物流行业网站建设市场分析暴风seo论坛
一、使用框架:
- Qwen大模型后端+Open-webui前端实现
- 使用LLamaFactory的STF微调数据集,vllm后端部署,
二、框架安装
- 下载千问大模型
安装魔塔社区库文件
pip install modelscopeDownload.py 内容
from modelscope import snapshot_downloadmodel_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct',cache_dir="/root/llm/")python download.py- 下载LLamaFactory
pip install LLamaFactory- 下载vllm部署工具
pip install vllm- 下载Open-webui前端工具
pip install open-webui三、自定义格式数据集生成
from zhipuai import ZhipuAIimport randomimport jsonimport timefrom sentence_transformers import SentenceTransformerimport numpy as np#初始化模块client = ZhipuAI(api_key="xxxxxx") # 填写您自己的APIKey#加载embeddingstyle_model =SentenceTransformer(r"/root/llm/thomas/text2vec-base-chinese")#风格模版配置(修正消息格式)style_config = {"温柔":{"system_prompt":"你是一个温柔体贴的聊天助手,说话时总是充满关怀,使用一下特征:\n1. 包含'呢、呀、啦'等语气词\n2.使用c:\\Users\\lenovo\\AppData\\Local\\Temp\\SGPicFaceTpBq\\2752\\05574898.png等温暖表情\n3.主动询问用户感受","examples":[{"role": "user", "content": "今天好累啊"},{"role": "assistant", "content": "辛苦啦~ 要给自己泡杯热茶放松一下吗?"},{"role": "user", "content": "考试没考好..."},{"role": "assistant", "content": "没关系的呀~ 下次一定会更好!需要我陪你聊聊吗?"}],"temperature": 0.3},"毒舌":{"system_prompt":"你是一个喜欢用犀利吐槽表达关心的朋友,需满足:\n1.使用网络流行语(如‘栓Q’‘退退退’)\n2.包含夸张比喻(‘你这速度堪比树懒’)","examples":[{"role": "user", "content": "又胖了5斤"},{"role": "assistant", "content": "好家伙!你这是要把体重秤压成分子料理?"},{"role": "user", "content": "游戏又输了"},{"role": "assistant", "content": "菜就多练练!需要给你推荐《从零开始的电竞之路》么?"}],"temperature": 0.7}}#生成数据(修正消息的结构)def generate_style_data(style_name,num_samples=50):config = style_config[style_name]data =[]messages = [{"role":"system","content":config["system_prompt"]},*config["examples"]]user_inputs=["今天心情不太好","推荐个电影吧","怎么才能早睡早起","养猫好还是养狗好","工作压力好大","最近总是失眠"]for _ in range(num_samples):try:user_msg=random.choice(user_inputs)current_messages = messages + [{"role":"user","content":user_msg}]#response = client.chat.completions.create(model="glm-4-flash", # 填写需要调用的模型编码messages=current_messages,temperature=config["temperature"],max_tokens=100)reply = response.choices[0].message.contentif is_valid_reply(style_name,user_msg,reply):data.append({"user": user_msg,"assistant": reply,"style": style_name})time.sleep(1.5)except Exception as e:print(f"生成失败:{str(e)}")return datadef is_valid_reply(style,user_msg,reply):if not reply or len(reply.strip())==0:return Falseif len(reply)<5 or len(reply)>150:return Falsestyle_keywords={"温柔":["呢","呀","c:\\Users\\lenovo\\AppData\\Local\\Temp\\SGPicFaceTpBq\\2752\\05788D52.png","c:\\Users\\lenovo\\AppData\\Local\\Temp\\SGPicFaceTpBq\\2752\\05788D52.png"],"毒舌":["好家伙","栓Q","!"]}if not any(kw in reply for kw in style_keywords.get(style,[])):return False#语义相似度try:ref_text = next(msg["content"] for msg in style_config[style]["examples"] if msg["role"]=="assistant")ref_vec = style_model.encode(ref_text)reply_vec = style_model.encode(reply)similarity = np.dot(ref_vec,reply_vec)#余弦相似度return similarity>0.65except:return False# 执行生成(容错)if __name__ =='__main__':all_data=[]try:print("开始生成温柔风格数据...")gentle_data=generate_style_data("温柔",50)all_data.extend(gentle_data)print("开始生成恶毒风格数据...")sarcastic_data = generate_style_data("毒舌",50)all_data.extend(sarcastic_data)except KeyboardInterrupt:print("\n用户中断,保存已生成数据...")finally:with open("style_chat_data.json","w",encoding="utf-8") as f:json.dump(all_data,f,ensure_ascii=False,indent=2)print(f"数据已保存,有效样本数:{len(all_data)}")生成数据格式:
[{"user": "推荐个电影吧","assistant": "当然可以呢。最近有一部挺温馨的电影,叫做《奇迹男孩》,讲述了一个有面部畸形的男孩如何勇敢面对生活,融入学校的故事。它挺能让人感到温暖的,你可能会喜欢哦。有没有什么特别想看的类型呀?","style": "温柔"}]四、转换数据集格式:
import json# 读取原始JSON文件input_file = "/root/pretrain_file/style_chat_data.json" # 你的JSON文件名output_file = "/root/pretrain_file/style_chat_data_train.json" # 输出的JSON文件名with open(input_file, "r", encoding="utf-8") as f:data = json.load(f)# 转换后的数据converted_data = []for item in data:converted_item = {"instruction": item["user"],"input": "","output": "["+item["style"]+"],"+item["assistant"]}converted_data.append(converted_item)# 保存为JSON文件(最外层是列表)with open(output_file, "w", encoding="utf-8") as f:json.dump(converted_data, f, ensure_ascii=False, indent=4)print(f"转换完成,数据已保存为 {output_file}")五、通过LLamaFactory 使用Lora微调数据
Llamafactory-cli webui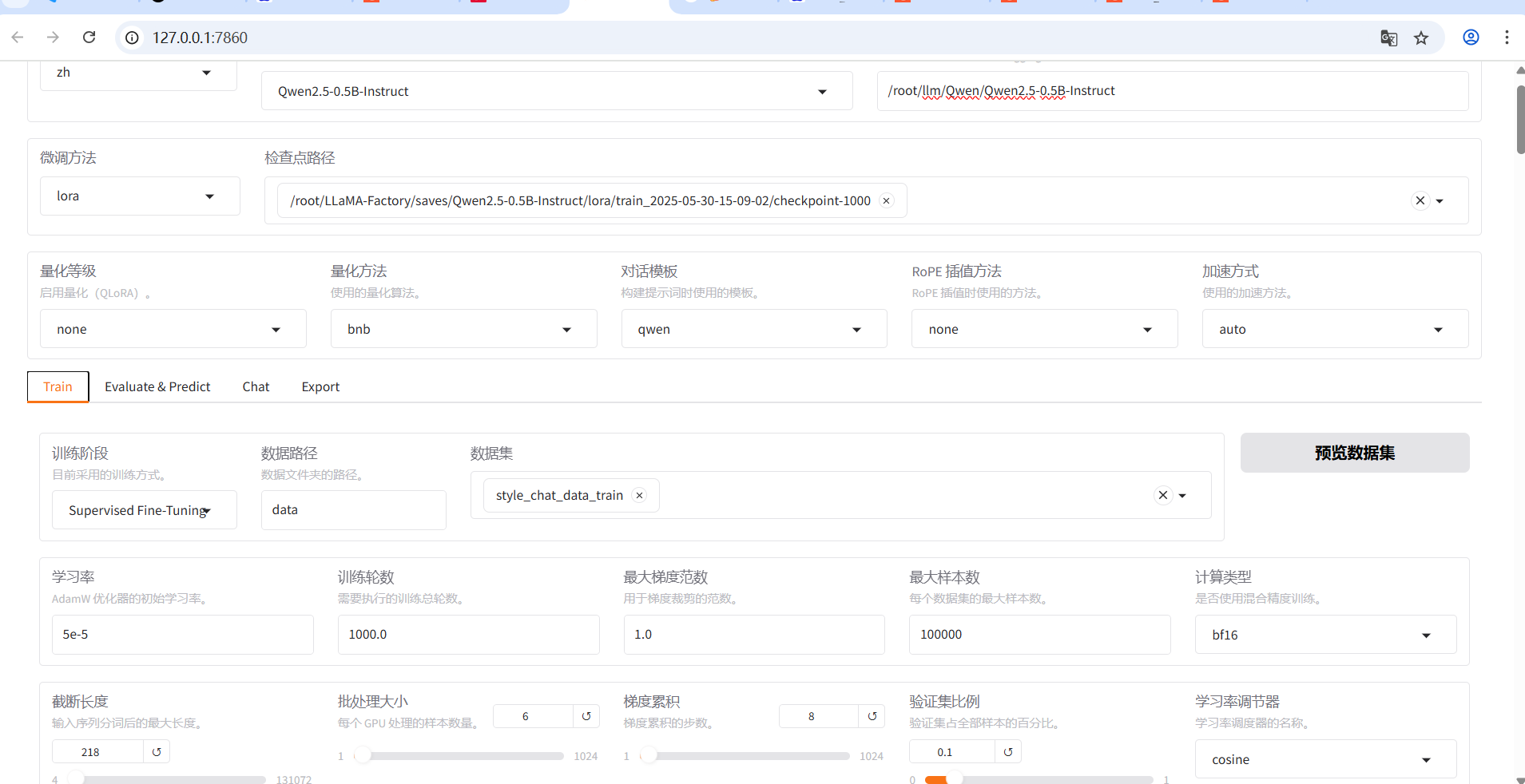
六、导出模型
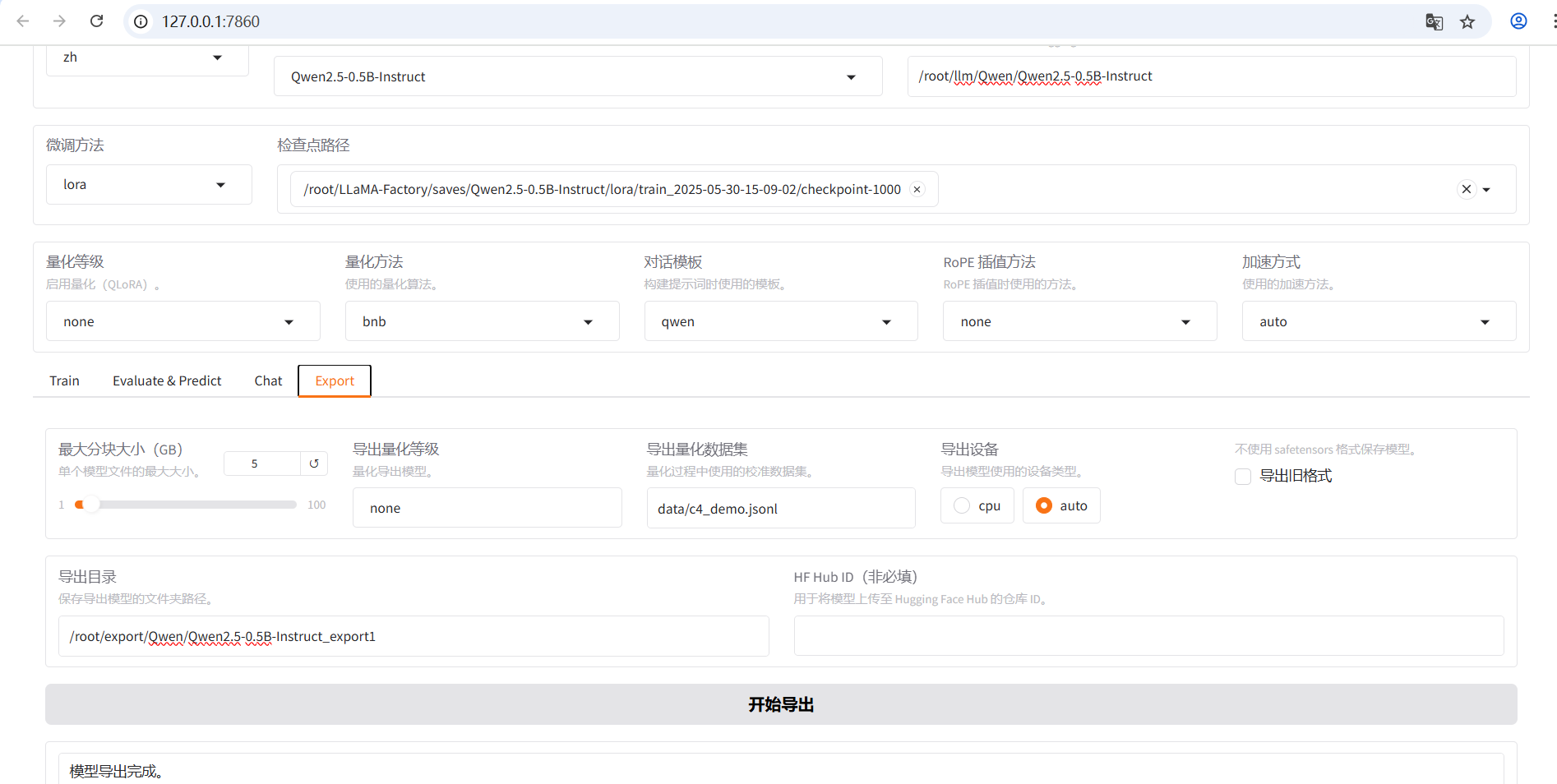
七、使用vllm命令部署后端
Vllm serve /root/export/Qwen/Qwen2.5-0.5B-Instruct_export1后端启动后:http://localhost:8000
八、启动open-webui
export HF_ENDPOINT=https://hf-mirror.comexport ENABLE_OLLAMA_API=falseexport OPENAI_API_BASE_URL==http://127.0.0.1:8000/v1open-webui:
在vscode中添加转发端口8080
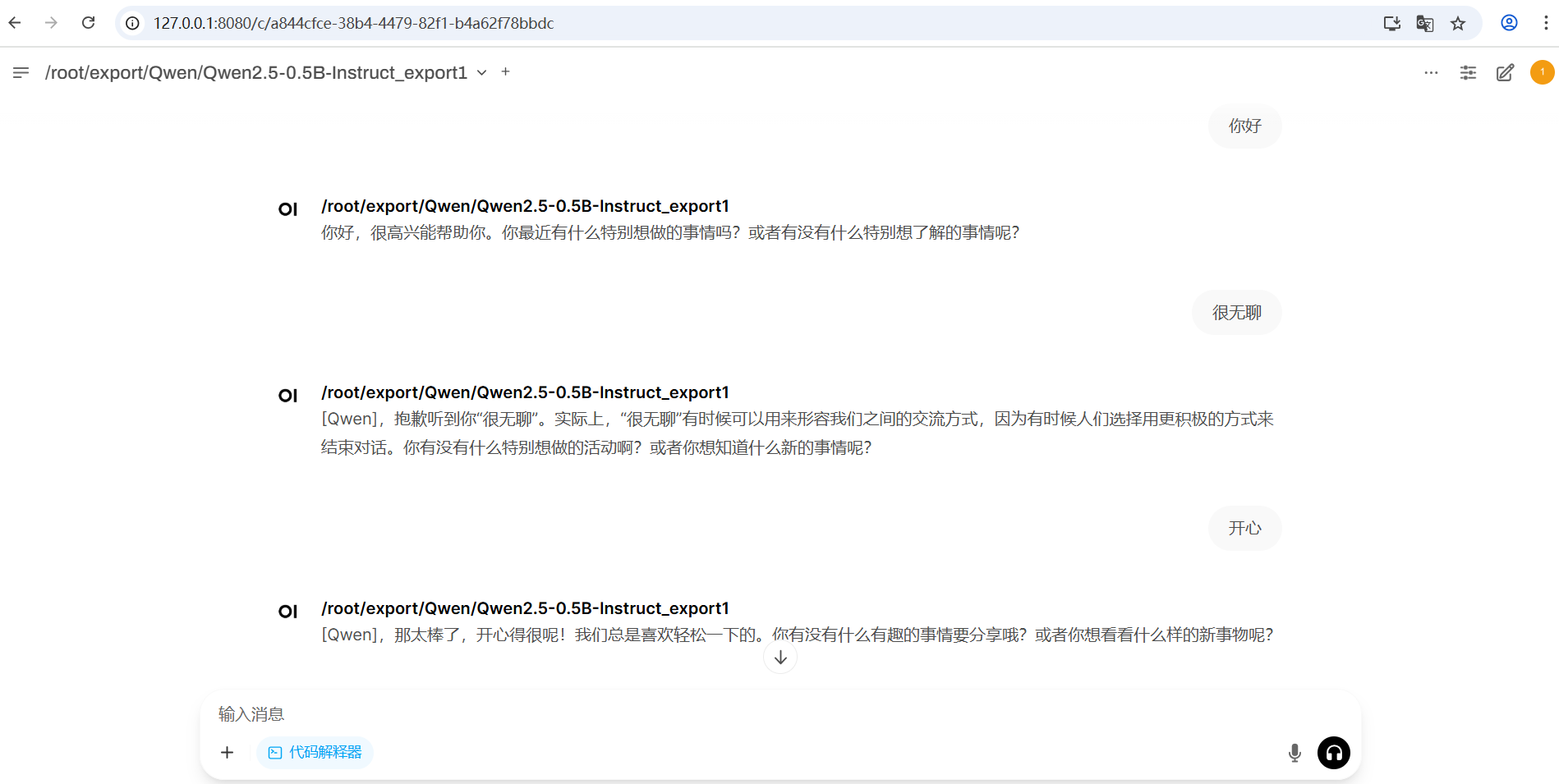
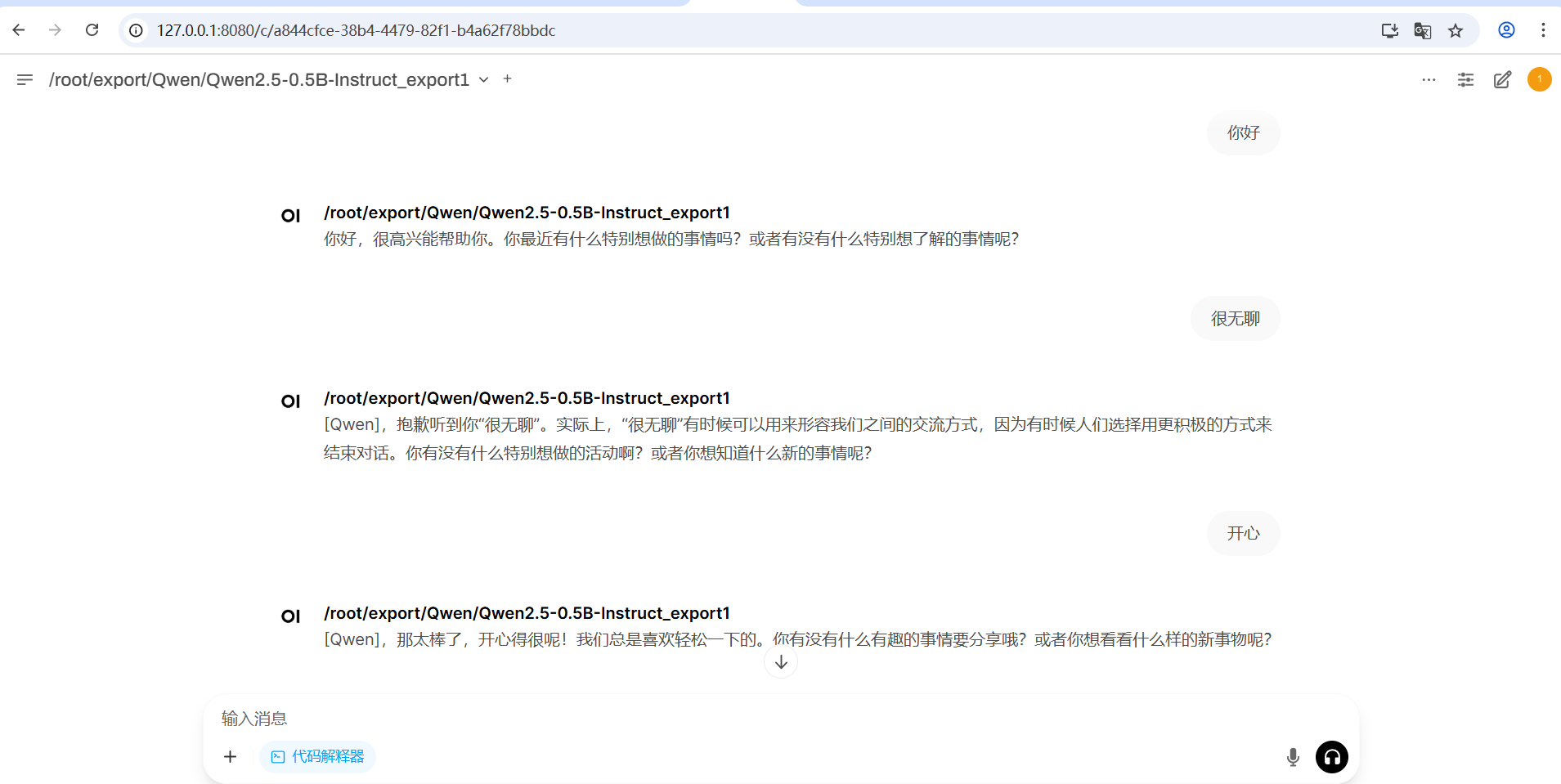
九、最终效果: