playwright基础样例demo大全
playwright
- 安装
- 优点
- 基础示例
- 同步代码
- 异步代码
- 启动不同浏览器
- 启用本地浏览器(使用浏览器cookie信息)
- playwright页面接管
- 设置环境变量和cmd启动浏览器
- 窗口最大化
- 录制脚本
- 录制脚本保存身份验证状态
- 代码中保存身份状态信息
- 代码中读取身份状态信息
- playwright发送api接口请求
安装
pip install pytest-playwright
playwright install
优点
- 支持异步操作(assync_api)
- 同步操作调用:sync_api
基础示例
同步代码
from playwright.sync_api import sync_playwright
with sync_playwright() as playwright:
browser = playwright.chromium.launch()
page = browser.new_page()
page.goto('https://www.baidu.com')
print(page.title())
browser.close()
异步代码
- 异步代码需要两个关键字:
async和await - 异步方法启动需要使用导入
asyncio包,运行asyncio.run()执行main()方法。
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
# headless = False : 是否启动无头模式,无头模式是不弹出浏览器,后台运行
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
await page.goto('https://www.baidu.com')
print(await page.title())
await browser.close()
asyncio.run(main())
启动不同浏览器
- 浏览器默认情况下是以无痕模式启动
channel:“chrome”, “chrome-beta”, “chrome-dev”, “chrome-canary”, “msedge”, “msedge-beta”, “msedge-dev”, or “msedge-canary”- chromium:谷歌开源内核
def run(playwright: Playwright) -> None:
# "chrome", "chrome-beta", "chrome-dev", "chrome-canary", "msedge", "msedge-beta", "msedge-dev", or "msedge-canary"
browser = playwright.chromium.launch(headless=False, channel='msedge')
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/")
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
- 火狐
from playwright.sync_api import sync_playwright
with sync_playwright() as playwright:
# 火狐
browser_f = playwright.firefox.launch()
page = browser_f.new_page()
page.goto('https://www.bing.com')
print(page.title())
browser_f.close()
启用本地浏览器(使用浏览器cookie信息)
from playwright.sync_api import Playwright, sync_playwright
import getpass
user_data_dir = fr'C:\Users\{getpass.getuser()}\AppData\Local\Google\Chrome\User Data'
def run(playwright: Playwright) -> None:
context = playwright.chromium.launch_persistent_context(
# 本地浏览器的数据目录
user_data_dir=user_data_dir,
# 指定Google
channel='chrome',
# 无头模式
headless=False
)
page = context.new_page()
page.goto("https://www.baidu.com/")
page.pause()
# ---------------------
context.close()
with sync_playwright() as playwright:
run(playwright)
playwright页面接管
- 针对场景:退出浏览器就需要重新登录,并且存在复杂的验证信息
设置环境变量和cmd启动浏览器
- 将起始位置添加到环境变量中,并且保证cmd命令窗口输出
chrome直接启动浏览器。
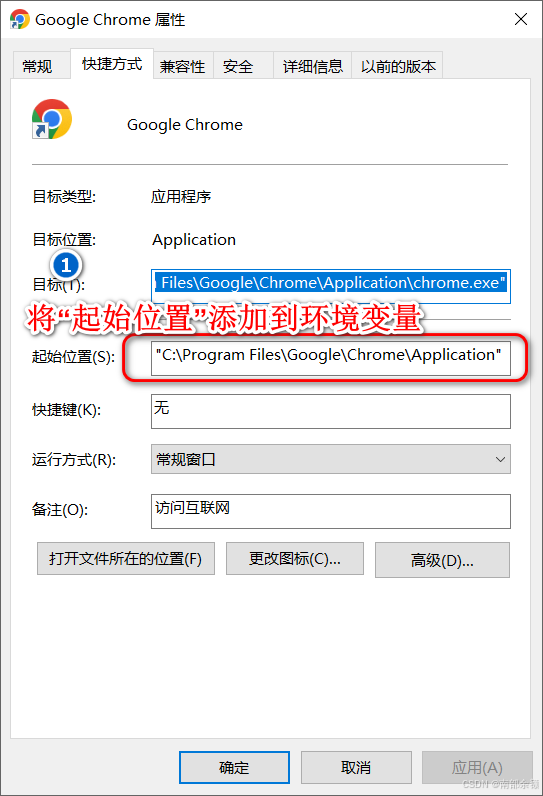
- 在cmd窗口中,输入启动命令和配置参数信息。
- 指定端口:
--remote-debugging-port=8888 - 指定浏览器数据目录:
--user-data-dir="D:\playwright_chrome_user_data"
chrome --remote-debugging-port=8888 --user-data-dir="D:\playwright_chrome_user_data"

3. 使用cdp链接chrome浏览器。
from playwright.sync_api import Playwright, sync_playwright
def run(playwright: Playwright) -> None:
browser = playwright.chromium.connect_over_cdp('http://localhost:8888')
page = browser.contexts[0].pages[0]
page.goto("https://www.baidu.com/")
page.pause()
# ---------------------
page.close()
with sync_playwright() as playwright:
run(playwright)
窗口最大化
--start-maximized:该参数来源是chromium浏览器命令行参数列表,https://peter.sh/experiments/chromium-command-line-switches/。no_viewport=True
import re
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False, args=['--start-maximized'])
context = browser.new_context(no_viewport=True)
page = context.new_page()
page.goto("https://www.baidu.com/")
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
录制脚本
- 命令:
playwright codegen
- 示例:
playwright codegen https://www.baidu.com
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("http://xx.xx.xx.xx:8080/login")
page.get_by_role("textbox", name="用户名").click()
page.get_by_role("textbox", name="用户名").fill("admin")
page.get_by_role("textbox", name="密码").click()
page.get_by_role("textbox", name="密码").fill("admin123")
page.get_by_role("button", name="登录").click()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
录制脚本保存身份验证状态
--save-storage:会保存cookie和localStorage。--load-storage:加载保存在本地的cookie信息。open:playwright open启动浏览器与codegen效果相似。
保存cookie信息
playwright codegen --save-storage=auto.json
加载cookie信息
playwright open http://xx.xx.xx.xx:8080/system/user --load-storage=auto.json
代码中保存身份状态信息
- 若导出的文件cookie信息为空,需要确认网站cookie的失效机制,
是否关闭浏览器或者关闭页面即失效。
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("http://xx.xx.xx.xx:8080/login")
page.get_by_role("textbox", name="用户名").click()
page.get_by_role("textbox", name="用户名").fill("admin")
page.get_by_role("textbox", name="密码").click()
page.get_by_role("textbox", name="密码").fill("admin123")
page.get_by_role("button", name="登录").click()
# 添加等待事件,保证登录信息的获取
page.wait_for_url(url='http://xx.xx.xx.xx:8080/index')
# 保存storage state 到指定的文件
storage = context.storage_state(path="../auth/ry_auto.json")
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
代码中读取身份状态信息
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context(storage_state="state.json")
playwright发送api接口请求
@pytest.fixture(scope="session")
def api_request_context(
playwright: Playwright,
) -> Generator[APIRequestContext, None, None]:
headers = {
# We set this header per GitHub guidelines.
"Accept": "application/vnd.github.v3+json",
# Add authorization token to all requests.
# Assuming personal access token available in the environment.
"Authorization": f"token {GITHUB_API_TOKEN}",
}
request_context = playwright.request.new_context(
base_url="https://api.github.com", extra_http_headers=headers
)
yield request_context
request_context.dispose()