滨江网站开发企业培训十大热门课程
文章目录
- 1.概率论基础
- 1.1 单事件概率
- 1.2 多事件概率
- 1.3 条件概率
- 1.3.1 多事件概率与条件概率的区别
- 1.4 贝叶斯定理
- 传统思维误区
- 贝叶斯定理计算
- 2. 朴素贝叶斯法
- 2.1 基本概念
- 2.2 模型
- 2.3 学习策略
- 2.4 优化算法
- 2.5 优化技巧
- 拉普拉斯平滑
- 对数似然
- 3. 情感分析实战
- 3.1 流程
- 3.2 模型评价
- 3.3 应用场景
- 3.4 局限性
- 3.4 局限性
1.概率论基础
1.1 单事件概率
定义:一个事件发生的可能性。
例子:假设事件A表示“一个文本是正向的”,则P(A) = 正向文本数 / 总文本数。
解释:比如有20个文本,其中13个是正向的,那么P(A) = 13/20 = 0.65。

1.2 多事件概率
定义:多个事件同时发生的概率。
例子:事件A(文本是正向的)和事件B(文本包含单词“happy”)同时发生的概率P(A,B) = P(A∩B) = 3/20。
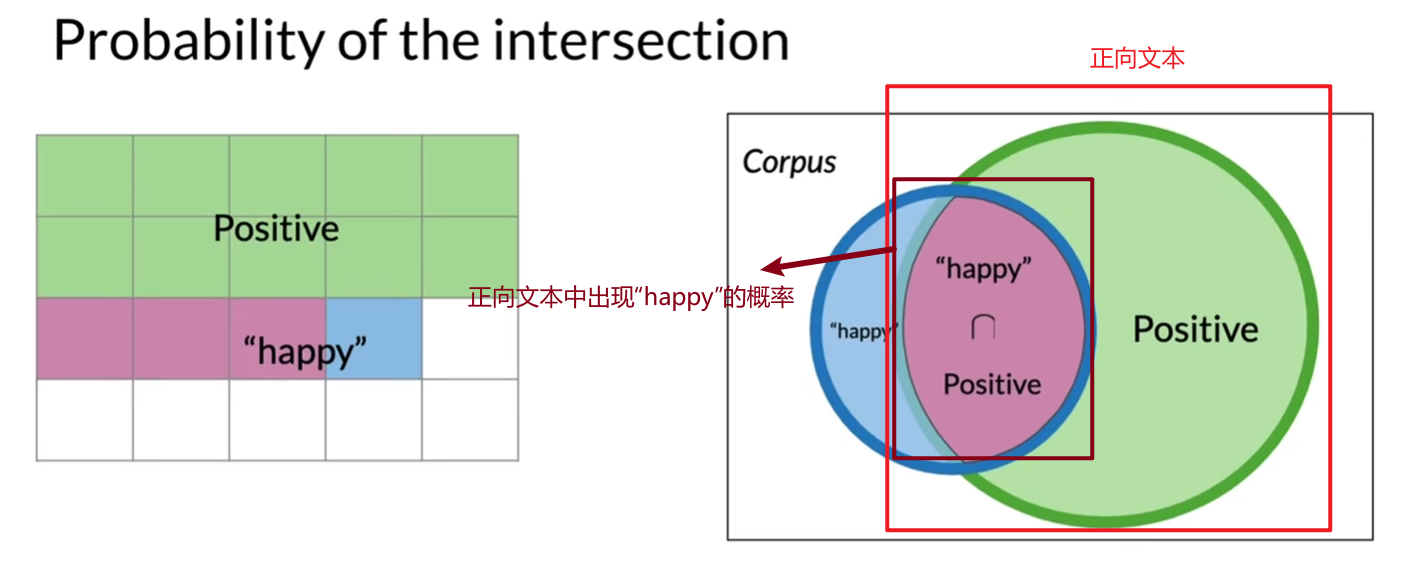
举个例子:假设某餐厅统计发现:
- 30%的订单点了汉堡(事件A)
- 20%的订单同时点了汉堡和薯条(事件A∩B)
那么:
- 多事件概率:P(汉堡且薯条) = 20%
(直接表示同时点这两样的概率)
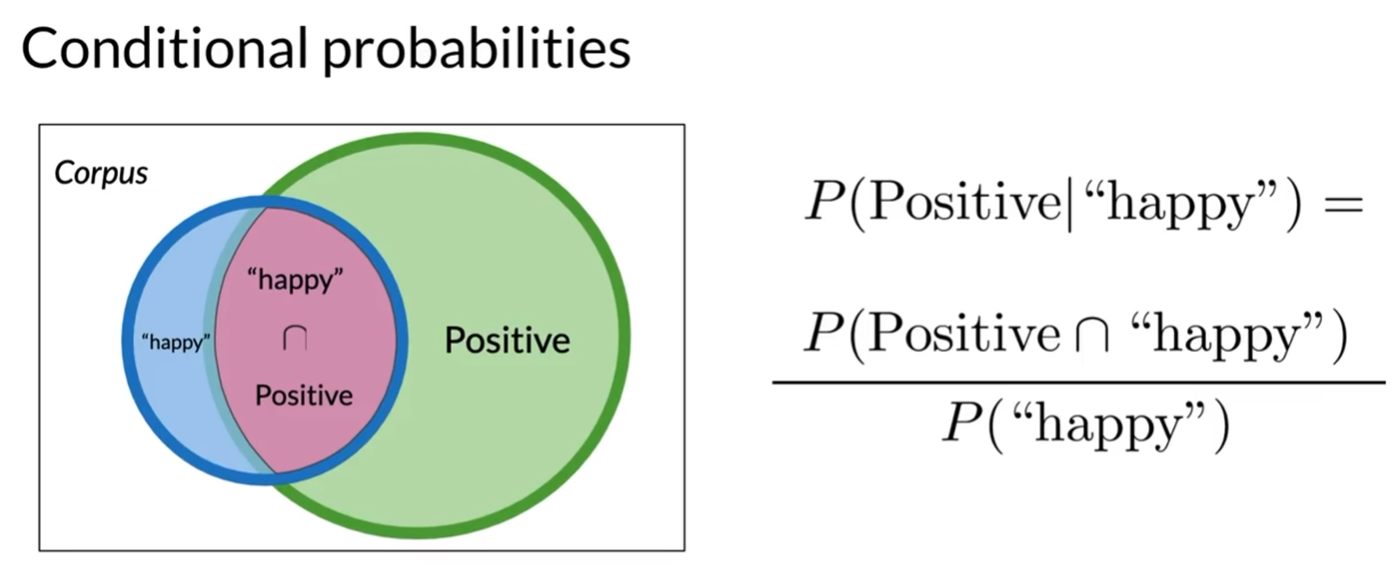
1.3 条件概率
定义:在已知事件B发生的情况下,事件A发生的概率,记作P(A|B)。
公式:P(A|B) = P(A∩B) / P(B)。
作用:缩小计算范围。例如,已知文本包含“happy”,计算它是正向的概率时,只需关注包含“happy”的文本。
延续刚刚的例子:已知某餐厅统计发现:
- 薯条订单占全店40%(事件B)
- 汉堡和薯条同时点占20%(事件A∩B)
则:
- 条件概率:P(汉堡|已点薯条) = 20%/40% = 50% 【两者同时的概率 / 单单薯条的概率】
(在已经点薯条的订单中,有50%会加购汉堡)
1.3.1 多事件概率与条件概率的区别
| 维度 | 多事件概率 | 条件概率 |
|---|---|---|
| 计算范围 | 全局样本空间 | 限定在条件事件发生的子空间 |
| 信息量 | 反映单纯共存概率 | 揭示事件间的关联强度 |
| 应用场景 | 分析事件组合频率 | 研究因果关系/预测 |
典型误区分辨
- ❌错误理解:“今天下雨且堵车”(多事件概率) vs “下雨导致堵车”(条件概率)
- ✅正确区分:
- 多事件概率:全市范围内同时下雨和堵车的概率(比如10%)
- 条件概率:在下雨的日子里发生堵车的概率(可能高达70%)
NLP应用实例(情感分析)
假设分析1,000条商品评论:
- 200条出现"价格"(事件A)
- 50条同时出现"价格"和"昂贵"(事件A∩B)
- "昂贵"出现总次数100次(事件B)
多事件概率:
P(“价格"且"昂贵”) = 50/1000 = 5%
(所有评论中同时包含这两个词的概率)
条件概率:
P(“昂贵”|出现"价格") = 50/200 = 25%
(在提到价格的评论中,"昂贵"出现的概率)【两者同时的概率 / 单单价格的概率】
1.4 贝叶斯定理
定义:通过已知事件Y反推事件X的概率。贝叶斯定理是"用结果反推原因"的概率计算方法。就像侦探破案:已知犯罪现场有某种证据(结果),计算某个嫌疑人作案(原因)的概率。
公式:P(X|Y) = P(Y|X) * P(X) / P(Y)。
用途:在分类问题中,通过观测数据反推类别概率。
举个例子(疾病检测)
假设:
- 某疾病在人群中的患病率是1%(先验概率)
- 检测准确率:
- 真有病的人,99%能测出阳性(真阳性率)
- 没病的人,2%会误测为阳性(假阳性率)
问题:如果一个人检测呈阳性,他实际患病的概率是多少?
传统思维误区
很多人会直接认为概率是99%,忽略了基础患病率。
贝叶斯定理计算
P(患病|阳性) = P(阳性|患病) * P(患病) / P(阳性) P(阳性) = [P(阳性|患病) * P(患病) + P(阳性|正常) * P(正常)
= (99% * 1%) / (99% * 1% + 2% * 99%) 这里的P(正常)更多的是:1-P(患病) = 99%
≈ 33%
【“患病”是因,“阳性”是果 ,先乘因,再除果】
即使检测呈阳性,实际患病概率只有33%!
接下来我将对公式进行拆解:
P(原因|结果) = [P(结果|原因) × P(原因)] / P(结果)
- P(原因):先验概率(已知的客观事实)
- P(结果|原因):似然度(原因导致结果的可能性)
- P(原因|结果):后验概率(我们想求的答案)
NLP应用实例(垃圾邮件过滤)
已知:
- 邮件中出现**“折扣”**这个词:
- 在垃圾邮件中出现的概率是80%(P(折扣|垃圾))
- 在正常邮件中出现的概率是10%(P(折扣|正常))
- 整体邮件中垃圾邮件占比20%(P(垃圾))
计算:
P(垃圾|折扣) = [P(折扣|垃圾) * P(垃圾)] / [P(折扣|垃圾) * P(垃圾) + P(折扣|正常) * P(正常)]
= (80% * 20%) / (80% * 20% + 10% * 80%) 这里的P(正常)更多的是:1-P(垃圾) = 80%
= 66.7%
虽然"折扣"在垃圾邮件中出现概率高,但综合考量后,含这个词的邮件是垃圾邮件的概率是66.7%。
那么为什么叫"定理"?
因为可以通过条件概率公式严格推导:
- 根据条件概率定义:P(A|B)=P(A∩B)/P(B)
- 同理:P(B|A)=P(A∩B)/P(A)
- 联立两式消去P(A∩B)即得贝叶斯定理
2. 朴素贝叶斯法
2.1 基本概念
概述:基于贝叶斯定理的分类方法,假设特征之间相互独立(称为“朴素”)。
优点:简单高效,适合文本分类等任务。
缺点:特征独立性假设可能影响准确性。
条件独立假设:
- 假设所有特征在类别确定时彼此独立。
- 虽然简化计算,但现实中特征可能相关。
2.2 模型
目标:对输入数据x,预测最可能的类别y。
核心公式:
y = argmax P(y) * Π P(x_i|y),即选择使后验概率最大的类别。
2.3 学习策略
极大似然估计(MLE):
- 估计先验概率P(y)和条件概率P(x_i|y)。
- 先验概率:P(y) = 类别y的样本数 / 总样本数。
- 条件概率:P(x_i|y) = 类别y中特征x_i出现的次数 / 类别y的总样本数。
2.4 优化算法
后验概率最大化:
- 选择使后验概率最大的类别,等价于最小化分类错误。
2.5 优化技巧
拉普拉斯平滑
问题:某些特征未出现时概率为0,导致整体概率为0。
解决:分子加1,分母加特征总数V,避免零概率。
对数似然
问题:连乘小数可能导致数值下溢(结果过小无法表示)。
解决:对概率取对数,将连乘转为连加。
- 概率比值:ratio(w_i) = P(w_i|正向) / P(w_i|负向)。
- 对数似然:λ(w_i) = log(ratio(w_i))。
- 最终决策:若对数先验 + Σλ(w_i) > 0,则为正向;否则为负向。
3. 情感分析实战
3.1 流程
- 数据预处理:清洗文本(如去标点、分词)。
- 构建词频表:统计单词在正向/负向文本中的出现次数。
- 计算概率:
- 条件概率:P(w_i|正向)和P(w_i|负向)。
- 对数似然:λ(w_i) = log(P(w_i|正向)/P(w_i|负向))。
- 预测:根据对数先验 + Σλ(w_i)的符号判断情感倾向。
3.2 模型评价
准确度:正确预测的文本数 / 总文本数。
3.3 应用场景
- 垃圾邮件分类
- 新闻分类
- 情感分析
3.4 局限性
- 条件独立假设:忽略单词间的关联(如“not happy”)。
- 数据不平衡:正向/负向样本数量差异大时影响效果。
- 文本复杂性:
- 标点可能携带情感(如“好!” vs “好?”)。
- 停用词(如“的”)有时也有情感意义。
- 反讽或夸张难以捕捉。
- 新闻分类
- 情感分析
3.4 局限性
- 条件独立假设:忽略单词间的关联(如“not happy”)。
- 数据不平衡:正向/负向样本数量差异大时影响效果。
- 文本复杂性:
- 标点可能携带情感(如“好!” vs “好?”)。
- 停用词(如“的”)有时也有情感意义。
- 反讽或夸张难以捕捉。