《Java编程思想》读书笔记:第八章 多态
目录
8.1再论向上转型
8.1.1忘记对象类型
8.2转机
8.2.1方法调用绑定
8.2.2产生正确的行为
8.2.3可扩展性
8.2.4缺陷:“覆盖”私有方法
8.2.5缺陷:域与静态方法
8.3构造器和多态
8.3.1构造器的调用顺序
8.3.2继承与清理
8.3.3构造器内部的多态方法的行为
8.4协变返回类型
4.5用继承进行设计
8.5.1纯继承与扩展
8.5.2向下转型与运行时类型识别
8.1再论向上转型
在第7章中我们已经知道,对象既可以作为它自己本身的类型使用,也可以作为它的基类型使用。而这种把对某个对象的引用视为对其基类型的引用的做法被称作向上转型——因为在继承树的画法中,基类是放置在上方的。
但是,这样做也有一个问题,具体看下面这个有关乐器的例子。
首先,既然几个例子都要演奏乐符(Note),我们就应该在包中单独创建一个Note类。
package polymorphism.music;
public enum Note {
HIDDLE_C, C_SHARP, B_FLAT;// Etc.
}
enum在第五章中介绍过
在这里,Wind是一种Instrument,因此可以从Instrument类继承
//polymorphism/music/Instrument.java
package polymorphism.music;
import static net.mindview.uti1.Print .* ;
class Instrument {
public void play (Note n) {
print(" Instrument.play (");
}
}
//polymorphism/music/wind.java
package polymorphism.music;
public class wind extends Instrument{
public void play (Note n) {
System.out.println( "wind.play()"+n);
}
}
//polymorphism/music/Husic.java
package polymor phism.music ;
public class Husic {
public static void tune ( Instrument i){
//...
i.play(Note.HIDDLE_c);
}
public static void main(string[] args) {
wind flute = new wind() ;
tune(flute);
}
}Output :
wind.play MIDDLE_C
Music.tune()方法接受一个Instrument引用,同时也接受任何导出自Instrument的类。在main()方法中,当一个Wind引用传递到tune()方法时,就会出现这种情况,而不需要任何类型转换。这样做是允许的——因为Wind从Instrument继承而来,所以Instrument的接口必定存在于Wind中。从Wind向上转型到Instrument可能会“缩小”接口,但不会比Instrument的全部接口更窄。
8.1.1忘记对象类型
Music.java看起来似乎有些奇怪。为什么所有人都故意忘记对象的类型呢?在进行向上转型时,就会产生这种情况:并且如果让tune()方法直接接受一个Wind引用作为自己的参数,似乎会更为直观。但这样引发的一个重要问题是:如果那样做,就需要为系统内Instrument的每种类型都编写一个新的tune()方法。假设按照这种推理,现在再加入Stringed(弦乐)和Brass(管乐)这两种Instrument(乐器):
//:polymorphism/music/Music2.java
package polymorphism.music ;
import static net.mindview.uti1.Print.* ;
class stringed extends Instrument {
public void play (Note n) {
print ("stringed.play() "+ n);
}
}
class Brass extends Instrument {
public void play (Note n) {
print ( "Brass.play() " + n) ;
}
}
public class Nusic2 {
public static void tune(wind i) {
i.play (Note.MIDDLE_C);
}
public static void tune(Stringed i){
i.play (Note.MIDDLE_C);
}
public static void tune (Brass i){
i.play (Note.HIDDLE_C);
}
public static void main(String[] args) {
Wind flute =new Wind () ;
Stringed violin = new Stringed() ;
Brass frenchHorn = new Brass();
tune(flute) ;
tune(violin) ;
tune(frenchHorn) ;
}
}Output :
Wind.play() MIDDLE_C
Stringed.play() HIDDLE_C
Brass.play() HIDDLE_C
这样做行得通,但有一个主要缺点:必须为添加的每一个新Instrument类编写特定类型的方法。这意味着在开始时就需要更多的编程,这也意味着如果以后想添加类似tune()的新方法,或者添加自Instrument导出的新类,仍需要做大量的工作。此外,如果我们忘记重载某个方法,编译器不会返回任何错误信息,这样关于类型的整个处理过程就变得难以操纵。
如果我们只写这样一个简单方法,它仅接收基类作为参数,而不是那些特殊的导出类。这样做情况会变得更好吗?也就是说,如果我们不管导出类的存在,编写的代码只是与基类打交道,会不会更好呢?
这正是多态所允许的。然而,大多数程序员具有面向过程程序设计的背景,对多态的运作方式可能会有一点迷惑。
8.2转机
运行这个程序后,我们便会发现Music.java的难点所在。Wind.play()方法将产生输出结果。这无疑是我们所期望的输出结果,但它看起来似乎又没有什么意义。请观察一下tune()方法:
public static void tune(Instrument t){
//...
i.play(Note.MIDDLE_C);
}它接受一个Instrument引用。那么在这种情况下,编译器怎样才能知道这个Instrument引用指向的是Wind对象,而不是Brass对象或Stringed对象呢?实际上,编译器无法得知。为了深入理解这个问题,有必要研究一下绑定这个话题。
8.2.1方法调用绑定
将一个方法调用同一个方法主体关联起来被称作绑定。若在程序执行前进行绑定(如果有的话,由编译器和连接程序实现),叫做前期绑定。读者可能以前从来没有听说过这个术语,因为它是面向过程的语言中不需要选择就默认的绑定方式。例如,C只有一种方法调用,那就是前期绑定。
上述程序之所以令人迷惑,主要是因为前期绑定。因为,当编译器只有一个Instrument引用时,它无法知道究竟调用哪个方法才对。
解决的办法就是后期绑定,它的含义就是在运行时根据对象的类型进行绑定。后期绑定也叫做动态绑定或运行时绑定。如果一种语言想实现后期绑定,就必须具有某种机制,以便在运行时能判断对象的类型,从而调用恰当的方法。也就是说,编译器一直不知道对象的类型,但是方法调用机制能找到正确的方法体,并加以调用。后期绑定机制随编程语言的不同而有所不同,但是只要想一下就会得知,不管怎样都必须在对象中安置某种“类型信息”。
Java中除了static方法和final方法(private方法属于final方法)之外,其他所有的方法都是后期绑定。这意味着通常情况下,我们不必判定是否应该进行后期绑定——它会自动发生。
为什么要将某个方法声明为final呢?正如前一章提到的那样,它可以防止其他人覆盖该方法。但更重要的一点或许是:这样做可以有效地“关闭”动态绑定,或者说,告诉编译器不需要对其进行动态绑定。这样,编译器就可以为final方法调用生成更有效的代码。然而,大多数情况下,这样做对程序的整体性能不会有什么改观。所以,最好根据设计来决定是否使用final,而不是出于试图提高性能的目的来使用final。
8.2.2产生正确的行为
一旦知道Java中所有方法都是通过动态绑定实现多态这个事实之后,我们就可以编写只与基类打交道的程序代码了,并且这些代码对所有的导出类都可以正确运行。或者换一种说法,发送消息给某个对象,让该对象去断定应该做什么事。
面向对象程序设计中,有一个经典的例子就是“几何形状”(shape)。因为它很直观,所以经常用到;但不幸的是,它可能使初学者认为面向对象程序设计仅适用于图形化程序设计,实际当然不是这样。
在“几何形状”这个例子中,有一个基类Shape,以及多个导出类——如Circle、Square,Triangle等。这个例子之所以好用,是因为我们可以说“圆是一种几何形状”,这种说法也很容易被理解。下面的继承图展示它们之间的关系:
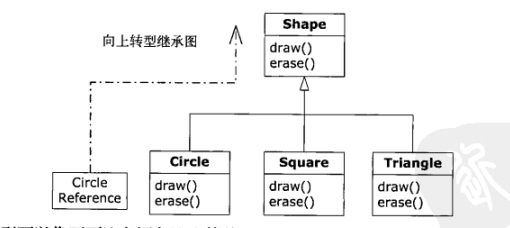
向上转型可以像下面这条语句这么简单:
Shape s=new Circle(); 这里,创建了一个Circle对象,并把得到的引用立即赋值给Shape,这样做看似错误(将一种类型赋值给另一种类型)﹔但实际上是没问题的,因为通过继承,Circle就是一种Shape。因此,编译器认可这条语句,也就不会产生错误信息。
假设你调用一个基类方法(它已在导出类中被覆盖):
s.draw();你可能再次认为调用的是Shape的draw(),因为这毕竟是一个Shape引用,那么编译器是怎样知道去做其他的事情呢?由于后期绑定(多态),还是正确调用了Circle.draw()方法。
//polymorphisml shape/ Shape.java
package polymorphism.shape ;
public class Shape {
public void draw() {}
public void erase() {}
}
//polymorphisml shapelCircle.java
package polymorphism.shape;
import static net.mindview.util.Print .* :
public class Circle extends 5hape {
public void draw() { print ("Circle.draw()"); }
public void erase() { print("Circle.erase()");}
}
//polymorphism/shape/ square.java
package polymorphism.shape;
import static net.mindview.util.Print.* :
public class square extends Shape {
public void draw(){ print ( "Square.draw()");}
public void erase() { print ( "Square.erase()"); }
}
//polymorphism/shape/Triangle.java
package polymorphism.shape;
import static net.mindview.util.Print .* ;
public class Triangle extends Shape {
public void draw() { print("Triangle.draw()"); }
public void erase() { print( "Triangle.erase()"); }
}
//polymorphism/shape/RandomShapeGenerator. java
package polymorphism.shape;
import java.util.*;
public class RandomShapeGenerator {
private Random rand = new Random(47);
public Shape next() {
switch(rand.nextInt(3)) {
default :
case 0: return new circle();
case 1: return new Square();
case 2: return new Triangle();
}
}
}
//polymorphism/ Shapes. java
import polymorphism.shape .*;
public class Shapes {
private static RandomShapeGenerator gen =
new RandomShapeGenerator();
public static void main(string[] args) {
Shape[] s = new Shape[9] ;
for(int i = 0; i < s .length; i++)
s[i] = gen.next();
for (Shape shp : s)
shp.draw();
}
}
Output :
Triangle.draw()
Triangle.draw()
square.draw()
Triangle.draw()
square.draw()
Triangle.draw()
Square.draw()
Triangle.draw()
circle.draw()
Shape基类为自它那里继承而来的所有导出类建立了一个公用接口——也就是说,所有形状都可以描绘和擦除。导出类通过覆盖这些定义,来为每种特殊类型的几何形状提供单独的行为。
RandomShapeGenerator是一种“工厂”(factory),在我们每次调用next()方法时,它可以为随机选择的Shape对象产生一个引用。请注意向上转型是在return语句里发生的。每个return语句取得一个指向某个Circle、Square或者Triangle的引用,并将其以Shape类型从next()方法中发送出去。所以无论我们在什么时候调用next()方法时,是绝对不可能知道具体类型到底是什么的,因为我们总是只能获得一个通用的Shape引用。
main()包含了一个Shape引用组成的数组,通过调用RandomShapeGenerator.next()来填入数据。此时,我们只知道自己拥有一些Shape,除此之外不会知道更具体的情况(编译器也不知道)。然而,当我们遍历这个数组,并为每个数组元素调用draw()方法时,与类型有关的特定行为会神奇般地正确发生,我们可以从运行该程序时所产生的输出结果中发现这一点。
随机选择几何形状是为了让大家理解:在编译时,编译器不需要获得任何特殊信息就能进行正确的调用。对draw()方法的所有调用都是通过动态绑定进行的。
8.2.3可扩展性
现在,让我们返回到“乐器”(Instrument)示例。由于有多态机制,我们可根据自己的需求对系统添加任意多的新类型,而不需更改tune()方法。在一个设计良好的OOP程序中,大多数或者所有方法都会遵循tune()的模型,而且只与基类接口通信。这样的程序是可扩展的,因为可以从通用的基类继承出新的数据类型,从而新添一些功能。那些操纵基类接口的方法不需要任何改动就可以应用于新类。
考虑一下:对于“乐器”的例子,如果我们向基类中添加更多的方法,并加入一些新类,将会出现什么情况呢?请看下图:
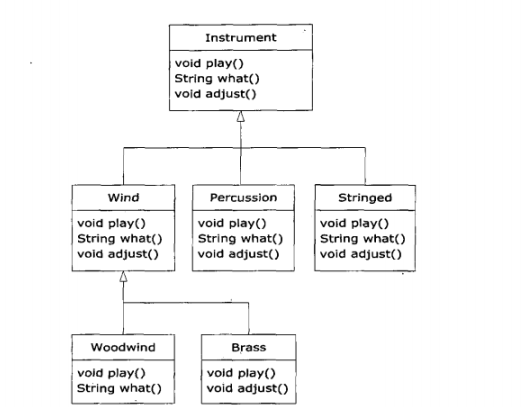
事实上,不需要改动tune()方法,所有的新类都能与原有类一起正确运行。即使tune()方法是单独存放在某个文件中,并且在Instrument接口中添加了其他的新方法,tune()也不需再编译就能正确运行。下面是上图的具体实现:
//polymorphism/music3/Husic3.java
package polymorphism.music3;
import polymorphi sm.music.Note;
import static net.mindview.uti1.Print.*;
class Instrument {
void play(Note n) { print ( "Instrument.play () " + n); }
String whato { return "Instrument" ; }
void adjusto { print ("Adjusting Instrument" ); }
}
class wind extends Instrument {
void play(Note n) { print ( "wind.play() " + n); }
String what() { return "wind" ; }
void adjust() { print("Adjusting wind"); }
}
class Percussion extends Instrument {
void play(Note n) { print ( "Percussion.play() " +n); }
String what() { return "Percussion" ; }
void adjust() { print( "Adjusting Percussion");}
}
class Stringed extends Instrument {
void play(Note n) { print ("Stringed. play() " + n); }
String what() { return "stringed" ; }
void adjust() { print ( "Adjusting stringed"); }
}
class Brass extends wind {
void play (Note n) { print ( "Brass.playo " +n); }
void adjust() { print ( "Adjusting Brass"); }
}
class woodwind extends wind {
void play(Note n) { print ( "woodwind.play () " +n); }
String what() { return "woodwind" ; }
)
public class Music3 {
public static void tune( Instrument i) {
// ...
i.play (Note.MIDDLE_C);
}
public static void tuneAl1 ( Instrument[] e){
for(Instrument i : e)
tune(i);
}
public static void main(string[] args) {
Instrument[] orchestra = {
new wind(),
new Percussion(),
new Stringed(),
new Brass(),
new woodwind(),
};
tuneAll(orchestra);
}
}
Output :
wind.play() MIDDLE_C
Percussion.play() HIDDLE_C
Stringed.play() HIDDLE_C
Brass.play() MIDDLE_C
Woodwind.play() HIDDLE_C
新添加的方法what()返回一个带有类描述的String引用;另一个新添加的方法adjust()则提供每种乐器的调音方法。
在main()中,当我们将某种引用置入orchestra数组中,就会自动向上转型到Instrument。可以看到,tune()方法完全可以忽略它周围代码所发生的全部变化,依旧正常运行。这正是我们期望多态所具有的特性。我们所做的代码修改,不会对程序中其他不应受到影响的部分产生破坏。换句话说,多态是一项让程序员“将改变的事物与未变的事物分离开来”的重要技术。
8.2.4缺陷:“覆盖”私有方法
我们试图像下面这样做也是无可厚非的
//polymorphi sm/ Privateoverride.java
package polymorphisn;
import static net.mindview.util.Print .*;
public class Privateoverride {
private void f() {
print ( "private f()");
}
public static void main(String[]args) {
Privateoverride po = new Derived() ;
po.f() ;
}
class Derived extends PrivateOverride {
public void f() { print ( "public f()"); }
}Output:
private f()
我们所期望的输出是public f(),但是由于private方法被自动认为是final方法,而且对导出类是屏蔽的。因此,在这种情况下,Derived类中的f()方法就是一个全新的方法;既然基类中的f()方法在子类Derived中不可见,因此甚至也不能被重载。
结论就是:只有非private方法才可以被覆盖,但是还需要密切注意覆盖private方法的现象,这时虽然编译器不会报错,但是也不会按照我们所期望的来执行。确切地说,在导出类中,对于基类中的private方法,最好采用不同的名字。
8.2.5缺陷:域与静态方法
一旦你了解了多态机制,可能就会开始认为所有事物都可以多态地发生。然而,只有普通的方法调用可以是多态的。例如,如果你直接访问某个域,这个访问就将在编译期进行解析,就像下面的示例所演示的:
//polymorphism/FieldAccess.java
class Super {
public int field = 0;
public int getField() { return field; }
}
class Sub extends Super {
public int field = i;
public int getField() { return field; }
public int getSuperField() { return super.field: }
}
public class FieldAccess {
public static void main(string[] args){
super sup = new Sub();
System.out.println("sup.Field = " +sup.field +
". sup.getFieid() = " + sup.getField());
Sub sub =new Sub();
System.out.println("sub.Field = " +
sub.Field + ". sub.getField() = " +
sub.getField() +
". sub.getSuperField() = " +
sub.getSuperField());
}
}Output :
sup.field = 0, sup.getField() = 1
sub.field = 1, sub.getField() = 1, sub.getsuperField() = 0
当Sub对象转型为Super引用时,任何域访问操作都将由编译器解析,因此不是多态的。在本例中,为Super.field和Sub.field分配了不同的存储空间。这样,Sub实际上包含两个称为field的域:它自己的和它从Super处得到的。然而,在引用Sub中的field时所产生的默认域并非Super版本的field域。因此,为了得到Super.field,必须显式地指明super.field。
尽管这看起来好像会成为一个容易令人混淆的问题,但是在实践中,它实际上从来不会发生。首先,你通常会将所有的域都设置成private,因此不能直接访问它们,其副作用是只能调用方法来访问。另外,你可能不会对基类中的域和导出类中的域赋予相同的名字,因为这种做法容易令人混淆。
如果某个方法是静态的,它的行为就不具有多态性:
//polymorphism/staticPolymorphism.java
class StaticSuper {
public static string staticGet() {
return "Base staticGet ()";
}
public String dynamicGet() {
return "Base dynamicGeto";
}
}
class staticsub extends StaticSuper {
public static String staticGet() {
return "Derived staticGet()";
}
public String dynamicGet() {
return "Derived dynamicGet()";
}
}
public class StaticPolymorphism {
public static void main(string[] args){
StaticSuper sup = new StaticSub();
System.out.println(sup.staticGet());
System.out.println(sup.dynamicGet());
}
}
Output :
Base staticGet()
Derived dynamicGet()
静态方法是与类,而并非与单个的对象相关联的
8.3构造器和多态
通常,构造器不同于其他种类的方法。涉及到多态时仍是如此。尽管构造器并不具有多态性(它们实际上是static方法,只不过该static声明是隐式的),但还是非常有必要理解构造器怎样通过多态在复杂的层次结构中运作,这一理解将有助于大家避免一些令人不快的困扰。
8.3.1构造器的调用顺序
基类的构造器总是在导出类的构造过程中被调用,而且按照继承层次逐渐向上链接,以使每个基类的构造器都能得到调用。这样做是有意义的,因为构造器具有一项特殊任务:检查对象是否被正确地构造。导出类只能访问它自己的成员,不能访问基类中的成员(基类成员通常是private类型)。只有基类的构造器才具有恰当的知识和权限来对自己的元素进行初始化。因此,必须令所有构造器都得到调用,否则就不可能正确构造完整对象。这正是编译器为什么要强制每个导出类部分都必须调用构造器的原因。在导出类的构造器主体中,如果没有明确指定调用某个基类构造器,它就会“默默”地调用默认构造器。如果不存在默认构造器,编译器就会报错(若某个类没有构造器,编译器会自动合成出一个默认构造器)。
让我们来看下面这个例子,它展示组合、继承以及多态在构建顺序上的作用:
//polymorphism/Sandwich.java
package polymorphism;
import static net.mindview.util.Print.*;
class Heal {
Heal() { print ( "Heal()"); }
}
class Bread {
Bread() { print ( "Bread()"); }
}
class Cheese() {
cheese() { print ( "Cheese()"); }
}
class Lettuce() {
Lettuce() { print ( "Lettuce ()"); }
}
class Lunch extends Heal {
Lunch() { print( "Lunch"); }
}
class PortableLunch extends Lunch {
PortableLunch() { print ( "PortableLunch()");}
}
public class sandwich extends PortableLunch {
private Bread b = new Bread();
private Cheese c = new Cheese();
private Lettuce l =new Lettuce();
public sandwich() { print( "Sandwicho" ); }
public static void main(string[] args){
new Sandwicho;
}
}
Output:
Heal()
Lunch()
PortableLunch()
Bread()
cheese()
Lettuce()
Sandwich()
在这个例子中,用其他类创建了一个复杂的类,而且每个类都有一个声明它自己的构造器。其中最重要的类是Sandwich,它反映了三层继承(若将自Object的隐含继承也算在内,就是四层)以及三个成员对象。当在main()里创建一个Sandwich对象后,就可以看到输出结果。这也表明了这一复杂对象调用构造器要遵照下面的顺序:
- 调用基类构造器。这个步骤会不断地反复递归下去,首先是构造这种层次结构的根,然后是下一层导出类,等等,直到最低层的导出类。
- 按声明顺序调用成员的初始化方法。
- 调用导出类构造器的主体。
构造器的调用顺序是很重要的。当进行继承时,我们已经知道基类的一切,并且可以访问基类中任何声明为public和protected的成员。这意味着在导出类中,必须假定基类的所有成员都是有效的。一种标准方法是,构造动作一经发生,那么对象所有部分的全体成员都会得到构建。然而,在构造器内部,我们必须确保所要使用的成员都已经构建完毕。为确保这一目的,唯一的办法就是首先调用基类构造器。那么在进入导出类构造器时,在基类中可供我们访问的成员都已得到初始化。此外,知道构造器中的所有成员都有效也是因为,当成员对象在类内进行定义的时候(比如上例中的b、c和l),只要有可能,就应该对它们进行初始化(也就是说,通过组合方法将对象置于类内)。若遵循这一规则,那么就能保证所有基类成员以及当前对象的成员对象都被初始化了。但遗憾的是,这种做法并不适用于所有情况,这一点我们会在下一节中看到。
8.3.2继承与清理
通过组合和继承方法来创建新类时,永远不必担心对象的清理问题,子对象通常都会留给垃圾回收器进行处理。如果确实遇到清理的问题,那么必须用心为新类创建dispose()方法(在这里我选用此名称﹔读者可以提出更好的)。并且由于继承的缘故,如果我们有其他作为垃圾回收一部分的特殊清理动作,就必须在导出类中覆盖dispose()方法。当覆盖被继承类的dispose()方法时,务必记住调用基类版本dispose()方法,否则,基类的清理动作就不会发生。下例就证明了这一点:
//polymorphism/Frog.java
package polymorphism;
import static net.mindview.uti1.Print .* :
class Characteristic {
private string s;
characteristic(String s) {
this.s =s;
print ("Creating Characteristic " + s);
}
protected void dispose() {
print ("disposing characteristic " + s );
}
}
class Description {
private string s;
Description (string s){
this.s = s ;
print ( "Creating Description " +s);
}
protected void dispose() {
print ( "disposing Description " + s);
}
}
class LivingCreature {
private Characteristic p =
new Characteristic ("is alive" );
private Description t =
new Description( "Basic Living creature" ) ;
LivingCreature() {
print ("LivingCreature()" );
}
protected void dispose() {
print ("Livingcreature dispose" );
t.dispose();
p.dispose();
}
}
class Animal extends Livingcreature {
private characteristic p=
new Characteristic("has heart" );
private Description t =
new Description ( "Animal not vegetable");
Animal() { print ( "Animal ("); }
protected void dispose() {
print ( "Animal dispose" );
t.dispose();
p.dispose();
super.dispose();
}
}
class Amphibian extends Animal {
private Characteristic p=
new Characteristic( "can live in water");
private Description t =
new Description( "Both water and 1and" );
Amphibian() {
print ( "Amphibian()" );
}
protected void dispose() {
print ( "Amphibian dispose");
t.dispose();
p.dispose();
super.dispose();
}
}
public class Frog extends Amphibian {
private Characteristic p = new Characteristic("Croaks");
private Description t = new Description( "Eats Bugs");
public Frog() { print ("Frog()"); }
protected void dispose() {
print ("Frog dispose");
t.dispose();
p.dispose();
super.dispose();
}
public static void main(string[] args) {
Frog frog =new Frog(;
print ("Bye! ");
frog.dispose();
}
}Output :
creating characteristic is alive
creating Description Basic Living creature
Livingcreature()
Creating characteristic has heart
creating Description Animal not vegetable
Animal()
creating Characteristic can live in water
creating Description Both water and land
Amphibian()
creating Characteristic croaks
Creating Description Eats Bugs
Frog()
Bye!
Frog dispose
disposing Description Eats Bugs
disposing characteristic croaks
Amphibian dispose
disposing Description Both water and land
disposing characteristic can live in water
Animal dispose
disposing Description Animal not vegetable
disposing Characteristic has heart
LivingCreature dispose
disposing Description Basic Living creature
disposing Characteristic is alive
层次结构中的每个类都包含Characteristic和Description这两种类型的成员对象,并且它们也必须被销毁。所以万一某个子对象要依赖于其他对象,销毁的顺序应该和初始化顺序相反。对于字段,则意味着与声明的顺序相反(因为字段的初始化是按照声明的顺序进行的)。对于基类(遵循C++中析构函数的形式),应该首先对其导出类进行清理,然后才是基类。这是因为导出类的清理可能会调用基类中的某些方法,所以需要使基类中的构件仍起作用而不应过早地销毁它们。从输出结果可以看到,Frog对象的所有部分都是按照创建的逆序进行销毁的。
在这个例子中可以看到,尽管通常不必执行清理工作,但是一旦选择要执行,就必须谨慎和小心。
在上面的示例中还应该注意到,Frog对象拥有其自己的成员对象。Frog对象创建了它自己的成员对象,并且知道它们应该存活多久(只要Frog存活着),因此Frog对象知道何时调用dispose()去释放其成员对象。然而,如果这些成员对象中存在于其他一个或多个对象共享的情况,问题就变得更加复杂了,你就不能简单地假设你可以调用dispose()了。在这种情况下,也许就必需使用引用计数来跟踪仍旧访问着共享对象的对象数量了。下面是相关的代码:
//polymorphism/Referencecounting.java
import static net.mindview.util.Print.* ;
class Shared {
private int refcount = 0;
private static 1long counter = 0;
private final long id = counter++ ;
public Shared() {
print ("Creating ". + this);
}
public void addRef() { refcount++; }
protected void dispose() {
if (--refcount ==0)
print ("Disposing " + this);
}
public string toString() { return "Shared " + id; }
}
class composing {
private Shared shared ;
private static long counter = 0 ;
private final long id = counter++;
public composing ( Shared shared) {
print ( "Creating " + this);
this.shared =shared ;
this.shared.addRef();
}
protected void dispose() {
print ("disposing " +this);
shared.dispose();
}
public String tostring() { return "Composing " + id; }
}
public class ReferenceCounting {
public static void main(String[]args) {
Shared shared =new Shared(;
Composing[] composing = { new Composing(shared) ,
new Composing(shared) , new composing(shared) ,
new Composing(shared), new Composing(shared)};
for(composing c : composing)
c.dispose( );
}
}Output :
creating shared 0
creating Composing 0
creating Composing 1
creating Composing 2
creating Composing 3
creating Composing 4
disposing Composing 0
disposing Composing 1
disposing Composing 2
disposing Composing 3
disposing Composing 4
Disposing Shared 0
static long counter跟踪所创建的Shared的实例的数量,还可以为id提供数值。counter的类型是long而不是int,这样可以防止溢出(这只是一个良好实践,对于本书中的所有示例,这种计数器不可能发生溢出)。id是final的,因为我们不希望它的值在对象生命周期中被改变。
在将一个共享对象附着到类上时,必须记住调用addRef(),但是dispose()方法将跟踪引用数,并决定何时执行清理。使用这种技巧需要加倍地细心,但是如果你正在共享需要清理的对象,那么你就没有太多的选择余地了。
8.3.3构造器内部的多态方法的行为
构造器调用的层次结构带来了一个有趣的两难问题。如果在一个构造器的内部调用正在构造的对象的某个动态绑定方法,那会发生什么情况呢?
在一般的方法内部,动态绑定的调用是在运行时才决定的,因为对象无法知道它是属于方法所在的哪个类,还是属于那个类的导出类。
如果要调用构造器内部的一个动态绑定方法,就要用到那个方法的被覆盖后的定义。然而,这个调用的效果可能相当难于预料,因为被覆盖的方法在对象被完全构造之前就会被调用。这可能会造成一些难于发现的隐藏错误。
从概念上讲,构造器的工作实际上是创建对象(这并非是一件平常的工作)。在任何构造器内部,整个对象可能只是部分形成——我们只知道基类对象已经进行初始化。如果构造器只是在构建对象过程中的一个步骤,并且该对象所属的类是从这个构造器所属的类导出的,那么导出部分在当前构造器正在被调用的时刻仍旧是没有被初始化的。然而,一个动态绑定的方法调用却会向外深入到继承层次结构内部,它可以调用导出类里的方法。如果我们是在构造器内部这样做,那么就可能会调用某个方法,而这个方法所操纵的成员可能还未进行初始化——这肯定会招致灾难。
通过下面这个例子,我们会看到问题所在:
//polymorphism/Polyconstructors.java
import static net.mindview.uti l.Print.* ;
class Glyph {
void draw() { print ("G1yph. draw()"); }
Glyph() {
print ( " Glyph() before draw() ");
draw() ;
print("Glyph() after draw()");
}
}
class RoundG1yph extends clyph {
private int radius = 1;
RoundGlyph(int r) {
radius = r;
print( "RoundGlyph.RoundGlyph(). radius = " + radius);
}
void draw() {
print ( "RoundGlyph.draw() , radius = " +radius);
}
}
public class PolyConstructors {
public static void main(string[] args) {
new RoundGlyph(5);
}
}
Output :
Glyph() before draw()
RoundGlyph.draw () , radius = 0
Glyph after draw()
Rounddilyph.RoundGlyph() , radius = 5
Glyph.draw()方法设计为将要被覆盖,这种覆盖是在RoundGlyph中发生的。但是Glyph构造器会调用这个方法,结果导致了对RoundGlyph.draw()的调用,这看起来似乎是我们的目的。但是如果看到输出结果,我们会发现当Glyph的构造器调用draw()方法时,radius不是默认初始值1,而是0。这可能导致在屏幕上只画了一个点,或者根本什么东西都没有,我们只能干瞪眼,并试图找出程序无法运转的原因所在。
前一节讲述的初始化顺序并不十分完整,而这正是解决这一谜题的关键所在。初始化的实际过程是:
- 在其他任何事物发生之前,将分配给对象的存储空间初始化成二进制的零。
- 如前所述那样调用基类构造器。此时,调用被覆盖后的draw()方法(要在调用RoundGlyph构造器之前调用),由于步骤1的缘故,我们此时会发现radius的值为0。
- 按照声明的顺序调用成员的初始化方法。
- 调用导出类的构造器主体。
这样做有一个优点,那就是所有东西都至少初始化成零(或者是某些特殊数据类型中与“零”等价的值),而不是仅仅留作垃圾。其中包括通过“组合”而嵌入一个类内部的对象引用,其值是null。所以如果忘记为该引用进行初始化,就会在运行时出现异常。查看输出结果时,会发现其他所有东西的值都会是零,这通常也正是发现问题的证据。
另一方面,我们应该对这个程序的结果相当震惊。在逻辑方面,我们做的已经十分完美,而它的行为却不可思议地错了,并且编译器也没有报错。(在这种情况下,C++语言会产生更合理的行为。)诸如此类的错误会很容易被人忽略,而且要花很长的时间才能发现。
因此,编写构造器时有一条有效的准则:“用尽可能简单的方法使对象进入正常状态,如果可以的话,避免调用其他方法”。在构造器内唯一能够安全调用的那些方法是基类中的final方法(也适用于private方法,它们自动属于final方法)。这些方法不能被覆盖,因此也就不会出现上述令人惊讶的问题。你可能无法总是能够遵循这条准则,但是应该朝着它努力。
8.4协变返回类型
Java SE5中添加了协变返回类型,它表示在导出类中的被覆盖方法可以返回基类方法的返回类型的某种导出类型:
//polymorphism/CovariantReturn.java
class Grain {
public string tostring() { return "Grain" ; }
}
class Wheat extends Grain {
public String tostring() { return "wheat" ; }
}
class Mill {
Grain process() { return new Grain(); }
}
class wheatHil1 extends Hi1l {
wheat process() { return new wheat(); }
}
public class CovariantReturn {
public static void main(String[] args){
Hill m = new Hill();
Grain g = m.process();
System.out.println(g);
m = new wheatMi1l();
g = m.process();
System.out.println(g);
}
}
Output:
Grain
wheat
Java SE5与Java较早版本之间的主要差异就是较早的版本将强制process)的覆盖版本必须返回Grain,而不能返回Wheat,尽管Wheat是从Grain导出的,因而也应该是一种合法的返回类型。协变返回类型允许返回更具体的Wheat类型。
4.5用继承进行设计
学习了多态之后,看起来似乎所有东西都可以被继承,因为多态是一种如此巧妙的工具。事实上,当我们使用现成的类来建立新类时,如果首先考虑使用继承技术,反倒会加重我们的设计负担,使事情变得不必要地复杂起来。
更好的方式是首先选择“组合”,尤其是不能十分确定应该使用哪一种方式时。组合不会强制我们的程序设计进入继承的层次结构中。而且,组合更加灵活,因为它可以动态选择类型(因此也就选择了行为)﹔相反,继承在编译时就需要知道确切类型。下面举例说明这一-点:
//polymorphism/Transmogrify.java
import static net.mindview.uti1.Print.*;
class Actor {
public void act() {}
}
class HappyActor extends Actor {
public void act() { print ( "HappyActor" ); }
}
class SadActor extends Actor {
public void act() { print ("SadActor"); }
}
class stage {
private Actor actor = new HappyAetor();
public void change() { actor = new SadActoro; }
public void performP1ay() { actor. act(); }
}
public class Transmogrify {
public static void main(String[] args) {
stage stage = new Stage();
stage.performP1ay() ;
stage.change() ;
stage.performP1ay();
}
}Output :
HappyActor
SadActor
在这里,Stage对象包含一个对Actor的引用,而Actor被初始化为HappyActor对象。这意味着performPlay()会产生某种特殊行为。既然引用在运行时可以与另一个不同的对象重新绑定起来,所以SadActor对象的引用可以在actor中被替代,然后由performPlay()产生的行为也随之改变。这样一来,我们在运行期间获得了动态灵活性(这也称作状态模式)。与此相反,我们不能在运行期间决定继承不同的对象,因为它要求在编译期间完全确定下来。
一条通用的准则是:“用继承表达行为间的差异,并用字段表达状态上的变化”。在上述例子中,两者都用到了:通过继承得到了两个不同的类,用于表达act()方法的差异,而Stage通过运用组合使自己的状态发生变化。在这种情况下,这种状态的改变也就产生了行为的改变。
8.5.1纯继承与扩展
采取“纯粹”的方式来创建继承层次结构似乎是最好的方式。也就是说,只有在基类中经建立的方法才可以在导出类中被覆盖,如图所示:
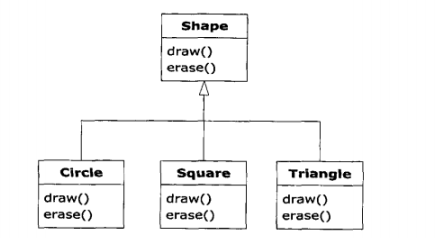
这被称作是纯粹的“is-a”(是一种)关系,因为一个类的接口已经确定了它应该是什么。继承可以确保所有的导出类具有基类的接口,且绝对不会少。按上图那么做,导出类也将具有和基类一样的接口。
也可以认为这是一种纯替代,因为导出类可以完全代替基类,而在使用它们时,完全不需要知道关于子类的任何额外信息:
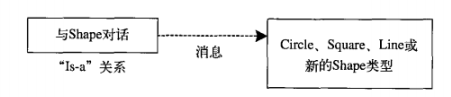
也就是说,基类可以接收发送给导出类的任何消息,因为二者有着完全相同的接口。我们只需从导出类向上转型,永远不需知道正在处理的对象的确切类型。所有这一切,都是通过多态来处理的(如右图所示)。
按这种方式考虑,似乎只有纯粹的is-a关系才是唯一明智的做法,而所有其他的设计都只会导致混乱和注定会失败。这其实也是一个陷阱,因为只要开始考虑,就会转向,并发现扩展接口(遗憾的是,extends关键字似乎在怂恿我们这样做)才是解决特定问题的完美方案。这可以称为“is-like-a”(像一个)关系,因为导出类就像是一个基类——它有着相同的基本接口,但是它还具有由额外方法实现的其他特性。
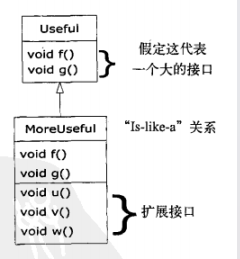
虽然这是一种有用且明智的方法(依赖于具体情况),但是它也有缺点。导出类中接口的扩展部分不能被基类访问,因此,一旦我们向上转型,就不能调用那些新方法。
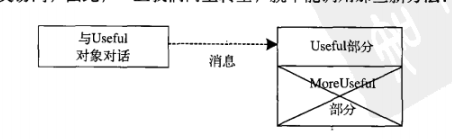
在这种情况下,如果我们不进行向上转型,这样的问题也就不会出现。但是通常情况下,我们需要重新查明对象的确切类型,以便能够访问该类型所扩充的方法。下一节将说明如何做到这一点。
8.5.2向下转型与运行时类型识别
由于向上转型(在继承层次中向上移动)会丢失具体的类型信息,所以我们就想,通过向下转型——也就是在继承层次中向下移动-——应该能够获取类型信息。然而,我们知道向上转型是安全的,因为基类不会具有大于导出类的接口。因此,我们通过基类接口发送的消息保证都能被接受。但是对于向下转型,例如,我们无法知道一个“几何形状”它确实就是一个“圆”,它可以是一个三角形、正方形或其他一些类型。
要解决这个问题,必须有某种方法来确保向下转型的正确性,使我们不致于贸然转型到一种错误类型,进而发出该对象无法接受的消息。这样做是极其不安全的。
在某些程序设计语言(如C++)中,我们必须执行一个特殊的操作来获得安全的向下转型。但是在Java语言中,所有转型都会得到检查!所以即使我们只是进行一次普通的加括弧形式的类型转换,在进入运行期时仍然会对其进行检查,以便保证它的确是我们希望的那种类型。如果不是,就会返回一个ClassCastException(类转型异常)。这种在运行期间对类型进行检查的行为称作“运行时类型识别”(RTTI)。下面的例子说明RTTI的行为:
//polymorphism/RTTI.java
class Useful {
public void f() {}
public void g() {}
}
class HoreUseful extends Useful {
public void f() {}
public void g() {}
public void u() {}
public void v() {}
public void w() {}
}
public class RTTI {
public static void main(String[] args){
Useful[] x = {
new Useful(),
new HoreUseful()
};
×[0].f();
x[1].g();
//! x[1].u();
((moreUseful)x[1]).u();
((MoreUseful)×[0]).j();
}
}
正如前一个示意图中所示,MoreUseful(更有用的)接口扩展了Useful(有用的)接口,但是由于它是继承而来的,所以它也可以向上转型到Useful类型。我们在main()方法中对数组x进行初始化时可以看到这种情况的发生。既然数组中的两个对象都属于Useful类,所以我们可以调用f()和g()这两个方法。如果我们试图调用u()方法(它只存在于MoreUseful),就会返回一条编译时出错消息。
如果想访问MoreUseful对象的扩展接口,就可以尝试进行向下转型。如果所转类型是正确的类型,那么转型成功:否则,就会返回一个ClassCastException异常。我们不必为这个异常编写任何特殊的代码,因为它指出的是程序员在程序中任何地方都可能会犯的错误。{Throws-Exception}注释标签告知本书的构建系统:在运行该程序时,预期抛出一个异常。
RTTI的内容不仅仅包括转型处理。例如它还提供一种方法,使你可以在试图向下转型之前,查看你所要处理的类型。第14章专门讨论Java运行时类型识别的所有不同方面。