西安做网站培训百度搜索资源平台token
一.有状态转化操作
1. UpdateStateByKey
UpdateStateByKey 原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加 wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的 DStream,其内部的 RDD 序列是由每个时间区间对应的(键,状态)对组成的。
updateStateByKey 操作使得我们可以在用新信息进行更新时保持任意的状态。为使用这个功能,需要做下面两步:
1. 定义状态,状态可以是一个任意的数据类型。
2. 定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新。
使用 updateStateByKey 需要对检查点目录进行配置,会使用检查点来保存状态。
val updateFunc = (values:Seq[Int],state:Option[Int])=>{
val currentCount = values.foldLeft(0)(_+_)
val previousCount = state.getOrElse(0)
Some(currentCount+previousCount)
}
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("update")
val ssc = new StreamingContext(sparkConf,Seconds(5))
ssc.checkpoint("./ck")
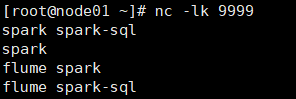
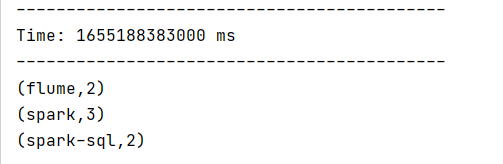
val lines = ssc.socketTextStream("node01",9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map((_,1))
val stateDStream = pairs.updateStateByKey[Int](updateFunc)
stateDStream.print()
ssc.start()
ssc.awaitTermination()
2.WindowOperations
Window Operations 可以设置窗口的大小和滑动窗口的间隔来动态的获取当前 Steaming 的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
窗口时长:计算内容的时间范围;
滑动步长:隔多久触发一次计算。
注意:这两者都必须为采集周期大小的整数倍。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("window")
val ssc = new StreamingContext(sparkConf,Seconds(3))
ssc.checkpoint("./ck")
val lines = ssc.socketTextStream("node01",9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map((_,1))
val wordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int)=>(a+b),Seconds(12),Seconds(6))
wordCounts.print()
ssc.start()
ssc.awaitTermination()
3.DStream输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。与 RDD 中的惰性求值类似,如果一个 DStream 及其派生出的 DStream 都没有被执行输出操作,那么这些 DStream 就都不会被求值。如果 StreamingContext 中没有设定输出操作,整个 context 就都不会启动。
输出操作如下:
print():在运行流程序的驱动结点上打印 DStream 中每一批次数据的最开始 10 个元素。这用于开发和调试。
saveAsTextFiles(prefix, [suffix]):以 text 文件形式存储这个 DStream 的内容。每一批次的存储文件名基于参数中的 prefix 和 suffix。”prefix-Time_IN_MS[.suffix]”。
saveAsObjectFiles(prefix, [suffix]):以 Java 对象序列化的方式将 Stream 中的数据保存为SequenceFiles . 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]".
saveAsHadoopFiles(prefix, [suffix]):将 Stream 中的数据保存为 Hadoop files. 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]"。
foreachRDD(func):这是最通用的输出操作,即将函数 func 用于产生于 stream 的每一个RDD。其中参数传入的函数 func 应该实现将每一个 RDD 中数据推送到外部系统,如将
RDD 存入文件或者通过网络将其写入数据库。
通用的输出操作 foreachRDD(),它用来对 DStream 中的 RDD 运行任意计算。这和 transform() 有些类似,都可以让我们访问任意 RDD。在 foreachRDD()中,可以重用我们在 Spark 中实现的所有行动操作。比如,常见的用例之一是把数据写到诸如 MySQL 的外部数据库中。
注意:
1) 连接不能写在 driver 层面(序列化)
2) 如果写在 foreach 则每个 RDD 中的每一条数据都创建,得不偿失;
3) 增加 foreachPartition,在分区创建(获取)。