做网站帮外国人淘宝网络推广如何收费
DeepSeek-R1模型蒸馏
一、蒸馏模型的基本原理
DeepSeek-R1蒸馏模型是一种通过知识迁移技术,将大型教师模型(如671B参数的DeepSeek-R1)的推理能力压缩到更小规模学生模型中的方法。其核心目标是在保持高精度的前提下,降低计算资源消耗,实现模型在消费级硬件上的部署。
该技术基于师生范式:
- 教师模型:采用强化学习训练的DeepSeek-R1,具备复杂推理能力。
- 学生模型:基于开源架构(如Qwen、Llama系列)的轻量化模型,通过蒸馏继承教师的知识。
- 知识迁移机制:利用软目标(概率分布)传递教师模型的决策逻辑,而非单纯模仿硬标签。
二、蒸馏模型实现步骤
1. 数据生成阶段
- 使用DeepSeek-R1生成约80万条包含多步推理的样本数据,覆盖数学解题、代码生成等复杂场景。
- 数据特点:
- 包含完整思维链(Chain-of-Thought)
- 标注置信度分数(如问题解法的概率分布)
- 覆盖长文本验证过程(部分案例达数万字)
2. 模型选择与训练
-
基础架构选择:
- Qwen系列:1.5B/7B/14B/32B参数版本
- Llama系列:8B/70B参数版本
-
训练方法:
- 混合损失函数:结合KL散度(衡量概率分布差异)和交叉熵(保证基础任务准确率)
- 渐进式蒸馏:分阶段迁移不同复杂度知识,先学习基础推理模式,再强化高阶逻辑
- 硬件优化:支持FP8/INT8量化,H800 GPU上单机吞吐可达2000+ token/s
3. 评估与优化
- 基准测试:在AIME2024(数学竞赛)、MATH-500等专业数据集验证:
- Qwen-32B:72.6% Pass@1(AIME2024)
- Llama-70B:94.5% Pass@1(MATH-500)
- 应用调优:支持RAG(检索增强生成)和领域微调,适配金融、医疗等垂直场景
三、关键技术解析
1. 师生架构设计
| 模型类型 | 参数规模 | 应用场景 |
|---|---|---|
| R1-Zero | 671B | 高精度推理任务 |
| Distill-Qwen | 1.5B-32B | 移动端/边缘计算部署 |
| Distill-Llama | 8B-70B | 企业级服务器集群 |
2. 数据生成策略
- 动态阈值过滤:仅保留教师模型置信度>85%的样本
- 多模态增强:混合文本、代码、数学符号等多类型数据
- 对抗性样本注入:提升模型鲁棒性
3. 训练优化方法
- 知识分层迁移:先迁移基础逻辑推理能力,再传递复杂策略
- 动态量化感知训练:在训练阶段模拟量化误差,提升部署稳定性
- 多教师协同:结合多个教师模型的优势知识(实验阶段)
核心技术汇总表
| 技术维度 | 具体实现 |
|---|---|
| 师生架构 | DeepSeek-R1作为教师模型,Qwen/Llama系列作为学生模型 |
| 数据策略 | 80万条多步推理数据生成,软硬标签混合训练 |
| 训练方法 | KL散度+交叉熵混合损失函数,渐进式知识迁移 |
| 模型变体 | 支持1.5B-70B参数范围,适配不同硬件部署需求 |
| 性能优化 | FP8/INT8量化支持,H800 GPU实现2000+ token/s吞吐 |
| 应用扩展 | 集成RAG技术,支持金融、医疗等领域的定制化微调 |
DeepSeek-R1模型蒸馏硬件要求
一、硬件配置分级说明
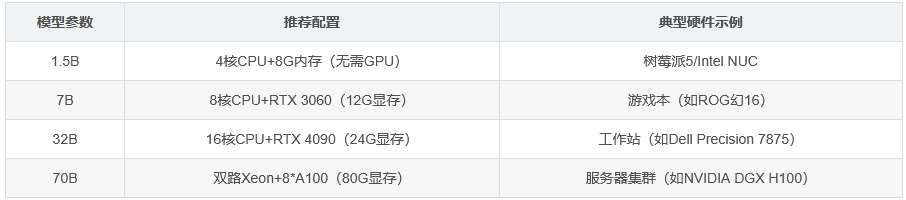
1. 轻量级模型(1.5B-8B)
- 适用场景:个人设备(如笔记本)、嵌入式系统、简单文本生成和基础问答
- CPU:Intel i7或AMD Ryzen 5以上多核处理器(建议4核以上)
- 内存:8-16 GB RAM(纯CPU推理无需GPU)
- GPU(可选):4-8 GB显存(如GTX 1060/RTX 3070),支持FP8/INT4量化加速
- 存储:5-10 GB SSD空间(推荐NVMe协议)
2. 中端模型(14B-32B)
- 适用场景:专业工作站、企业服务器、长文本处理和领域咨询(医疗/法律)
- CPU:12-16核服务器级处理器(如Xeon E5/AMD EPYC)
- 内存:64 GB以上DDR4 ECC内存
- GPU:单卡16-24 GB显存(如RTX 4090/A100 40GB),支持多卡并行
- 存储:30-50 GB SSD空间(推荐读写速度≥3 GB/s)
3. 高性能模型(70B)
- 适用场景:科研机构、大规模数据分析、复杂算法设计
- CPU:32核及以上服务器处理器(如Xeon Platinum)
- 内存:128 GB以上DDR5内存
- GPU:多卡集群(如8+张A100/H100,显存≥80GB/卡),需支持NVLink/InfiniBand高速互联
- 存储:100 GB+ NVMe SSD(建议采用分布式存储)
二、关键硬件指标说明
| 指标 | 具体要求 |
|---|---|
| 量化支持 | FP8/INT8量化技术可降低显存占用(如32B模型Q4量化仅需20GB显存) |
| 散热系统 | 70B模型需配备液冷散热系统,中端模型建议风冷TDP≥250W |
| 网络带宽 | 多卡部署需千兆局域网,云端API调用推荐≥100Mbps带宽 |
| 指令集 | CPU需支持AVX2指令集,GPU需CUDA 11.8以上 |
三、部署优化建议
-
显存管理:
- 16G显存设备可通过分层加载技术部署32B Q4模型,但推理速度会降至5-15 token/s
- 推荐24G显存(如RTX 4090)搭配32B Q4量化实现经济高效部署
-
混合推理:
- CPU+GPU协同计算(如Llama.cpp 的BLAS加速)可提升14B模型在消费级硬件的性能
-
工具适配:
- 支持LM Studio/Ollama等框架,70B模型建议采用vLLM加速引擎
硬件配置速查表