博客网站程序我是站长网
今天是学Python算法的第1天,第一卷:起行。

目录
题引
序言
章一:悟透韬略——概念
章二:洞晓玄机——特性
1.输入
2.输出
3.有穷性
4.确定性
5.可行性
章三:优胜劣汰——优化
章四:统一度量衡——时间复杂度
1.引入
2.定义
3.大O记法
4.时间复杂度分类
5.几条基本计算规则
6.计算
7.常见的时间复杂度
章五:如虎添翼——timeit模块
章六:实例:Python中列表类型不同操作的时间效率
章七:列表和字典操作的时间复杂度
章八:数据结构引入
题引
概念
Python中的数据结构
算法和数据结构的区别
章九:抽象数据类型
引
概念
尾声
题引
如果将最终写好运行的程序比作战场,
我们便是指挥作战的将军,
而我们所写的代码便是士兵和武器。
那么数据结构和算法是什么?
答曰:兵法!
序言
有这样一道题:
有三个自然数,a,b,c,已知a+b+c=100,且a^2+b^2+c^2=100,求a,b,c,所有的组合。
这个问题我们应该怎么解决?第一想法:一个个试——即枚举法。
所以这时我们的思路为:a=0,b=0,c从0试验到1000,符合a^2+b^2+c^2=100就写下来,一轮试过后,再改变a或b的一个变量,继续试验……
# 普通算法
import time
start_time = time.time()
for a in range(0,1001):for b in range(0,1001):for c in range(0,1001):if a+b+c == 1000 and a**2 + b**2 == c**2:print(a,b,c)
end_time = time.time()
print("time:%d"%(end_time-start_time))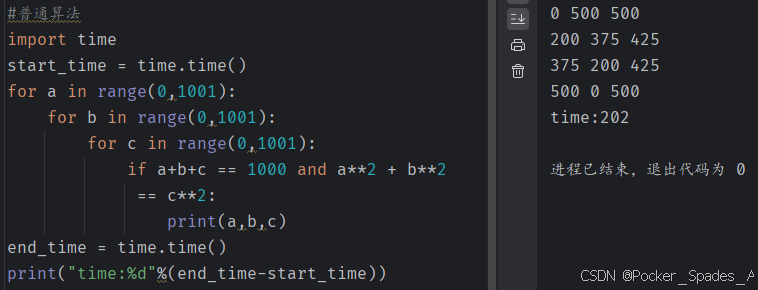
章一:悟透韬略——概念
算法是计算机处理信息的本质,因为计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务。一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写入输出设备或某个存储地址,供以后再调用。
算法是独立存在的一种解决问题的方法和思想,如序言中的枚举法。
对于算法而言,实现的语言并不重要,重要的是思想。
算法可以有不同的语言描述实现版本(如c描述,c++描述,Python描述等),我现在是在用Python语言进行描述实现。
章二:洞晓玄机——特性
1.输入
算法具有0个或多个输入。
2.输出
算法至少有一个或多个输出。
3.有穷性
算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成。
4.确定性
算法中的每一步都有确定的含义,不会出现二义性。
5.可行性
算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成。
章三:优胜劣汰——优化
优化序言中题目的思路:
因为当a,b确定时,c也能确定,所以可以改进程序。
import time
start_time = time.time()
for a in range(0,1001):for b in range(0,1001):c = 1000 - a - bif a+b+c == 1000 and a**2 + b**2 == c**2:print(a,b,c)
end_time = time.time()
print("time:%d"%(end_time-start_time))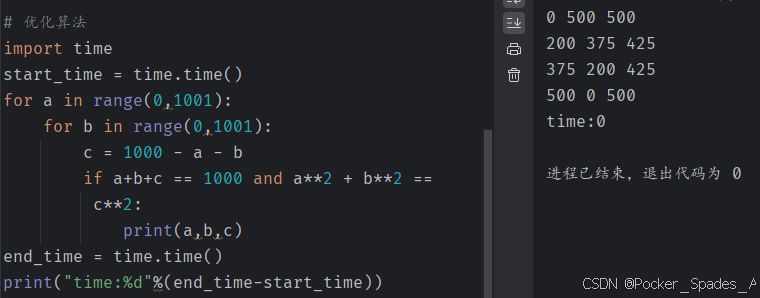
对于同一问题我们给出了两种解决算法,在两种算法的实现中,我们对程序执行的时间进行了测算,发现两段程序执行的时间相差悬殊(202秒相较于0秒)。
由此我们可以得出结论:实现算法程序的执行时间可以反映出算法的效率,即算法的优劣。
章四:统一度量衡——时间复杂度
1.引入
如果我们将第二次尝试的算法程序运行在一台配置古老,性能低下的计算机中,情况会如何?
所以,单纯依靠运行的时间比较算法的优劣并不一定是客观准确的!
于是,我们应该统一度量衡。
因为每台机器执行的总时间不同,但是执行基本运算数量大体相同,如上面的例题,T=N*N*N*2,所以T(n)=n^3*2,所以我们把这个T(n)的函数叫做这个算法的时间复杂度。
2.定义
假设存在函数g,使得算法A处理规模为n的问题示例所用时间为T(n)=O(g(n)),则称为O(g(n))为算法A的渐进时间复杂度,简称时间复杂度,记为T(n)。
对于算法的时间效率,我们可以用“大O记法”来表示。
3.大O记法
对于单调的整数函数f,如果存在一个整数函数g和实常数c(c>0),使得对于充分大的n,总有f(n)<=c*g(n),就说函数g是f的一个渐进函数(忽略常数),记为f(n)=O(g(n)).也就是说在趋向无穷的极限意义下,函数f的增长速度受到函数g的约束,亦即函数f与函数g的特征相似。
4.时间复杂度分类
分析算法时,存在几种可能的考虑:
- 算法完成工作最少需要多少基本操作,即最优时间复杂度;
- 算法完成工作最多需要多少基本操作,即最坏时间复杂度;
- 算法完成工作平均需要多少基本操作,即平均时间复杂度。
对于最优时间复杂度,其价值不大,因为它没有提供什么有用信息,其反映的只是最乐观最理想的情况,没有参考价值。
对于最坏时间复杂度,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作。
对于平均时间复杂度,是对算法的一个全面评价,因此它完整的全面的反映了这个算法的性质。但另一方面,这种衡量并没有保证,不是每个计算都能在这个基本操作内完成。而且,对于平均情况的计算,也会因为应用算法的实力分布可能并不均匀而难以计算。
因此,我们主要关注算法的最坏情况,亦即最坏时间复杂度。
5.几条基本计算规则
1.基本操作,即只有常数项,认为其时间复杂度为O(1)
2.顺序结构,时间复杂度按加法进行计算。
3.循环结构,时间复杂度按乘法进行计算。
4.分支结构,时间复杂度取最大值。
5.判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略。
6.在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度。
6.计算
所以,序言中的题目,第一次的时间复杂度为:T(n)=O(n*n*n)=O(n^3),第二次的时间复杂度为:T(n)=O(n*n*(1+1))=O(n*n)=O(n^2)
由此可见第二种的算法要比第一种的算法时间复杂度好。
7.常见的时间复杂度
| 执行次数函数举例 | 阶 | 非正式术语 |
| 12 | O(1) | 常数阶 |
| 2n+3 | O(n) | 线性阶 |
| O(n^2) | 平方阶 | |
| O(log n) | 对数阶 | |
| O(nlog n ) | nlog n阶 | |
| O(n^3) | 立方阶 | |
| O(2^n) | 指数阶 |
注意:经常将以二为底的对数简写为log n
具体大小关系可以见下图:
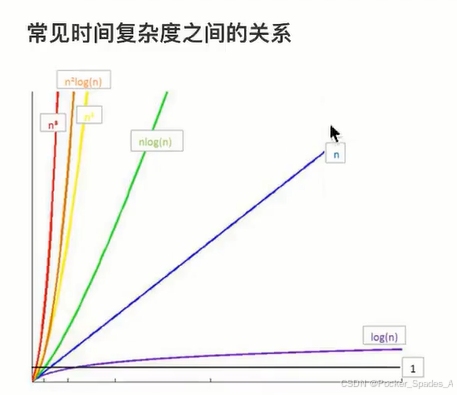
所消耗的时间大小从小到大(要背诵):
O(1)<O(log n)<O(n)<O(nlog n)<O(n^2)<O(n^3)<O(2^n)<O(n!)<O(n^n)
章五:如虎添翼——timeit模块
timeit模块可以用来测试一小段Python代码的执行速度。
class timeit.Timer(stmt = 'pass',setup = 'pass',timer = <timer function>Timer是测量小段代码执行速度的类;
stmt参数是要测试的代码语句(statment);
setup参数是运行代码时需要的设置;
timer参数是一个定时器函数,与平台有关。
import timeit
timeit.Timer.timeit(number=1000000)Timer类中测试语句执行速度的对象方法。number参数是测量代码时的测量次数,默认为1000000次。方法返回执行代码的平均耗时是一个float类型的秒数。
章六:实例:Python中列表类型不同操作的时间效率
from timeit import Timer
def test1():li= []for i in range(10000):li.append(i)def test2():li = []for i in range(10000):li += [i] # 缩写和不缩写不一样def test3():li = [i for i in range(10000)]def test4():li = list(range(10000))def test5():li =[]for i in range(10000):li.extend([i])timer1 =Timer("test1()", "from __main__ import test1")
# timer1.timeit(1000)返回的是花费多长时间,单位是秒
print("append:",timer1.timeit(1000))timer2 =Timer("test2()", "from __main__ import test2")
print("+",timer2.timeit(1000))timer3 =Timer("test3()", "from __main__ import test3")
print("[i for in range]:",timer3.timeit(1000))timer4 =Timer("test4()", "from __main__ import test4")
print("list(range()):",timer4.timeit(1000))timer5 =Timer("test5()", "from __main__ import test5")
print("extend:",timer5.timeit(1000))运行结果如下
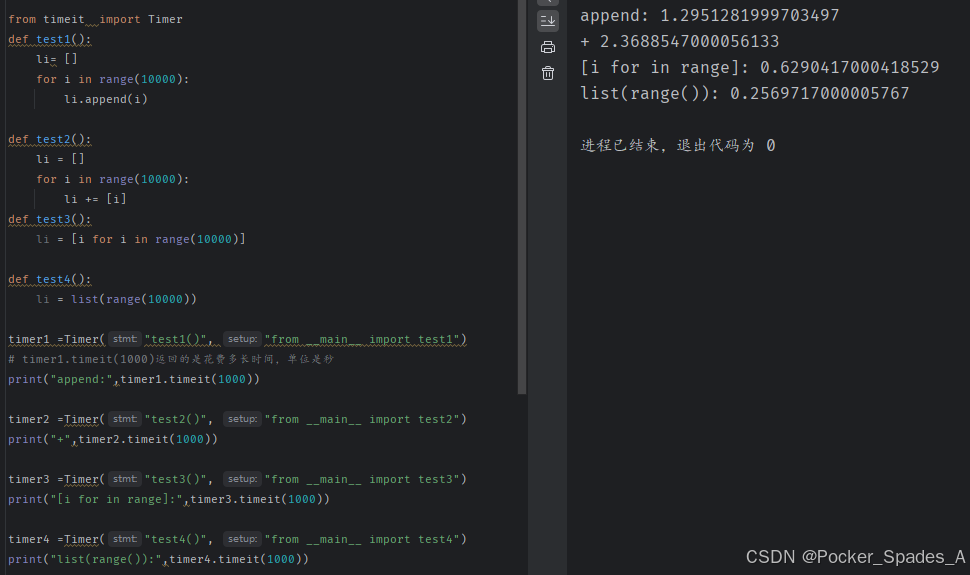
注意:缩写写法:li+ = 1和li = li+[i],不一样。
章七:牛刀小试——列表和字典操作的时间复杂度
| 操作 | 解释 | 算法复杂度 |
| index[x] | 索引操作 [x] | O(1) |
| index assignment | 索引赋值操作 | O(1) |
| append | 追加操作 | O(1) |
| pop() | 无参的弹出操作 | O(1) |
| pop(i) | 根据索引 i 进行的弹出操作 | O(n) |
| insert(i,item) | 在索引 i 处插入元素 item 的操作 | O(n) |
| del opearator | 删除操作符 | O(n) |
| iteration | 迭代操作 | O(n) |
| contains(in) | 包含操作(in) | O(n) |
| get slice[x:y] | 获取切片 [x:y] 操作 | O(k) |
| del slice | 删除切片操作 | O(n) |
| set slice | 设置切片操作 | O(n+k) |
| reverse | 反转操作 | O(n) |
| concatenate | 连接操作 | O(k) |
| sort | 排序操作 | O(n log n) |
| multiply | 乘法操作 | O(nk) |
| 操作 | 解释 | 算法复杂度 |
| copy | 复制操作 | O(n) |
| get item | 检查操作(使用 in) | O(1) |
| set item | 设置元素操作 | O(1) |
| delete item | 删除元素操作 | O(1) |
| contains(in) | 包含检查操作(使用 in) | O(1) |
| iteration | 迭代操作 | O(n) |
章八:初窥门径——数据结构引入
题引
例题:我们如何用Python中的类型来保存一个班的学生信息?(包括姓名,年龄,家乡)
方法:1.列表
列表中加上元组
l1 = [("zhangsan",24,"beijing"),("lisi",24,"beijing"),("wangwu",24,"beijing"),
]列表中加上字典
l2 = [{"name":"zhangsan","age":24,"hometown":"beijing",}
]2.字典
l3 = {"name":"zhangsan","age":24,"hometown":"beijing",
}如果我要在里面查找是否存在一个叫“zhangsan” 的同学,两者的查找时间复杂度有什么区别呢?
1.对列表
for item in l1:if item[0] == "zhangsan":print("在") # 时复杂度为O(n)2.对字典
if l3["name"] == "zhangsan":print("在") # 时间复杂度为O(1)所以,字典中查找要比列表中查找的时间复杂度要小。
概念
数据是一个抽象的概念,将其进行分类后得到程序设计语言中的基本类型。如:int,float,char等。数据元素之间不是独立的,存在特定的关系,这些关系便是结构数据。结构指数据对象中数据元素之间的关系。
Python中的数据结构
Python给我们提供了很多现成的数据结构类型,这些系统自己定义好的,不需要我们自己去定义的数据结构叫做Python的内置数据结构,比如列表,元组,字典,而有些数据组织方式,Python系统里面没有直接定义,需要我们自己去定义实现这些数据的组织方式,这些数据组织方式称为Python的扩展数据结构,比如栈、队列等。
算法和数据结构的区别
数据结构只是静态的描述了数据元素之间的关系。
高效的程序需要在数据结构的基础上设计和选择算法。
程序 = 数据结构 + 算法(重要)
总结:算法是为了解决实际问题而设计的,数据结构是算法需要处理的问题载体。
章九:另辟蹊径——抽象数据类型
引
如果对上述的学生信息查找换个方式实现,很多人会想到——面向对象程序设计,定义学生类,在类里面对学生进行查找,是不是更方便了?
在类里面,我们不仅能对学生进行查找,还能进行添加(转入新同学),删除(转走同学),排列(成绩等排名),修改(修改学生信息)等等。
class Stu(object) :def adds(self):def pop(self):def sort(self):def modify(self):当把数据结构和它所支持的方法放在一起的时候,就产生了一个新的概念。叫做抽象数据类型。
概念
抽象数据类型(ADT):一个数学模型以及定义在此数学模型上的一组操作。即把数据类型和数据类型上的运算捆在一起进行封装。引入抽象数据类型的目的是把数据类型的表示和数据类型上的运算的实现与这些数据类型的运算在程序中引用隔开,使它们相互独立。
最常用的数据运算有五种:查找,插入,删除,排序,修改。
尾声
数据结构和算法是一名程序开发人员的必备基本功,不是一朝一夕就能练成绝世高手的。冰冻三尺非一日之寒,需要我们平时不断的主动去学习积累。
(未完待续)