做动物网站的素材seo优化推广多少钱
摘要:大型语言模型(LLM)的推理过程往往会产生比简单语言建模任务更长的标记生成序列。这种更长的生成长度反映了推理的多步骤和组合性质,并且通常与更高的解决方案准确性相关。从效率角度来看,更长的标记生成加剧了LLM解码阶段固有的顺序性和内存受限问题。然而,并非推理过程的所有部分生成难度都相同。我们利用这一观察结果,将推理过程中最具挑战性的部分卸载到一个更大、能力更强的模型中,而大部分生成工作则由一个更小、更高效的模型完成;此外,我们还训练较小的模型识别这些困难部分,并在需要时独立触发卸载。为了实现这种行为,我们在OpenR1-Math220k链式思维(CoT)数据集中标注了1.8万个推理轨迹中的困难部分。然后,我们对一个拥有15亿参数的推理模型应用了监督微调(SFT)和强化学习微调(RLFT),训练它将自己的推理过程中最具挑战性的部分卸载到一个更大的模型中。这种方法在分别卸载1.35%和5%的生成标记时,将AIME24推理准确率分别提高了24%和28.3%。我们开源了我们的SplitReason模型、数据集、代码和日志。
本文目录
一、背景动机
二、核心贡献
三、实现方法
3.1 数据构造
3.2 推理阶段
3.3 训练阶段
四、实验结果
4.1 推理切换行为
4.2 跨模型大小的卸载
4.3 数据集分布和诱导卸载
4.4 性能模拟
一、背景动机
论文题目:SplitReason: Learning To Offload Reasoning
论文地址:https://arxiv.org/pdf/2504.16379v1
大尺寸模型在推理任务中表现优秀,但推理过程通常需要生成更长的token序列,这增加了推理时的计算成本。此外,推理任务需要在推理时增加更多的计算量,这导致了推理时间的显著增加。
文章提出,推理过程的不同部分在生成难度上并不均匀,某些部分可以使用较小的模型轻松生成,而其他部分则需要更大的模型进行复杂推理。基于这一观察,SplitReason框架通过将最复杂的推理部分卸载到更大的模型上,同时使用较小的模型进行大部分生成,从而提高推理效率和准确性。
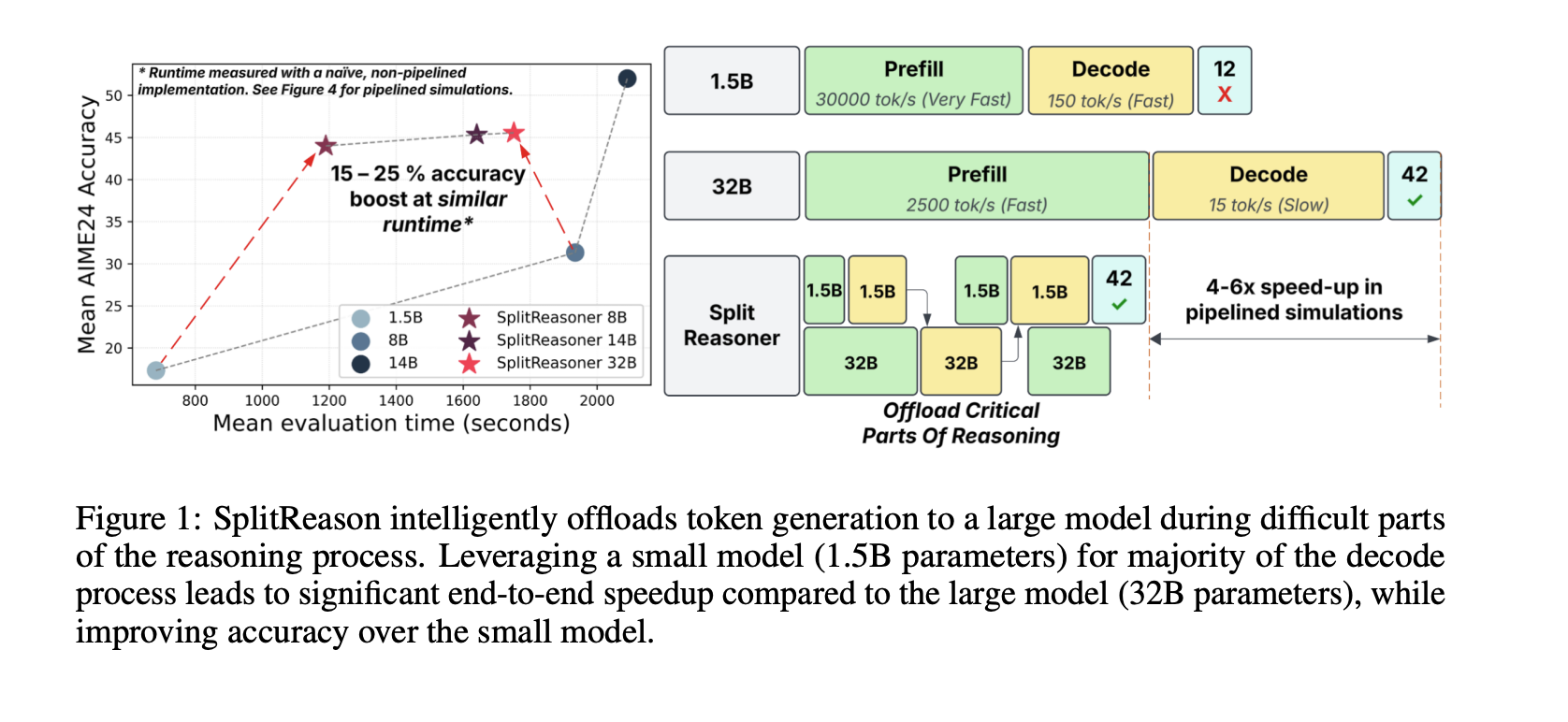
二、核心贡献
- 构造了一个微调数据集和训练框架,使模型能够学习何时将自身的推理过程卸载到更大的模型上。
- 通过将约5%的推理过程卸载到更大的模型上,小推理模型的准确性可以提高28.3%:这可以将推理速度加快4-6倍。
- 证明了模型可以学习分辨出推理中步骤的难易程度,并且可以利用强化学习优化效率来实现更高的效率。
三、实现方法
3.1 数据构造
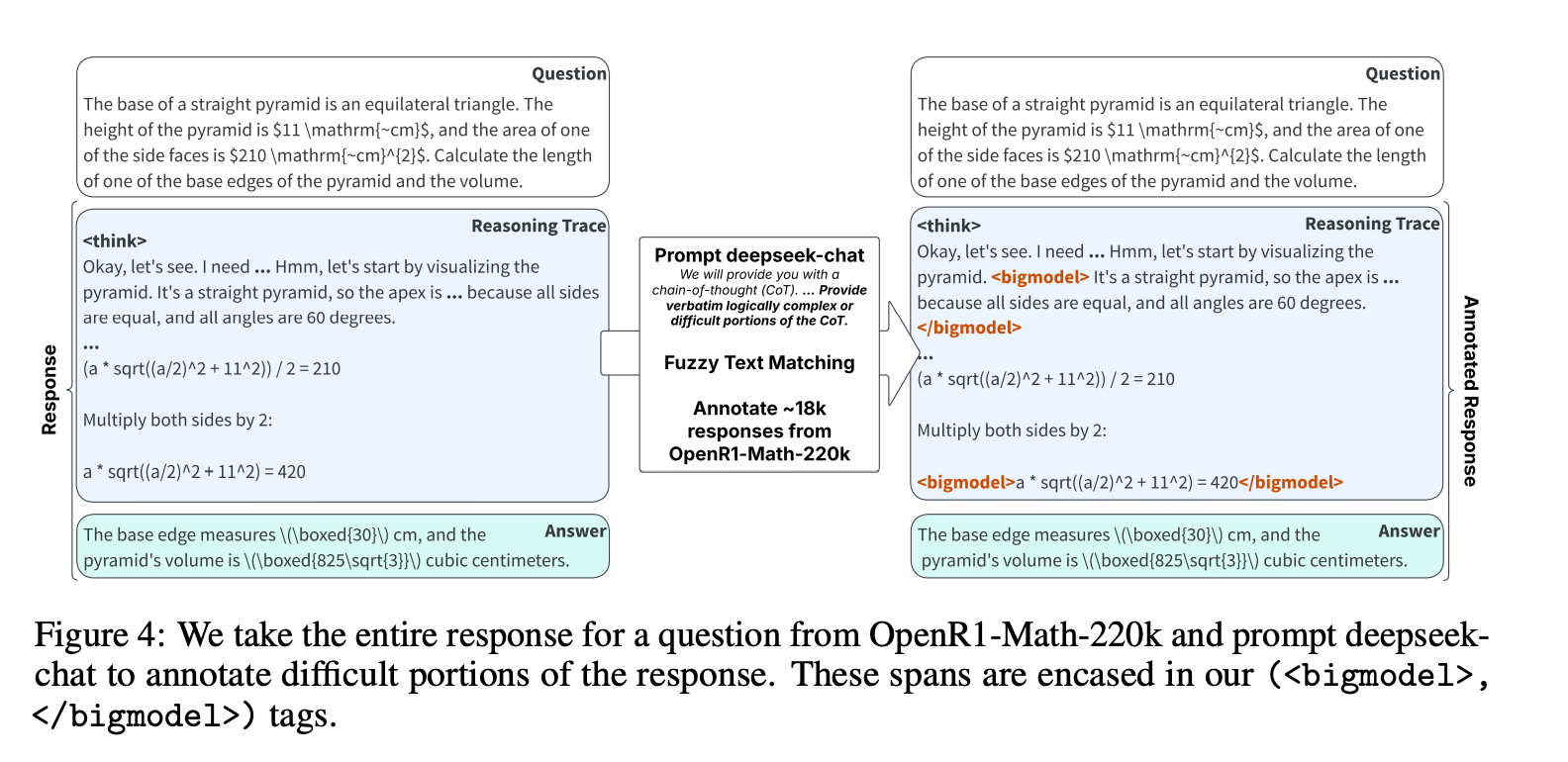
- 数据生成和训练设置:使用DeepSeek-R1-Distill-Qwen-1.5B作为小模型,DeepSeek-R1-Distill-Qwen-32B作为大模型。通过模糊文本匹配和特殊标记包裹困难部分,生成训练数据集。
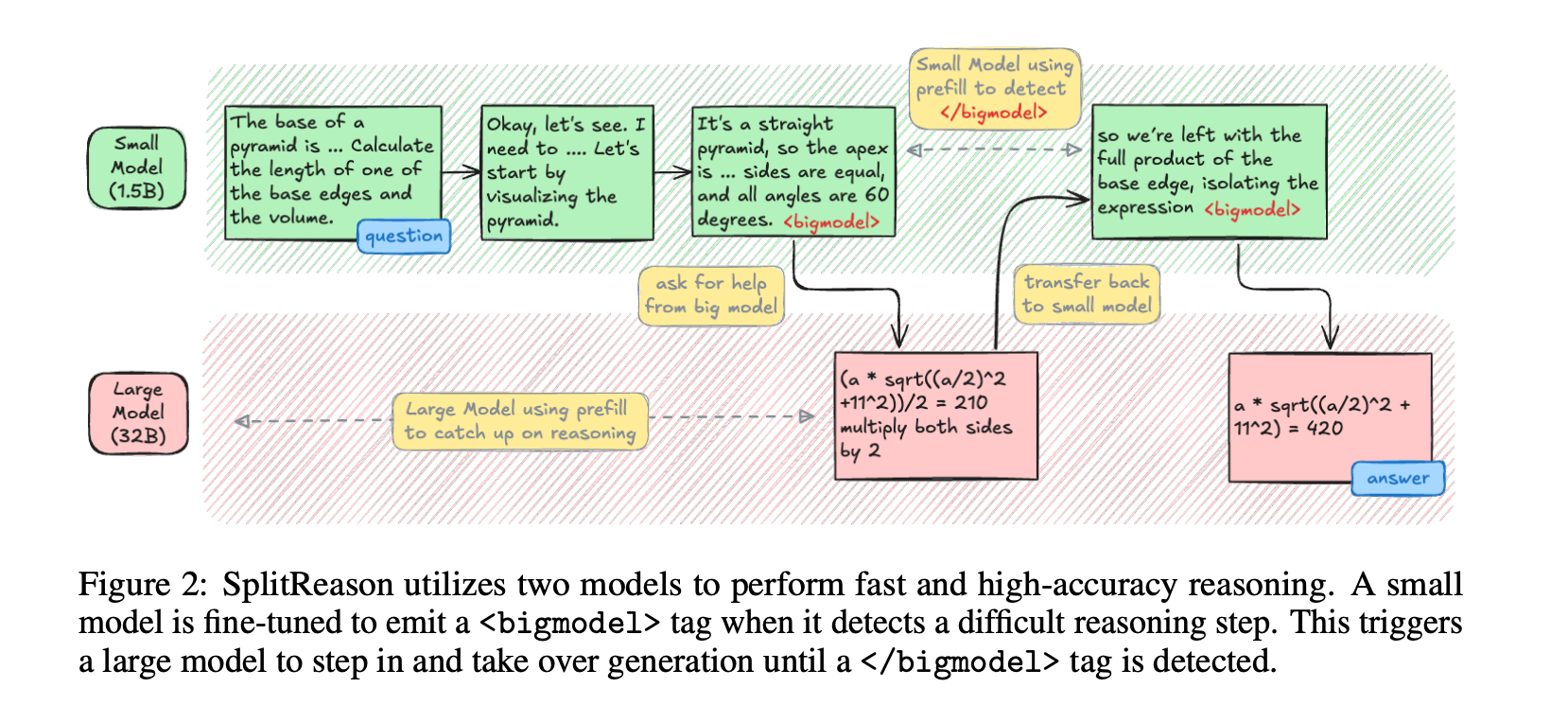
3.2 推理阶段
- 引入新的控制标记<bigmodel>...</bigmodel>,在推理过程中智能地将token生成卸载到大型模型。小模型在解码过程中,如果遇到困难的部分,会生成标记<bigmodel>,触发大型模型接管生成,直到检测到标记</bigmodel>。
3.3 训练阶段
- 监督微调(SFT):从OpenR1-Math220k数据集中采样18k推理步骤,并使用DeepSeek-R1 671B模型标注困难部分。这些标注部分被包裹在
<bigmodel>和</bigmodel>标记之间。然后对小模型进行微调,使其学会在推理过程中插入这些特殊标记。 - GRPO微调:在SFT之后,使用GRPO对模型进行微调,以调节和鼓励标记<bigmodel>的生成,平衡下游任务的准确性与整体生成延迟。
- 奖励函数由三部分组成,分别衡量准确性、格式正确性和切换行为的合理性。准确性奖励衡量最终答案是否与真实答案匹配;格式奖励检查整个响应是否遵循
<think>和</think>以及<answer>和</answer>的结构;切换奖励鼓励适度的卸载行为。
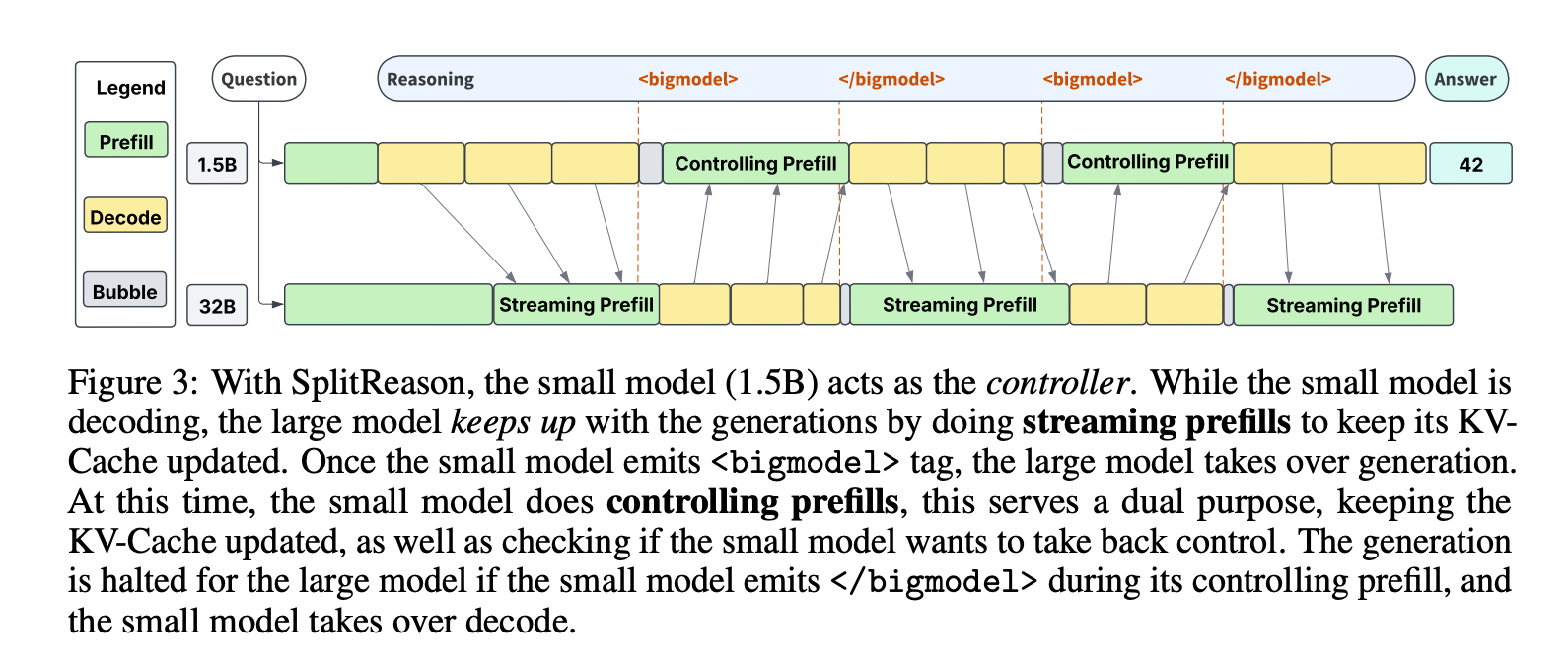
四、实验结果
4.1 推理切换行为
-
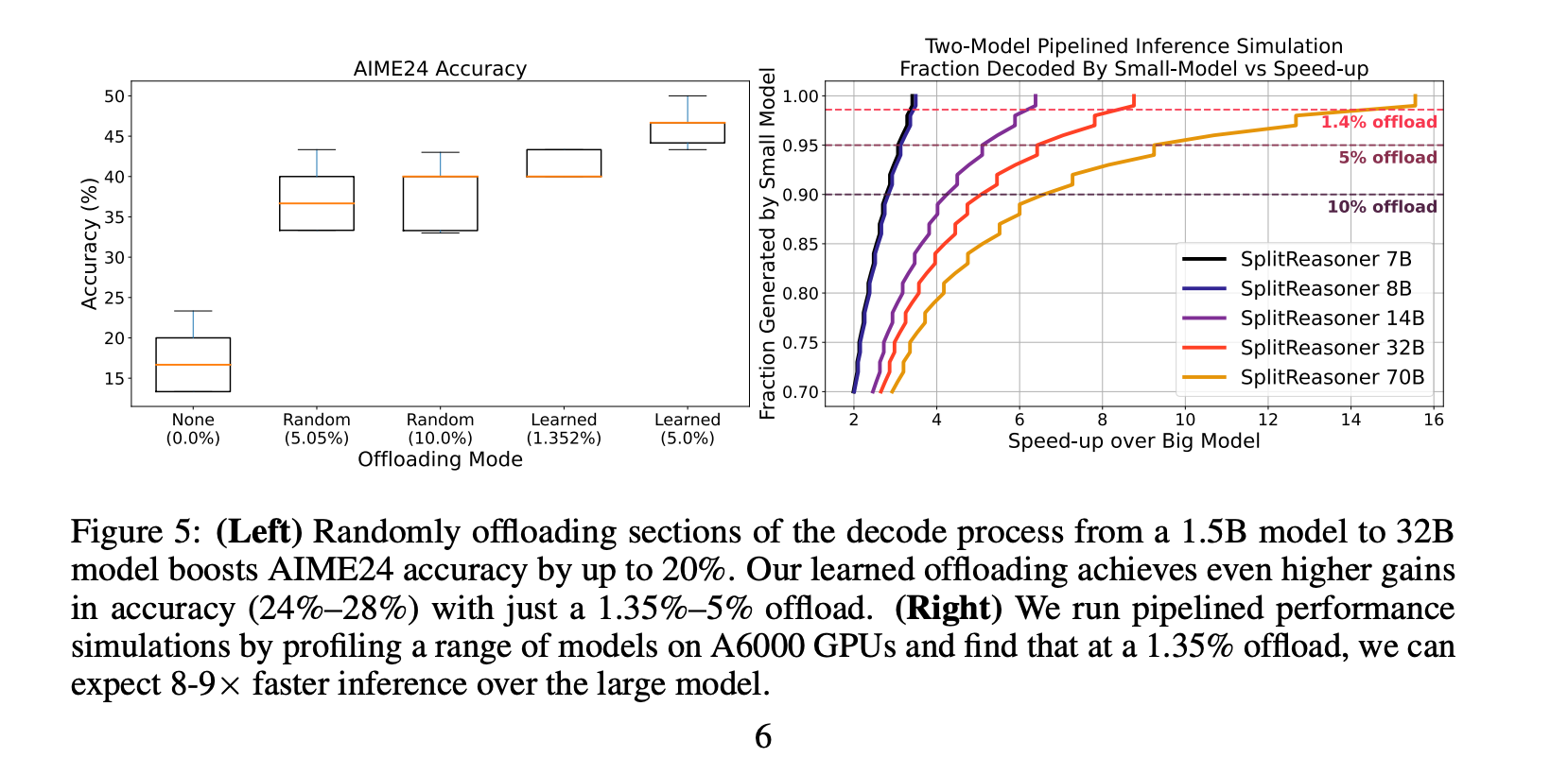
随机切换:随机将5-10%的解码步骤切换到32B模型,可以将AIME24的准确性提高20%。
-
学习切换:通过学习确定何时切换,仅1.35%的中位卸载量就超过了10%随机卸载的准确性,提高了24%。5%的卸载量进一步提高了准确性,比基线模型提高了28%。
-
性能模拟:在1.35%的卸载量下,SplitReason可以比单独运行32B模型快8-9倍。
4.2 跨模型大小的卸载
-
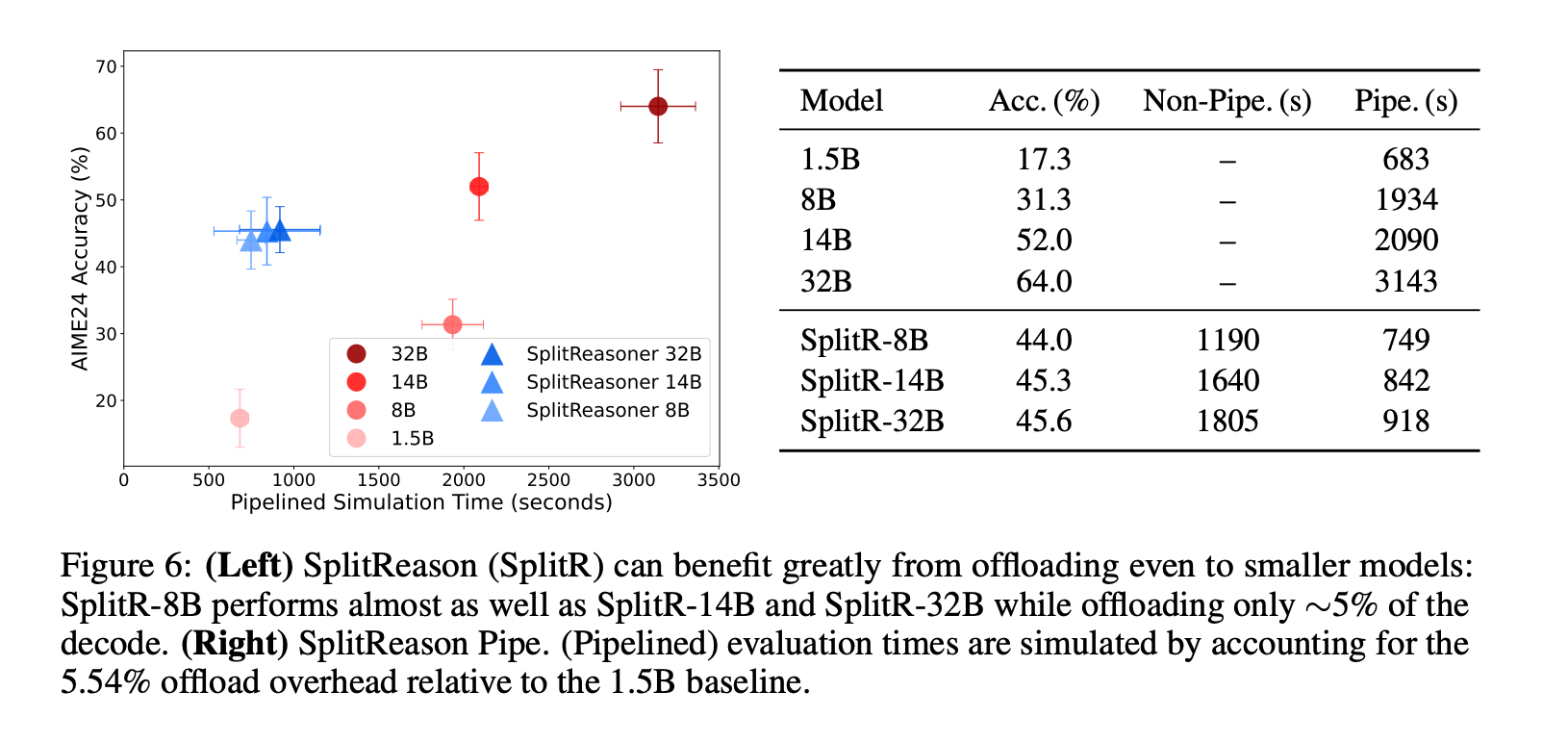
不同大模型:使用不同大小的大模型(8B、14B、32B)进行卸载,发现卸载到最小的大模型(8B)已经可以将准确性从17.3%提高到44%,随着模型大小的增加,准确性继续提高。
-
流水线执行:在流水线执行设置下,SplitReason-32B提高了28%的准确性,同时仅略微增加了运行时间,显著优于使用8B或14B模型。
4.3 数据集分布和诱导卸载
-
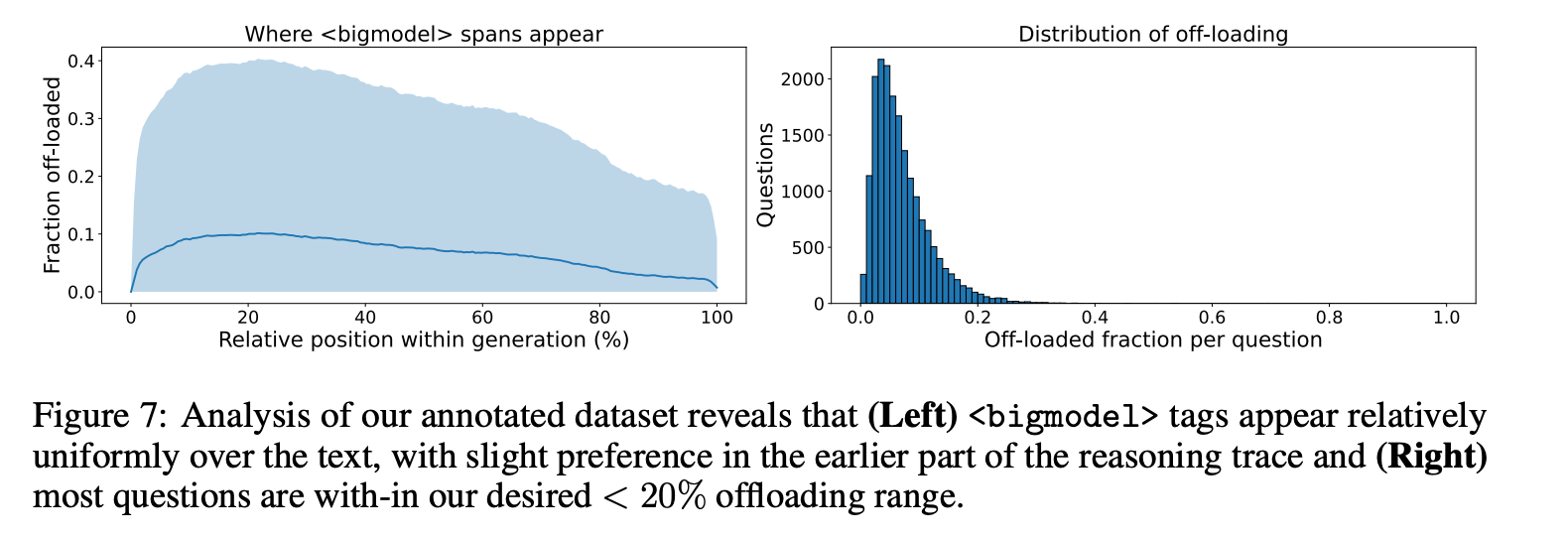
标注数据集:分析了18,500个推理步骤的标注数据集,发现
<bigmodel>标记倾向于出现在推理过程的早期部分,且大多数问题的卸载量在20%以下。
-
随机样本:随机采样10个问题,发现经过SFT和GRPO微调后,模型能够有效地进行卸载,遵循格式和频率要求。
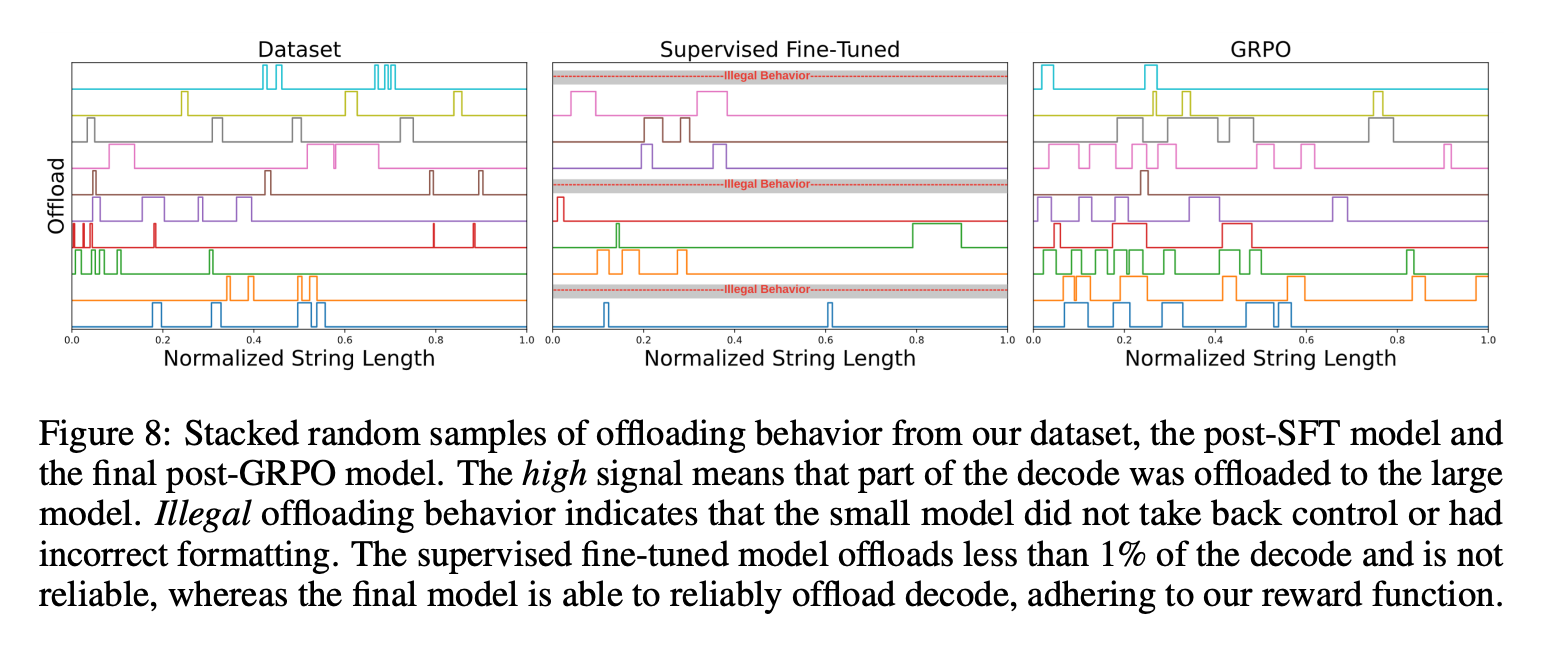
4.4 性能模拟
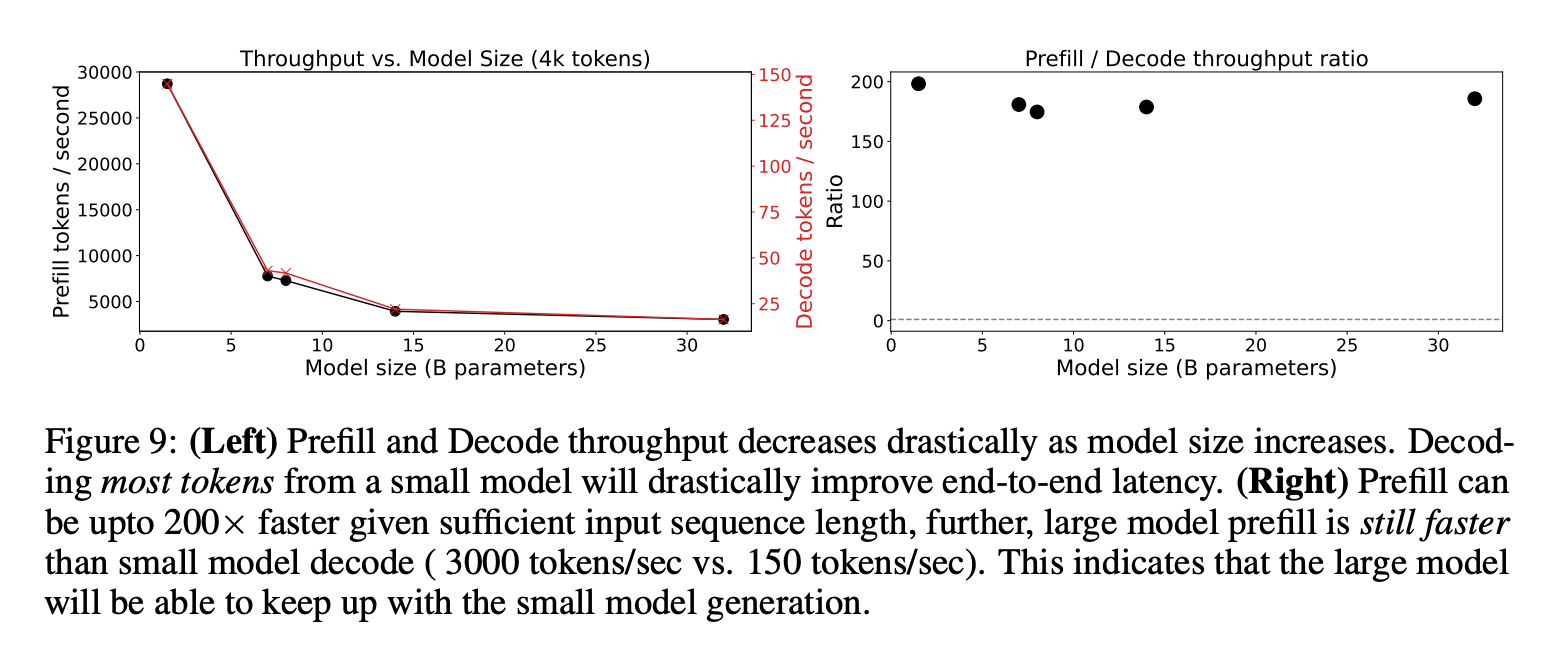
-
吞吐量:小模型(1.5B)的解码吞吐量比大模型(32B)快8倍以上,但大模型的预填充(prefill)速度仍然比小模型的解码快,表明流水线推理流程是可行的。
-
模拟结果:通过模拟流水线执行,预计在1.35%的卸载量下,SplitReason可以比单独运行32B模型快8-9倍。