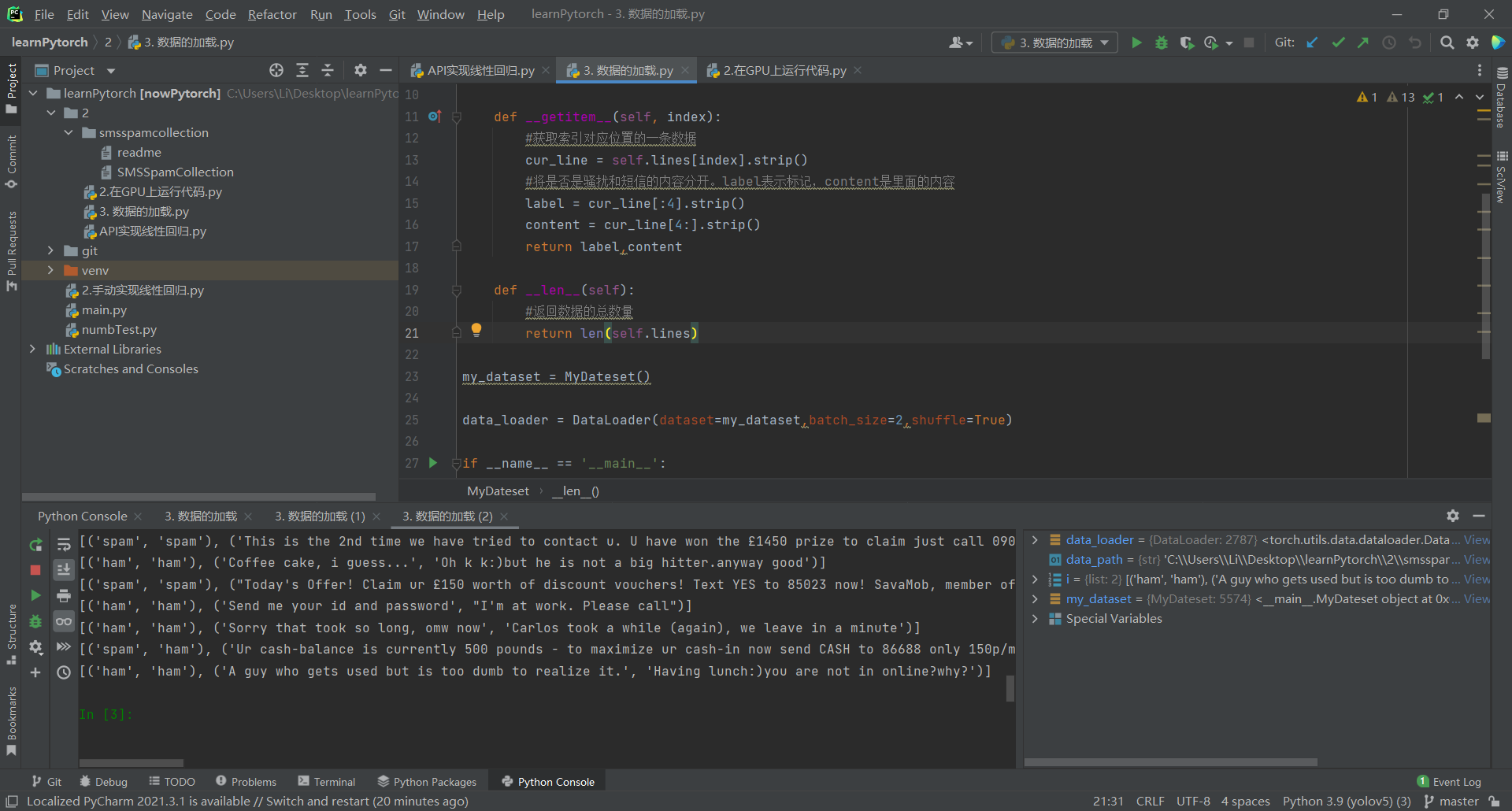
数据加载器

数据集类必要的三个方法:
init:从哪里读取数据,写路径
getitem:获取数据的内容
len:获取数据的总个数
数据加载器类相当于一个容器,你把数据放进去由它进行下一步管理。
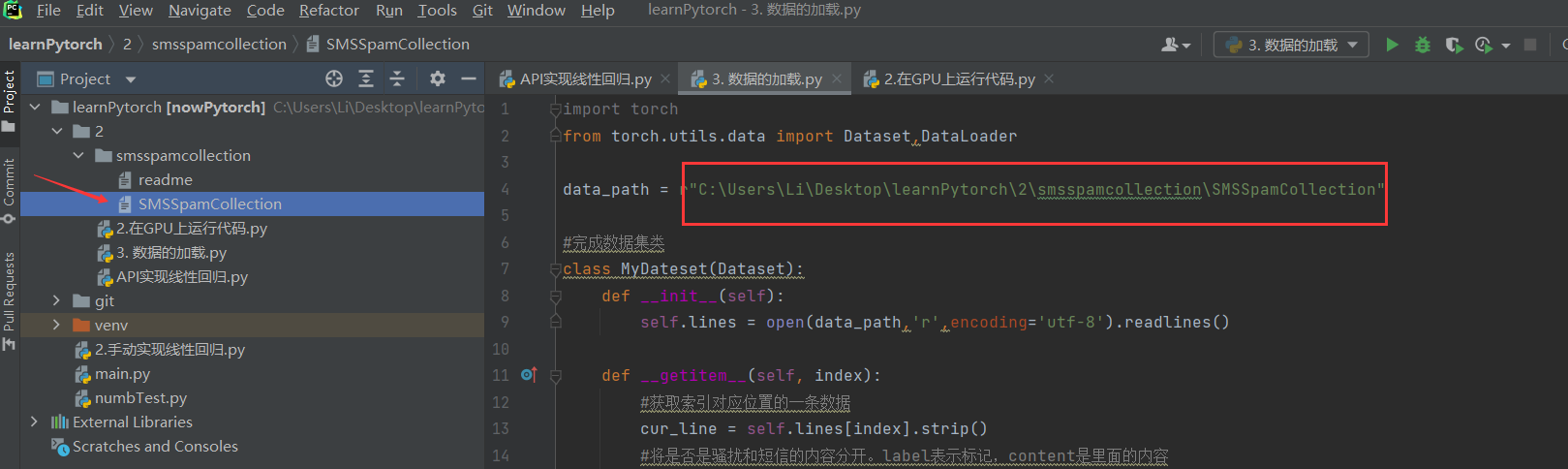
注意文件的路径
import torch
from torch.utils.data import Dataset,DataLoader
data_path = r"C:\Users\Li\Desktop\learnPytorch\2\smsspamcollection\SMSSpamCollection"
#完成数据集类
class MyDateset(Dataset):
def __init__(self):
self.lines = open(data_path,'r',encoding='utf-8').readlines()
def __getitem__(self, index):
#获取索引对应位置的一条数据 这里有无strip都无关紧要
cur_line = self.lines[index].strip()
#将是否是骚扰和短信的内容分开。label表示标记,content是里面的内容
label = cur_line[:4].strip()
content = cur_line[4:].strip()
return label,content
def __len__(self):
#返回数据的总数量
return len(self.lines)
my_dataset = MyDateset()
data_loader = DataLoader(dataset=my_dataset,batch_size=2,shuffle=True)
if __name__ == '__main__':
# my_dataset = MyDateset()
# print(my_dataset[0])
# print(my_dataset.__len__())
for i in data_loader:
print(i)