.net网站开发后编译怎么创造自己的网站
论文来自 《Visual Instruction Tuning,2023, NeurIPS.》
1. 概述
LLaVA是视觉大模型,涉及主流大模型微调方法,包括:
-
通过超大参数模型(GPT-4)生成<微调数据>(这里是图文跨模态数据)
-
两阶段微调大模型(原文为Vicuna-7B,即llama2,相比GPT-4约小10倍)
- 第一阶段实现<视觉-语言特征对齐>
- 第二阶段将<图像融合进上下文>
-
两阶段微调对应不同的 <数据集> 及 <微调数据结构>
2. GPT-4的用途
这里GPT-4有以下三个用途:
2.1 微调数据集生成
- 多模态指令数据(无图像输入,仅用图像的描述信息)
向 GPT-4 输入 caption + box(位置坐标和物体描述) ,这些“符号化表示”作为输入,
- 产出问题-回答对,涉及三类问题- 会话型(Conversation)- 详细描述(Detailed Description)- 复杂推理(Complex Reasoning)
具体如下:

2.2 模型评估
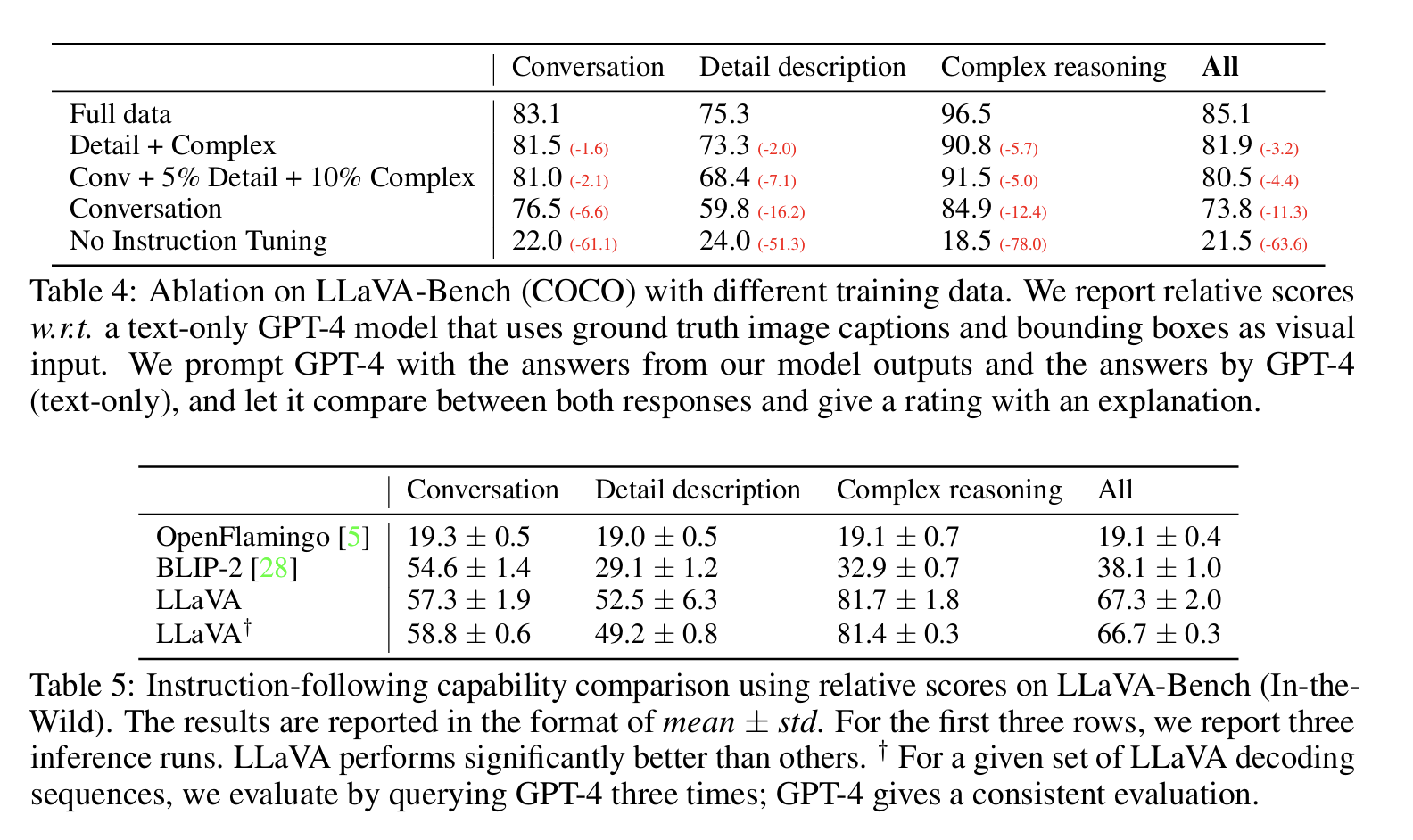
用 GPT-4 来对比 LLaVA 和其他模型的输出质量, 即“主观题”的 AI 判卷人。
在 Table 4 和 Table 5 中,作者让 GPT-4 读图像描述、问题和不同模型的回答,然后打分(1-10 分),评估, helpfulness(有用性),
relevance(相关性), accuracy(准确性), level of detail(细节程度)
2.3 协同工作(下游任务)
- 方式 1:GPT-4 回答为主(complement)- 如果 GPT-4 因缺图而拒答,那么就用 LLaVA 的答案;- 即 LLaVA 补充回答图像理解部分,GPT-4 主导,最终准确率:90.97%
- 方式 2:GPT-4 仲裁选择(judge)- 当 GPT-4 和 LLaVA 答案不一致时,再请 GPT-4 看“两个答案 + 问题”进行比较和仲裁;- 这类似 chain-of-thought + ensemble 的思路,利用 GPT-4 的强语言推理能力去选最靠谱答案,最终准确率:92.53%(比 SOTA 还高)
3. 微调阶段
3.1 基本方法
给定图像 X v X_v Xv 和语言指令 X instruct X_{\text{instruct}} Xinstruct,模型的训练目标是最大化 Assistant 回答 X a X_a Xa 的概率:
p ( X a ∣ X v , X instruct ) = ∏ i = 1 L p θ ( x i ∣ X v , X instruct , < i , X a , < i ) p(X_a \mid X_v, X_{\text{instruct}}) = \prod_{i=1}^{L} p_{\theta}(x_i \mid X_v, X_{\text{instruct}}, <i, X_a,<i) p(Xa∣Xv,Xinstruct)=∏i=1Lpθ(xi∣Xv,Xinstruct,<i,Xa,<i)
其中 x i x_i xi 表示第 i i i 个目标 token, θ \theta θ 是模型参数, L L L 是回答的长度, < i <i <i 表示前缀上下文。
- 训练样本:
Image: <img_feature>
Human: What is the man doing? ###
Assistant: He is ironing clothes on top of a moving car. ###
- 输入:
[<img_tokens>] Human: What is the man doing? ###
Assistant:
- 自回归逐步输出预测:
He → is → ironing → clothes → ...
3.2 计算过程
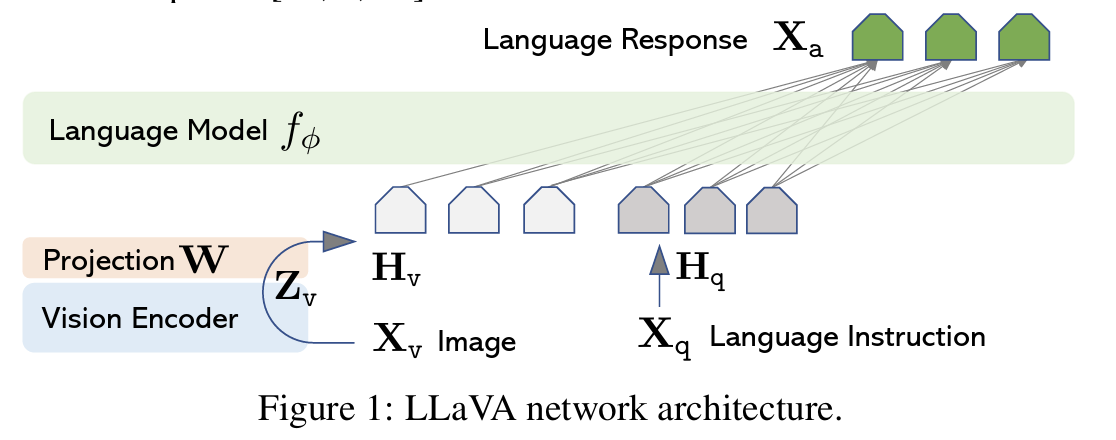
LLaVA 使用 CLIP 作为视觉编码器,将图像 X v X_v Xv 编码为视觉特征 Z v Z_v Zv,然后通过一个线性映射层投影到语言模型词嵌入空间:
H v = W ⋅ Z v H_v = W \cdot Z_v Hv=W⋅Zv
其中:
- X v X_v Xv 表示输入图像;
- Z v ∈ R N × D Z_v \in \mathbb{R}^{N \times D} Zv∈RN×D 是视觉编码器输出的图像 patch 特征;
- W ∈ R D × d W \in \mathbb{R}^{D \times d} W∈RD×d 是可学习的线性映射矩阵;
- H v ∈ R N × d H_v \in \mathbb{R}^{N \times d} Hv∈RN×d 是与语言模型词向量同维度的视觉 token 表达。
最终将 H v H_v Hv 拼接到语言指令 token 的前面,送入语言模型进行自回归训练(token-level cross-entropy loss)。
3.3 两阶段微调
- 阶段一:预训练阶段(视觉-语言特征对齐)
只训练投影层W, 冻结视觉编码器和语言模型, 对齐视觉特征与语言模型词嵌入空间。
- 数据集:Filtered CC3M(Conceptual Captions 3M) + naive QA
- 筛选后规模:595K 图文对(称为 CC-595K)
- 构造方式:- 每对 image-caption 构造为:
Human: What does this image show? ###
Assistant: <caption> ###
- 阶段二:端到端微调阶段
微调语言模型 + 投影层,训练模型执行多模态指令任务。
- 数据集:GPT-4 生成的多模态指令微调数据集,称为 LLaVA-Instruct-158K
- 规模:共 158,000 条样本,来自 COCO 等图文数据集,分为三类:- Conversation(58K)- Detailed Description(23K)- Complex Reasoning(77K)
- 构造方式:- 图像 → caption 和 box 表示(符号化)- 使用 GPT-4 生成合理指令 + 回答
Human: What is the man doing in the picture? ###
Assistant: He is ironing clothes on the roof of a car. ###
除了上面两个阶段,论文还单独用 ScienceQA 做了一个下游任务训练:
- 数据集:ScienceQA
- 包含 21K 多模态选择题
- 文本 + 图像 + 多项选择题
- 训练目标:生成回答 + 解释(chain of thought + 答案选择)
4.效果展示
4.1 异常图像推理
- 图像内容(根据描述还原):
这张图片是一个真实生活中很“怪”的场景:
* 一个男人站在一辆 黄色 SUV / 出租车 的车顶上;
* 他正在用熨斗熨衣服;
* 旁边有便携梯子、街道、消防栓、路人、其他车;
* 看起来像是在大街上搞行为艺术或者恶搞照片。
- 问题(prompt):What is unusual about this image?
这类问题属于视觉理解中的 异常检测/常识推理(visual oddity + reasoning),
模型不能只是说“一个人在熨衣服”——这在图像中是表面动作;
而是要意识到 “在车顶熨衣服”是不寻常的、危险的、不合理的,这是“异常”。
原文展示如图:
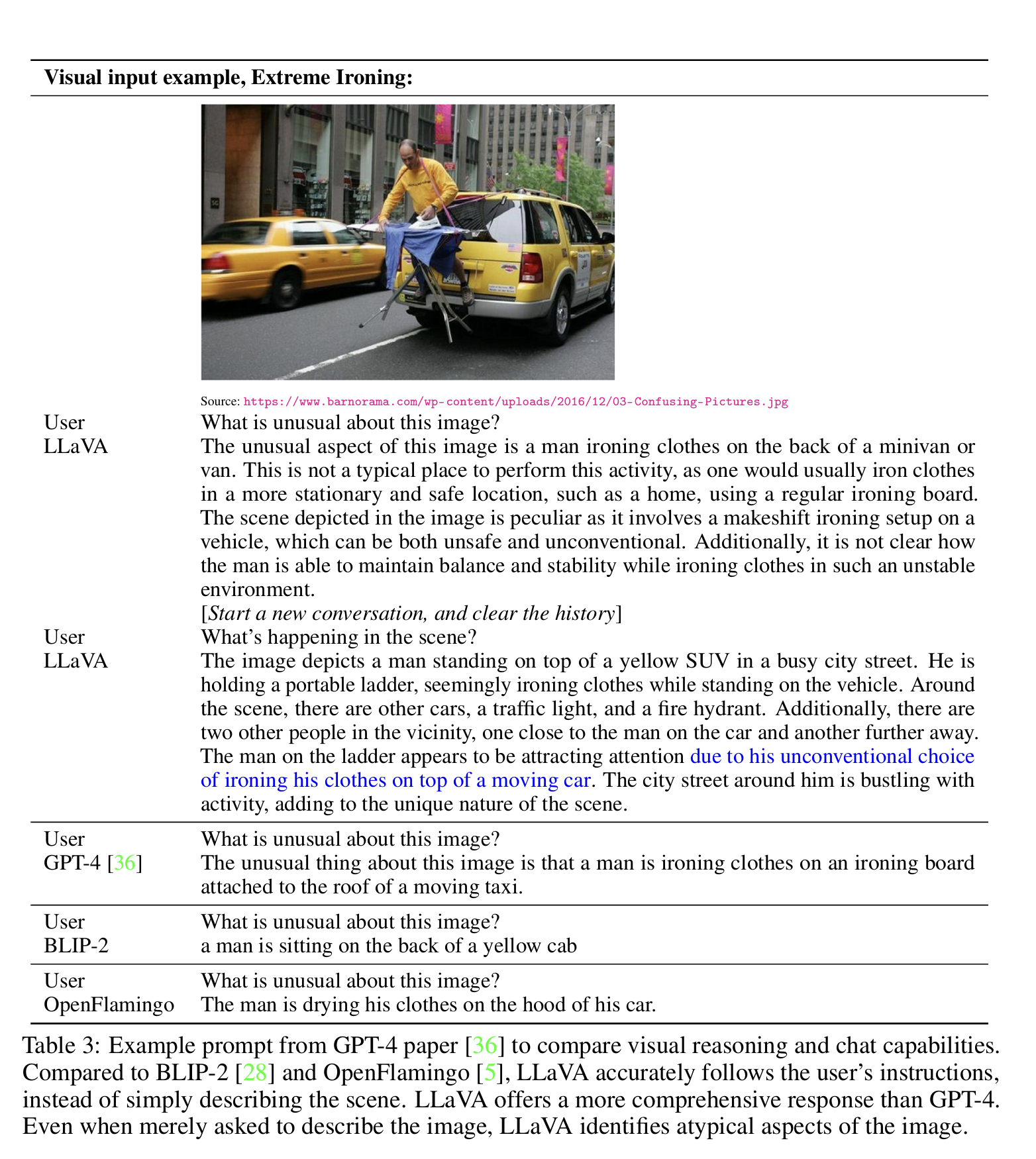
- 模型 | 回答摘要 | 分析
GPT-4 (text-only) | 熨衣服是在一辆行驶中的出租车上进行的,这很奇怪 | ✅ 识别到了“移动中的车” + 熨衣服不匹配
BLIP-2 | 一个男人坐在黄色出租车后面 | ❌ 只是描述了一部分画面,没有理解“不寻常”之处
OpenFlamingo | 男人在车引擎盖上晾衣服 | ❌ 误解了行为(不是晾,而是熨)+ 场景错误
LLaVA | 熨衣服 + 不寻常地点 + 危险性 + 不稳定 + 行为非常规 | ✅ ✅ ✅ 全部命中,且结构清晰、有推理链
4.2 图像标注理解
涉及2个问题,并将回答与答案(详细标注)对比,检测模型对图像的细节推理能力。
标注涉及:
- 物体种类(strawberries、milk、yogurt) | 检查模型是否真的识别了所有关键元素
- 品牌名(Fage、blueberry flavor) | 检查模型是否具有 OCR/品牌识别能力
- 相对位置(左侧、后排、顶部) | 检查模型是否能理解空间关系(这在导航类任务中特别重要)
- 组合逻辑(草莓 vs 草莓味酸奶) | 检查模型是否具备正确的语义组合和否定推理能力
如图:

系统把 模型的回答 和 人工标注 中对应的细节进行比对;可以手动比对,也可以借助 GPT-4 做智能评分(论文的方法):
GPT-4 作为“裁判”,读取模型回答 + 标注 → 打出 helpfulness(有用性), relevance(相关性), accuracy(准确性), level of detail(细节程度) 等分数。
5.总结与后续
- 微调《数据集》来自通用大模型 (比如ChatGPT的格式化输出)。
- 微调《中小规模的参数模型》 3B / 7B / 35B 以适配下游任务
(比如llama2-b,这里是图像理解任务)。 - 《跨模态图像理解》需要一个视觉编码器(如CLIP),并将其输出特征与大模型特征对齐