双塔模型3之线上召回与模型更新
双塔模型3之线上召回与模型更新
在训练好双塔模型之后,就可以部署到线上做召回,以及根据线上的数据对模型进行更新。
双塔模型的召回
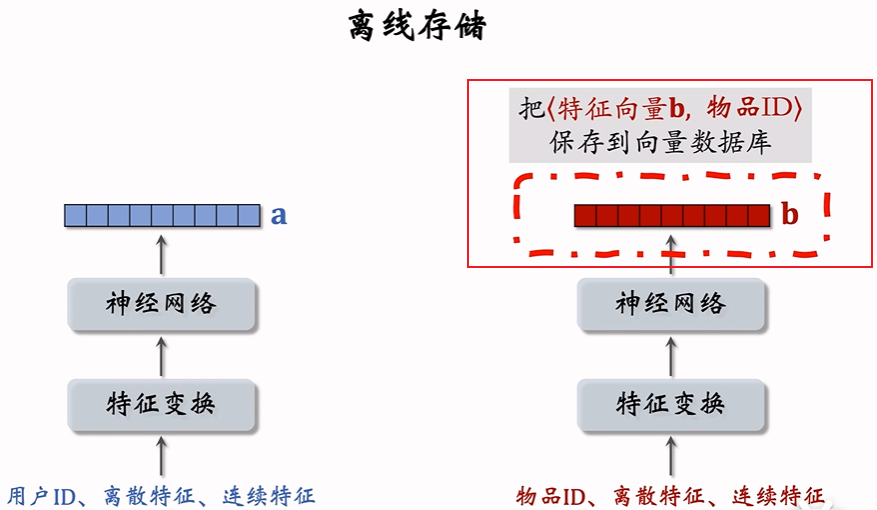
离线存储
在训练好模型之后,开始线上服务之前,将<物品特征向量b,物品ID>这样的二元组保存到向量数据库进行离线存储,方便最近邻查找
线上召回
用户塔,不需要事先计算和离线存储用户向量(注意这里的计算是指训练好神经网络之后不存储推理结果)。
而是当用户发起推荐请求的时候调用神经网络在线上算一个用户特征向量a。
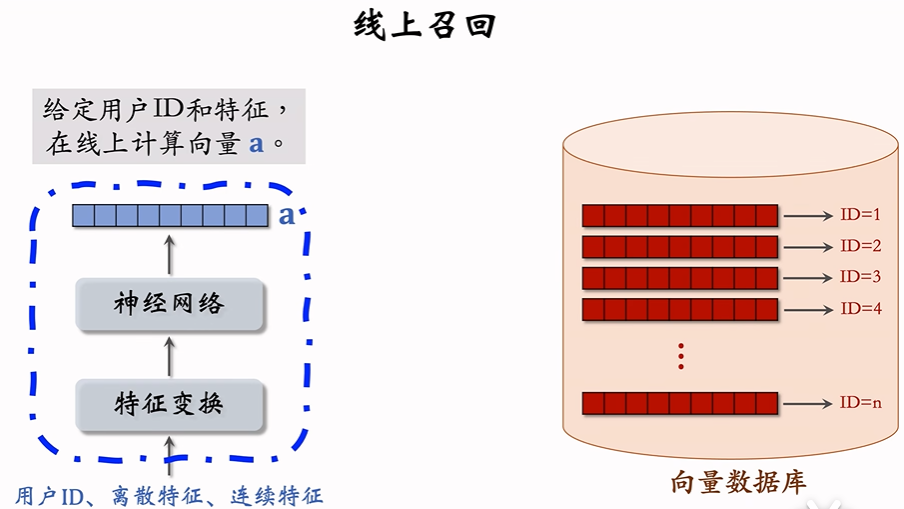
把a当作query去存储物品特征的向量数据库中做检索查找最近邻,也就是查找跟向量a最相似的k个红色向量。每个红色向量对应一个物品。
双塔模型召回小结
-
离线存储:把物品向量b存入向量数据库。
- 完成训练之后,用物品塔神经网络计算每个物品的特征向量 b 。
- 把几亿个物品向量 b 存入向量数据库(比如 Milvus、Faiss、HnswLib)。
- 向量数据库建索引,以便加速最近邻查找
-
线上召回:查找用户最感兴趣的k个物品
-
给定用户ID和画像,输入用户塔神经网络算出用户特征向量 a。
-
在向量数据库中根据 a向量做最近邻查找:
1)把向量 a 作为query,调用向量数据库做最近邻查找。
2) 返回余弦相似度最大的 k 个物品,作为双塔模型召回结果。然后本次召回结果会跟ItemCF, Swing,UseCF等召回通道的召回结果融合 ——> 排序 ——>展示给用户
-
思考 为何实现存储物品向量b,线上现算用户向量 a ?

双塔模型更新
在实践中,会涉及到模型的全量更新和增量更新。
全量更新
每次用前一天的数据生成TFRecord文件 再做random shuffle打乱 然后做随机梯度下降 只训练1epoch即每条数据只过一遍。

增量更新
做 online learning 更新模型参数,每几十分钟就发布新的模型,刷新线上用户塔 embedding层参数。
用梯度下降,来更新 的参数。注意增量更新只更新Embedding层的参数,做全量更新时才会更新全连接层参数。(why? 主要是出于工程实践的考虑)

发布用户 ID Embedding 的目标是为了线上计算用户特征向量。
最新的 ID Embedding 可以捕捉到用户最新的兴趣点,对推荐很有帮助。
发布用户 ID Embedding 这个过程会有延迟,通过对系统做优化可以降至几十分钟甚至更短。
全量更新 vs 增量更新
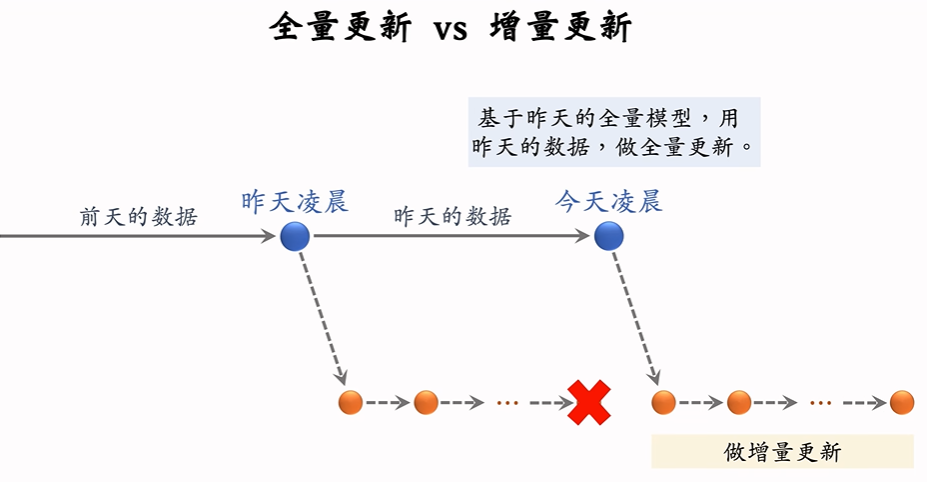
问题:能否只做增量更新,不做全量更新?如下图

答:只做增量效果不好。不如上面全量更新和增量更新相结合的方式(全量更新效果更好,增量更新可实时捕捉用户兴趣)。
双塔模型总结

召回总结

模型更新总结
