美国地址生成器北京seo招聘
[AI] AI Agent快速入门
全部代码地址:
https://github.com/ziyifast/ziyifast-code_instruction/tree/main/python-demo/AI-demo/AI-Agent/transformer
本文主要使用Transformer库实现简易的AI Agent,了解AI领域的同学都知道除了Transformer还是一个LangChain,不过他们侧重点不同,Transformer更偏向底层(模型微调等),LangChain更偏向应用层(封装好了一系列API供我们使用)。
| 概念 | 类比 | 说明 |
|---|---|---|
| Transformer | 厨师 | 负责烹饪(处理语言),决定菜品口味 |
| LangChain | 餐厅经理 | 协调服务员、采购食材、管理订单流程 |
| AI Agent | 整个餐厅 | 由厨师和精力协作提供完整用餐体验 |
- Transformers 是由 Hugging Face 开发的一个开源库,它提供了大量预训练模型,主要用于自然语言处理(NLP)任务。这个库提供的模型可以用于文本分类、信息抽取、问答、文本生成等多种任务。
- Langchain 是一个高级库,用于构建语言理解应用。它主要关注于结合语言模型和其他技术(如搜索引擎、数据库)来构建复杂的语言理解系统。
主要方向:Transformers主要提供的是对于模型的底层访问和操作,因此我们可以利用Transformers用于模型训练、评估与推理进而微调各种NLP模型。对比之下,Langchain提供的是更加高级的接口,可直接开发上层应用。
概念
为什么LLM需要Agent
经常用AI的人都知道,AI的输出结果只能作为一个参考,这是为什么呢?因为虽然大语言模型的能力很强大,但是LLM仅限于用于训练的知识,这些知识很快会过时(虽然现在有联网功能,但依然免不了幻觉),所以LLM有以下缺点:
- 幻觉
- 结果并不总是真实的
- 对时事的了解有限或一无所知
- 难以应对复杂推理和计算
(虽然LLM完全理解了我的需求,但是它本身并不知道“我”所处的城市等信息)
而基于大模型的Agent (LLM based Agent) 可以利用外部工具来克服以上缺点。
ReAct核心定义
ReAct Agent 论文:https://arxiv.org/abs/2210.03629
ReAct = Reasoning(推理) + Action(行动),是一种AI Agent的设计范式:
- Reasoning:模型通过思考确定解决问题的最佳路径(如选择工具、分解步骤)
- Action:根据推理结果调用外部工具(如API、数据库)或执行操作
AI Agent典型流程:
实战
这里以查询天气的AI Agent为例,思路:
- 通过transformer库调用大模型
- 注册高德开发者,通过高德API直接查询城市天气。将该功能封装为工具,提供给AI
- transformers官方文档:https://huggingface.co/docs/transformers/index
- AI对话开发文档:https://huggingface.co/docs/transformers/main/chat_templating
- 解析AI返回结果
环境准备
- Python环境准备:本地需要有Python开发环境,我这里是Mac,所以自带Python。
- 方式一:可以选择直接下载PyCharm:https://www.jetbrains.com/pycharm/
- 方式二:直接从Python官方下载并配置:https://www.python.org/
- 高德API Key:注册高德开发者即可
- 注册高德开发者:https://developer.amap.com/api/webservice/guide/create-project/get-key
- 获取API Key:
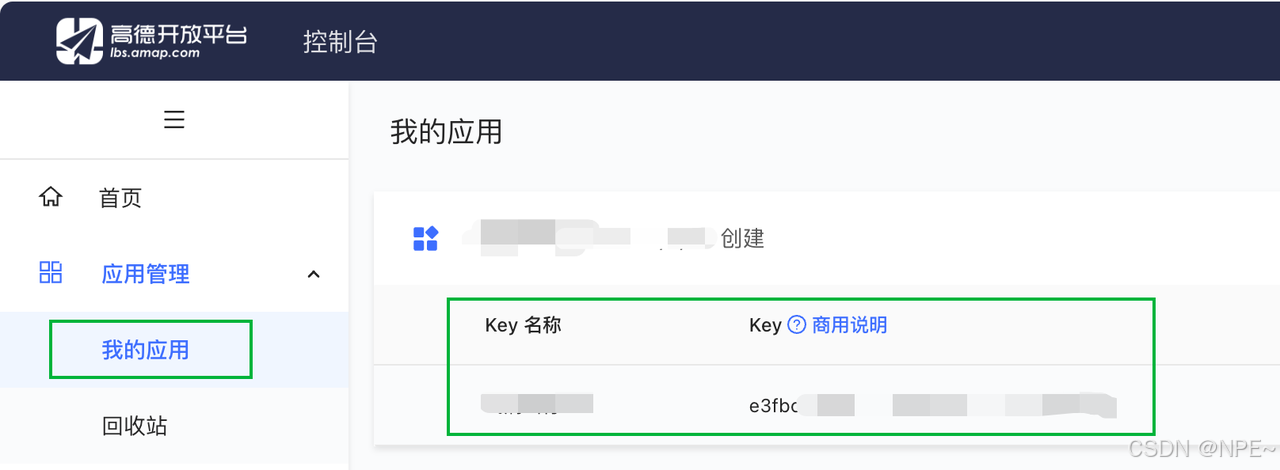
- 下载好之后,安装python依赖
pip install transformers
pip install requests
问题:如果出现ImportError: Using
low_cpu_mem_usage=Trueor adevice_maprequires Accelerate:pip install 'accelerate>=0.26.0'报错
解决:pip install accelerate==0.26.0
模型与工具初始化
加载Qwen大模型和对应的分词器
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name_or_path = "Qwen/Qwen2.5-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,torch_dtype="auto", # 自动选择精度device_map="auto" # 自动分配GPU/CPU
)
实现Agent核心能力:天气查询
这里主要实现Agent核心能力:调用高德API查询实时天气
- 获取行政区划代码
- 获取天气数据
①调用高德API获取行政区划代码
- 调用高德行政区划API
- 检查API返回状态码status
- 提取第一个匹配城市的adcode和名称
def get_abcode(city):url = "https://restapi.amap.com/v3/config/district?"params = {"key": GD_KEY, "keywords": city, "subdistrict": 0}try:response = requests.get(url=url, params=params)response.raise_for_status() # 自动抛出HTTP错误if response.json()["status"] == "1":return (response.json()["districts"][0]["adcode"], # 行政区划代码response.json()["districts"][0]["name"] # 城市名称)else:return Noneexcept Exception as e:print(f"Error: {e}")return None
②获取对应城市天气数据
def get_weather(cityname: str = "成都"):abcode, city_name = get_abcode(cityname)url = "https://restapi.amap.com/v3/weather/weatherInfo?"params = {"key": GD_KEY, "city": abcode, "extensions": "base"}try:response = requests.get(url=url, params=params)if response.json()["status"] == "1":return response.json()["lives"][0] # 实时天气数据else:return Noneexcept Exception as e:print(f"Error: {e}")return None
工具调用解析器
- 使用正则表达式提取<tool_call>标签内容
- 将内容解析为JSON对象
- 自动转换字符串类型的参数为字典
def try_parse_tool_calls(content: str):tool_calls = []# 正则匹配 <tool_call> 标签for m in re.finditer(r"<tool_call>\n(.+)?\n</tool_call>", content):try:func = json.loads(m.group(1)) # 解析JSON格式的工具调用# 参数自动类型转换if isinstance(func["arguments"], str):func["arguments"] = json.loads(func["arguments"])tool_calls.append({"type": "function", "function": func})except json.JSONDecodeError as e:print(f"解析失败: {e}")return {"tool_calls": tool_calls}
主对话循环
①消息模板构建
预制提示词以及大模型角色
MESSAGES = [{"role": "system","content": "你是由阿里云开发的助手Qwen\n当前日期:2024-05-20"},{"role": "user", "content": "查询北京天气"}
]
text = tokenizer.apply_chat_template(messages, tools=tools, # 声明可用工具add_generation_prompt=True, # 添加生成提示tokenize=False # 返回字符串而非token
)
②模型推理与输出解析
inputs = tokenizer(text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512)
output_text = tokenizer.decode(outputs[0][len(inputs[0]):])# 解析工具调用
response = try_parse_tool_calls(output_text)
if response["tool_calls"]:for tool_call in response["tool_calls"]:fn_name = tool_call["function"]["name"]fn_args = tool_call["function"]["arguments"]result = get_weather(**fn_args)print(f"工具调用结果:{result}")
运行效果
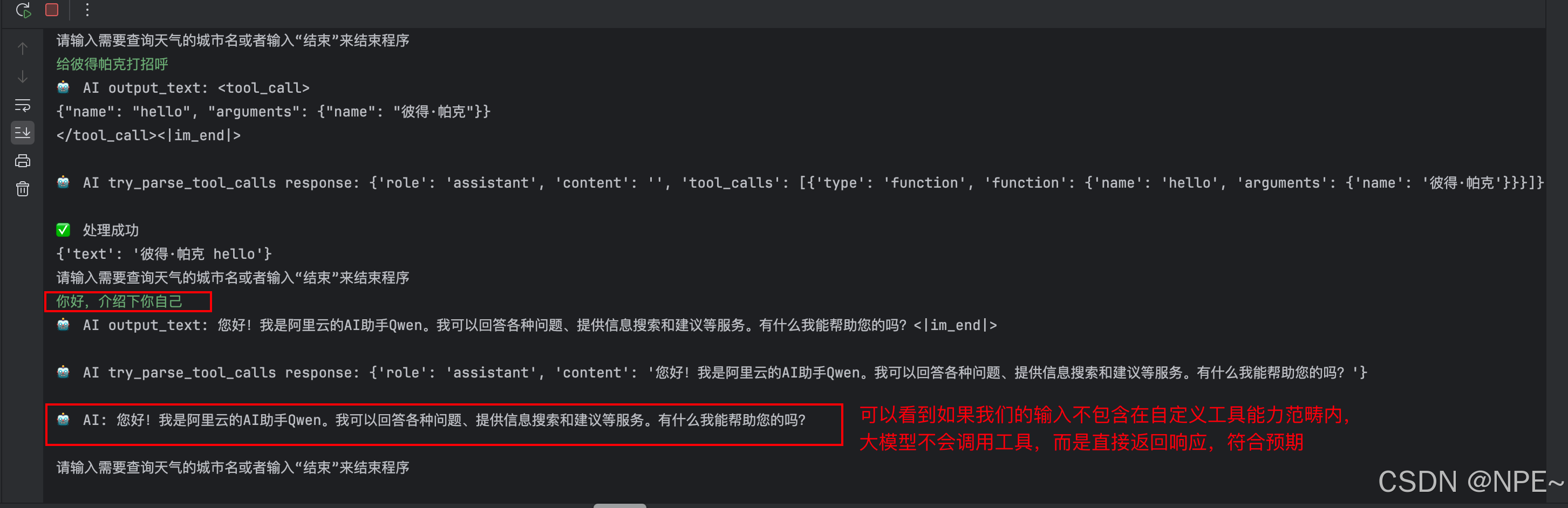
说明:这里为了给大家演示大模型对工具的选择,所以我Python完整代码里提供了两个工具,一个是查天气,一个是打招呼。
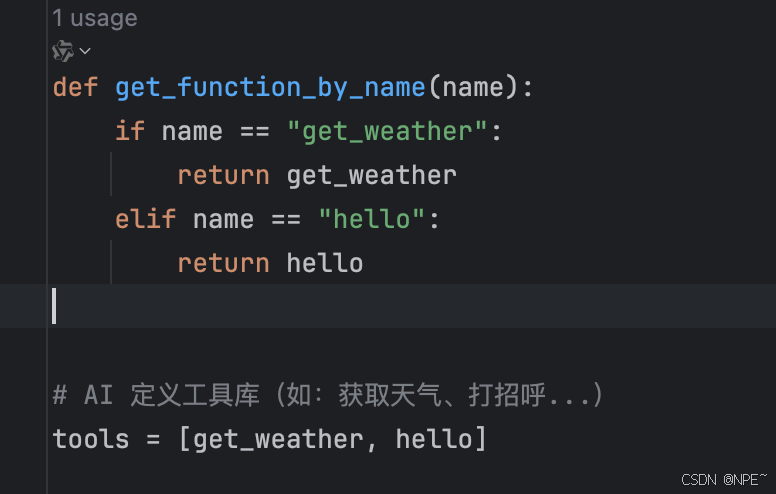
1. 案例一:调用天气查询功能
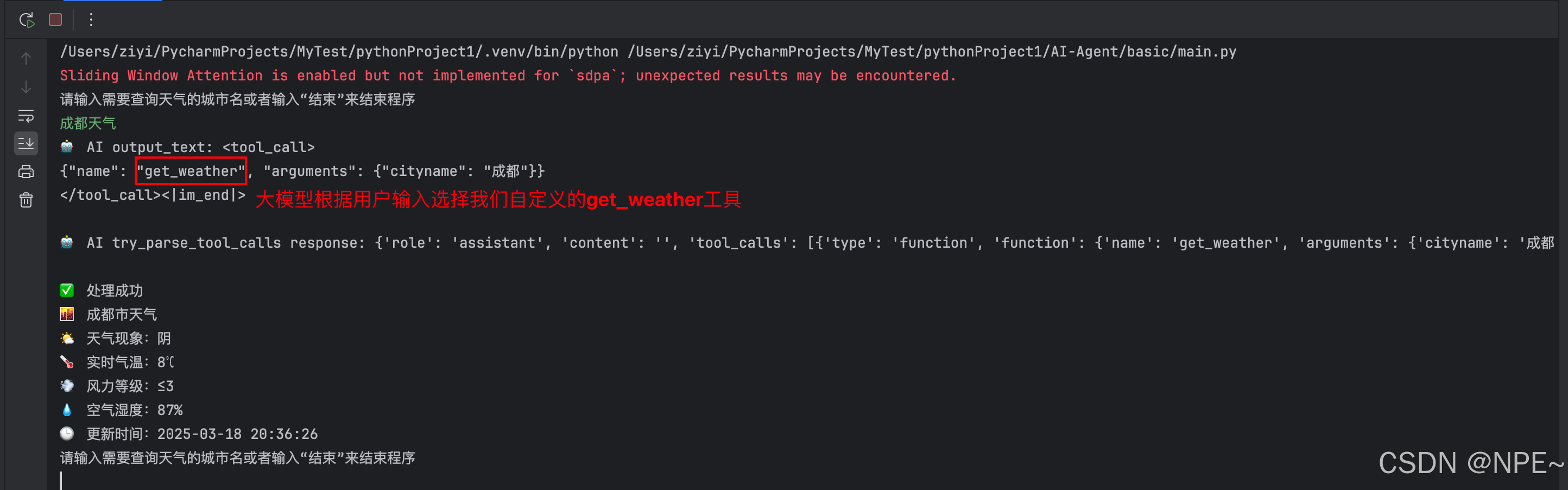
2. 案例二:调用打招呼功能
3. 案例三:正常对话功能
结合上面两个案例,可以看到大模型可以根据用户的输入分析并调用我们对应的自定义工具。下面我们试试其他功能,比如我们的输入都不包含在那两项里面:
全部代码
这里为了给大家演示大模型对工具的选择,所以我提供了两个工具,一个是查天气,一个是打招呼。
代码仓库地址:https://github.com/ziyifast/ziyifast-code_instruction/tree/main/python-demo/AI-demo/AI-Agent/transformer
from tool import GD_KEY
from transformers import AutoModelForCausalLM, AutoTokenizer
import datetime
import re
import json
import requests
# 基于transformers实现简易AI Agent:查询天气、打招呼等...# 选择大模型,这里以阿里的千问为例
model_name_or_path = "Qwen/Qwen2.5-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
# 加载配置模型参数
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,torch_dtype="auto", # 自动选择精度device_map="auto", # 自动分配GPU/CPU
)# 调用高德API:根据城市名称获取区划代码
def get_abcode(city):url = "https://restapi.amap.com/v3/config/district?"params = {"key": GD_KEY,"keywords": city,"subdistrict": 0,}try:response = requests.get(url=url, params=params)response.raise_for_status() # 检查请求是否成功if "1" == response.json()["status"]:abcode = response.json()["districts"][0]["adcode"]city_name = response.json()["districts"][0]["name"]return (abcode, city_name)else:return Noneexcept requests.exceptions.RequestException as e:# 处理请求异常print(f"Error during API request: {e}")return f"Error during API request: {e}"passdef hello(name: str):"""Say Hi.Args:name: 对谁打招呼Returns:text: 打招呼的内容"""return {"text": f"{name} hello"}# 根据城市名获取天气,
def get_weather(cityname: str = "成都"):# 这里需要添加函数注解,否则transformers会报:Cannot generate JSON schema# 同时这里的函数注解会喂给大模型,大模型会根据你的需求调用不同的tools工具来完成你的需求"""Get current weather at a location.Args:cityname:获取天气的城市, in the format "City".Returns:province: 省份名称,city: 市级城市名称,adcode: 城市的abcode,weather: 对于天气现象的描述,temperature: 实时气温,单位:摄氏度,winddirection: 风向描述,windpower:风力级别,单位:级,humidity: 空气湿度,reporttime: 数据发布的时间,temperature_float: 实时气温,单位:摄氏度 的float格式的字符串,humidity_float: 空气湿度 的float格式的字符串,"""abcode, city_name = get_abcode(cityname)url = "https://restapi.amap.com/v3/weather/weatherInfo?"params = {"key": GD_KEY, "city": abcode, "extensions": "base"}try:# 发送请求response = requests.get(url=url, params=params)response.raise_for_status() # 检查请求是否成功if "1" == response.json()["status"]:return response.json()["lives"][0]else:return Noneexcept requests.exceptions.RequestException as e:print(f"Error during API request: {e}")return f"Error during API request: {e}"def get_function_by_name(name):if name == "get_weather":return get_weatherelif name == "hello":return hello# AI 定义工具库(如:获取天气、打招呼...)
tools = [get_weather, hello]def try_parse_tool_calls(content: str):"""Try parse the tool calls."""tool_calls = []offset = 0for i, m in enumerate(re.finditer(r"<tool_call>\n(.+)?\n</tool_call>", content)):if i == 0:offset = m.start()try:func = json.loads(m.group(1))tool_calls.append({"type": "function", "function": func})if isinstance(func["arguments"], str):func["arguments"] = json.loads(func["arguments"])except json.JSONDecodeError as e:print(f"Failed to parse tool calls: the content is {m.group(1)} and {e}")passif tool_calls:if offset > 0 and content[:offset].strip():c = content[:offset]else:c = ""return {"role": "assistant", "content": c, "tool_calls": tool_calls}return {"role": "assistant", "content": re.sub(r"<\|im_end\|>$", "", content)}def get_current_data():dt = datetime.datetime.now()return dt.strftime("%Y-%m-%d")def format_response(data, fn_name):if fn_name == "get_weather":return (f"🌆 {data['city']}天气\n"f"🌤 天气现象:{data['weather']}\n"f"🌡 实时气温:{data['temperature']}℃\n"f"💨 风力等级:{data['windpower']}\n"f"💧 空气湿度:{data['humidity']}%\n"f"🕒 更新时间:{data['reporttime']}")elif fn_name == "hello":return datawhile True:input_1 = input("请输入需要查询天气的城市名或者输入“结束”来结束程序\n")if "结束" == input_1:breakdt = datetime.datetime.now()formatted_date = dt.strftime("%Y-%m-%d")MESSAGES = [{# 系统参数设置默认大模型角色"role": "system","content": f"You are Qwen, created by Alibaba Cloud. You are a helpful assistant.\n\nCurrent Date: {formatted_date}",},{# 接受用户输入的参数"role": "user","content": f"{input_1}",},]messages = MESSAGES[:]# 配置聊天模版以及对应的工具toolstext = tokenizer.apply_chat_template(messages, tools=tools, add_generation_prompt=True, tokenize=False)# 将用户输入的字符转换为模型可识别的数据inputs = tokenizer(text, return_tensors="pt").to(model.device)# 限制最大处理token数为512,同时根据用户输入调用对应的自定义工具toolsoutputs = model.generate(**inputs, max_new_tokens=512)# print(f"🤖️ AI outputs: {outputs}\n")# 将AI模型返回的数据转换为字符output_text = tokenizer.batch_decode(outputs)[0][len(text):]print(f"🤖️ AI output_text: {output_text}\n")# 根据AI返回的output_text获取需要调用的工具以及对应参数# 例:<tool_call># {"name": "get_weather", "arguments": {"cityname": "北京"}}# </tool_call><|im_end|>response = try_parse_tool_calls(output_text)print(f"🤖️ AI try_parse_tool_calls response: {response}\n")# 判断是否调用了自定义工具if not response.get("tool_calls", None):output = response.get("content", "")print(f"🤖️ AI: {output}\n")continuetry:for tool_call in response.get("tool_calls", None):if fn_call := tool_call.get("function"):fn_name: str = fn_call["name"]fn_args: dict = fn_call["arguments"]# 调用API获取数据fn_res: str = json.dumps(get_function_by_name(fn_name)(**fn_args), ensure_ascii=False)print(f"✅ 处理成功")print(format_response(json.loads(fn_res), fn_name))except Exception as e:print(f"❌ 查询失败:\n{e}")pass相关文章:
https://arxiv.org/abs/2210.03629
https://huggingface.co/docs/transformers/main/chat_templating