今科网站建设公司梅州网络推广
Web Scraper是一款功能丰富的浏览器扩展爬虫工具,有着直观的图形界面,无需编写代码即可自定义数据抓取规则,高效地从网页中提取结构化数据,而且它支持灵活的数据导出选项,广泛应用于电商监控、内容聚合、市场调研等多元化数据收集与分析场景。
Web Scraper的安装也很简单,在Chrome应用商店里搜索“Web Scraper”,找到该插件并点击“添加至Chrome”按钮。

安装好Web Scraper后,需要在开发者工具中使用它,按F12键打开开发者模式能找到Web Scraper功能区,在这里可以新建并配置爬虫,你也不需要写任何代码就能抓取数据。

Web Scraper的优势有以下几个方面:
- 数据抓取方式简单:用户可以通过选择网页上的元素来定义抓取点,插件会自动从这些元素中提取数据。
- 多浏览器支持:支持多种浏览器,包括但不限于Chrome和Firefox,使其可以轻松集成到用户的日常工作流程中。
- 灵活配置:提供了丰富的配置选项,可以满足不同用户的需求,包括自动翻页、登录认证等功能。
- 数据导出:抓取的数据可以导出为CSV、Excel等格式,便于后续处理和分析。
下面讲讲实践案例,使用Web Scraper爬取抖音评论数据。
首先,按F12打开开发者界面,点击Web Scraper按钮,会进入到操作界面。

接下来,新建Sitemap name项目名称,英文随意取,Start URL就是想要爬取的网站的URL,输入完点击Create Sitemap。

然后,点击“添加新的Selector”按钮,在网页中选择要爬取的数据所在的区域(如“抖音视频”模块中的评论区)。注意必须勾选Multiple,因为字样才会批量爬取。

这样对于评论的简单抓取设置就可以了,最后保存并导出评论数据。
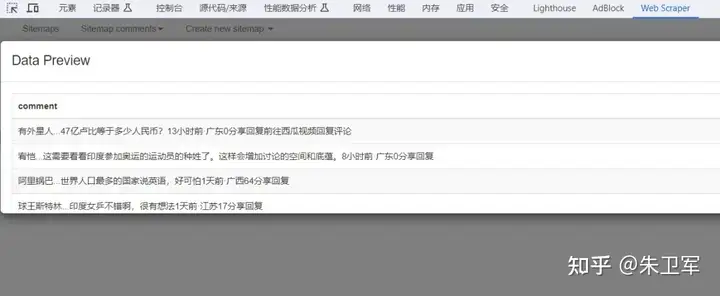
使用Web Scraper需要对HTML结构有一定的了解,需要自己一步步去配置,可能对于初学者还有些门槛,适合IT从业者。而且Web Scraper抓取的数据形式有限,适合文本这样简单的数据需求,对于图片、视频就会比较困难。