 checkMessageAndReturnSize 中消息头记录的长度和实际求出来的真实长度不一样,这种情况下直接跳过这条消息继续构建下去。
但是如果说消息头记录的 magic code 非法,又或者说消息体被篡改过了,这种情况下 size 就是 -1,也就是比较严重的情况,直接设置 doNext = false 停止重放。当然由于 checkMessageAndReturnSize 传入的 checkCRC 和 readBody 都是 false,所以这里并不会校验 CRC,也就是消息体是否被篡改了。
同时会判断下失败的情况下,如果启用了 Dledger 默认或者当前 broker 节点是主节点,也会严格处理错误,因为主节点负责写入数据,任何错误都需要被记录和处理。这种情况下就会直接跳过当前 MappedFile 的重放了。就是设置 this.reputFromOffset += result.getSize() - readSize。
else if (!dispatchRequest.isSuccess()) {// 消息校验不通过,下面大于 0 就表示没有那么严重,比如只是消息头记录的长度和实际求出来的真实长度不一样if (size > 0) {log.error("[BUG]read total count not equals msg total size. reputFromOffset={}", reputFromOffset);// 直接加上消息大小,表示跳过这条消息的重放this.reputFromOffset += size;} else {// size < 0 表示比较严重的错误,不需要往下走了doNext = false;// dledger 模式是 RocketMQ 的一种高可用性模式,通过 Raft 协议保证数据的一致性和可靠性。如果启用了 dledger 模式,系统会更加严格地处理错误,不会忽略异常// 如果当前 broker 节点是主节点,也会严格处理错误,因为主节点负责写入数据,任何错误都需要被记录和处理if (DefaultMessageStore.this.getMessageStoreConfig().isEnableDLegerCommitLog() ||DefaultMessageStore.this.brokerConfig.getBrokerId() == MixAll.MASTER_ID) {log.error("[BUG]dispatch message to consume queue error, COMMITLOG OFFSET: {}",this.reputFromOffset);// readSize 就是已经重放过的消息字节数// result.getSize() 是总共需要重放的消息字节数// 这里意思就是让 reputFromOffset 加上剩下没有重放的字节,意思就是当前的 MappedFile 都跳过重放this.reputFromOffset += result.getSize() - readSize;}}
}
好了,这里就是全部的重复逻辑了,当然这里只是外层逻辑,具体每个文件的重放我们会在后面两篇文章去讲解。
4. checkMessageAndReturnSize 检查消息是否合法并返回消息大小
这个方法就是 doReput 方法中用于校验一条消息是否合法的,并且最后会返回这条消息的大小。
/*** 检查消息是否合法** @return 0 Come the end of the file // >0 Normal messages // -1 Message checksum failure*/
public DispatchRequest checkMessageAndReturnSize(java.nio.ByteBuffer byteBuffer, final boolean checkCRC,final boolean readBody) {try{...} catch (Exception e) {}return new DispatchRequest(-1, false /* success */);
}
外层调用的时候传入的参数 byteBuffer 就是获取到要重放的消息 Buffer,同时 checkCRC 设置为 false,readBody 也设置为 false。所以这个方法并不会去校验消息体是否被篡改过。如果在校验的过程发生了异常,就会返回 -1。
不知道大家还记得 CommitLog 单条消息的结构吗,不记得没关系,下面我把之前文章给出的结构粘贴过来。
| msg length(4 字节) | magicCode(4 字节) | body crc(4 字节) | queueId(4字节) | msg flag(4 字节) |
|---|---|---|---|---|
| 总长度 | 魔数,用于判断是不是空消息 | 消息体CRC校验码,用于校验消息传输的过程是否有错 | 队列 ID | 消息 flag |
| queue offset(8 字节) | physical offset(8 字节) | sys flag(4 字节) | born timestamp(8 字节) | |
| 消息在 ConsumeQueue 中的偏移量(实际要 * 20) | 消息在 CommitLog 中的物理偏移量 | 消息状态,如压缩、事务的各个阶段等 | 消息生成时间(时间戳) | |
| born host(8 字节) | store timestamp(8 字节) | store host(8 字节) | consume times(4 字节) | |
| 消息生成的 Producer 端地址 | 消息在 Broker 存储的时间戳 | Broker 端的地址 | 消息重试次数 | |
| prepared transaction offset(8 字节) | msg body(4 + body.length) | msg topic(1 + topic) | msg properties(2 + properties) | |
| prepared 状态的事务消息偏移量 | 消息体长度 + 消息体 | topic 长度和 topic 内容 | 消息属性长度 + 属性内容 |
那么我们来看下 try 里面的逻辑,首先就是获取消息的 总长度。就是 4 个字节的 int 类型。
// 1.消息总长度
int totalSize = byteBuffer.getInt();
然后就是获取 4 个字节的魔术,就是 magicCode,这个 magicCode 可以用来判断一条消息是正常消息还是空消息,如果是一条空消息,当然就是会返回 size = 0 的 DispatchRequest 了 ,除了这两种其他的状态就是错误非法状态了,这时候会返回 -1 表示严重错误。
// 2.魔数,用来判断是不是空消息
int magicCode = byteBuffer.getInt();
switch (magicCode) {case MESSAGE_MAGIC_CODE:// 正常消息break;case BLANK_MAGIC_CODE:// 空消息,读到文件尾部了return new DispatchRequest(0, true /* success */);default:// 这里就是错误情况了log.warn("found a illegal magic code 0x" + Integer.toHexString(magicCode));return new DispatchRequest(-1, false /* success */);
}
下面创建一个 bytesContent 数组,这个数组你可以理解为是一个辅助数组,就是用来辅助获取各种不定长数据,比如 broker 地址、producer 地址、消息体、topic、属性…
byte[] bytesContent = new byte[totalSize];
接着按照上面的表格依次获取下面的属性,我就不一一说了,大家直接看注解。
// 消息体 CRC 校验码,用于校验消息传输的过程是否有错
int bodyCRC = byteBuffer.getInt();// 消息队列 ID
int queueId = byteBuffer.getInt();// 消息 flag
int flag = byteBuffer.getInt();// 消息在 ConsumeQueue 中的偏移量(实际要 * 20)
long queueOffset = byteBuffer.getLong();// 消息在 CommitLog 中的物理偏移量
long physicOffset = byteBuffer.getLong();// 消息状态,如压缩、事务的各个阶段等
int sysFlag = byteBuffer.getInt();// 消息生成时间(时间戳)
long bornTimeStamp = byteBuffer.getLong();
看上面表格,接下来就轮到消息生成的 Producer 端地址了 (IP + 端口),大家知道 IPV4 和 IPV6 所生成的地址字节数是不一样的,那么如何判断是哪一个呢?就需要依靠 sysFlag 来判断,这个字段我在文章 - 【RocketMQ 存储】- 一文总结 RocketMQ 的存储结构-基础 有解析过,这里不多说。
下面获取消息生成的 Producer 端地址和端口号,写入上面的临时 bytesContent。
// 消息生成的 Producer 端地址和端口号
ByteBuffer byteBuffer1;
if ((sysFlag & MessageSysFlag.BORNHOST_V6_FLAG) == 0) {// IPV4 就是读取 4 个字节byteBuffer1 = byteBuffer.get(bytesContent, 0, 4 + 4);
} else {// IPV6 就是读取 16 个字节byteBuffer1 = byteBuffer.get(bytesContent, 0, 16 + 4);
}
继续往下读取,下面就是读取消息在 Broker 存储的时间戳,以及存储的地址和端口号。
// 消息在 Broker 存储的时间戳
long storeTimestamp = byteBuffer.getLong();// 存储的 Broker 端的地址和端口号
ByteBuffer byteBuffer2;
if ((sysFlag & MessageSysFlag.STOREHOSTADDRESS_V6_FLAG) == 0) {// IPV4 就是读取 4 个字节byteBuffer2 = byteBuffer.get(bytesContent, 0, 4 + 4);
} else {// IPV6 就是读取 4 个字节byteBuffer2 = byteBuffer.get(bytesContent, 0, 16 + 4);
}
这里没看懂为什么要用 bytesContent 存储这些信息,而且还是覆盖的,大家如果有知道的可以评论交流下。
继续往下读取,获取消息重试次数和事务消息物理偏移量。
// 消息重试次数
int reconsumeTimes = byteBuffer.getInt();// prepared 状态的事务消息物理偏移量
long preparedTransactionOffset = byteBuffer.getLong();
下面获取消息长度,同时读取消息到 bytesContent 中,然后判断要不要进行 CRC 校验,如果需要就进行校验,当校验失败直接返回 -1,外层会跳过当前 MappedFile 剩下的消息的重构。
// 消息长度
int bodyLen = byteBuffer.getInt();
if (bodyLen > 0) {// 是否需要读取具体消息内容if (readBody) {// 读取消息内容到 bytesContent 数组中byteBuffer.get(bytesContent, 0, bodyLen);// 如果要校验消息内容if (checkCRC) {// 根据消息体生产 CRC 校验码int crc = UtilAll.crc32(bytesContent, 0, bodyLen);// 如果生成的校验码和原来的校验码不一样,说明消息有可能被篡改了,不正确if (crc != bodyCRC) {log.warn("CRC check failed. bodyCRC={}, currentCRC={}", crc, bodyCRC);return new DispatchRequest(-1, false/* success */);}}} else {// 这里就是不需要读取消息内容,直接重新设置 positionbyteBuffer.position(byteBuffer.position() + bodyLen);}
}
接着继续处理 topic,将 topic 写入 bytesContent 中。
// topic 长度
byte topicLen = byteBuffer.get();
// topic 内容
byteBuffer.get(bytesContent, 0, topicLen);
// 这里就是消息是哪个 topic 的
String topic = new String(bytesContent, 0, topicLen, MessageDecoder.CHARSET_UTF8);
然后就是处理消息属性,下面这一段代码都是在处理属性,比如属性里面的 tagsCode,普通消息的 tagsCode 就是消息的 hashCode,如果是延时消息就是延时消息的发送时间,所以这里就是处理这部分内容,至于处理来干嘛,是作为返回结果的一部分的。
long tagsCode = 0;
String keys = "";
String uniqKey = null;// 消息属性大小
short propertiesLength = byteBuffer.getShort();
Map<String, String> propertiesMap = null;
if (propertiesLength > 0) {// 消息属性具体内容byteBuffer.get(bytesContent, 0, propertiesLength);String properties = new String(bytesContent, 0, propertiesLength, MessageDecoder.CHARSET_UTF8);// 转化成 mappropertiesMap = MessageDecoder.string2messageProperties(properties);// KEYS是一个消息属性,用于标识消息的唯一键,由调用者可以自己设置keys = propertiesMap.get(MessageConst.PROPERTY_KEYS);// 客户端生成的唯一ID,也就是消息ID,也可以作为消息的唯一标识uniqKey = propertiesMap.get(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX);// 消息 tagsString tags = propertiesMap.get(MessageConst.PROPERTY_TAGS);if (tags != null && tags.length() > 0) {// 普通消息就是消息的 hashCodetagsCode = MessageExtBrokerInner.tagsString2tagsCode(MessageExt.parseTopicFilterType(sysFlag), tags);}// 延时消息的 tagsCode 就是延时消息的发送时间{// 获取消息的延时等级,不同的延时等级就是不同的延时时间String t = propertiesMap.get(MessageConst.PROPERTY_DELAY_TIME_LEVEL);// SCHEDULE_TOPIC_XXXX 就是延时消息的 topicif (TopicValidator.RMQ_SYS_SCHEDULE_TOPIC.equals(topic) && t != null) {// 获取延时等级int delayLevel = Integer.parseInt(t);// 不能超过最大延时等级if (delayLevel > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) {delayLevel = this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel();}// 如果设置了延时级别if (delayLevel > 0) {// 将 tagsCode 设置成实际投递时间,具体逻辑就是将存储时间 + 延时级别对应的时间tagsCode = this.defaultMessageStore.getScheduleMessageService().computeDeliverTimestamp(delayLevel,storeTimestamp);}}}
}
到这里,所有需要动态计算的长度 sysFlag,bodyLen,topicLen,propertiesLength 已经获取到了,这时候就可以计算消息长度了。
// 根据读取的消息来还原消息的长度
int readLength = calMsgLength(sysFlag, bodyLen, topicLen, propertiesLength);
最后就是判断计算处理的消息长度和记录的长度是否一致,不一致就记录 BUG,返回结果,但是这里不会设置为 -1,外层并不会直接跳出当前 MappedFile 的重放,而是只会跳过当前这条消息的重放。
// 将上面真实的长度和消息头中记录的长度做比较
if (totalSize != readLength) {// 不相同就记录 BUGdoNothingForDeadCode(reconsumeTimes);doNothingForDeadCode(flag);doNothingForDeadCode(bornTimeStamp);doNothingForDeadCode(byteBuffer1);doNothingForDeadCode(byteBuffer2);log.error("[BUG]read total count not equals msg total size. totalSize={}, readTotalCount={}, bodyLen={}, topicLen={}, propertiesLength={}",totalSize, readLength, bodyLen, topicLen, propertiesLength);return new DispatchRequest(totalSize, false/* success */);
}
否则最后就是正常的返回结果了。
// 根据读取的消息属性内容,构建 DispatchRequest 返回结果
return new DispatchRequest(topic,queueId,physicOffset,totalSize,tagsCode,storeTimestamp,queueOffset,keys,uniqKey,sysFlag,preparedTransactionOffset,propertiesMap
);
下面就是所有的代码。
/*** 检查消息是否合法** @return 0 Come the end of the file // >0 Normal messages // -1 Message checksum failure*/
public DispatchRequest checkMessageAndReturnSize(java.nio.ByteBuffer byteBuffer, final boolean checkCRC,final boolean readBody) {try {// 1.消息总长度int totalSize = byteBuffer.getInt();// 2.魔数,用来判断是不是空消息int magicCode = byteBuffer.getInt();switch (magicCode) {case MESSAGE_MAGIC_CODE:// 正常消息break;case BLANK_MAGIC_CODE:// 空消息,读到文件尾部了return new DispatchRequest(0, true /* success */);default:// 这里就是错误情况了log.warn("found a illegal magic code 0x" + Integer.toHexString(magicCode));return new DispatchRequest(-1, false /* success */);}byte[] bytesContent = new byte[totalSize];// 消息体 CRC 校验码,用于校验消息传输的过程是否有错int bodyCRC = byteBuffer.getInt();// 消息队列 IDint queueId = byteBuffer.getInt();// 消息 flagint flag = byteBuffer.getInt();// 消息在 ConsumeQueue 中的偏移量(实际要 * 20)long queueOffset = byteBuffer.getLong();// 消息在 CommitLog 中的物理偏移量long physicOffset = byteBuffer.getLong();// 消息状态,如压缩、事务的各个阶段等int sysFlag = byteBuffer.getInt();// 消息生成时间(时间戳)long bornTimeStamp = byteBuffer.getLong();// 消息生成的 Producer 端地址和端口号ByteBuffer byteBuffer1;if ((sysFlag & MessageSysFlag.BORNHOST_V6_FLAG) == 0) {// IPV4 就是读取 4 个字节byteBuffer1 = byteBuffer.get(bytesContent, 0, 4 + 4);} else {// IPV6 就是读取 16 个字节byteBuffer1 = byteBuffer.get(bytesContent, 0, 16 + 4);}// 消息在 Broker 存储的时间戳long storeTimestamp = byteBuffer.getLong();// 存储的 Broker 端的地址和端口号ByteBuffer byteBuffer2;if ((sysFlag & MessageSysFlag.STOREHOSTADDRESS_V6_FLAG) == 0) {// IPV4 就是读取 4 个字节byteBuffer2 = byteBuffer.get(bytesContent, 0, 4 + 4);} else {// IPV6 就是读取 4 个字节byteBuffer2 = byteBuffer.get(bytesContent, 0, 16 + 4);}// 消息重试次数int reconsumeTimes = byteBuffer.getInt();// prepared 状态的事务消息物理偏移量long preparedTransactionOffset = byteBuffer.getLong();// 消息长度int bodyLen = byteBuffer.getInt();if (bodyLen > 0) {// 是否需要读取具体消息内容if (readBody) {// 读取消息内容到 bytesContent 数组中byteBuffer.get(bytesContent, 0, bodyLen);// 如果要校验消息内容if (checkCRC) {// 根据消息体生产 CRC 校验码int crc = UtilAll.crc32(bytesContent, 0, bodyLen);// 如果生成的校验码和原来的校验码不一样,说明消息有可能被篡改了,不正确if (crc != bodyCRC) {log.warn("CRC check failed. bodyCRC={}, currentCRC={}", crc, bodyCRC);return new DispatchRequest(-1, false/* success */);}}} else {// 这里就是不需要读取消息内容,直接重新设置 positionbyteBuffer.position(byteBuffer.position() + bodyLen);}}// topic 长度byte topicLen = byteBuffer.get();// topic 内容byteBuffer.get(bytesContent, 0, topicLen);// 这里就是消息是哪个 topic 的String topic = new String(bytesContent, 0, topicLen, MessageDecoder.CHARSET_UTF8);long tagsCode = 0;String keys = "";String uniqKey = null;// 消息属性大小short propertiesLength = byteBuffer.getShort();Map<String, String> propertiesMap = null;if (propertiesLength > 0) {// 消息属性具体内容byteBuffer.get(bytesContent, 0, propertiesLength);String properties = new String(bytesContent, 0, propertiesLength, MessageDecoder.CHARSET_UTF8);// 转化成 mappropertiesMap = MessageDecoder.string2messageProperties(properties);// KEYS是一个消息属性,用于标识消息的唯一键,由调用者可以自己设置keys = propertiesMap.get(MessageConst.PROPERTY_KEYS);// 客户端生成的唯一ID,也就是消息ID,也可以作为消息的唯一标识uniqKey = propertiesMap.get(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX);// 消息 tagsString tags = propertiesMap.get(MessageConst.PROPERTY_TAGS);if (tags != null && tags.length() > 0) {// 普通消息就是消息的 hashCodetagsCode = MessageExtBrokerInner.tagsString2tagsCode(MessageExt.parseTopicFilterType(sysFlag), tags);}// 延时消息的 tagsCode 就是延时消息的发送时间{// 获取消息的延时等级,不同的延时等级就是不同的延时时间String t = propertiesMap.get(MessageConst.PROPERTY_DELAY_TIME_LEVEL);// SCHEDULE_TOPIC_XXXX 就是延时消息的 topicif (TopicValidator.RMQ_SYS_SCHEDULE_TOPIC.equals(topic) && t != null) {// 获取延时等级int delayLevel = Integer.parseInt(t);// 不能超过最大延时等级if (delayLevel > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) {delayLevel = this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel();}// 如果设置了延时级别if (delayLevel > 0) {// 将 tagsCode 设置成实际投递时间,具体逻辑就是将存储时间 + 延时级别对应的时间tagsCode = this.defaultMessageStore.getScheduleMessageService().computeDeliverTimestamp(delayLevel,storeTimestamp);}}}}// 根据读取的消息来还原消息的长度int readLength = calMsgLength(sysFlag, bodyLen, topicLen, propertiesLength);// 将上面真实的长度和消息头中记录的长度做比较if (totalSize != readLength) {// 不相同就记录 BUGdoNothingForDeadCode(reconsumeTimes);doNothingForDeadCode(flag);doNothingForDeadCode(bornTimeStamp);doNothingForDeadCode(byteBuffer1);doNothingForDeadCode(byteBuffer2);log.error("[BUG]read total count not equals msg total size. totalSize={}, readTotalCount={}, bodyLen={}, topicLen={}, propertiesLength={}",totalSize, readLength, bodyLen, topicLen, propertiesLength);return new DispatchRequest(totalSize, false/* success */);}// 根据读取的消息属性内容,构建 DispatchRequest 返回结果return new DispatchRequest(topic,queueId,physicOffset,totalSize,tagsCode,storeTimestamp,queueOffset,keys,uniqKey,sysFlag,preparedTransactionOffset,propertiesMap);} catch (Exception e) {}return new DispatchRequest(-1, false /* success */);
}
5. 计算消息长度 calMsgLength
这个方法就是根据传入的几个非定长的属性长度来计算消息长度,这里方法不难,注释说得很清楚了,所以直接看代码就行。
/*** 计算消息长度* @param sysFlag 是否是 IPV6* @param bodyLength 消息体长度* @param topicLength topic 长度* @param propertiesLength 消息属性长度* @return*/
protected static int calMsgLength(int sysFlag, int bodyLength, int topicLength, int propertiesLength) {// 如果是 IPV6 就是 20,否则是 8,这是因为 bornhost 是包括 IP + port 的,所以会多上 4 字节int bornhostLength = (sysFlag & MessageSysFlag.BORNHOST_V6_FLAG) == 0 ? 8 : 20;// 这里也是同理int storehostAddressLength = (sysFlag & MessageSysFlag.STOREHOSTADDRESS_V6_FLAG) == 0 ? 8 : 20;// 计算一条 CommitLog 消息的长度final int msgLen = 4 //TOTALSIZE+ 4 //MAGICCODE+ 4 //BODYCRC+ 4 //QUEUEID+ 4 //FLAG+ 8 //QUEUEOFFSET+ 8 //PHYSICALOFFSET+ 4 //SYSFLAG+ 8 //BORNTIMESTAMP+ bornhostLength //BORNHOST+ 8 //STORETIMESTAMP+ storehostAddressLength //STOREHOSTADDRESS+ 4 //RECONSUMETIMES+ 8 //Prepared Transaction Offset+ 4 + (bodyLength > 0 ? bodyLength : 0) //BODY+ 1 + topicLength //TOPIC+ 2 + (propertiesLength > 0 ? propertiesLength : 0) //propertiesLength+ 0;return msgLen;
}
6. rollNextFile 获取当前 offset 所在的 MappedFile 的下一个 MappedFile 的偏移量
这个方法注释里面也写得很详细,下面我就再给个例子,大家就知道这个偏移量是怎么算的了。
假设现在 MappedFile 文件大小是 1024,那么 MappedFile1 的范围是 [0, 1024),MappedFile2 的范围是 [1024, 2048),现在 offset 是 500,位于第一个 MappedFile 中。
- offset + mappedFileSize = 1524
- offset % mappedFileSize = 500
- offset + mappedFileSize - offset % mappedFileSize = 1024
/*** 获取当前 offset 所在的 MappedFile 的下一个 MappedFile 的偏移量* @param offset* @return*/
public long rollNextFile(final long offset) {// MappedFile 文件大小int mappedFileSize = this.defaultMessageStore.getMessageStoreConfig().getMappedFileSizeCommitLog();// 假设现在 MappedFile 文件大小是 1024,那么 MappedFile1 的范围是 [0, 1024),MappedFile2 的范围是 [1024, 2048)// 现在 offset 是 500,位于// 1.offset + mappedFileSize = 1524// 2.offset % mappedFileSize = 500// 3.offset + mappedFileSize - offset % mappedFileSize = 1024// 1024 就是下一个 MappedFile 的起始偏移量return offset + mappedFileSize - offset % mappedFileSize;
}
7. 小结
好了,这篇文章就写到这里了,我们讲解了 RocketMQ 的消息重放服务,那么从下一篇文章开始我们就会去解析 IndexFile 和 ConsumeQueue 的索引构建。
如有错误,欢迎指出!!!