啥是深圳网站建设平台seo什么意思
1. 简介
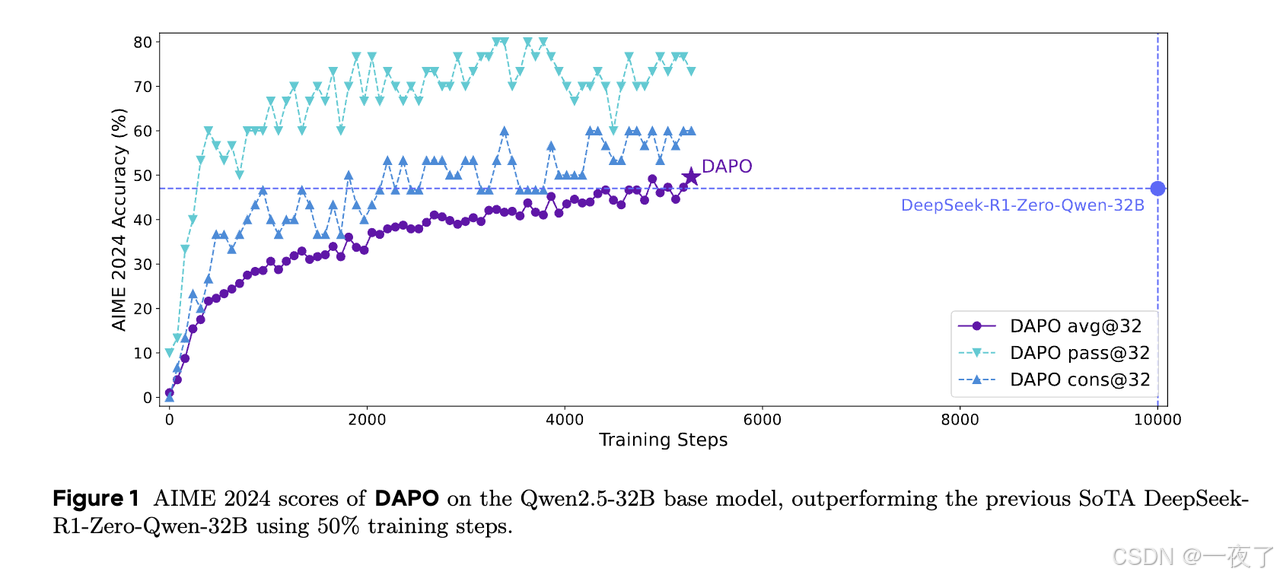
尽管RL对complex reasoning效果提升有重要作用,但是在openAI o1和DeepSeek R1 technical report上都没有详细的实验细节。本文主要提出了DAPO算法,提出了4个关键技术点并开源参数和代码。在AIME 2024验证了DAPO算法的有效性。
2. Tricks
- Exclude KL term:在long CoT任务中,actor model分布会与初始模型有很大的不同。因此,可以去掉KL term。
- Rule-based reward:使用rule-based reward可以避免reward model不准带来的reward hacking问题。
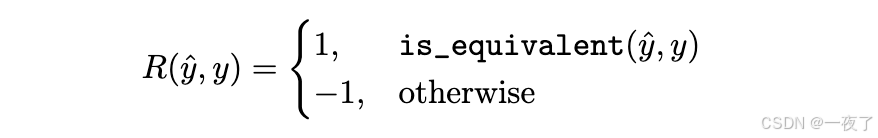
3. DAPO
-
目标函数:
- o i i = 1 G {o_i}_{i=1}^{G} oii=1G表示a group of outputs
- q表示question,a表示answer
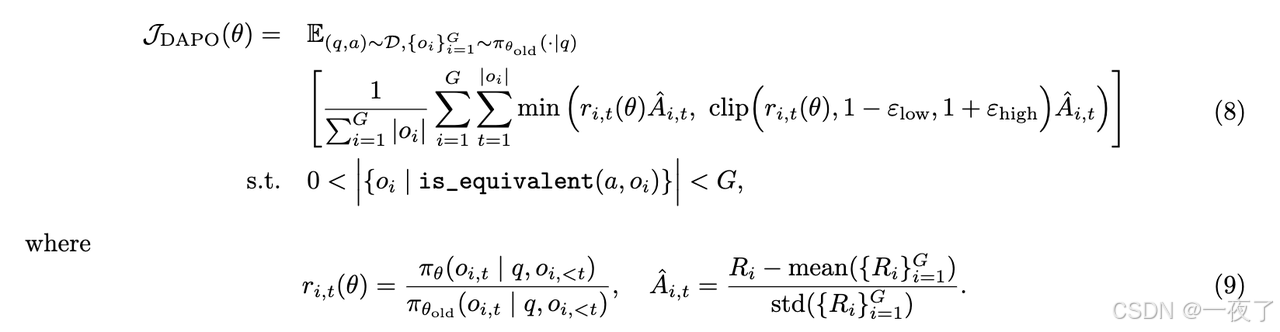
-
优化1 : Raise the ceiling: Clip-Higher
-
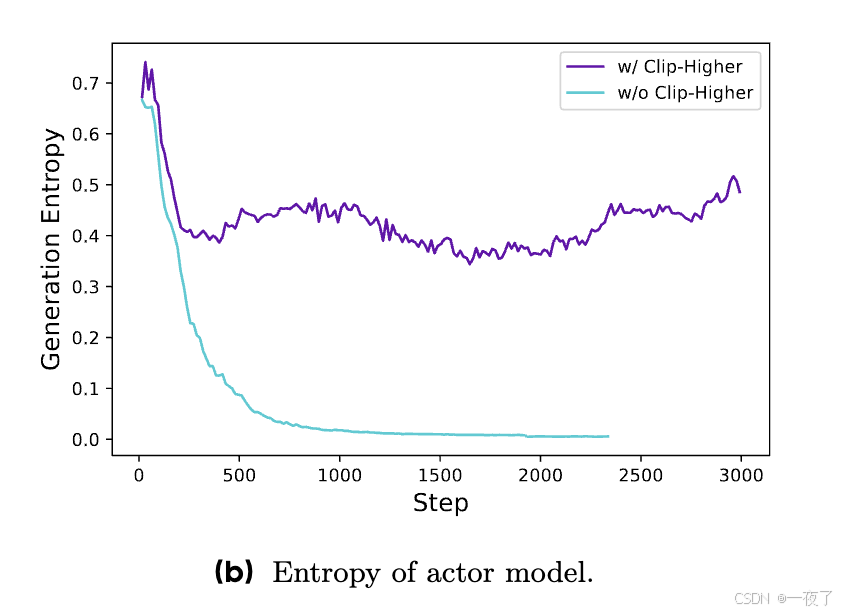
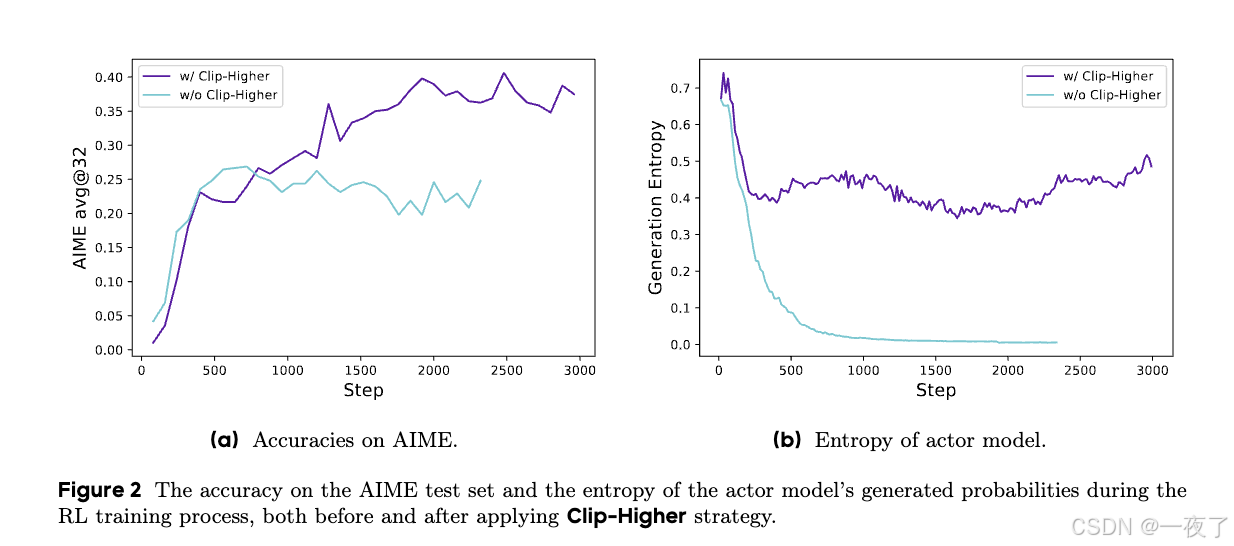
问题:当使用PPO或GRPO进行训练时,会有entropy collapse现象,随着模型的进行,the entropy of policy会快速的下降。这会导致policy生成samples比较接近,会限制policy早期的探索,从而阻碍scaling process。
-
方法:增加clip-Higher。PPO-clip中提出了用cliip控制importance sampling ratio,upper clipping threshold限制了低概率token的概率增加。例如两个token概率分别为0.01和0.9,然后upper clip为0.2。那么两个token最大概率分别为 0.012和1.08。所以具体做法是增加high clip,low clip继续保持小的值。具体公式见:
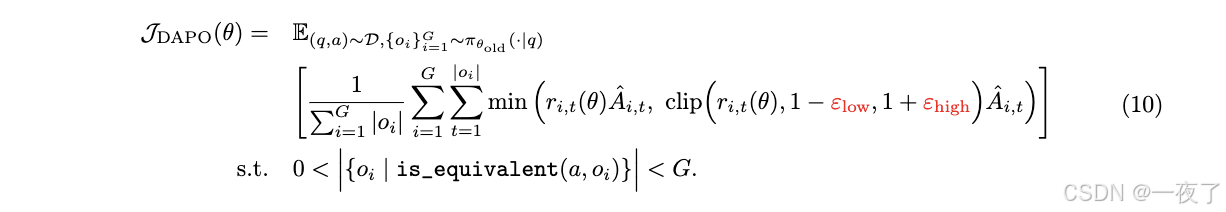
-
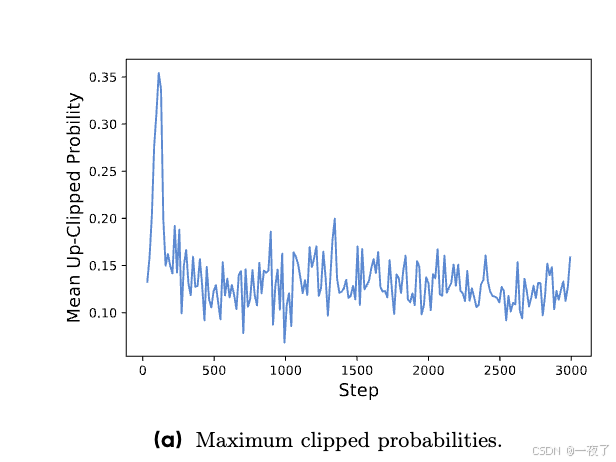
从实验中可以看出,所有up-clip都在0.2以下。
-
优化2: Dynamic sampling
-
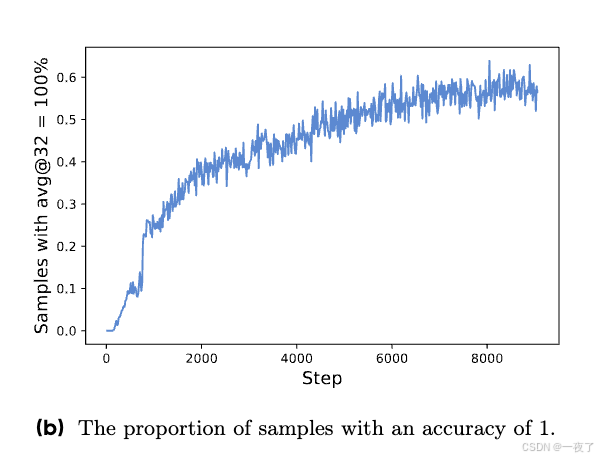
问题:当一些prompt的accuracy等于1的时候,RL算法会有gradient-decreasing问题。例如,GRPO中,当一个batch中所有样本都是对的,reward=1,则这个batch中的advantage为0,对应的policy就会没有gradient。随着训练的进行,reward=1的样本会越来越多,见下图1。就会导致gradient有更大的方差,也会减弱训练中的gradient信号。
-
方法:过滤掉batch中所有reward=0或1的样本,保持batch中的prompt在一个固定的常数。
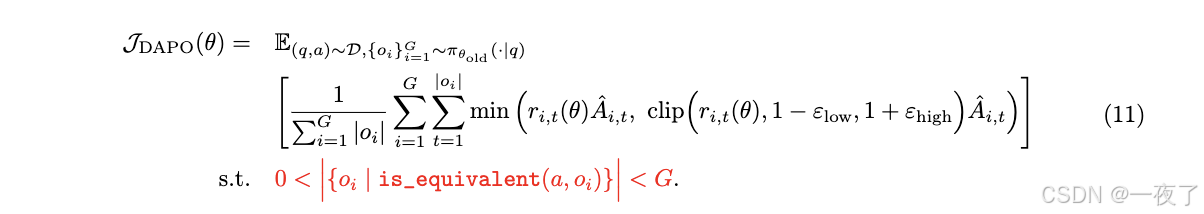
-
-
优化3: Token-Level Policy Gradient Loss
-
问题:初始的GRPO算法对loss进行样本层面的计算(平均),首先用token数平均每个response中的loss,然后在用batch size平均loss。在这种方式下,每个response在最终loss计算中权重一样,但会增加模型训练中entropy和response的不健康。例如,因为每个response在loss中的权重是一样的,那么长度比较长的response中的token对loss的贡献就比较低,这样就会导致模型训练有偏差。1. 对于高质量的长样本,会阻碍模型学习其中与推理相关的模式的能力。2. 观察到过长的样本经常表现出低质量的模式,如乱码和重复的单词。
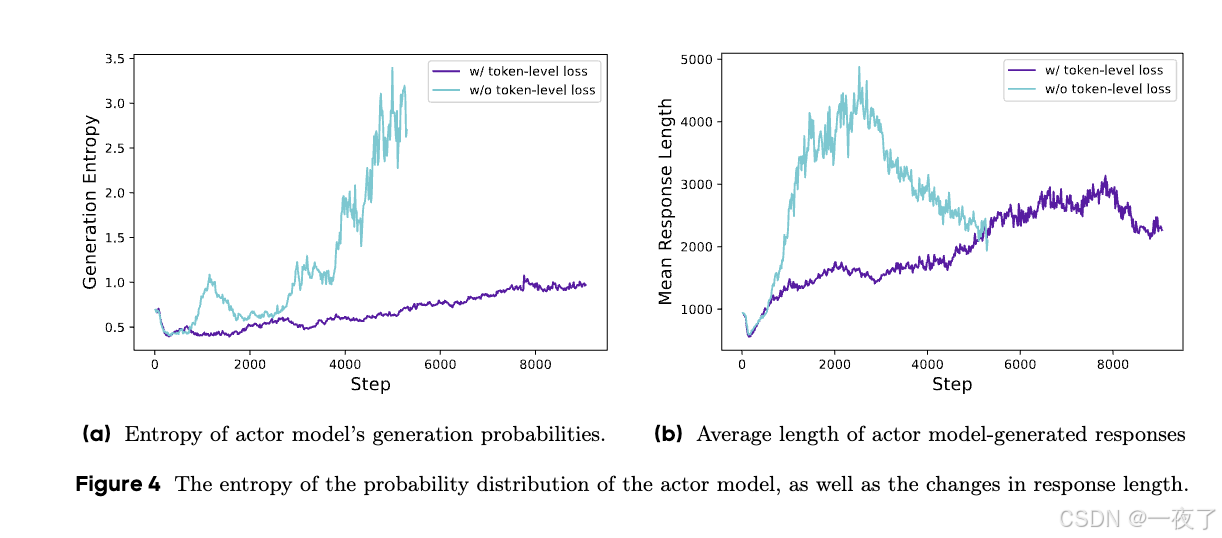
-
方法:提出了token-level policy gradient loss
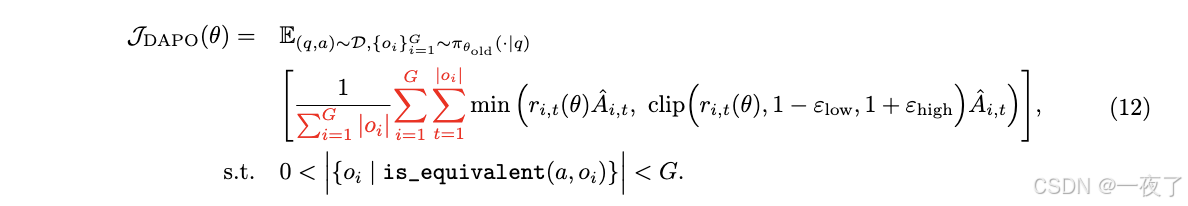
-
-
优化4: Overlong Reward Shaping
- 问题:在RL训练中,会设置一个最大长度用来截断样本。如果截断样本的reward设置不当会引入奖励噪声,从而干扰模型训练。比如,一般情况下,会为截断的sample设置惩罚reward,这种做法就会引入噪声(一个合理的response,仅因为过长就被惩罚),这样的惩罚可能会使模型对其推理过程的有效性产生混淆。
- 方法:mask掉过长的samples(截断样本)的loss。更进一步,提出了soft overlong punishment(针对truncated samples的一个长度惩罚机制)。当样本超过了最大长度,定义了一个惩罚区间。在这个区间内,越长的sample惩罚力度越高
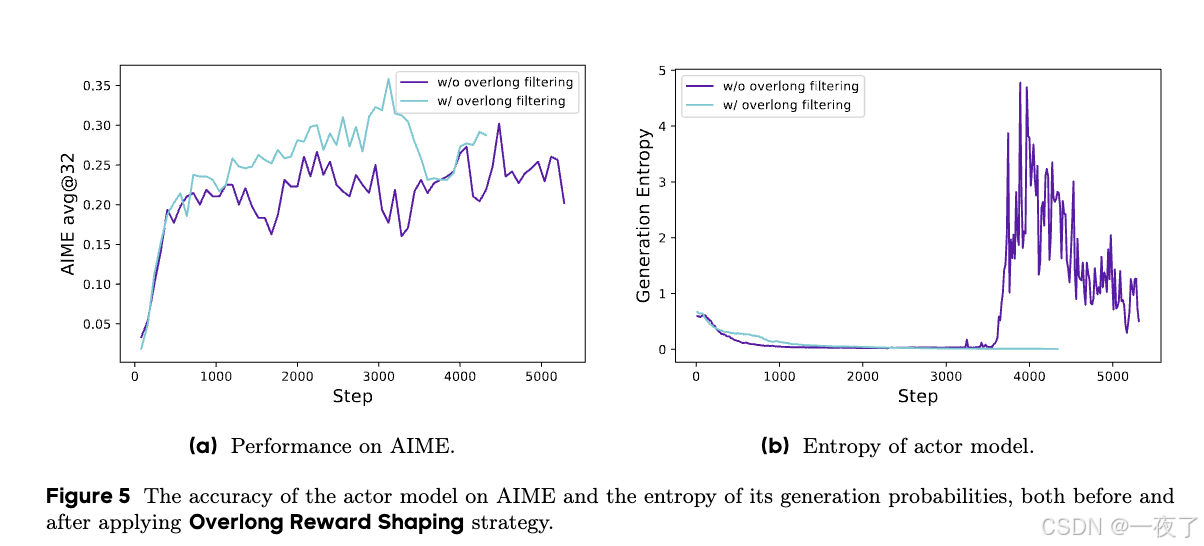
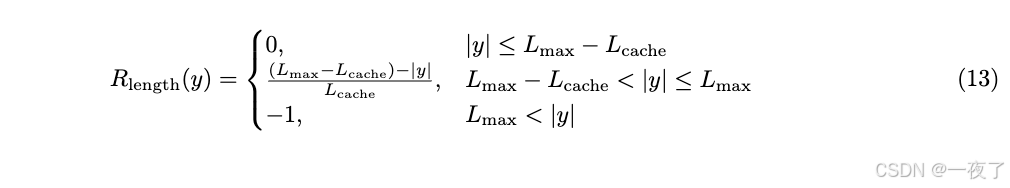
- 完整DAPO算法:

4. 实验
-
数据:
- 数据来自AoPS website和抓取一些官方比赛主页。
- 数学数据集的答案通常有多种格式,如表达式、公式和数字,这使得设计全面的规则来解析它们具有挑战性。
- 为了提供更好的reward,答案都解析为整数。
- 最终得到17K的DAPO-Math-17k数据集。
-
实验细节:
- 使用verl训练框架;
- baseline:naive GRPO
- optimizer:AdamW
- learning rate:1 * 10^{-6},linear warm-up over 20 rollout steps
- rollout:bs=512,每个样本sample 16次。
- Training:mini-batch size=512,所以每个rollout step模型16次迭代。
- 最大长度:16384,soft punish cache=4096,因此最大长度为20480
- clip-higher:low-clip=0.2,up-clip=0.28
- 在AIME验证:重复验证32次,平均结果作为最终结果。
- inference:temperature=1.0,topp=0.
-
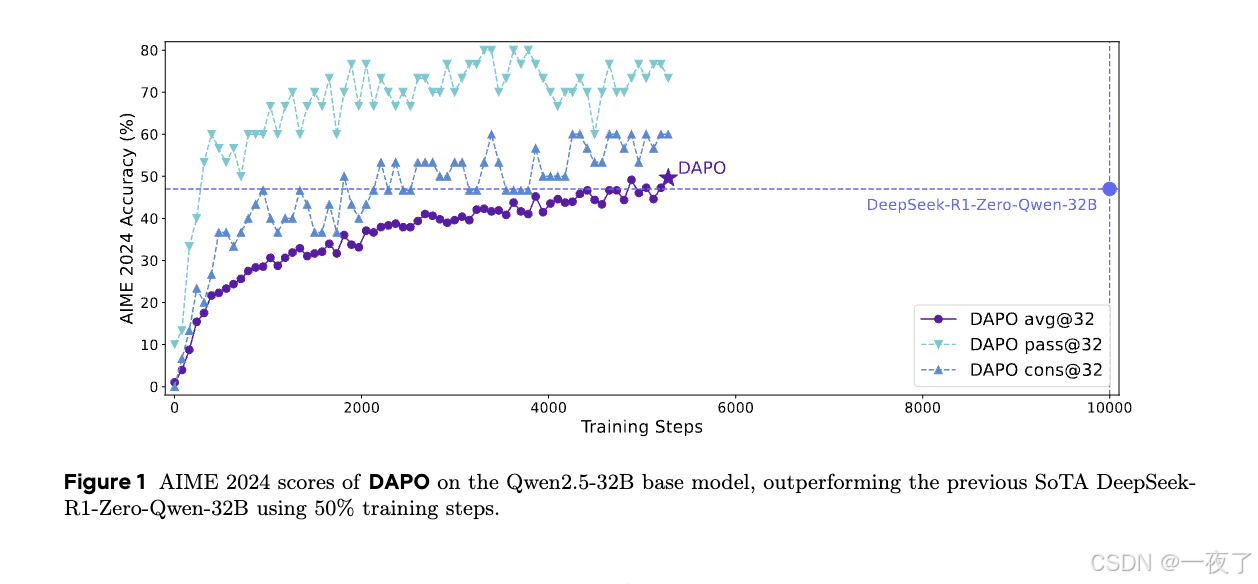
结果:
-
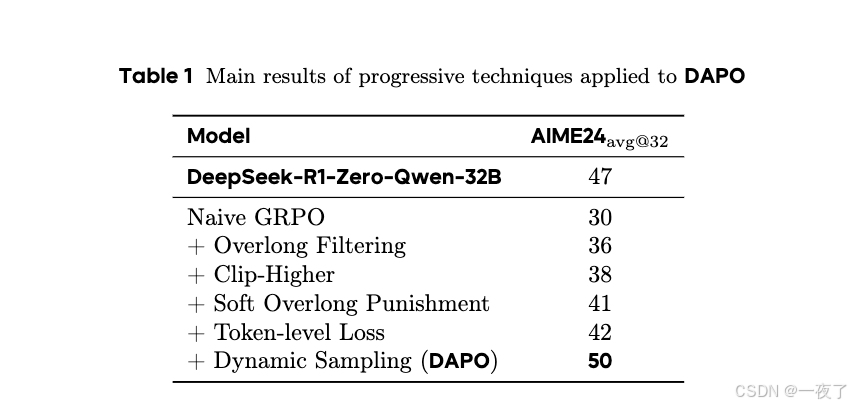
消融实验:
-
Training Dynamics:
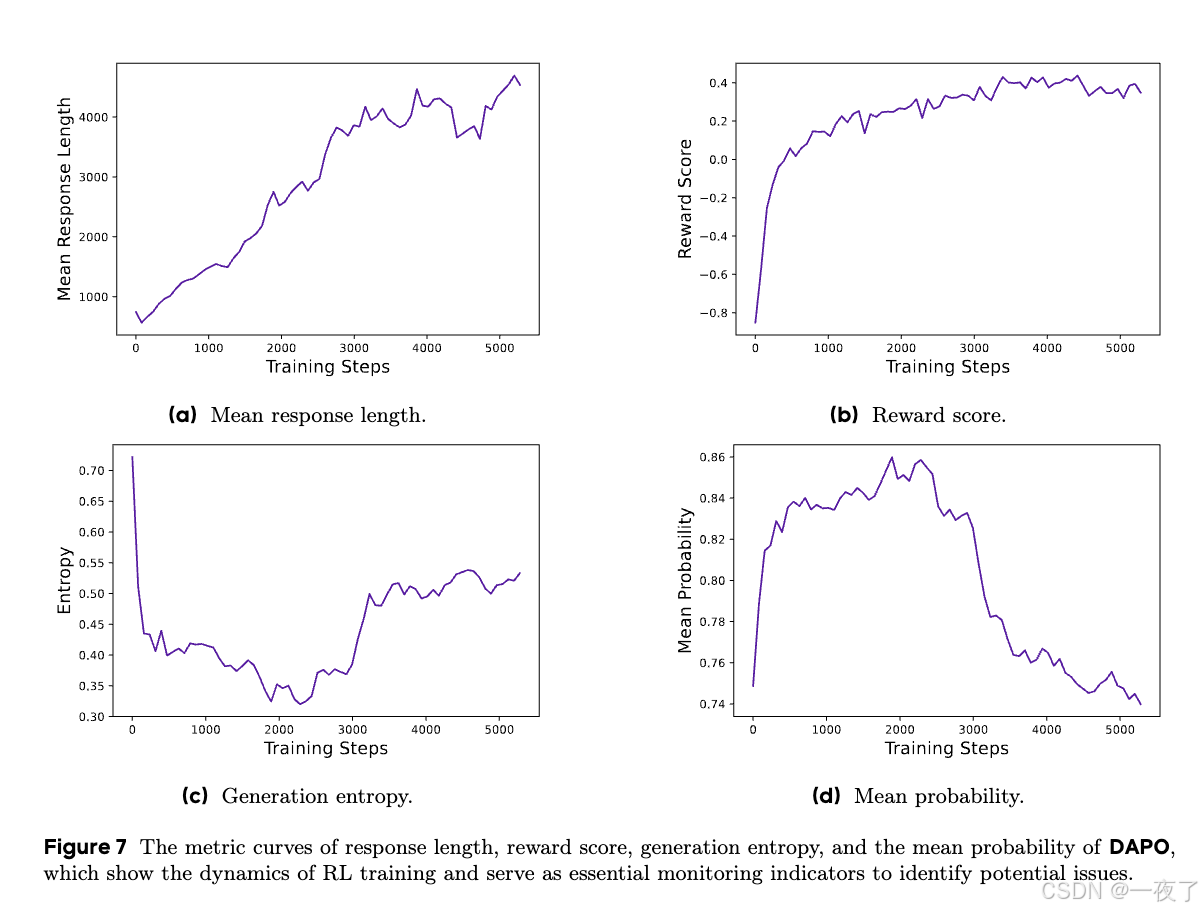
- The Length of Generated Responses:response长度是一个在训练中重要的监测指标,但是训练过程中,response长度并不总是增加,甚至不变或减小。通常要将长度与validation精度结合使用。
- The Dynamics of Reward:reward是训练过程中的重要指标,一般情况下都会稳定的增长。但是如果训练中reward与validation set上的accuracy不相关,表示模型在训练集上overfitting。
- The Entropy of the Actor Model and Generation Probability:关系到训练中actor模型的探索能力,所以是需要密切关注的指标。直觉上,模型的entropy应该保持在一个稳定的区间。过低的entropy表示概率分布过于尖锐,导致探索能力的丧失。过高的entropy与模型过度探索有关,例如胡言乱语和重复生成等。对于生成概率,情况正好相反,通过clip-higher策略,有效的解决了entropy崩溃问题。在随后的实验中,发现保持entropy的缓慢上升趋势有利于模型性能的提高,如图7c和7d所示。
5. 总结
在本文中,我们发布了一个完全开源的大规模LLM RL系统,包括算法、代码基础架构和数据集。该系统实现了最先进的大规模LLM RL性能(AIME 50使用Qwen-32B预训练模型)。我们提出了Decoupled Clip和Dynamic sAmpling Policy Optimization(DAPO)算法,并介绍了4个关键技术,使RL在long cot 场景中强大而高效。