上海可靠的网站建设公司做推广的技巧
文章目录
- 前言
- 一、openpyxl是什么?
- 二、基础用法
- 1.读取和写入文件
- 2.合并单元格
- 三、合并单元格实战
- 1.连续相同元素的索引范围
- 2.转换
- 3.获取列合并索引
- 4.整体
- 总结
前言
python可以很方便的操作各种文档,比如docx,xlsx等。本文主要介绍在xlsx文档中合并单元格的做法,并由此引申出一个很常见的应用场景,如何在一个xlsx文档中对具有层次关系的单元格数据进行合并。
一、openpyxl是什么?
openpyxl是一款基于python的操作xlsx文件代码库。python自带的xlrd 和 xlwt则无法操作xlsx文件,只能操作xls文件,而openpyxl可以读取,创建和修改xlsx文件,是一个功能强大的工具库。
二、基础用法
1.读取和写入文件
代码如下(示例):
workbook = openpyxl.load_workbook(file_path)
# 获取活动工作表
sheet1 = workbook.active
sheet1 = workbook["Sheet1"]
sheet1 = workbook.worksheets[0]
print(sheet1["A1"].value)
# 读取所有的数据
for row in sheet1.rows:for col in row:print(col.value)# 加载已有的工作簿
workbook = openpyxl.load_workbook(file_path)
# 获取指定工作表,这里假设工作表名为 'Sheet1'
sheet = workbook['Sheet1']# 在已有数据基础上追加一行数据
new_row = ["xxxx"]
sheet.append(new_row)# 保存修改后的工作簿
workbook.save(file_path)
2.合并单元格
代码如下(示例):
workbook = openpyxl.load_workbook(file_path)
# 获取活动工作表
sheet = workbook.active# 合并 第一列的第一个和第二个单元格为1个
sheet.merge_cells(start_row=1, end_row=2, start_column=1, end_column=1)
三、合并单元格实战
存在一个嵌套字典,想把这个字典展示在xlsx表格中,应该如何展示?
直观地想,可以将遍历嵌套字典的所有路径,然后将路径写入表格中,但是这种写法会导致数据冗余,不符合阅读习惯。因此,需要使用合并单元格来进行消消乐。
1.连续相同元素的索引范围
def find_consecutive_ranges(lst):"""输入: ["xx", 23, "xx", "xx"]输出: [(0, 0), (1,1), (2,3)]输入: ["xx", xx, "xx", "xx"]输出: [(0, 3)]需求是找出列表中连续相同元素的索引范围"""ranges = []if not lst:return rangesstart = 0for i in range(1, len(lst)):if lst[i] != lst[start]:ranges.append((start, i - 1))start = i# 处理最后一组元素ranges.append((start, len(lst) - 1))return ranges
上述代码可以找到任意一列中连续相同元素的索引,可以利用合并函数进行合并。
2.转换
def transform_arr(A):"""将二维数组A转成二维数组C,二者的形状相同对于每一个元素,将其前所有元素和该元素组成一个元组添加到结果数组 C 的当前行中。"""rows = len(A)cols = len(A[0]) if rows > 0 else 0C = []for i in range(rows):row = []for j in range(cols):element = []for k in range(j+1):element.append(A[i][k])row.append(element)C.append(row)return CA = [[1,2,3,4],[1,2,5,4], [4,3,2,1],[4,3,2,5]]
print(transform_arr(A))
# 输出:
C = [[[1], [1, 2], [1, 2, 3], [1, 2, 3, 4]], [[1], [1, 2], [1, 2, 5], [1, 2, 5, 4]], [[4], [4, 3], [4, 3, 2], [4, 3, 2, 1]], [[4], [4, 3], [4, 3, 2], [4, 3, 2, 5]]]3.获取列合并索引
def fill_value(two_d_array):# 针对 二维数组的 进行填充# 使用 itertools.zip_longest 进行填充打包import itertoolspadded_zip = itertools.zip_longest(*two_d_array, fillvalue='')arr = list(padded_zip)return [list(row) for row in zip(*arr)]def get_arr_merge_col_table(A):"""1、先将二维数组A转换成一个同样形状的二维数组转换规律:函数 transform_arr读者可以考虑如果不使用transform_arr函数后的效果2、根据1中的结果使用函数find_consecutive_ranges后,知道数组A中每列相同元素的索引"""# 可以补充每行的长度一致A = fill_value(A)# 读者可以屏蔽本行,同样可以运行,但是问题是什么??A = transform_arr(A)rows = len(A)cols = len(A[0]) if rows > 0 else 0# 初始化新的二维数组 DD = []for j in range(cols):# 提取第 j 列column = [A[i][j] for i in range(rows)]# 使用函数 B 处理该列processed_column = find_consecutive_ranges(column)# 将处理后的列添加到 D 中D.append(processed_column)return DA = [[1,2,3,4],[1,2,5,4], [4,3,2,1],[4,3,2,5]]
print(get_arr_merge_col_table(A))
# 输出:
C = [[(0, 1), (2, 3)], [(0, 1), (2, 3)], [(0, 0), (1, 1), (2, 3)], [(0, 0), (1, 1), (2, 2), (3, 3)]]上述代码可以将每一列中连续相同元素的索引找出来,方便后续进行合并
4.整体
import openpyxldef load_data(file_path):# 加载 Excel 文件workbook = openpyxl.load_workbook(file_path)# 获取活动工作表sheet = workbook.active# 获取原始数据data = []# 遍历工作表的每一行for row in sheet.iter_rows(values_only=True):data.append(list(row))return datadef merge_cells_in_excel(file_path, merge_index_table):# 加载 Excel 文件workbook = openpyxl.load_workbook(file_path)# 获取活动工作表sheet = workbook.active# 也可以使用行和列的索引来指定合并范围for col_index, col_index_list in enumerate(merge_index_table, 1):for col_index_tuple in col_index_list:sheet.merge_cells(start_row=col_index_tuple[0] + 1, end_row=col_index_tuple[1] + 1, start_column=col_index, end_column=col_index)# 保存修改后的 Excel 文件workbook.save(file_path)return workbookfile_path = "test.xlsx"excel_data = load_data(file_path=file_path)merge_index_table = get_arr_merge_col_table(excel_data)merge_cells_in_excel(file_path, merge_index_table)
test.xlsx文件合并前:
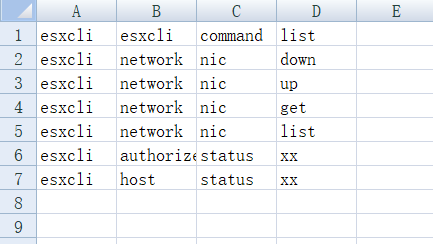
合并后:
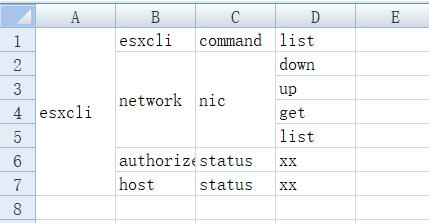
总结
本文简单介绍了openpyxl的用法,然后针对合并单元格的特殊场景用法给出了实例。