郑州营销网站建设公司网站关键词优化软件
1月15日,由上海人工智能实验室(上海AI实验室)推出的书生·浦语3.0(InternLM3)正式开源,通过精炼数据框架,大幅提升了数据效率,并实现思维密度的跃升。仅使用4T训练数据的InternLM3-8B-Instruct,其综合性能超过了同量级开源模型,节约训练成本75%以上;同时,书生·浦语3.0首次在通用模型中实现了常规对话与深度思考能力融合,可应对更多真实使用场景。
基于上海AI实验室的DeepLink人工智能开放计算体系,书生·浦语3.0与沐曦达成合作,支持使用开源工具LMDeploy和XTuner,在沐曦曦云C系列产品上实现书生·浦语3.0的高效推理与微调训练。
沐曦旗舰产品曦云C系列产品采用全自主研发的通用GPU IP,内置大容量显存、支持多卡互联。自研MXMACA 原生支持国际主流深度学习算法框架,配套自研Compiler、Libraries、Runtime API、Tools & Documents等一系列整套GPU编程工具,并全面兼容国际主流GPU生态,可大幅降低新兴GPU的迁移适配成本。曦云C系列GPU适用于智算、通用计算、数据处理等多种应用场景。
本文将介绍如何使用开源工具LMDeploy和XTuner,结合DeepLink在沐曦曦云C系列产品上实现书生·浦语3.0的高效推理与微调训练。
InternLM 开源链接:
https://github.com/InternLM/InternLM
DeepLink dlinfer 开源链接:
https://github.com/DeepLink-org/dlinfer
LMDeploy 开源链接:
https://github.com/InternLM/lmdeploy
XTuner 开源链接:
https://github.com/InternLM/xtuner
1.使用LMDeploy进行高效推理
1.1 LMDeploy 与 dlinfer简介
LMDeploy涵盖了LLM任务的全套轻量化、部署和服务解决方案。
DeepLink团队开发的dlinfer提供了一套将新兴硬件接入大模型推理框架的解决方案。对上承接大模型推理框架,对下在eager模式下调用各厂商的融合算子,在graph模式下调用厂商的图引擎。dlinfer 根据主流大模型推理框架与主流硬件厂商的融合算子粒度,定义了大模型推理的融合算子接口。目前,dlinfer正在全力支持LMDeploy适配包括沐曦在内的多款新兴芯片品牌。
1.2 推理环境准备
获取模型推理镜像
登录沐曦开放平台软件中心获取docker镜像:
vllm:maca2.27.0.9-py38-ubuntu22.04-amd64
可联系沐曦business@metax-tech.com获取软件中心地址和账号
安装 dlinfer 和 LMDeploy
dlinfer 安装:
DEVICE=maca python3 setup.py developLMDeploy安装:
LMDEPLOY_TARGET_DEVICE=maca pip3 install -e .1.3 进行推理
环境变量设置
export MACA_PATH=/opt/maca
export PATH=${MACA_PATH}/bin:${PATH}
export LD_LIBRARY_PATH=${MACA_PATH}/lib:${MACA_PATH}/mxgpu_llvm/lib:${LD_LIBRARY_PATH}推理代码示例如下:
import lmdeploy
from lmdeploy import PytorchEngineConfig
if name == "__main__":pipe = lmdeploy.pipeline("internlm/internlm3-8b-instruct",backend_config = PytorchEngineConfig(tp=1,cache_max_entry_count=0.8, device_type="maca", block_size=16))question = ["Shanghai is", "Please introduce China", "How are you?"]response = pipe(question, request_output_len=256, do_preprocess=False)for idx, r in enumerate(response):print(f"Q: {question[idx]}")print(f"A: {r.text}")print()使用XTuner进行微调训练
XTuner是一个高效、灵活、全能的轻量化大模型微调工具库。
训练环境准备
获取模型训练镜像
登录沐曦开放平台软件中心获取docker镜像:
deepspeed:maca2.27.0.10-py38-ubuntu22.04-amd64
可联系沐曦business@metax-tech.com获取软件中心地址和账号
安装XTuner
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -r requirements.txt
pip install -e .依赖安装
升级pip并安装transformers库:
pip install --upgrade pip
pip install transformers安装适配沐曦曦云C系列产品的torch2.4
登录沐曦开软件中心下载适配沐曦GPU的torch 2.4并安装:
pip install torch*.whl训练数据与模型准备
准备训练数据文件
向sft.jsonl中填入样例SFT格式数据:
{"messages": [{"role": "user", "content": "Hello"}, {"role": "assistant", "content": "Hello!"}]}
{"messages": [{"role": "user", "content": "Hello"}, {"role": "assistant", "content": "Hello!"}]}
{"messages": [{"role": "user", "content": "Hello"}, {"role": "assistant", "content": "Hello!"}]}下载模型文件
modelscope download --model Shanghai_AI_Laboratory/internlm3-8b-instruct --local_dir pth_to_internlm3_8b启动微调训练
环境变量设置
export MACA_PATH=/opt/maca
export PATH=${MACA_PATH}/bin:${PATH}
export LD_LIBRARY_PATH=${MACA_PATH}/lib:${MACA_PATH}/mxgpu_llvm/lib:${LD_LIBRARY_PATH}启动微调
torchrun --nnodes=1 --nproc_per_node=4 --master_port=12983 \tools/fsdp_sft.py \--llm pth_to_internlm3_8b \ --tokenizer pth_to_internlm3_8b \ --datasets internlm3/data/sft.jsonl \--dset-file-types .jsonl \--dset-cache-dir cached \--dset-formats openai \--dset-pack-level soft \--group-by-length \--max-length 2048 \--sp-size 4 \--global-batch-size 4 \--lr 2e-6 \--wd 0.0 \--warmup-ratio 0.03 \--num-workers 1 \--work-dir saves/output/ \2>&1 | tee -a $logfile;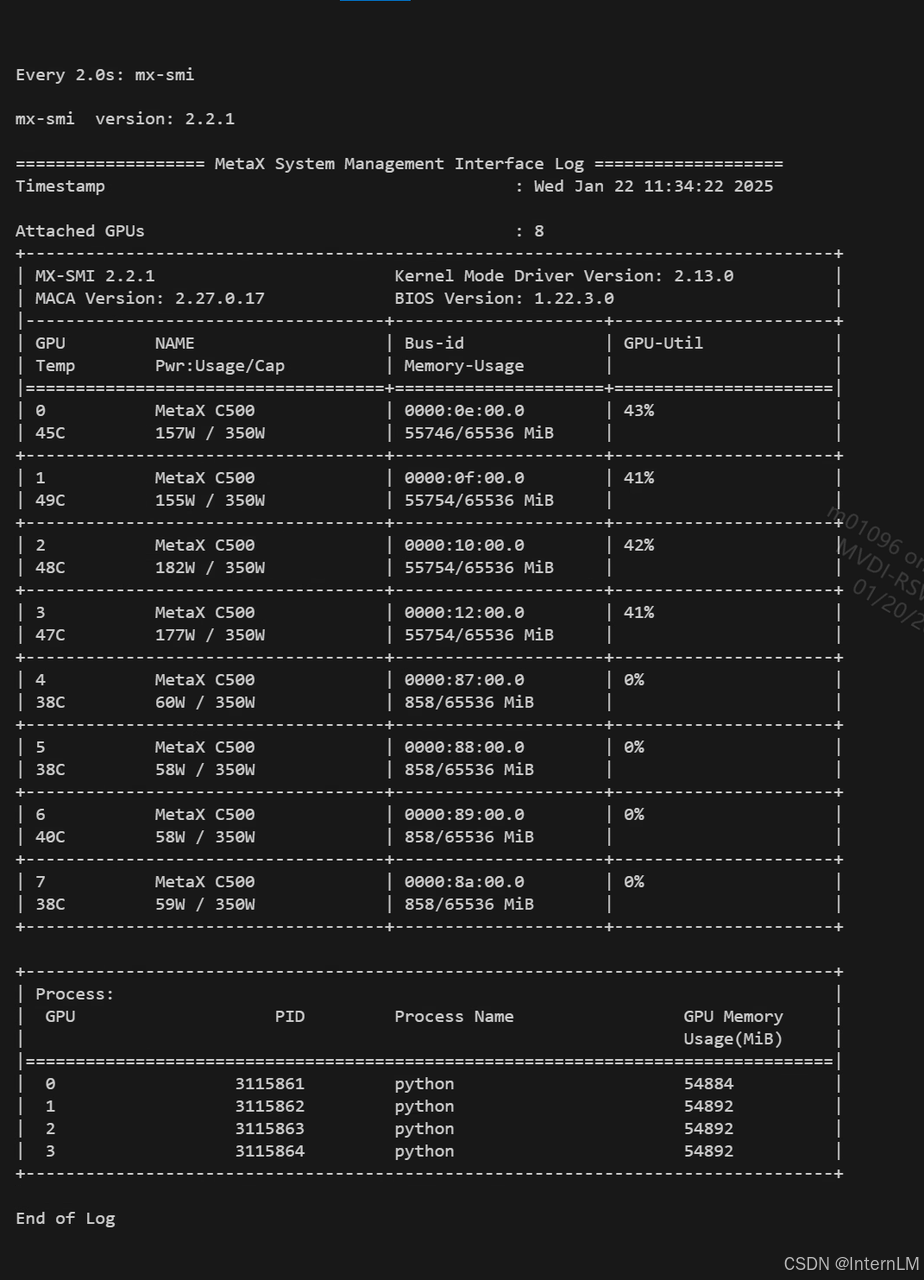
通过以上步骤,您可以使用开源工具DeepLink、LMDeploy 和 XTuner,在沐曦曦云C系列产品上实现书生·浦语3.0的高效推理与微调训练。