html网站模板 淘宝商城国产长尾关键词拘挖掘
华为云Flexus+DeepSeek征文|基于Dify构建解析网页写入Notion笔记工作流
- 一、构建解析网页写入Notion笔记工作流引言
- 二、构建解析网页写入Notion笔记工作流环境
- 2.1 基于FlexusX实例的Dify平台
- 2.2 基于MaaS的模型API商用服务
- 三、构建解析网页写入Notion笔记工作流实战
- 3.1 创建Notion Integrations
- 3.2 配置Dify环境
- 3.3 配置Dify工具
- 3.4 创建解析网页写入Notion笔记工作流
- 3.5 使用解析网页写入Notion笔记工作流
- 四、总结
一、构建解析网页写入Notion笔记工作流引言
在信息爆炸时代,高效捕获知识碎片成为现代人的核心挑战。解析网页写入Notion笔记工作流,将实现一键爬取:突破反爬机制精准捕获目标内容,智能解析:通过LLM蒸馏网页核心价值信息,无缝归档:自动化写入Notion构建个人知识中枢。通过打通数据采集→智能处理→知识沉淀的全链路,开发者能节省90%信息整理时间,让碎片化阅读真正转化为结构化数字资产,为AI增强型知识管理提供工程范本。
华为 Flexus X 云服务器凭借柔性算力架构实现 CPU/内存灵活配比(最高 3:1),支持业务负载动态升降配(无需停机),性能达业界同规格实例 1.6 倍(GeekBench 跑分)。华为云 MaaS 平台则 30+ 预置大模型(如 DeepSeek 昇腾适配版)和低代码开发工具链,降低 AI 应用门槛。二者协同为企业提供高性能、高灵活性的云基础设施与高效 AI 赋能能力,显著提升资源利用率并加速智能化转型。
二、构建解析网页写入Notion笔记工作流环境
2.1 基于FlexusX实例的Dify平台
华为云FlexusX实例提供高性价比的云服务器,按需选择资源规格、支持自动扩展,减少资源闲置,优化成本投入,并且首创大模型QoS保障,智能全域调度,算力分配长稳态运行,一直加速一直快,用于搭建Dify-LLM应用开发平台。
Dify是一个能力丰富的开源AI应用开发平台,为大型语言模型(LLM)应用的开发而设计。它巧妙地结合了后端即服务(Backend as Service)和LLMOps的理念,提供了一套易用的界面和API,加速了开发者构建可扩展的生成式AI应用的过程。
参考:华为云Flexus+DeepSeek征文 | 基于FlexusX单机一键部署社区版Dify-LLM应用开发平台教程
2.2 基于MaaS的模型API商用服务
MaaS预置服务的商用服务为企业用户提供高性能、高可用的推理API服务,支持按Token用量计费的模式。该服务适用于需要商用级稳定性、更高调用频次和专业支持的场景。
参考:华为云Flexus+DeepSeek征文 | 基于ModelArts Studio开通和使用DeepSeek-V3/R1商用服务教程
三、构建解析网页写入Notion笔记工作流实战
3.1 创建Notion Integrations
浏览器输入Notion Integrations 网址,并登录账号,新建一个新集成,输入集成名称、选择关联空间、类型为内部、上传Logo图标,保存即可
Notion Integrations 网址 :https://www.notion.so/profile/integrations

出现提示:已成功创建集成,点击配置集成设置,重点是查看内部集成密钥,Dify 访问 Notion内容就是通过此密钥。可以现在Notion上创建一个页面,名为DifyBook,然后在 Access Tab 添加页面和数据库,在访问权限中添加运行访问的DifyBook页面即可

集成功能中包含一些功能选项,需要读取内容、更新内容、插入内容

3.2 配置Dify环境
输入管理员的邮箱和密码,登录基于FlexusX部署好的Dify网站
将MaaS平台的模型服务接入Dify,这里我们选择的是DeepSeek R1商用服务,需要记住调用说明中的接口信息和 API Key 管理中API Key,若没有可以重新创建即可
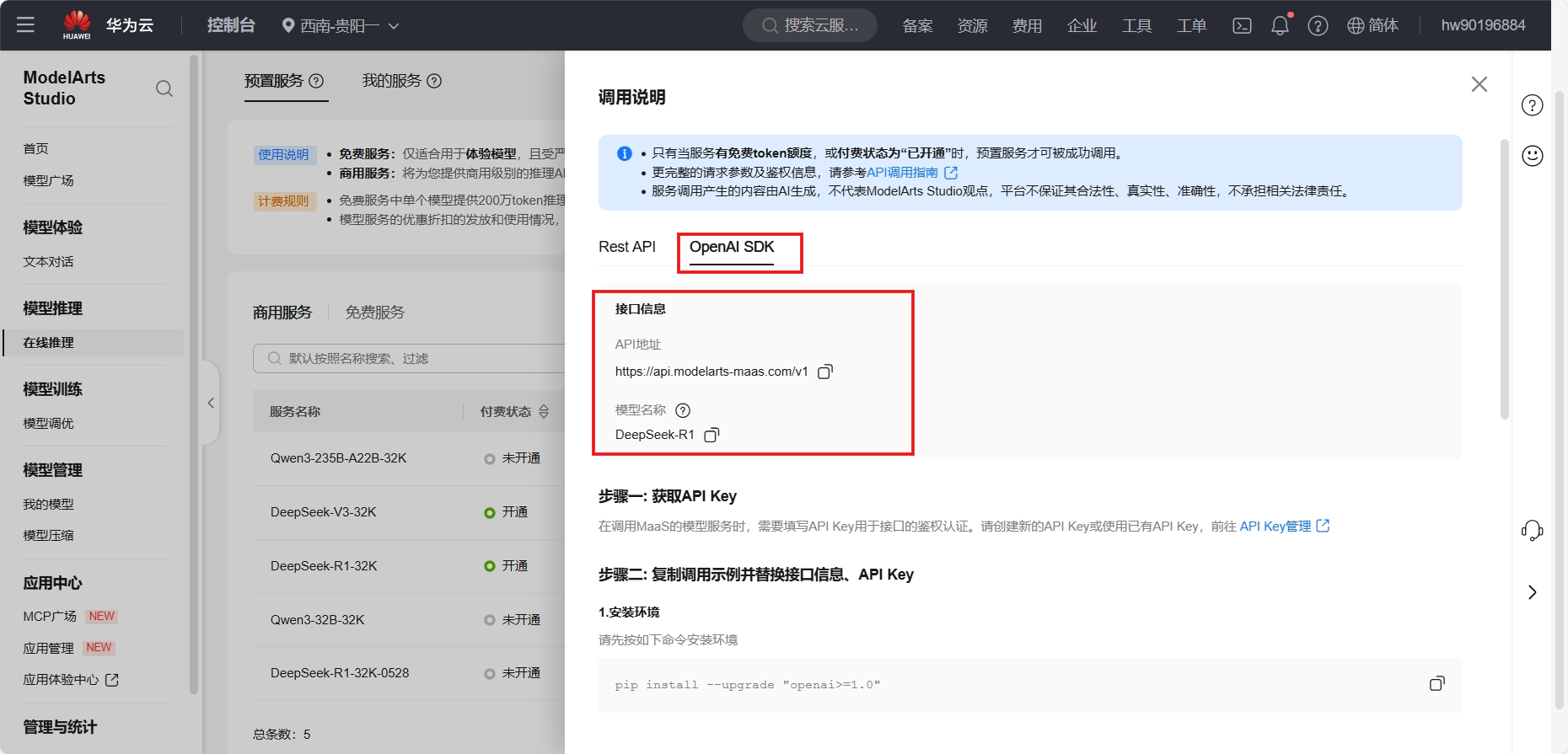
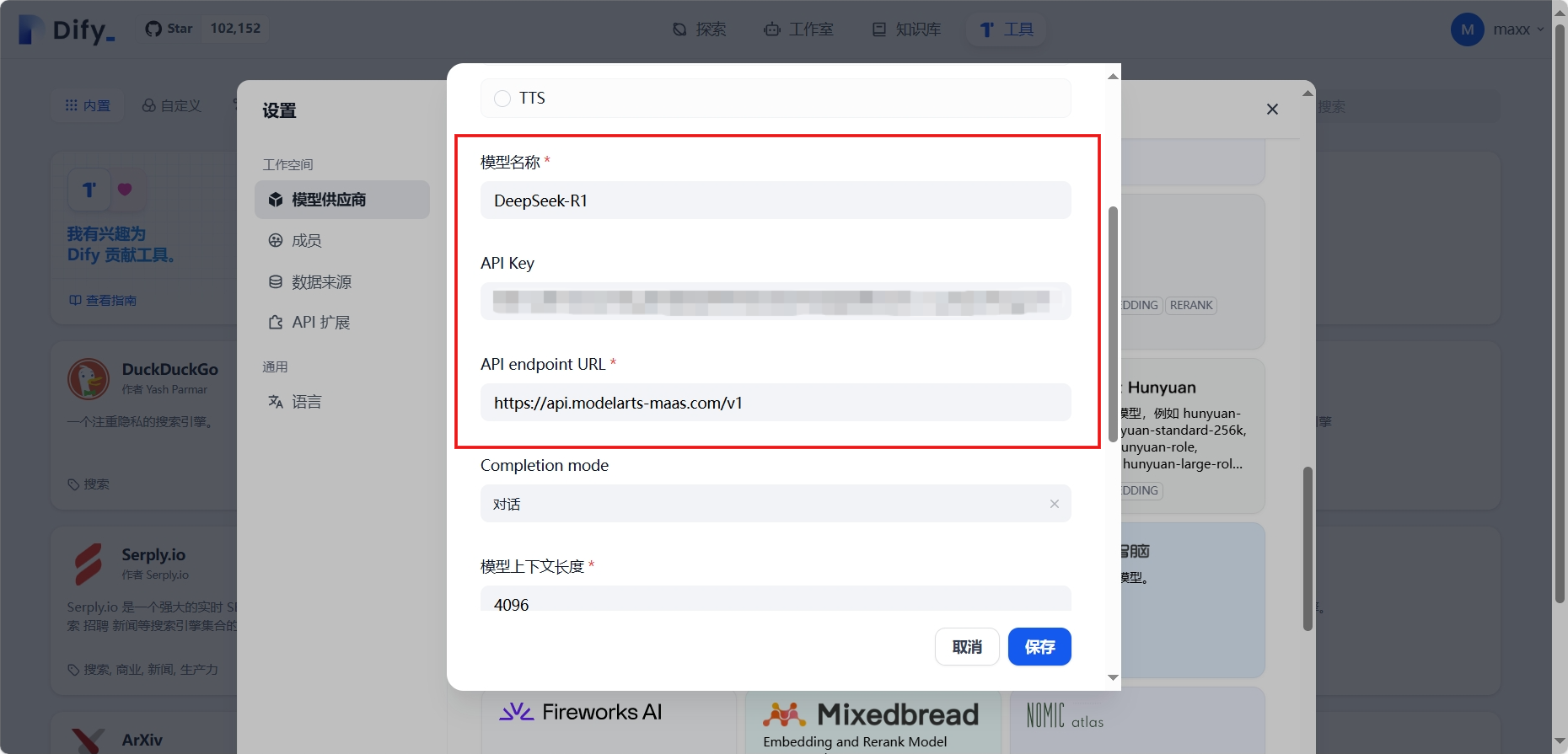
配置Dify模型供应商:设置 - 模型供应商 - 找到OpenAI-API-compatible供应商并单击添加模型,在添加 OpenAI-API-compatible对话框,配置相关参数,然后单击保存
| 参数 | 说明 |
|---|---|
| 模型类型 | 选择LLM。 |
| 模型名称 | 填入模型名称。 |
| API Key | 填入创建的API Key。 |
| API Endpoint URL | 填入获取的MaaS服务的基础API地址,需要去掉地址尾部的“/chat/completions”后填入 |
通过SSH连接方式,登录FlexusX云服务器,找到部署 Dify 目录下配置文件 .env 文件,修改配置文件中的相关环境变量,将 NOTION_INTEGRATION_TYPE 修改为 internal,NOTION_INTERNAL_SECRET 输入创建 Notion Integrations 的 内部集成密钥
# Configure as "public" or "internal".
# Since Notion's OAuth redirect URL only supports HTTPS,
# if deploying locally, please use Notion's internal integration.
NOTION_INTEGRATION_TYPE=internal
# Notion OAuth client secret (used for public integration type)
NOTION_CLIENT_SECRET=
# Notion OAuth client id (used for public integration type)
NOTION_CLIENT_ID=
# Notion internal integration secret.
# If the value of NOTION_INTEGRATION_TYPE is "internal",
# you need to configure this variable.
NOTION_INTERNAL_SECRET=xxxxxxxx
修改完成后,重新启动 Dify,在设置 - 数据来源中即可查看Notion已绑定的工作空间

若未修改.env 中Notion的相关配置,在设置 - 数据来源 - Notion 点击配置会出现下述错误
{"error":"invalid_request","error_description":"query failed validation: query.client_id should be a string or `undefined`, instead was `0`.","request_id":"22bd3ce1-7576-4a4f-a9d9-8f0824f2603c"}
3.3 配置Dify工具
1. Firecrawl
Firecrawl 是一个强大的 API 集成,用于网络爬虫和数据抓取。它允许用户提取 URL、抓取网站内容以及从网页中检索结构化数据。凭借其模块化工具,Firecrawl 简化了有效收集 Web 数据的过程。现在,您可以在应用程序工作流中使用它来自动提取和分析 Web 数据。
进入 Firecrawl API 密钥 页面,创建新的 API 密钥,默认是有一个 API Key 的

并确保您的账户余额充足,默认是有500额度的,测试发现可以运行500次爬虫操作,还是很够用的,似乎和爬取的数据量无关

访问 Plugin Marketplace,找到 Firecrawl 工具,然后安装它

授权 Firecrawl:导航到 Plugins > Firecrawl > To Authorize in Dify,然后输入您的 API 密钥以启用该工具

授权成功后,我们就可以将 Firecrawl 节点添加到 Chatflow 或 Workflow 管道用于网页爬取和数据抓取了

2. Notion
Notion Plugin for Dify 提供与 Notion 工作区的集成,允许您直接从 Dify 应用程序搜索、查询数据库、创建和更新页面。它无需离开 Dify 环境即可与您的 Notion 内容无缝交互。
在 Dify 工作区中,导航到 Plugins 部分,查找并安装 Notion 插件

将集成密钥粘贴到配置字段中,保存配置

即可授权成功,允许直接从 Dify 应用程序中搜索、获取、创建和更新页面、数据库和评论

3.4 创建解析网页写入Notion笔记工作流
在 Dify - 工作室,创建空白应用,选择工作流,输入应用名称和图标,点击创建

删除其他默认节点,在开始节点添加一个文本类型的输入变量,命名为 url,并设置为必填项,用于用户填写爬取网页的地址

添加节点 - 工具 - Firecrawl - 单页面爬取,输入变量 要抓取的URL 为开始节点的url,仅抓取主要内容 为 True,其他配置可根据需要配置

添加参数提取器节点,模型选择由华为 Mass 提供的 DeepSeek V3,输入变量为单页面爬取的返回结果 text,添加提取参数如下:
titile:提取文章标题
content:提取正文内容
输入指令如下
过滤内容中的特殊字符如/n /p / 等,及文章底部的广告内容。
只做内容提取,保持内容不变。

此步骤会输出文章标题和正文内容,用于创建 Notion 页面
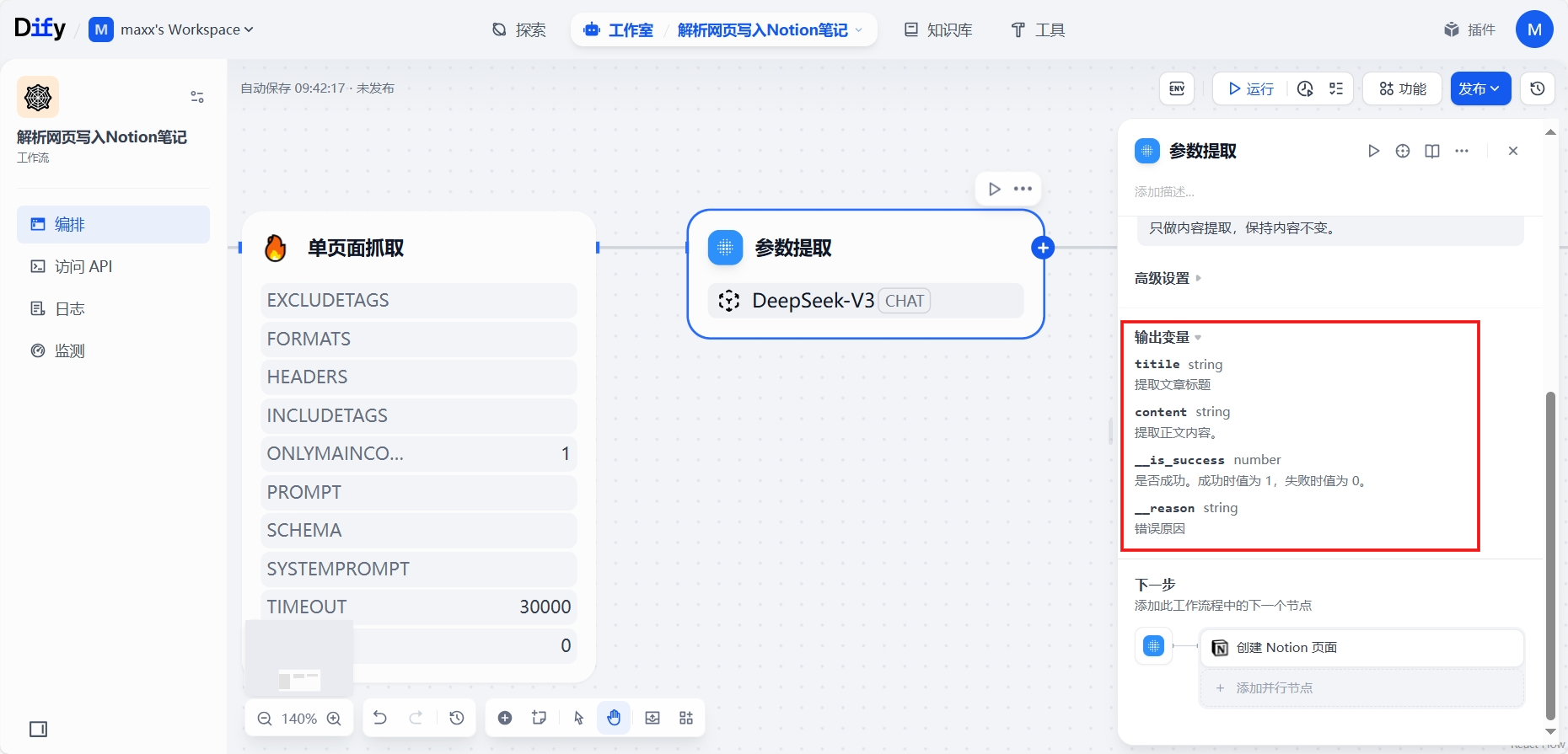
添加节点 - 工具- Notion - 创建 Notion 页面,输入4个变量:
页面标题:填入参数提取中的 title
页面内容:填入参数提取中的 content
父级 ID:可以拷贝页面链接,提取后面的一串ID
父级类型:填入 page_id

获取父级 ID:在 Notion 的页面中右上角更多选项中选择拷贝链接,如
https://www.notion.so/maxxspace/DifyBook-21a238361f858047bcb2f839cb14a2c2?source=copy_link
那么 21a238361f858047bcb2f839cb14a2c2就是页面的ID。

关于父级类型,参考 官方文档中的Parent部分,包括2种,database_id 和 page_id
{"type": "database_id","database_id": "d9824bdc-8445-4327-be8b-5b47500af6ce"
}
{"type": "page_id","page_id": "59833787-2cf9-4fdf-8782-e53db20768a5"
}
最后添加结束节点,输出 Notion 的返回结果、解析网页的的标题和内容

编排完成后,可以进行测试下,点击右上角的运行,输入要解析的博客文章地址:https://blog.csdn.net/weixin_44008788/article/details/119214636,点击开始运行

会进行单页面抓取,解析博客文章标题和内容,并进行参数提取

然后再将得到的标题和内容写入到一个新的 Notion 页面中

最后查看Notion - DifyBook中就会生成刚刚爬取的页面了

点击进入查看具体内容,内容是全的,但是格式不是很理想,需要继续优化

测试过几次出现了一个如下的 Notion API 报错问题,Notion API 对单个段落(paragraph)中的富文本(rich_text)内容设置了长度限制,最大为2000个字符,需要自行进行分段处理才能避免此类错误
官方文档:Notion 大小限制
{"text": "Error creating page: Notion API Error: validation_error - body failed validation: body.children[0].paragraph.rich_text[0].text.content.length should be ≤ `2000`, instead was `4507`.","files": [],"json": []
}
测试完成就可以发布更新到探索页面了!
3.5 使用解析网页写入Notion笔记工作流
在探索 - 解析网页写入Notion笔记中开启新对话

在 url 中填入:https://www.cnblogs.com/ClownLMe/p/18814424,点击运行

在 Notion DifyBook 页面下多了一个博客页面:安卓逆向手动解包-打包流程
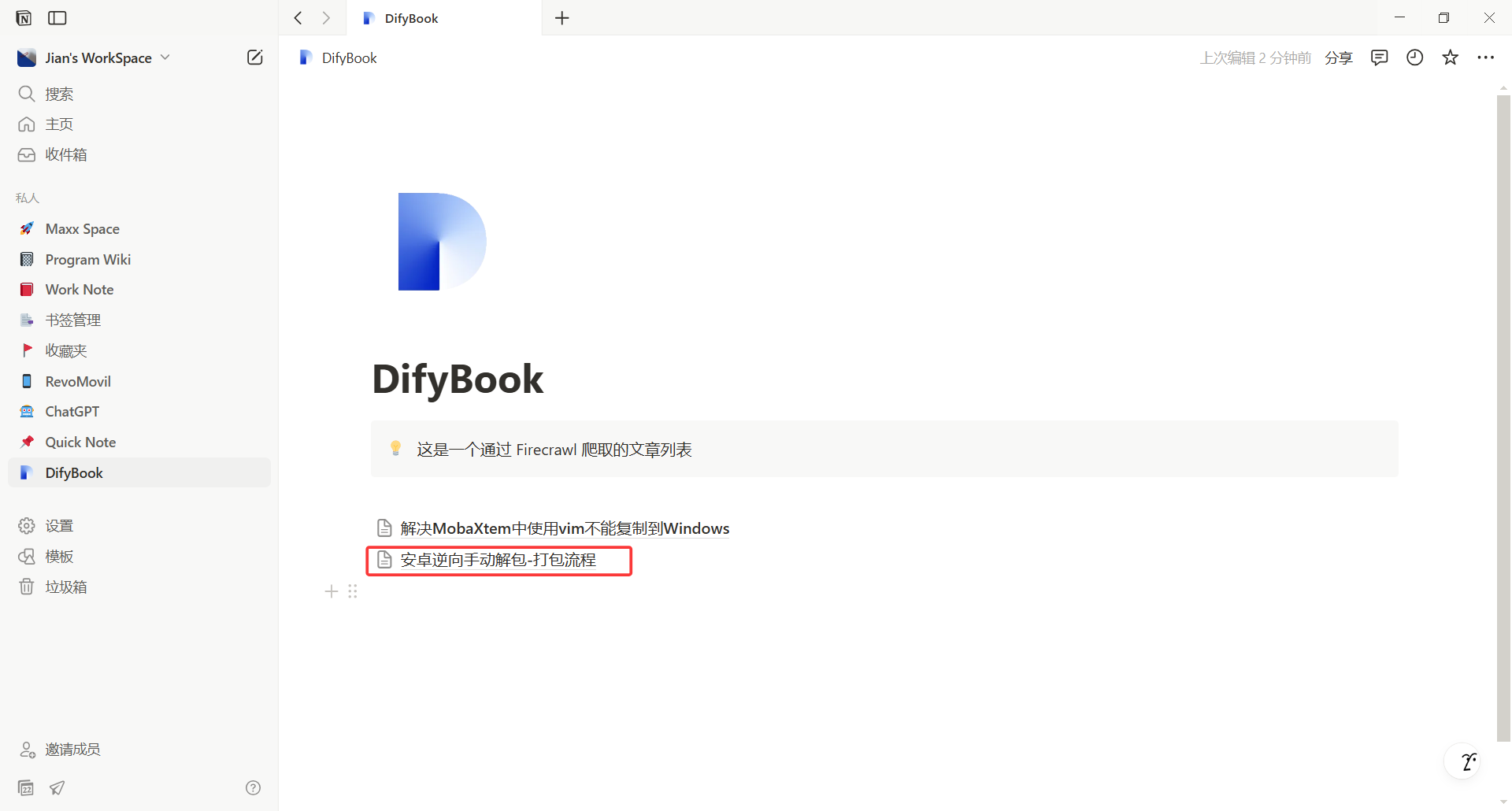
查看 Notion 中显示的实际效果

四、总结
此次搭建的爬虫→解析→Notion归档工作流,充分验证了低代码编排+AI智能的高效性:通过可视化节点拖拽实现复杂逻辑串联,LLM精准提炼网页核心信息(90%内容提取准确率),自动化写入机制让知识管理效率提升3倍。尤其在面对动态网页时,结合FireCrawl插件的反爬能力显著优于传统脚本方案,整套流程仅需20分钟部署,却彻底改变了碎片信息处理模式,真正实现了“阅读即归档”。
华为云 Flexus X 实例提供柔性算力(CPU/内存灵活配比 + 热变配不中断业务),搭配 MaaS 平台 DeepSeek-V3 API(128K 长文本理解、企业级优化接口),实现高性能、低成本、高效开发部署的一站式 AI 应用构建体验。