【斯坦福】【ICLR】RAPTOR:基于树结构的检索增强技术详解
重磅推荐专栏:
《大模型AIGC》
《课程大纲》
《知识星球》
本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展
在处理长文档和复杂知识库时,如何高效地检索和利用信息是一个关键问题。传统的检索增强方法往往只能处理短文本片段,难以捕捉文档的整体语义结构。为了解决这一问题,斯坦福大学的研究团队提出了 RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval),一种基于树结构的检索增强方法,它通过递归地嵌入、聚类和摘要文本块,构建了一个多层次的树状结构,从而实现了对长文档的高效检索和理解。
RAPTOR 概述
上图展示了 RAPTOR 树的构建过程。从叶节点(文本块)开始,通过递归地嵌入、聚类和摘要,构建出一个多层次的树状结构。每个父节点包含其子节点的摘要,从而形成了不同抽象层次的表示。
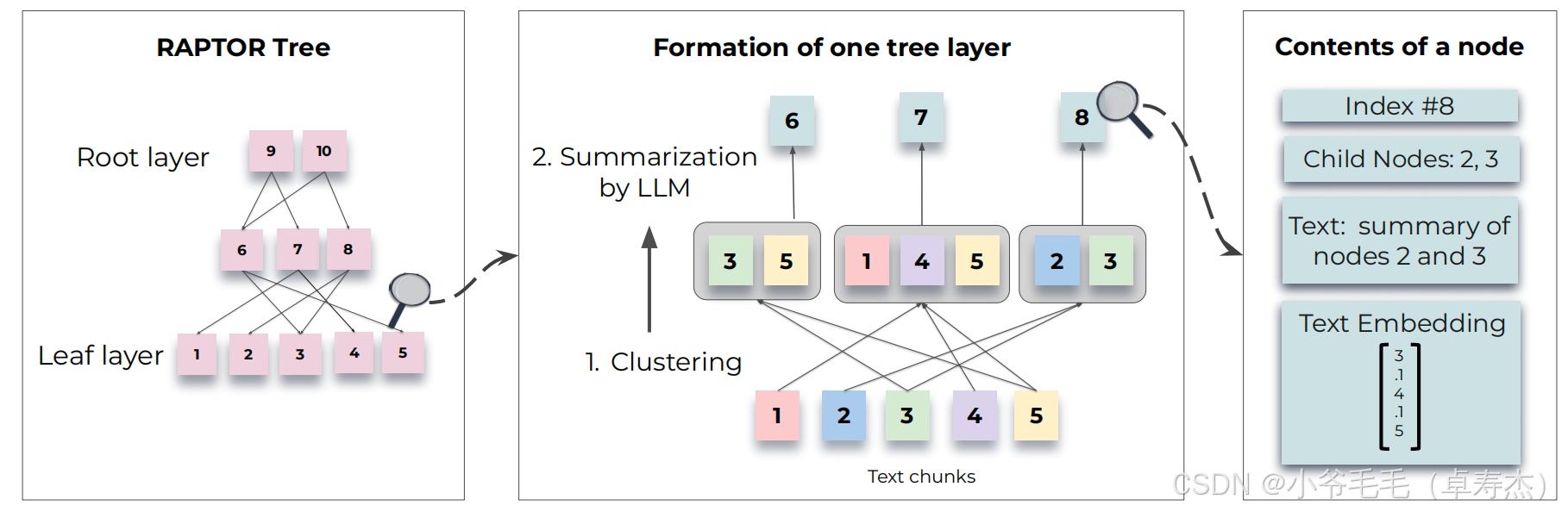
RAPTOR 的核心思想是利用文本摘要来允许在不同尺度上进行检索增强,从而有效地处理长文档。它通过以下步骤构建树状结构:
- 文本分割与嵌入:将检索语料库分割成短文本块(约 100 个 token),并使用 SBERT(Sentence-BERT)对这些文本块进行嵌入,形成叶节点。
- 聚类与摘要:对嵌入后的文本块进行聚类,然后使用语言模型对每个聚类生成摘要。这些摘要被重新嵌入,并重复聚类和摘要的过程,直到无法再进行聚类为止,从而构建出一个多层次的树状结构。
- 检索策略:在查询时,RAPTOR 提供了两种检索策略——树遍历和折叠树,用于从构建好的树中检索相关信息。
这种树状结构使得 RAPTOR 能够在不同抽象层次上整合信息,从而更好地适应文档的整体语境,并在各种检索任务中表现出色。
聚类算法
聚类算法在构建 RAPTOR 树的过程中起着至关重要的作用。RAPTOR 采用了基于高斯混合模型(GMM)的软聚类方法,允许文本块属于多个聚类,从而更好地捕捉文本中的语义关联。
高斯混合模型(GMM)
GMM 假设数据点是从多个高斯分布的混合中生成的。对于每个文本块的嵌入向量 x,其属于第 k 个高斯分布的概率为:
P ( x ∣ k ) = N ( x ; μ k , Σ k ) P(x|k) = \mathcal{N}(x; \mu_k, \Sigma_k) P(x∣k)=N(x;μk,Σk)
其中, μ k \mu_k μk