搭建自己微信网站苏州seo培训
在数据库的日常使用中,会经常遇到以下场景:
- 数据复制:将一个或多个表中的数据复制到目标表中,可能是复制全部数据,也可能仅复制部分数据。
- 数据合并:将数据从一个表转移到另一个表,或者将多个表的数据合并为一个表
- 表备份:常用于备份表数据,以防止在修改或删除数据时出现问题,需要还原数据的情况。
- 数据加工:将当前数据按照特定规则进行处理,并将处理后的数据放入一个新的表中。
OceanBase 支持并行导入功能,其并行执行框架能够并发执行DML语句(即Parallel DML),使得在多节点数据库环境中能够实现跨节点的并发写入,同时,它还能确保大事务的一致性。现在,让我们通过实验来体验OceanBase的并行导入能力。
一、准备环境
我准备了两套环境一套单节点的,一套1-1-1的集群
单节点:8C16G
集群:4C10G*3 (吐槽一下太费资源了,试验机快冒烟了/(ㄒoㄒ)/~~)
二、准备表结构和数据
找了一张经常使用的表修改为oceanbase脚本
表结构:
CREATE TABLE `test_bingxing` ( `fzssuuid` bigint AUTO_INCREMENT , `jcxxuuid` varchar(32) NOT NULL , `gtfwwrfzsslbdm` char(1) NULL DEFAULT NULL , `cshssmc` text NULL , `zxxzm_dm` char(16) NULL DEFAULT NULL , `gtfwly_dm` char(1) NULL DEFAULT NULL , `zhlycw` text NULL , `werjbqk` longtext NULL , `lrrq` datetime NOT NULL , `lrr_dm` char(11) NOT NULL , `xgrq` datetime NULL DEFAULT NULL , `sjgsdq` char(11) NOT NULL , `sjtb_sj` datetime NULL DEFAULT NULL ,`zhlyhcsdfg` decimal(18, 6) NULL DEFAULT NULL ,`zhlyzyfss_dm` varchar(45) NULL DEFAULT NULL , `ssbm` varchar(45) NULL DEFAULT NULL , `yxbz` char(1) NULL DEFAULT NULL , `sjblbz` decimal(2, 0) NULL DEFAULT NULL , PRIMARY KEY (fzssuuid)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = COMPACT COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384;准备造数脚本:
写了一个简单的python造数脚本仅供参考,构造500万左右的数据
import random
import string
import pymysql
import time
import datetime
import multiprocessing
import threading # 数据生成部分------------公共------------------------------------------------------------------------------------------------------------------------------(始)
# 随机时间 2000年-2023年
class CreateData(object):def randdatetime(self):mintime = datetime.datetime(2000, 1, 1, 0, 0, 0)maxtime = datetime.datetime(2023, 12, 31, 23, 23, 59)mintime_ts = int(time.mktime(mintime.timetuple()))maxtime_ts = int(time.mktime(maxtime.timetuple()))random_ts = random.randint(mintime_ts, maxtime_ts)randomtime = datetime.datetime.fromtimestamp(random_ts)# print(randomtime)return (randomtime)# # 获取fundid随机6位,乙级差不多相同会又1000左右def get_fundid(self):fundid = '25010'for ii in range(6):fundid += str(random.randint(0, 9))return fundid# 生成数据def get_one_data(self,xh):matchsno = 1000000+xh# 此处返回的数据顺序最好与创建表时的结构顺序一致,以便插入数据时一一对应aa=["dsdfsdf","Y",self.get_fundid(),"WRFG3452","Y",self.get_fundid(),"FTERGDFFSGHTRT324RDAFAGDA",self.randdatetime().strftime('%Y-%m-%d %H:%M:%S'),"12032032",self.randdatetime().strftime('%Y-%m-%d %H:%M:%S'),"中国",self.randdatetime().strftime('%Y-%m-%d %H:%M:%S'),"1232143.12","sadfkjjdfw231","dsfwer23Dcxf","n","1"]return aadef insert_data(tablename,*args):get_conn = pymysql.connect(host="192.168.150.117",user="banjin",password="oracle123",port=2881,database="test") # 连接数据库get_cursor = get_conn.cursor() # 获取游标str_sql = "insert into {0}(jcxxuuid,gtfwwrfzsslbdm,cshssmc,zxxzm_dm,gtfwly_dm,zhlycw,werjbqk,lrrq,lrr_dm,xgrq,sjgsdq,sjtb_sj,zhlyhcsdfg,zhlyzyfss_dm,ssbm,yxbz,sjblbz) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s);".format(tablename) # 定义SQL语句get_cursor.executemany(str_sql,args) # 批量执行SQL语句get_conn.commit() # 提交保存数据
# # 定义一个关闭对象的方法get_conn.close()# print(str_sql)
# # 测试代码
# #生成数据当前批量写入,三个线程,需手工大致画区间
if __name__ == "__main__":createdata = CreateData() # 实例化CreateData类方法list1 = []for i in range(1,5000000): # 循环1000000次,生成1000000条数据get_one = createdata.get_one_data(i) # 调用CreateData类的get_one_data方法list1.append(get_one) # 在list1列表中插入get_one列表(一行数据)start_time = time.time()print("执行程序开始时间:",start_time)p1 = multiprocessing.Process(target=insert_data,args=("`test_bingxing`",*list1[:1800000]))p2 = multiprocessing.Process(target=insert_data,args=("`test_bingxing`",*list1[1800001:3600000]))p3 = multiprocessing.Process(target=insert_data,args=("`test_bingxing`",*list1[3600001:]))p1.start()p2.start()p3.start()p1.join()p2.join()p3.join()end_time = time.time()print("执行程序结束时间:", end_time)print("执行程序总耗费时间:",end_time - start_time) #时间统计为脚本数据库执行时间,不包含脚本生成数据时间三、并行导入验证
测试脚本
set ob_query_timeout = 1000000000;
set ob_trx_timeout = 1000000000; insert into test_bingxing1 select * from test_bingxing;truncate table test_bingxing1;
insert /*+ parallel(8) enable_parallel_dml */ into test_bingxing1 select * from test_bingxing;1、单机环境
先不开启并行的方式插入,然后清空数据添加一个 Hint,开启 PDML 的执行选项,执行结果如下:
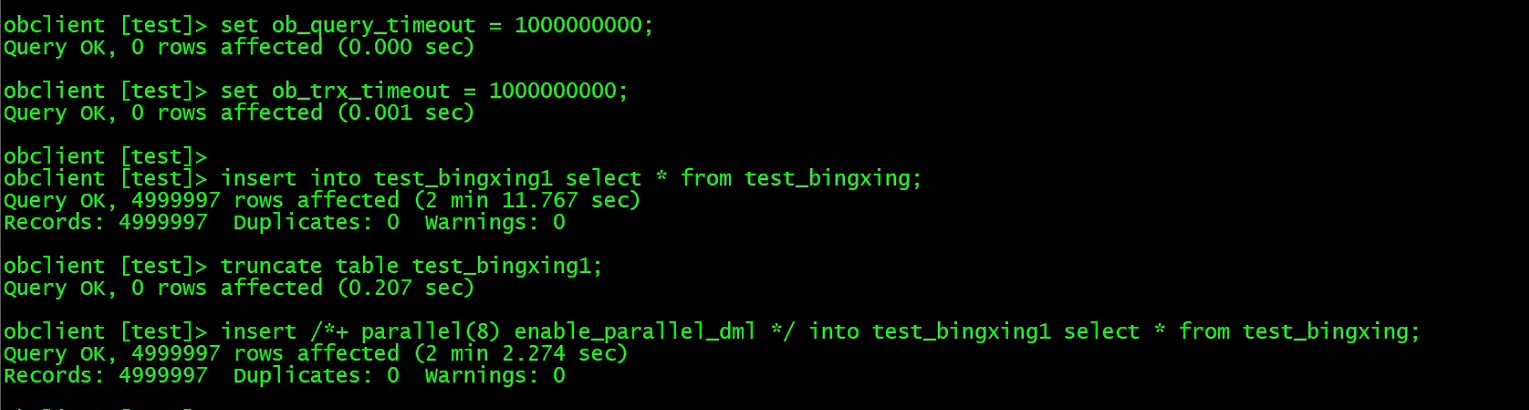
非并行插入时间消耗两分多,并插入时间相差不多
2、集群环境
先不开启并行的方式插入,然后清空数据添加一个 Hint,开启 PDML 的执行选项,执行结果如下:
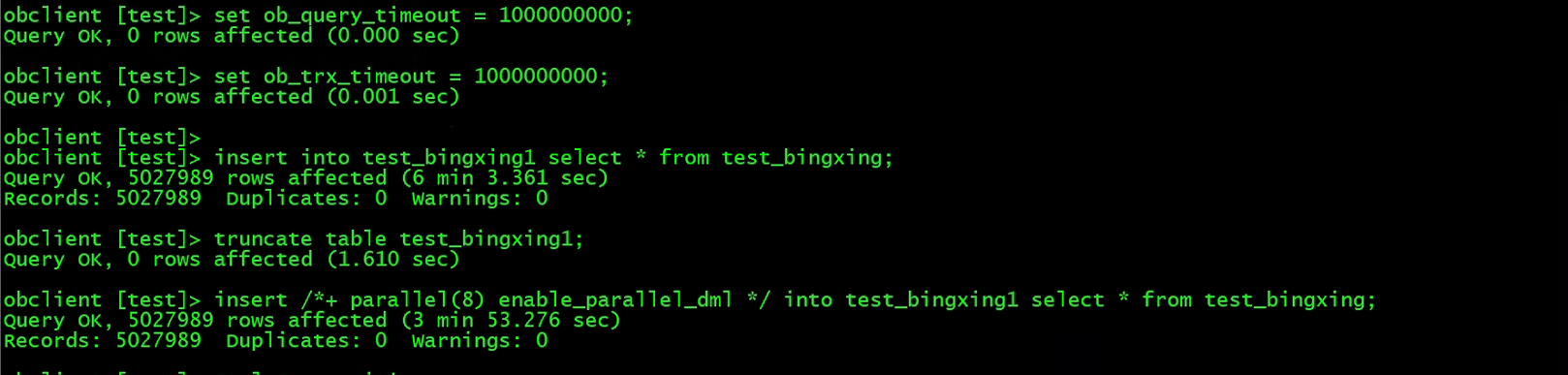
非并行插入时间消耗六分多,并插入时间差不多节约一半,(集群环境因为电脑没有空间了,外插了一块老的移动硬盘,写入速度有点慢)
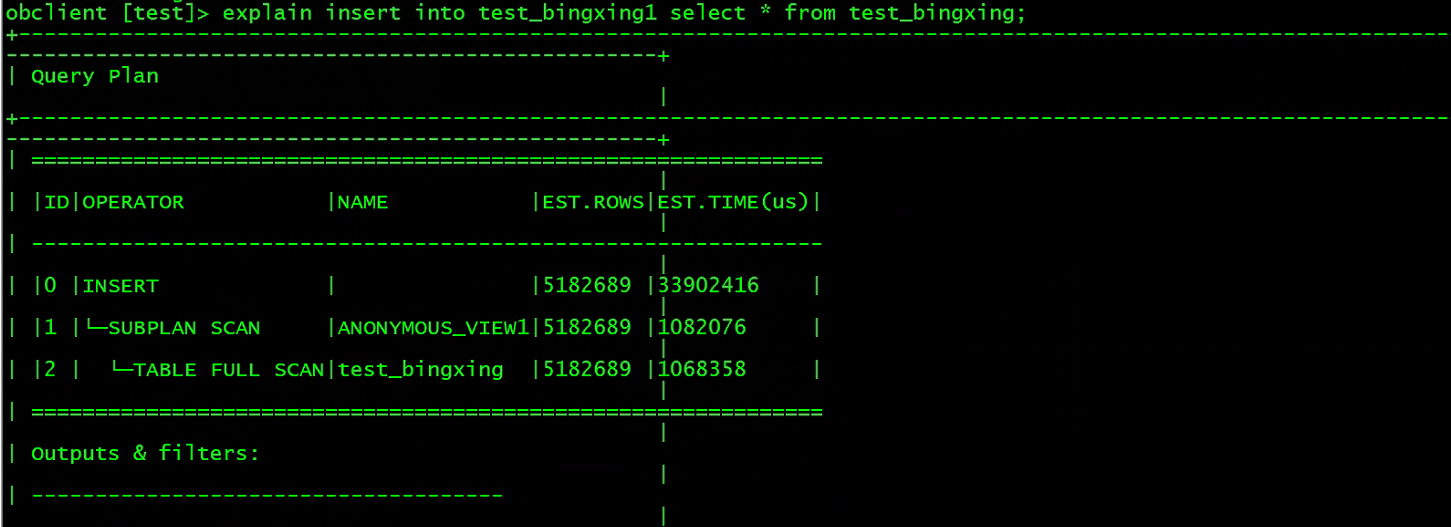
3、执行计划对比
未开启并行导入的执行计划
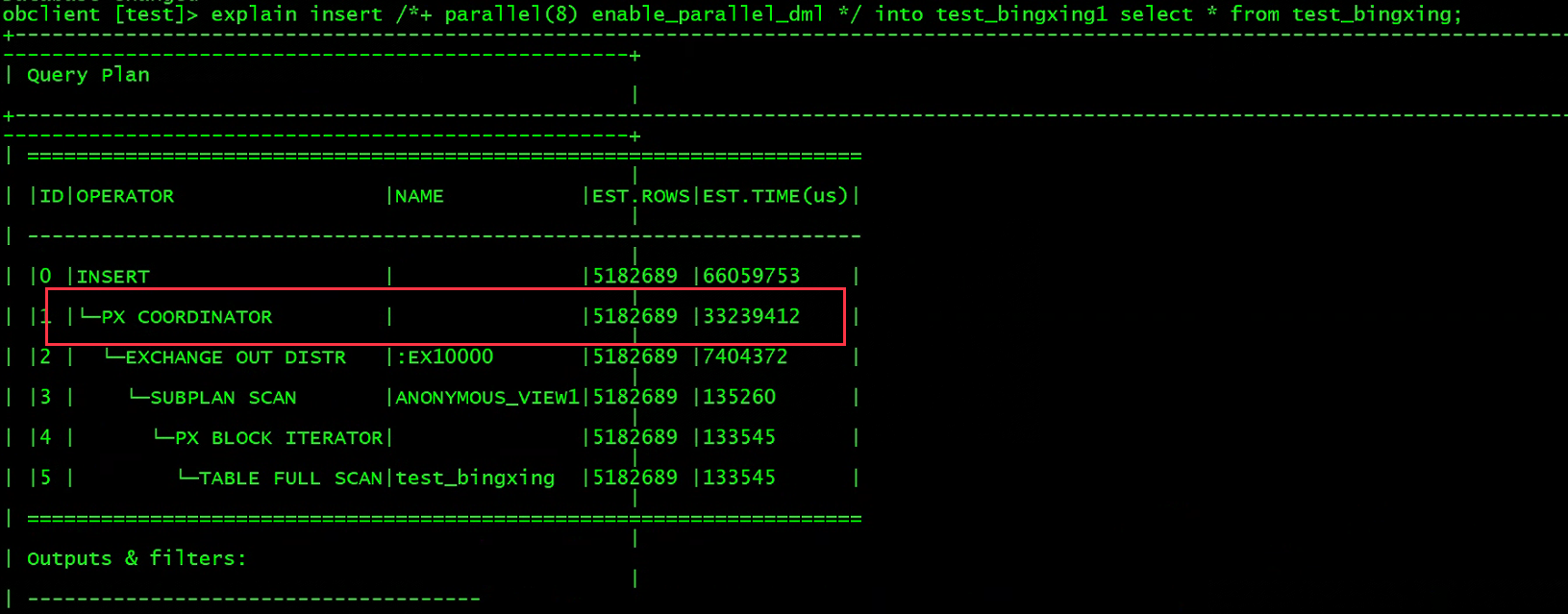
开启并行导入的执行计划,可以看到使用了并行算子
四、总结
并行插入可以实现更高效的数据插入,因为实验环境是虚拟机,磁盘都是一块,性能提升没有官网文档说明的那么大,有条件的伙伴可以用真实环境进行测试。