wordpress中文企业主题 下载地址整站seo教程
起因, 目的:
- ✅下载单个视频,完成。
- ✅ 获取某用户的视频列表,完成。
- 剩下的就是, 根据视频列表,逐个下载视频,我没做,没意思。
- 获取视频的评论,以后再说。
关键点记录:
1. 对一个视频的直接 url,
- ssig 是变动的。 我估计是有时效的。
- 使用 requests 来下载单独视频,还是可行的。
2. 获取视频播放列表
- 不能直接使用 seleinum 库, 因为网页没有显示,只能一个一个点击。 会很慢.
- 获取视频播放列表,可以访问 api: https://weibo.com/ajax/profile/getWaterFallContent?uid=5653796775&cursor=4436755690237089
- cursor 参数是从 0 开始,而且相应的json 中,会给出 “next_cursor”: “4560020807617171”
- 实际情况是,使用 firefox 浏览器查看 json 相应,很方便查看 json 的结构,很清晰。
3. 爬取微博,不建议使用 requests 库, 理由是
- 静态页面和动态页面的区别。
- 中间有个 js 验证!
1. 使用 requests,单独下载一个微博视频, 成功。
# -*- coding: UTF-8 -*-
import requests# 1. 假如知道了视频的直接 url, 那么直接下载视频,成功!
# 2. 知道了视频的 主页面,然后找到视频的 url, 再下载。失败! 因为中间涉及 js !def make_headers():headers = {'Accept-Encoding': '*/*','Referer': 'https://weibo.com/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36',}return headersclass PlayAround:def __init__(self):self.headers = make_headers()self.session = requests.Session()self.fail = []# 单纯的下载视频。已经完成。能实现。def download_video(self, video_url, video_name):resp = self.session.get(video_url, headers=self.headers, allow_redirects=False)if resp.status_code == 200:with open(f"{video_name}.mp4", "wb") as f:f.write(resp.content)if __name__ == '__main__':p = PlayAround()# 视频的直接链接mp4_url = "https://f.video.weibocdn.com/o0/QSQkAf0wlx08cD50PfXa01041201cfbq0E010.mp4?label=mp4_1080p&template=1080x1920.24.0&media_id=5002705307893807&tp=8x8A3El:YTkl0eM8&us=0&ori=1&bf=4&ot=v&lp=00002D9dZv&ps=mZ6WB&uid=6Ak7kf&ab=13038-g1,,8012-g2,3601-g32,3601-g31,8013-g0,3601-g29,3601-g39,3601-g19,3601-g36,3601-g27,12739-g1,3601-g38,3601-g37&Expires=1744548301&ssig=jh4Js32Fx1&KID=unistore,video"video_name = "赵露思的微博的微博视频223"p.download_video(mp4_url, video_name)
2. 使用 selenuim + cookies 登录微博
实际上,修改 cookies, 可以登录任意网站。
import time
import random
import json
import pickle
from selenium import webdriver
from selenium.webdriver.chrome.options import Options"""
此文件, 使用 selenium + cookies, 登录微博 1. 任意网站,从插件 editThisCookie 导出所有的 cookies , 复制到 cookies.json 文件
2. 运行此文件的过程中,会自动生成 pickle 文件
3. 然后模拟登录,刷新页面,即可登录成功
4. 继续 selenium 的其他功能如果报错,那么需要删除 cookies 中的 sameSite 属性, 并重新生成 pickle 文件
"""URL = "https://weibo.com/"
PKL_NAME = "weibo_cookies.pkl"
JSON_NAME = "weibo_cookies.json"class SeleHeaders:def __init__(self):self.option = Options()# self.option.add_argument("--start-maximized")# self.option.add_argument('--headless')self.bot = webdriver.Chrome(options=self.option)@staticmethoddef make_cookie():with open(JSON_NAME, encoding="utf-8") as f:cookies = json.load(f)# 删除 sameSite 属性for c in cookies:if "sameSite" in c:del c["sameSite"]# 保存为 pickle 文件with open(PKL_NAME, "wb") as f:pickle.dump(cookies, f)print("✅ 已生成新的 pickle 文件(sameSite 属性已删除)")def login(self):self.make_cookie()bot = self.botbot.get(URL)time.sleep(random.randint(3, 7))try:cookies = pickle.load(open(PKL_NAME, "rb"))for c in cookies:bot.add_cookie(c)bot.refresh()print("✅ 登录成功!")# 刷新页面,检查效果!for i in range(3):time.sleep(random.randint(2, 5))bot.refresh()except Exception as e:print("❌ 失败!请检查 cookies 文件或登录状态")print(e)if __name__ == "__main__":meme = SeleHeaders()meme.login()
3. 使用 selenium 提取一个视频的基本信息
- 比如: ‘2,095万次观看 · 1月前 · 发布于 四川’
- 还是需要使用 cookies, 与前面的很像相似。
import os
import time
import random
import json
import pickle
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import requests"""
2025-04-13 19:07:07 能成功运行, 能下载视频。此文件,
1. 使用 selenium + cookies, 登录 weibo.com
2. 找到视频的 url , 下载视频1. 任意网站,从插件 editThisCookie 导出所有的 cookies , 复制到 cookies.json 文件
2. 运行此文件的过程中,会自动生成 pickle 文件
3. 然后模拟登录,刷新页面,即可登录成功
4. 继续 selenium 的其他功能如果报错,那么需要删除 cookies 中的 sameSite 属性, 并重新生成 pickle 文件
"""URL = "https://weibo.com/"
PKL_NAME = "weibo_cookies.pkl"
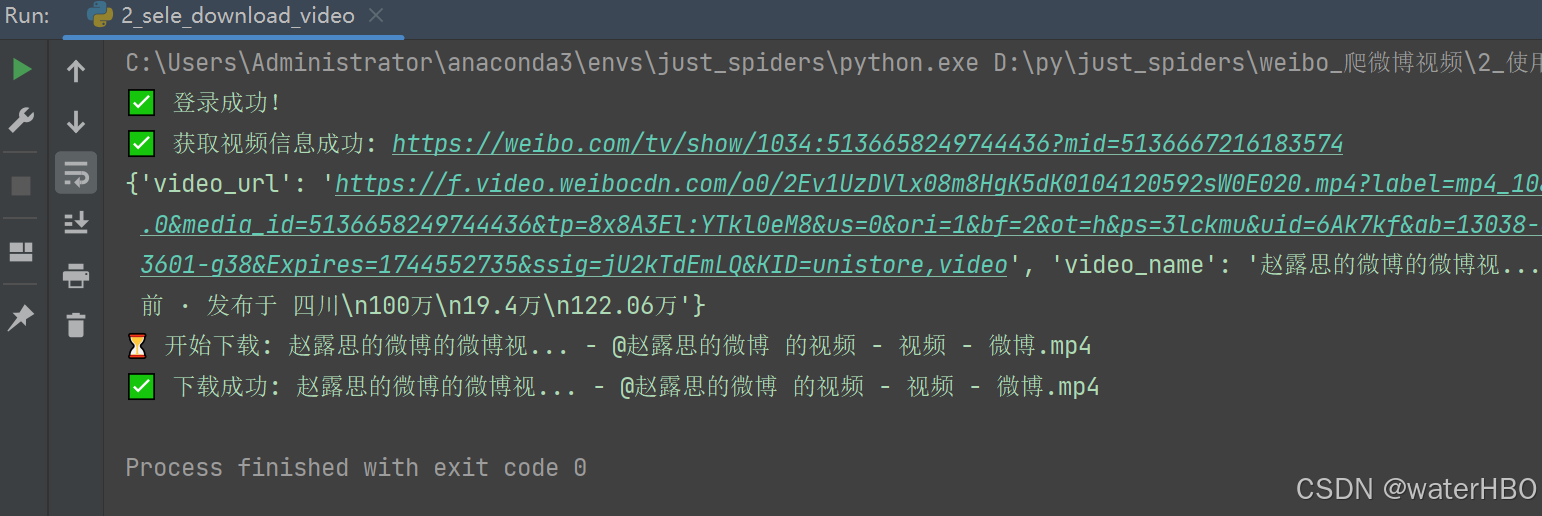
JSON_NAME = "weibo_cookies.json"def make_headers():headers = {'Accept-Encoding': '*/*','Referer': 'https://weibo.com/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36',}return headersdef make_cookies():if PKL_NAME in os.listdir(): return # 已有 pickle 文件,直接返回with open(JSON_NAME, encoding="utf-8") as f:cookies = json.load(f)# 删除 sameSite 属性for c in cookies:if "sameSite" in c:del c["sameSite"]# 保存为 pickle 文件with open(PKL_NAME, "wb") as f:pickle.dump(cookies, f)print("✅ 已生成新的 pickle 文件(sameSite 属性已删除)")class SeleniumSpider:def __init__(self):self.option = Options()# self.option.add_argument("--start-maximized")# self.option.add_argument('--headless')self.bot = webdriver.Chrome(options=self.option)make_cookies()def login(self):bot = self.botbot.get(URL)time.sleep(random.randint(3, 7))try:cookies = pickle.load(open(PKL_NAME, "rb"))for c in cookies:bot.add_cookie(c)bot.refresh()print("✅ 登录成功!")except Exception as e:print("❌ 失败!请检查 cookies 文件或登录状态")print(e)def get_video_info(self, url):video_info = {"video_url": "","video_name": "","video_date": ""}bot = self.botbot.get(url)time.sleep(random.randint(3, 6)) # Wait for page to load# Check if URL is a direct video linkif url.endswith(('.mp4', '.m3u8')):video_info["video_url"] = urlvideo_info["video_name"] = url.split('/')[-1].split('.')[0]print(f"✅ 检测到直接视频链接: {url}")else:# Parse page for video informationtry:# Find video elementvideo_element = bot.find_element("tag name", "video")video_info["video_url"] = video_element.get_attribute("src")except:print(f"❌ 未找到视频元素: {url}")return None# Extract title (video name)try:video_info["video_name"] = bot.title.strip()except:video_info["video_name"] = f"weibo_video_{int(time.time())}"print(f"⚠️ 未找到标题,使用默认名称: {video_info['video_name']}")# Extract full date/views/location stringtry:# Target div.star-f16 with parent div.Detail_tith4_3_UzS# '2,095万次观看 · 1月前 · 发布于 四川'date_element = bot.find_element("css selector", "div.Detail_tith4_3_UzS > div.star-f16")#date_element = bot.find_element("css selector", "div.Detail_tith4_3_UzS")video_info["video_date"] = date_element.text.strip()except:video_info["video_date"] = ""print("⚠️ 未找到日期信息")print(f"✅ 获取视频信息成功: {url}")print(video_info)return video_infodef download_video(self, video_info, save_path=""):session = requests.Session()headers = make_headers()# Construct full save pathfilename = f"{video_info['video_name']}.mp4"# Download videoprint(f"⏳ 开始下载: {filename}")response = session.get(video_info["video_url"], headers=headers, stream=True, timeout=30)if response.status_code == 200:with open(filename, "wb") as f:for chunk in response.iter_content(chunk_size=8192):if chunk:f.write(chunk)print(f"✅ 下载成功: {filename}")return Trueelse:print(f"❌ 下载失败: {filename} (状态码: {response.status_code})")return Falseif __name__ == "__main__":# 1. 先登录spider = SeleniumSpider()spider.login()# 2. 再获取视频的内容one_video_url = "https://weibo.com/tv/show/1034:5136658249744436?mid=5136667216183574"video_info = spider.get_video_info(one_video_url)# 3. 下载视频if video_info:spider.download_video(video_info, save_path="videos/")spider.bot.quit() # Close browser when done输出结果:
4. 使用 requests + cookies + api, 获取某用户的视频播放列表。
- 这部分是比较麻烦的。需要加上 cookies!! 否则的话,得到的是 js 代码 !
- 下面的代码,请使用自己的 cookies ,并且修改页数,默认是5页。
import requests# 请求 api: https://weibo.com/ajax/profile/getWaterFallContent?uid=5653796775&cursor=4436755690237089
# 这里有点复杂,需要加上 cookies!!
# 否则的话,会得到 js !
def make_headers():headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Referer': 'https://weibo.com/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36',"cookie": "SC*****很长很长*******FVH4X16"}return headers# def get_video_list(self, user_id, max_pages=5):
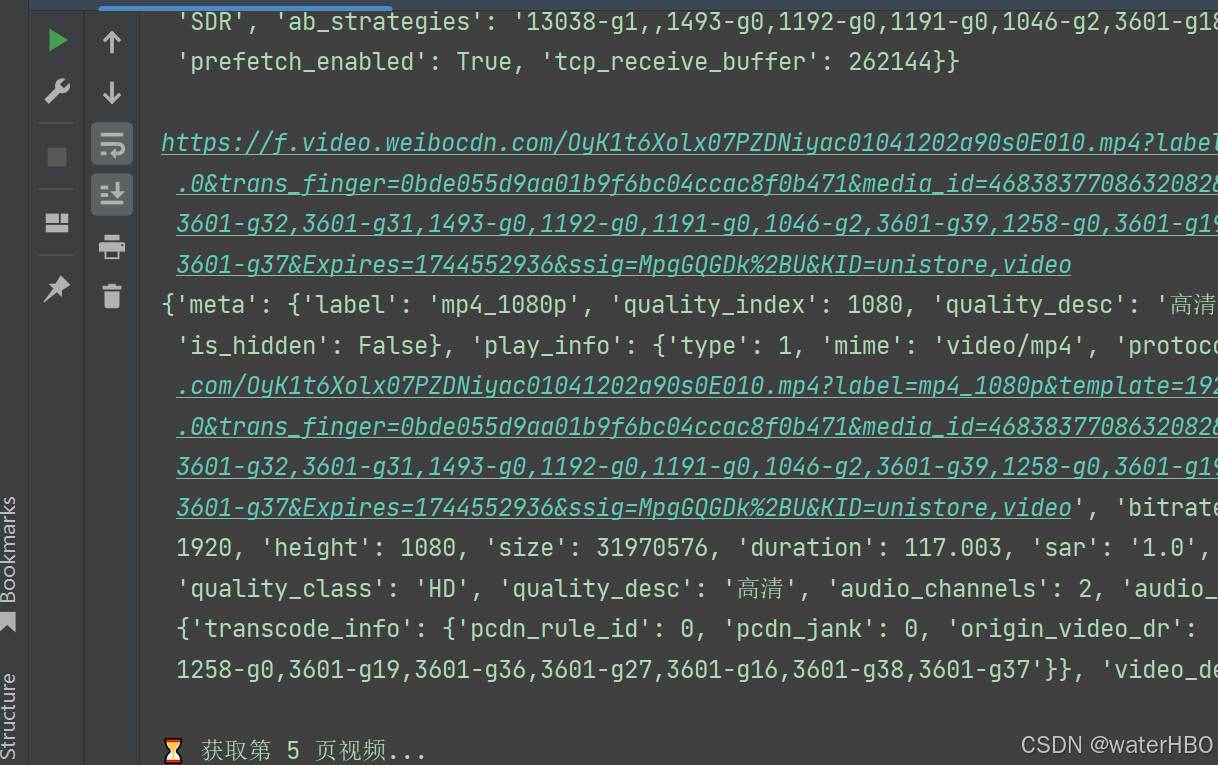
def get_video_list( user_id, max_pages=5):# api: https://weibo.com/ajax/profile/getWaterFallContent?uid=5653796775&cursor=4436755690237089video_infos = []cursor = "0"cnt = 0for page in range(max_pages):print(f"⏳ 获取第 {page + 1} 页视频...")url = f"https://weibo.com/ajax/profile/getWaterFallContent?uid={user_id}&cursor={cursor}"response = requests.get(url, headers=make_headers())print(response.status_code)print(response.text)if response.status_code != 200:print(f"❌ API 请求失败: {response.status_code}")breakdata = response.json()print(type(data))# 解析 JSON 数据for item in data.get("data", {}).get("list", []):# 此时位于 data/list/item[0]# 继续提取 page_info/media_info/playback_list/[0]/play_info/url# 对于 playback_list, 只需要提前第一个即可。playback_list = item.get("page_info", {}).get("media_info", {}).get("playback_list", [])for play_info in playback_list:video_url = play_info.get("play_info", {}).get("url", "")print(video_url)print(play_info)print()cnt += 1break# 继续检查下一个 api jsoncursor = data.get("data", {}).get("next_cursor", "")if not cursor:print("✅ 已到达最后一页")breakprint(f"✅ 共收集 {cnt} 个视频信息")return video_infosif __name__ == '__main__':get_video_list(user_id="5653796775", max_pages=5)
输出效果类似:
结论 + todo
- 就是找点事情做做。不然很无聊。
- 微博爬虫,估计会继续。