做刀模网站windows优化大师卸载不了
文章目录
- 前言
- 一、层次聚类(Hierarchical Clustering)
- 二、DBSCAN(基于密度的空间聚类)
- 三、高斯混合模型(GMM)
- 四、谱聚类(Spectral Clustering)
- 五、模糊 C 均值(Fuzzy C-Means)
- 六、算法选择指南
- 七、组合使用多种算法
前言
在 MATLAB 的 NLP 工具箱中,除了 K-Means 算法外,还支持多种文本聚类算法。以下是详细介绍及实现示例:
一、层次聚类(Hierarchical Clustering)
特点:
无需预先指定聚类数
生成树形结构,便于可视化
计算复杂度高,适合中小规模数据
实现示例:
% 计算相似度矩阵
similarity = cosineSimilarity(tfidf); % TF-IDF矩阵
distance = 1 - similarity; % 转换为距离矩阵% 执行层次聚类
linkageMatrix = linkage(distance, 'ward'); % Ward方法最小化方差% 绘制树状图
figure
dendrogram(linkageMatrix, 'Orientation', 'left', 'Labels', tbl.DocumentID)
title('文本层次聚类树状图')
xlabel('距离')% 切割树状图获取聚类
clusterIdx = cluster(linkageMatrix, 'Cutoff', 0.7*max(linkageMatrix(:,3)));
tbl.Cluster = categorical(clusterIdx);
二、DBSCAN(基于密度的空间聚类)
特点:
无需预先指定聚类数
能发现任意形状的聚类
可识别噪声点(不属于任何聚类)
对参数敏感(ε 和 MinPts)
实现示例:
% 计算距离矩阵
distance = pdist2(tfidf, tfidf, 'cosine'); % 余弦距离% 执行DBSCAN
epsilon = 0.5; % 邻域半径
minPts = 5; % 最小点数
clusterIdx = dbscan(distance, epsilon, 'Distance', 'precomputed', 'MinPts', minPts);% 可视化聚类结果
figure
gscatter(tfidf(:,1), tfidf(:,2), clusterIdx, 'rgbcmyk', 'osd^v><')
title('DBSCAN文本聚类结果')
xlabel('特征1')
ylabel('特征2')
legend('Location', 'best')
三、高斯混合模型(GMM)
特点:
基于概率分布的软聚类
适合表示数据的概率分布
输出每个样本属于各聚类的概率
实现示例:
% 训练GMM模型
gmm = fitgmdist(tfidf, numClusters, 'CovarianceType', 'diagonal');% 获取聚类标签
clusterIdx = cluster(gmm, tfidf);
tbl.Cluster = categorical(clusterIdx);% 获取属于每个聚类的概率
probabilities = posterior(gmm, tfidf);
四、谱聚类(Spectral Clustering)
特点:
基于图论的聚类方法
对非线性结构的数据效果好
计算相似度矩阵和拉普拉斯矩阵
实现示例:
% 计算相似度矩阵
similarity = exp(-pdist2(tfidf, tfidf, 'cosine') / (2*sigma^2));% 构建拉普拉斯矩阵
degreeMatrix = diag(sum(similarity, 2));
laplacianMatrix = degreeMatrix - similarity;% 特征分解
[eigenVectors, ~] = eigs(laplacianMatrix, numClusters, 'sm');% 对特征向量进行K-Means聚类
clusterIdx = kmeans(eigenVectors, numClusters);
五、模糊 C 均值(Fuzzy C-Means)
特点:
软聚类方法,每个样本以一定程度属于多个聚类
参数 m 控制模糊程度(通常 m=2)
实现示例:
% 使用Statistics and Machine Learning Toolbox
fuzzyPartition = fcm(tfidf, numClusters, 'Options', [2 100 1e-5 0]);% 获取聚类中心和隶属度矩阵
centers = fuzzyPartition.Centers;
membership = fuzzyPartition.U;% 获取硬聚类标签
[~, clusterIdx] = max(membership, [], 1);
tbl.Cluster = categorical(clusterIdx');
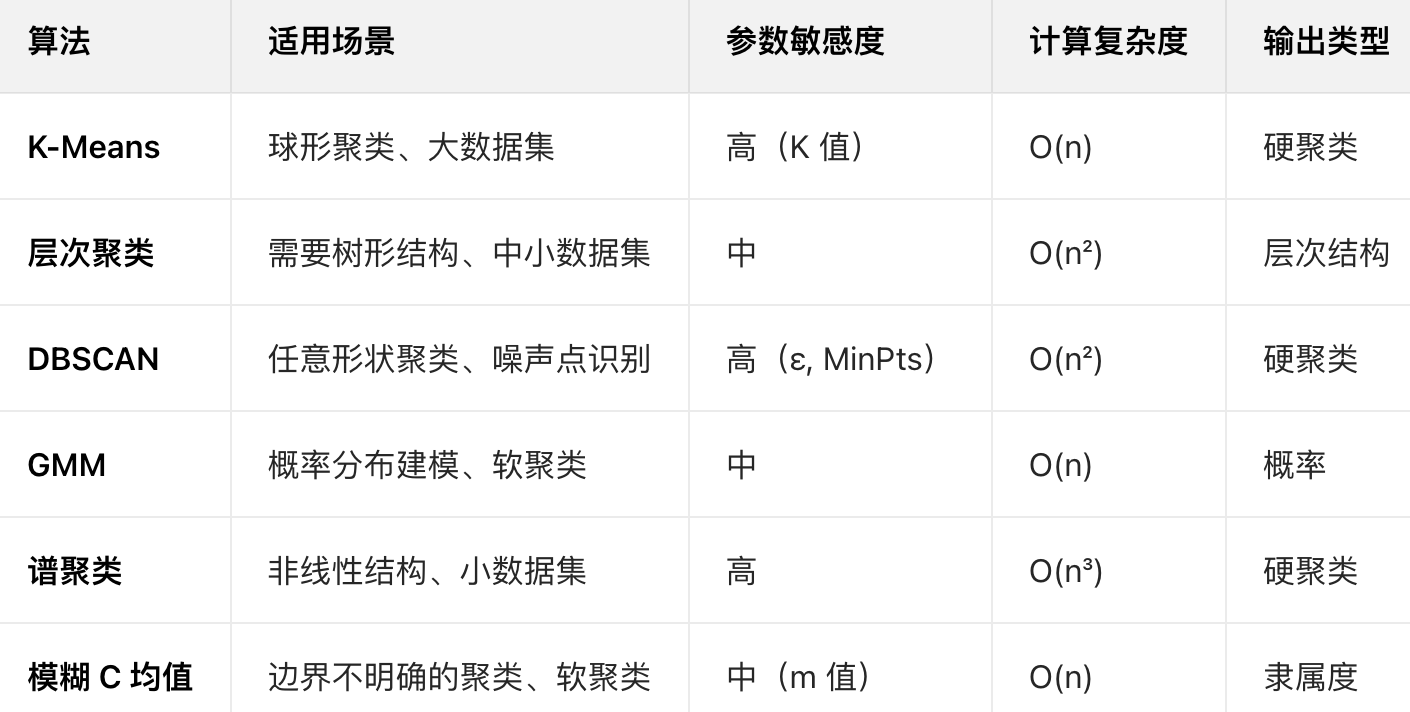
六、算法选择指南
七、组合使用多种算法
% 集成多种聚类结果
kmeansIdx = kmeans(tfidf, numClusters);
hierarchicalIdx = cluster(linkageMatrix, 'MaxClust', numClusters);
dbscanIdx = dbscan(distance, epsilon, 'MinPts', minPts);% 构建一致性矩阵
consensusMatrix = zeros(height(tbl));
consensusMatrix = consensusMatrix + (kmeansIdx*ones(1, height(tbl)) == ones(height(tbl), 1)*kmeansIdx');
consensusMatrix = consensusMatrix + (hierarchicalIdx*ones(1, height(tbl)) == ones(height(tbl), 1)*hierarchicalIdx');% 基于一致性矩阵进行最终聚类
finalIdx = kmeans(consensusMatrix, numClusters);