怀远网站建设百度高级搜索网址
1. 找到视频播放网站
百度一下 龙珠视频播放 精挑细选一个可以播放的网站。
如:我在网上随便找了一个播放网站,可以直接在线播放 https://www.xxx.com/play/39999-1-7.html
这里不具体写视频地址了,大家可以自行搜索
2.分析网页DOM结构 找出视频资源地址
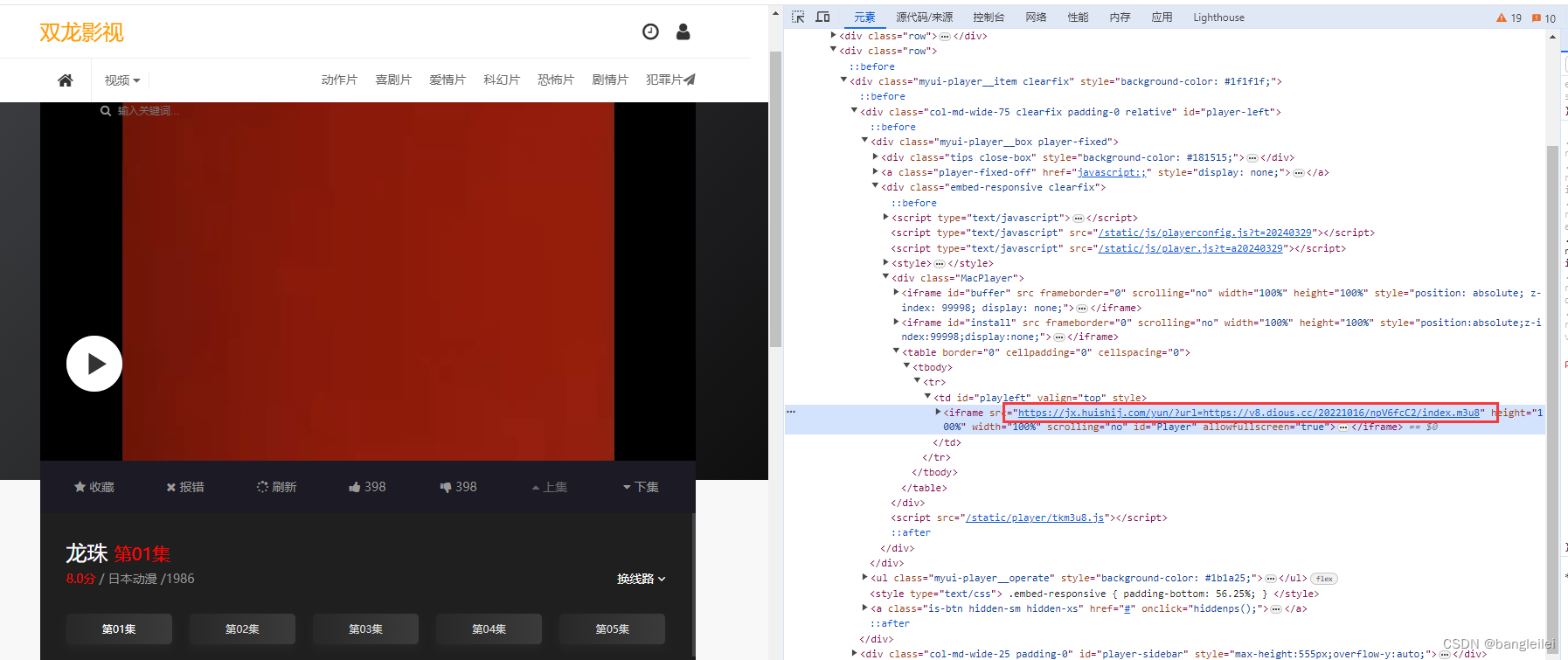
可以看到 整块播放内容在 td#playleft 下的 iframe 引入。
验证一下:把 https://xxx/yun/?url=https://XXX/20221016/npV6fcC2/index.m3u8 地址在浏览器内直接访问 发现可以正常播放视频

那这串地址就是我们所需要的视频文件资源路径。那我们接下来就需要想办法根据这个路径把视频保存到本地。
3.批量获取视频播放地址
虽然通过第二步的操作 我们可以拿到了第一话的视频资源地址,但是是手动完成的。需要想办法能批量的拿到第一部153话的所有资源地址。
想拿到所有视频的视频资源地址的前提是拿到所有视频的播放地址。所以我们要先想办法拿到每一集的播放地址。
点击播放第1话 第2话 第3话 ,可以看到 浏览器URL 分别是
第1话 /play/39999-1-1.html
第2话 /play/39999-1-2.html
第3话/play/39999-1-3.html
分析视频网站的地址不难看出 规律, 递增n就可以获取到每一话的在线播放地址
let n = 1
let urlArr = []
while(n < 154){urlArr.push('/play/39999-1-' +n+'.html' ) n++
}
console.log(urlArr )
4.批量获取视频资源地址
通过第三步我们已经拿到了 每一话的播放地址,那就要想办法拿到 每一个播放地址下的td#playleft 下的 iframe 的 src。
1.第一次尝试
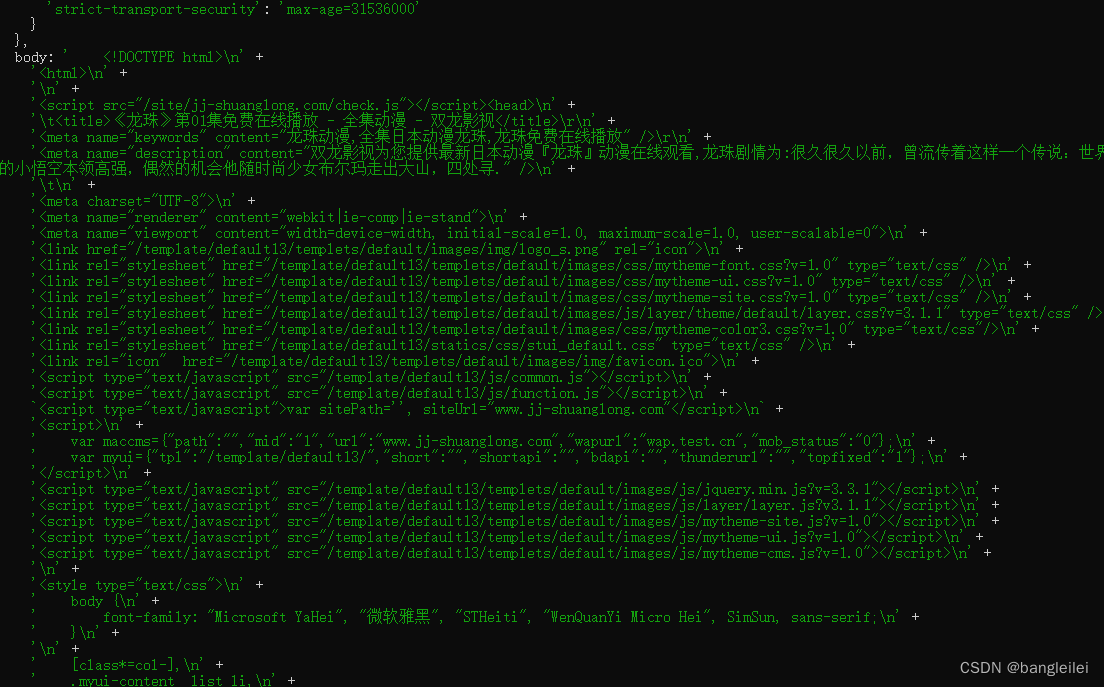
直接获取 /play/39999-1-1.html 的页面结构,尝试从返回的dom中找到 td#playleft 下的 iframe。但是并没有找到相关的DOM,推测应该是动态添加的 节点,第一次尝试失败
var request = require('request');request(`https://www.xxx.com/play/39999-1-1.html`, function (err, res, body) {console.log(err, res, body);
});
2.第二次尝试
既然直接拿不到那就等页面加载完成再去拿,所以第二种方案就是 在本地项目中 通过 iframe引入
https://www.xxx.com/play/39999-1-1.html 等 iframe onload之后再去获取iframe.contentDocument 下的
<body><iframe id="iframe" src="https://www.xxx.com/dragon/39999-1-1.html" onload="loadPage()" frameborder="0"></iframe>
</body><script>
function loadPage(e){let iframe = document.getElementsByTagName('iframe')[0]var iframeDocument = iframe.contentDocument || iframe.contentWindow.document;console.log(iframeDocument )
}
</script>
但是呢 并没有拿到 ,

虽然拿到了ifram的dom,但是呢 拿不到 contentDocument。
这是为什么呢?
新机呲挖一呲冒黑套呲 真相只有一个
iframe src 的跨域问题,
方案二失败
3.第三次尝试
第三次的尝试是和第二次思路一样的,所以主要任务是解决 iframe的跨域问题,
<iframe id="iframe" src="/dragon/39999-1-1.html" onload="loadPage()" frameborder="0"></iframe>代理一下吧
# 龙珠server {listen 9001;location / {root E:/dragonBall;index index.html index.htm;try_files $uri $uri/ @router;}location /dragon {proxy_pass https://www.xxx.com/play;}location /_guard {proxy_pass https://www.xxx.com;}location /template {proxy_pass https://www.xxx.com;}location /static {proxy_pass https://www.xxx.com;}}至此 终于拿到了 在线播放页面的全部DOM数据

那么简单的处理下数据 就可以拿到每一话的 视频资源地址了
(这里直接循环了,也可以直接使用第3步获取的视频播放地址,逻辑是一致的)
<script>let num = 1let arr = []function loadPage(e){arr = localStorage.getItem('streamUrl')if(arr){arr = JSON.parse(arr)}else{arr = []}if(num > 154) return let iframe = document.getElementsByTagName('iframe')[0]var iframeDocument = iframe.contentDocument || iframe.contentWindow.document;var iframeElement = iframeDocument.getElementById('playleft').getElementsByTagName('iframe')[0];let streamUrl = iframeElement.attributes.src.value.split('?url=')[1]console.log('这是第'+ num +"话:"+streamUrl)arr.push({index:num,url:streamUrl})num ++localStorage.setItem('streamUrl',JSON.stringify(arr))iframe.src = "/dragon/39999-1-"+num+".html"}
</script>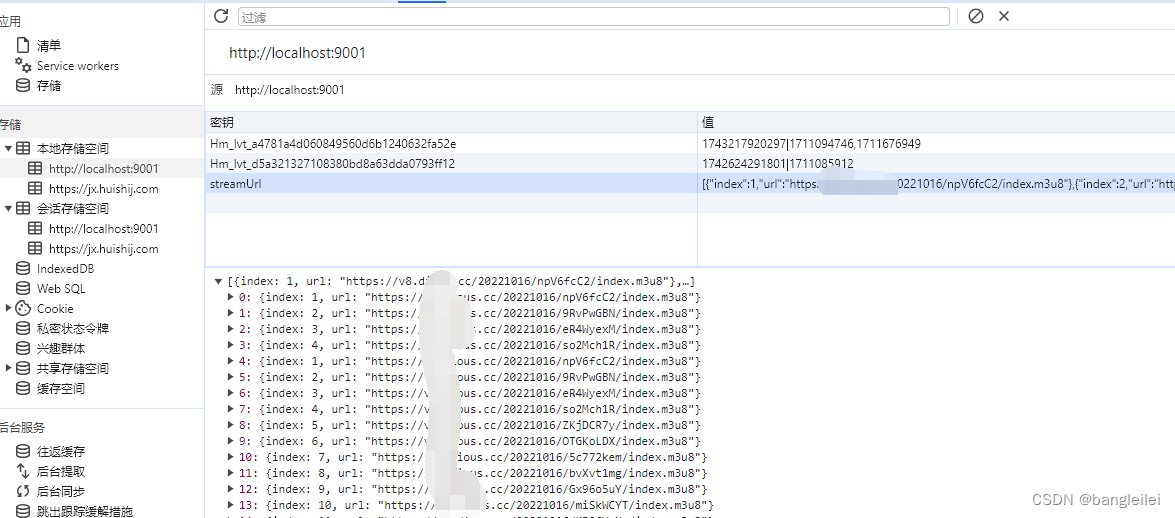
5.根据m3u8的资源地址下载视频
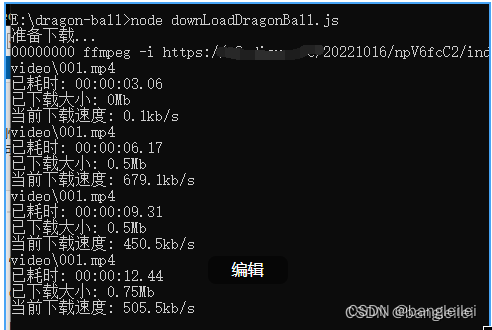
首先封装一个下载视频的函数
function downloadMedia (opt, callback) {// 测试视频,如果链接失效的话就自己找一个let url = opt.url ;let output = opt.output || 'video';let filename = opt.index + '.mp4';let title = opt.title || '测试视频';if (!fs.existsSync(output)) {fs.mkdirSync(output, {recursive: true,});}(async function() {try {console.log("准备下载...");await converter.setInputFile(url).setOutputFile(path.join(output, filename)).start();console.log("下载完成!");if ( typeof callback === 'function' ) callback(opt.index);} catch (error) {console.log(error)throw new Error("哎呀,出错啦! 检查一下参数传对了没喔。", error);}})(); }然后 再遍历一下我们拿到的视频资源地址 ,轮询调用一下 下载方法 就可以了
let arr = [{"index": 1,"url": "https://xxx/20221016/npV6fcC2/index.m3u8"},...{"index": 153,"url": "https://xxx/20221016/6AaX2hCl/index.m3u8"}
]let callback = function(index){let indexName = arr[index - 1].indexif(indexName.length === 1){indexName = '00' + indexName} if(indexName.length === 2){indexName = '0' + indexName}downloadMedia({url:arr[indexName].url,index:arr[indexName].index},callback)
}downloadMedia({url:arr[0].url,index:'001'},callback)我现在设置的是一次下载1个文件,也可以修改下同时下载多个,注意别把 视频网站搞崩了。
总结:
主要问题还是获取到资源地址。处理好资源地址的问题,就可以轮询下载了。
附:
gitee源码
仓库 - wangbanglei (wangbangleilei) - Gitee.com
注:仅供学习使用