做藏头诗的网站seo快速优化文章排名
R1-Searcher++新突破!强化学习如何赋能大模型动态知识获取?
大语言模型(LLM)虽强大却易因静态知识产生幻觉,检索增强生成(RAG)技术成破局关键。本文将解读R1-Searcher++框架,看其如何通过两阶段训练策略,让LLM智能融合内外知识,实现高效推理,为AI知识获取开辟新路径。
论文标题
R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning
来源
arXiv:2505.17005v1 [cs.CL] + https://arxiv.org/abs/2505.17005
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
大语言模型(LLMs)虽能凭借参数中编码的信息展现出色推理能力,但对静态内部知识的依赖使其存在明显局限,容易产生幻觉,在开放任务中表现不佳。因此,让 LLM 在推理困惑时获取外部信息以实现更审慎推理至关重要。为解决此问题,大量研究聚焦于用外部信息源增强 LLM(即 RAG),早期方法强调特定提示策略,后续研究通过监督微调将此能力提炼到更小 LLM 中,但基于 SFT 的提炼会使模型记忆解决方案路径,限制其在新场景的泛化能力。
研究问题
-
过度依赖外部检索:传统RAG方法或基于强化学习的检索模型,训练后常过度依赖外部搜索引擎,忽略模型自身内部知识的利用。
-
知识利用效率低:模型未能有效在内部知识和外部检索间动态切换,导致检索次数多、推理效率低。
-
知识积累能力弱:缺乏对检索到的外部知识的记忆机制,无法将新信息转化为内部知识,难以持续提升推理能力。
主要贡献
-
两阶段训练框架:提出R1-Searcher++,通过SFT冷启动阶段让模型初步学习格式,再用强化学习(RL)实现动态知识获取,使LLM能自适应利用内外知识,这与现有RAG方法显著不同。
-
动态知识管理机制:设计奖励机制鼓励模型利用内部知识,引入记忆机制将检索信息转化为内部知识,实现知识的动态积累与高效利用,提升推理效率。
-
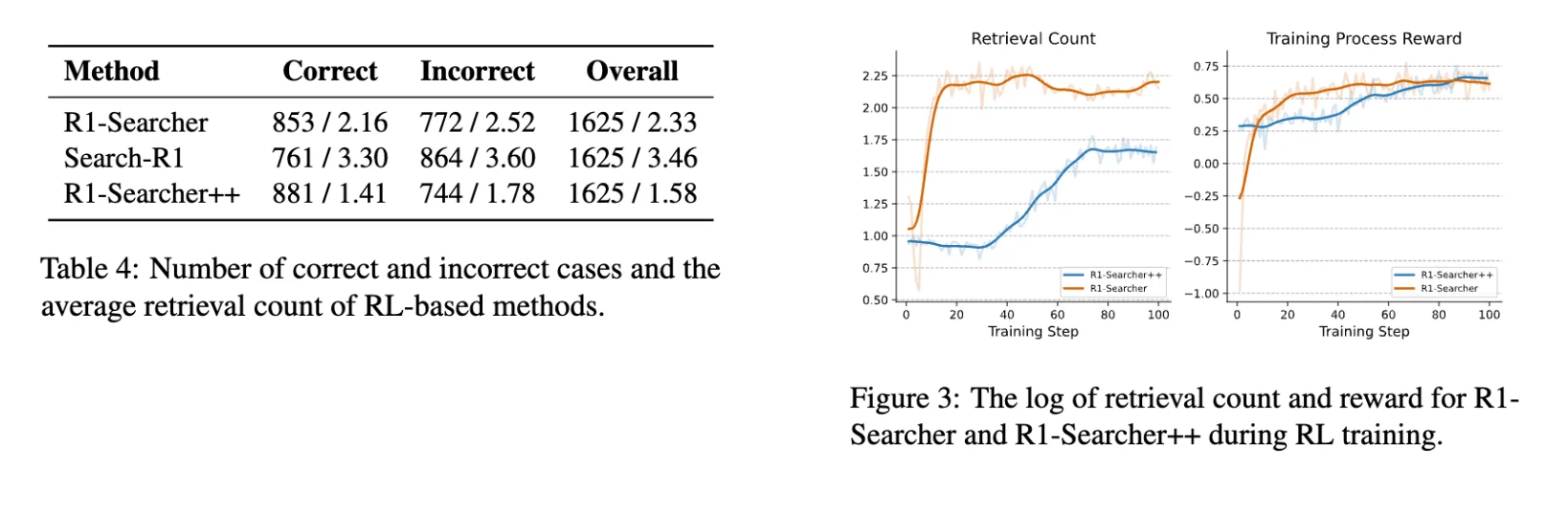
性能与效率双提升:实验表明,该方法在多跳问答任务上优于现有RAG和推理方法,相比基于RL的基线模型,检索次数减少42.9%,实现性能与效率的平衡。
方法论精要
1. 核心框架: R1-Searcher++采用两阶段训练策略。第一阶段为SFT冷启动,通过拒绝采样收集符合格式要求的数据,对模型进行初步格式学习;第二阶段为RL动态知识获取,利用基于结果的RL训练模型,结合内部知识利用鼓励和外部知识记忆机制,引导模型动态获取知识。
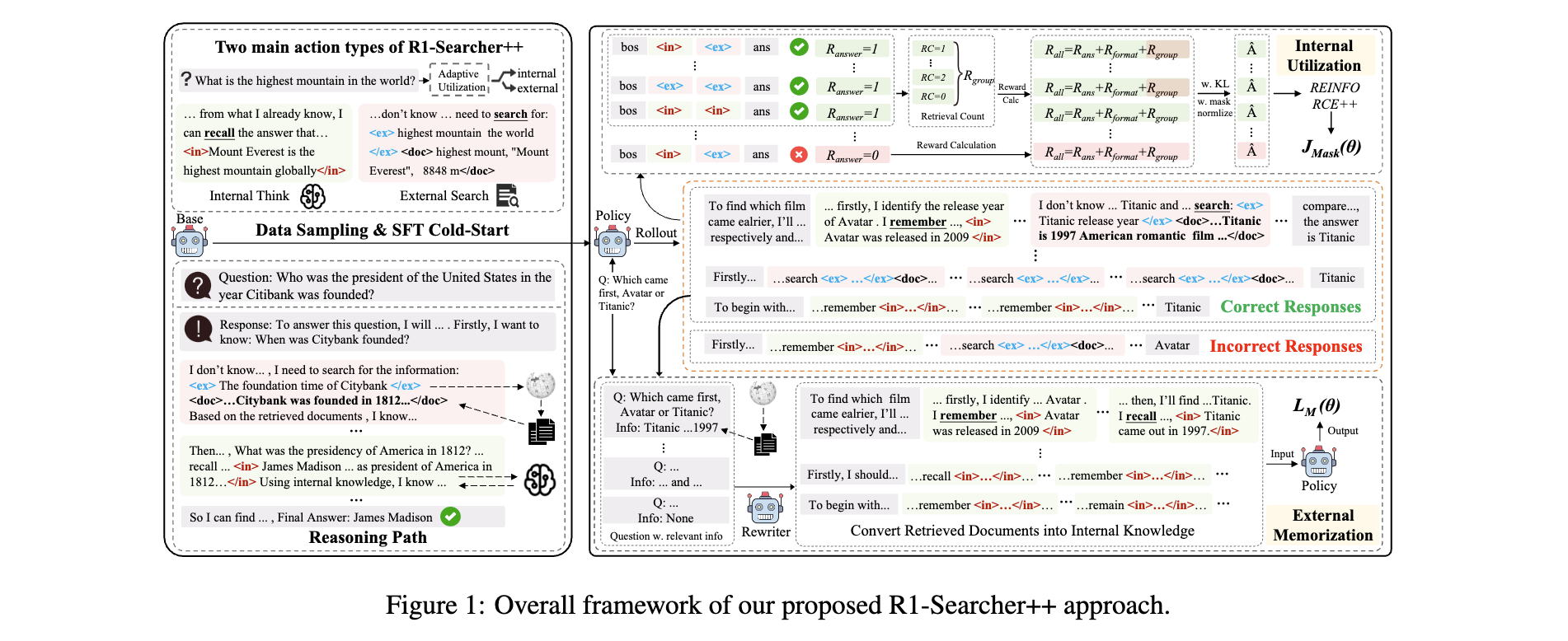
2. 关键参数设计原理:
SFT阶段:使用拒绝采样,仅保留包含适当和标签的正确响应,目标函数如下,其中 M i M_{i} Mi用于屏蔽外部文档token:
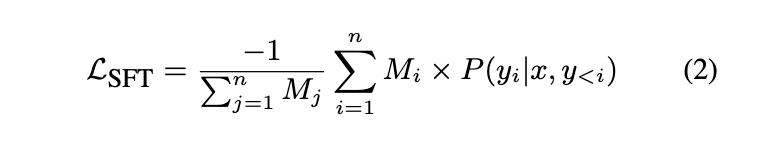
RL阶段:奖励函数由格式奖励、答案奖励和组奖励组成。格式奖励确保响应格式正确,答案奖励采用覆盖精确匹配(CEM) metric并限制答案在10字内,组奖励通过计算同一问题正确响应中检索器调用次数的标准差,鼓励模型减少对外部检索的依赖,最终奖励 R ( q , o i ) = R f o r m a t ( q , o i ) + R a n s w e r ( q , o i ) + R g r o u p ( q , o i ) R(q, o_{i})=R_{format }\left(q, o_{i}\right)+R_{answer }\left(q, o_{i}\right)+R_{group }\left(q, o_{i}\right) R(q,oi)=Rformat(q,oi)+Ranswer(q,oi)+Rgroup(q,oi)。

3. 创新性技术组合: 将SFT与RL结合,在RL中融入内部知识利用鼓励和外部知识记忆机制。记忆机制通过训练单独的重写模型,将检索到的文档转化为模型可内部化的推理路径,损失函数为 L ( θ ) = − J M a s k ( θ ) + μ ∗ L M ( θ ) \mathcal{L}(\theta)=-\mathcal{J}{Mask }(\theta)+\mu * \mathcal{L}{M}(\theta) L(θ)=−JMask(θ)+μ∗LM(θ),其中 μ \mu μ为预定义系数,平衡策略模型训练和知识记忆。
4. 实验验证方式: 使用HotpotQA、2WikiMultiHopQA、Musique和Bamboogle四个多跳数据集,前两个为域内数据集,后两个为域外数据集,评估指标为F1-score和LLM-as-Judge(LasJ)。对比基线包括Naive Generation、Standard RAG、SuRe、Selective-Context、Adaptive-RAG、CRPlanner、RAG-CoT方法和RAG-RL方法等,验证模型在不同场景下的性能。
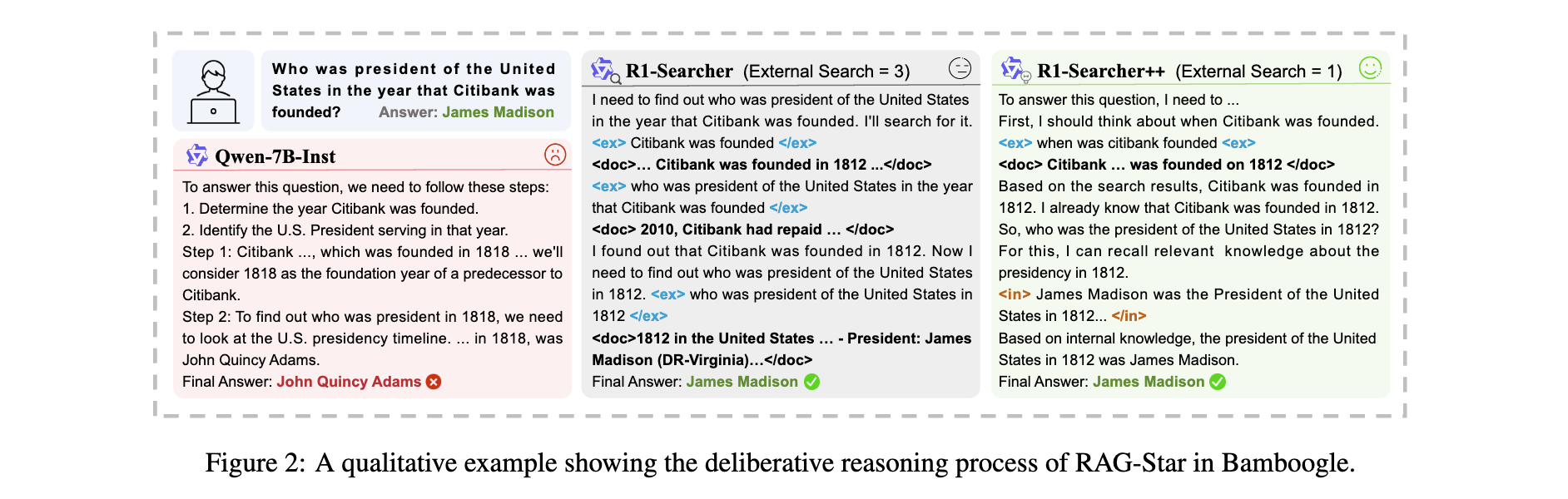
实验洞察
1. 性能优势: 在整体测试集上,R1-Searcher++相比最佳基于RL的方法R1-Searcher提升4.3%;在HotpotQA上,LasJ指标达64.2%,优于R1-Searcher的62.2%;在Bamboogle上,LasJ指标为59.2%,显著高于其他基线。
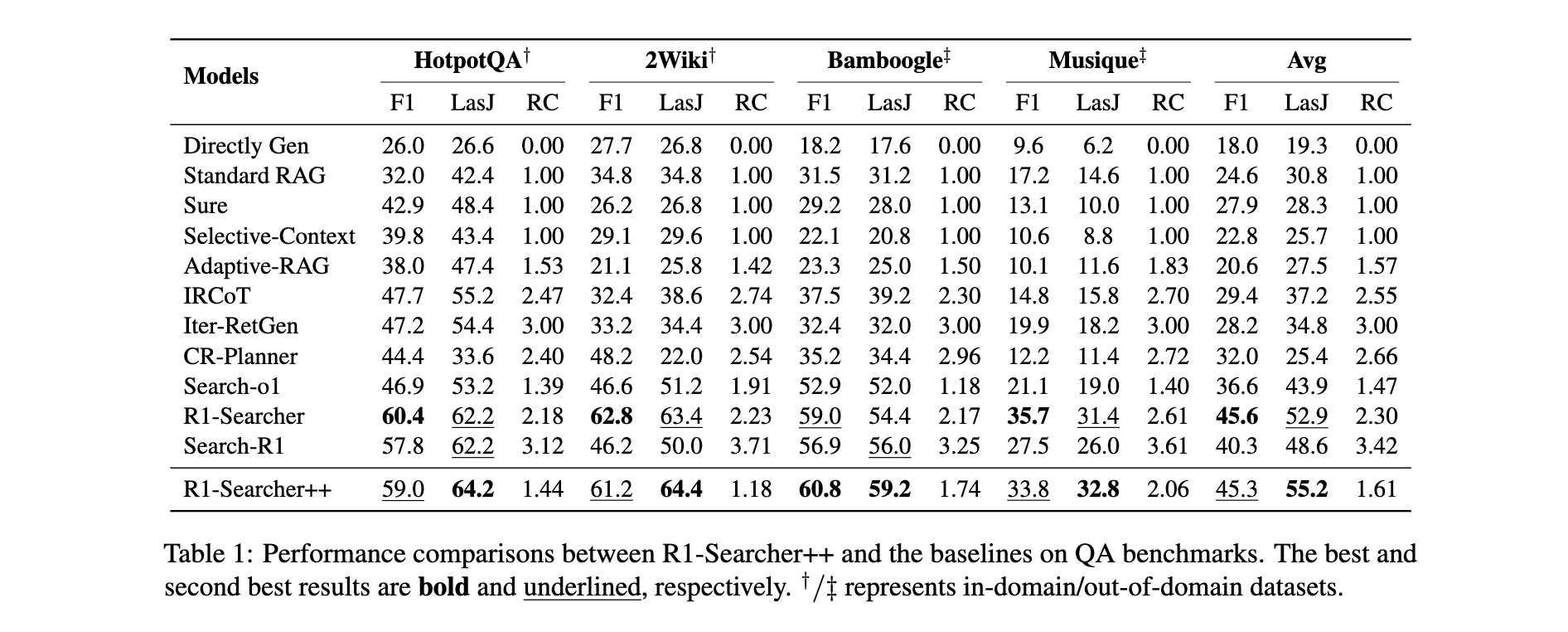
2. 效率突破: 相比基于RL的方法,检索次数大幅减少,平均检索次数比R1-Searcher减少30.0%,比Search-R1减少52.9%,有效降低推理成本。
3. 消融研究: 各关键组件均对模型性能有重要贡献。移除SFT冷启动阶段,Bamboogle上LasJ指标从59.2%降至56.8%;移除RL阶段,性能大幅下降,F1指标从60.8%降至47.4%;移除组奖励或记忆机制,性能也有不同程度下降,如移除组奖励,Musique上LasJ指标从32.8%降至32.4%,验证了各模块的有效性。