【网络】:应用层 —— HTTP协议
目录
HTTP协议的概念
URL的概念
HTTP协议格式
HTTP请求
HTTP响应
HTTP协议请求方法
使用Postman工具
测试HTTP协议请求方法
HTTP状态码
HTTP常见Header
请求头(Request Headers)
响应头(Response Headers)
Cookie
Session
HTTPS VS HTTP
HTTP协议的概念
HTTP(Hyper Text Transfer Protocol)协议又叫做超文本传输协议,,是一个简单的请求-响应协议,HTTP通常运行在应用层。
- HTTP是无连接, 无状态, 工作在应用层的协议。
- HTTP基于请求-响应模型:客户端(如浏览器)向服务器发送请求,服务器处理请求后返回响应。
- 无连接
- HTTP协议本身不保存客户端状态,每个请求相互独立。
- HTTP协议本身是没有维护连接信息的,HTTP的数据回交给网络协议栈传输层的TCP协议,TCP协议是面向连接的。
- HTTP是可靠传输的,虽然HTTP无连接,自身不会维护连接信息,但是,它的数据最终会交给传输层的TCP协议,而TCP协议是可靠传输的,因此HTTP协议是可靠传输的
- 无状态
- HTTP 协议自身不对请求和响应之间的通信状态进行保存。也就是说在 HTTP 这个级别,协议对于发送过的请求或响应都不做持久化处理
URL的概念
URL(Uniform Resource Lacator)叫做统一资源定位符,也就是我们通常所说的网址,是因特网的万维网服务程序上用于指定信息位置的表示方法。
以下图为例对URL的各部分进行说明:
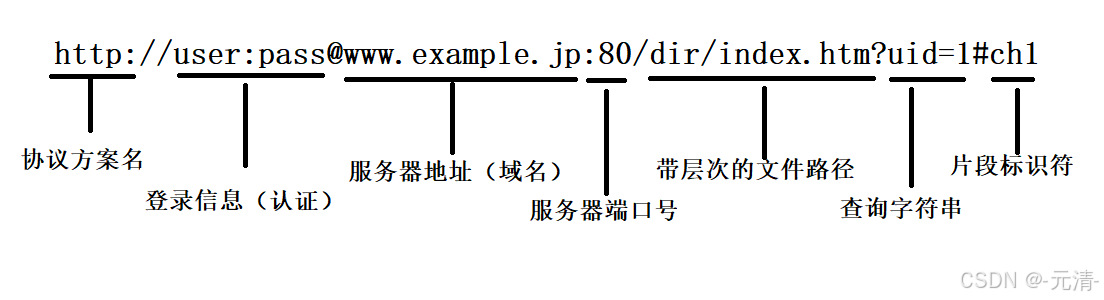
一、协议方案名
http://表示的是协议名称,表示请求时需要使用的协议,通常使用的是HTTP协议或安全协议HTTPS。HTTPS是以安全为目标的HTTP通道,在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性。
- HTTP: 明文传输
- HTTPS:加密传输
- 一般用ssl非对称加密方式,会对 HTTP 双方发送的数据进行加密
- 公钥:客户端所持有,私钥:服务端所持有
- 默认端口:HTTP为
80,HTTPS(加密的HTTP)为443。
常见的应用层协议:
一、网络服务与通信
-
HTTP/HTTPS
-
用途:传输网页、API数据(如浏览器加载网站)。
-
端口:HTTP默认80,HTTPS默认443。
-
特点:基于请求-响应模型,HTTPS通过SSL/TLS加密数据。
-
-
DNS(域名系统)
-
用途:将域名(如
www.example.com)解析为IP地址。 -
端口:UDP 53(查询),TCP 53(区域传输)。
-
特点:分布式数据库,支持递归查询和缓存机制。
-
-
DHCP(动态主机配置协议)
-
用途:自动分配IP地址、子网掩码等网络参数给设备。
-
端口:UDP 67(服务器)、UDP 68(客户端)。
-
特点:简化网络配置,支持地址租约续期。
-
二、文件传输
-
FTP(文件传输协议)
-
用途:上传/下载文件,支持目录操作。
-
端口:控制连接21,数据连接20(主动模式)或随机(被动模式)。
-
特点:明文传输,可通过FTPS(FTP over SSL)加密。
-
-
TFTP(简单文件传输协议)
-
用途:轻量级文件传输(如网络设备固件升级)。
-
端口:UDP 69。
-
特点:无认证机制,基于UDP,适用于局域网。
-
-
SFTP(SSH文件传输协议)
-
用途:通过SSH加密通道安全传输文件。
-
端口:通常SSH的22端口。
-
特点:加密传输,支持文件操作和权限管理。
-
三、电子邮件
-
SMTP(简单邮件传输协议)
-
用途:发送电子邮件(从客户端到服务器或服务器间中转)。
-
端口:25(明文)、465(SMTPS加密)。
-
特点:仅负责发送,不管理接收。
-
-
POP3(邮局协议第3版)
-
用途:从服务器下载邮件到本地设备(如Outlook)。
-
端口:110(明文)、995(POP3S加密)。
-
特点:下载后通常删除服务器上的邮件(可配置保留)。
-
-
IMAP(互联网消息访问协议)
-
用途:在服务器上管理邮件(如Gmail网页版)。
-
端口:143(明文)、993(IMAPS加密)。
-
特点:邮件保留在服务器,支持多设备同步。
-
四、远程管理与通信
-
SSH(安全外壳协议)
-
用途:加密远程登录服务器或执行命令(替代Telnet)。
-
端口:22。
-
特点:支持密钥认证、端口转发和文件传输(SFTP)。
-
-
Telnet
-
用途:明文远程登录设备(如路由器调试)。
-
端口:23。
-
特点:无加密,安全性低,逐渐被SSH取代。
-
-
RDP(远程桌面协议)
-
用途:图形化远程控制Windows计算机。
-
端口:3389。
-
特点:支持音频、剪贴板共享和文件重定向。
-
五、实时通信与物联网
-
MQTT(消息队列遥测传输)
-
用途:轻量级物联网设备通信(如传感器数据传输)。
-
端口:1883(明文)、8883(加密)。
-
特点:基于发布-订阅模型,低带宽消耗。
-
-
WebSocket
-
用途:全双工实时通信(如在线聊天、股票行情)。
-
端口:80(WS)、443(WSS,加密)。
-
特点:基于HTTP升级握手,保持长连接。
-
-
SIP(会话初始协议)
-
用途:建立和管理VoIP(网络电话)或视频会议会话。
-
端口:5060(明文)、5061(加密)。
-
特点:与RTP协议结合传输音视频数据。
-
六、其他重要协议
-
SNMP(简单网络管理协议)
-
用途:监控和管理网络设备(如路由器、交换机)。
-
端口:UDP 161(代理)、162(Trap消息)。
-
特点:通过MIB库定义可管理对象。
-
-
NTP(网络时间协议)
-
用途:同步设备时钟(确保时间一致性)。
-
端口:UDP 123。
-
特点:分层时间源(Stratum层级)。
-
-
LDAP(轻量目录访问协议)
-
用途:访问和维护目录服务(如企业用户认证)。
-
端口:389(明文)、636(LDAPS加密)。
-
二、登录信息
usr:pass表示的是登录认证信息,包括登录用户的用户名和密码。虽然登录认证信息可以在URL中体现出来,但绝大多数URL的这个字段都是被省略的,因为登录信息可以通过其他方案交付给服务器。
三、服务器地址
www.example.jp表示的是服务器地址,也叫做域名,比如www.qq.com,www.baidu.com
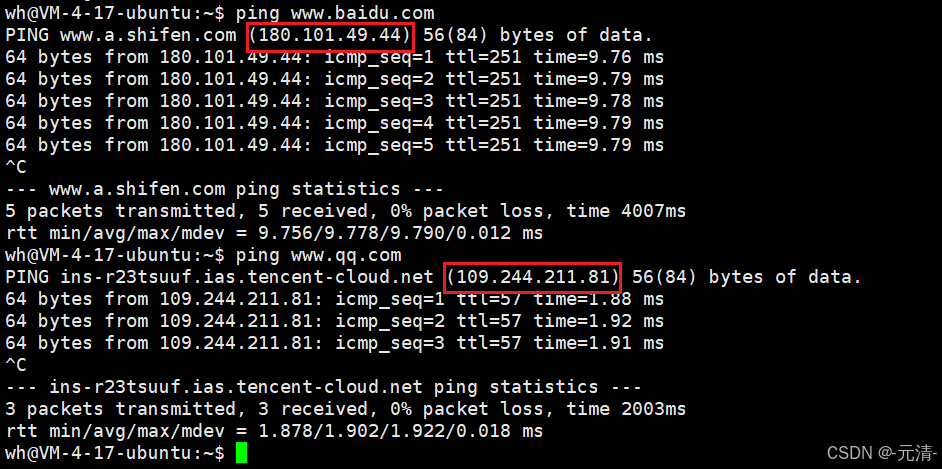
我们用IP地址标识公网内的一台主机,但IP地址本身并不适合给用户看。比如说我们可以通过ping命令,分别获得www.baidu.com 和 www.qq.com这两个域名解析后的IP地址。
四、服务器端口号
80表示的是服务器端口号。HTTP协议和套接字编程一样都是位于应用层的,在进行套接字编程时我们需要给服务器绑定对应的IP和端口,而这里的应用层协议也同样需要有明确的端口号。
当我们使用某种协议时,该协议实际就是在为我们提供服务,现在这些常用的服务与端口号之间的对应关系都是明确的,所以我们在使用某种协议时实际是不需要指明该协议对应的端口号的,因此在URL当中,服务器的端口号一般也是被省略的。
五、带层次的文件路径
/dir/index.htm表示的是要访问的资源所在的路径。访问服务器的目的是获取服务器上的某种资源,通过前面的域名和端口已经能够找到对应的服务器进程了,此时要做的就是指明该资源所在的路径。
比如我们使用浏览器输入qq的域名后,此时浏览器就帮我们获取到了腾讯网的首页。
 当我们查看网页源码,当我们发起网页请求时,本质是获得了这样的一张网页信息,然后浏览器对这张网页信息进行解释,最后就呈现出了对应的网页。
当我们查看网页源码,当我们发起网页请求时,本质是获得了这样的一张网页信息,然后浏览器对这张网页信息进行解释,最后就呈现出了对应的网页。

我们可以将这种资源称为网页资源,此外我们还会向服务器请求视频、音频、网页、图片等资源。HTTP之所以叫做超文本传输协议,而不叫做文本传输协议,就是因为有很多资源实际并不是普通的文本资源。
在URL当中就有这样一个字段,用于表示要访问的资源所在的路径。此外我们可以看到,这里的路径分隔符是/,而不是 \,这也就证明了实际很多服务都是部署在Linux上的。
六、查询字符串
uid=1表示的是请求时提供的额外的参数,这些参数是以键值对的形式,通过&符号分隔开的。
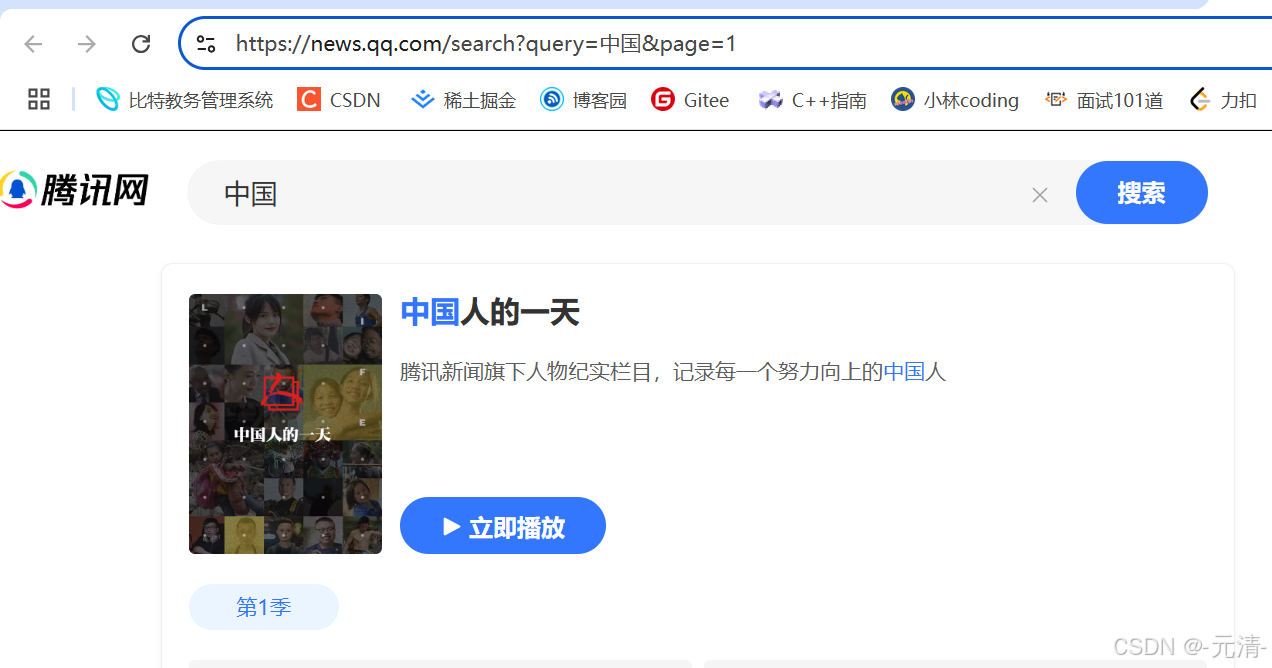
比如我们在腾讯网上面搜索中国,此时可以看到URL中有很多参数,而在这众多的参数当中有一个参数 查询(query),表示的就是我们搜索时的搜索关键字query=中国。
并且通过&符号分隔开的,page=1,代表这是第一页
七、片段标识符
ch1表示的是片段标识符,是对资源的部分补充。
转义(urlencode和urlecode)
如果在搜索关键字当中出现了像/?:这样的字符,由于这些字符已经被URL当作特殊意义理解了,因此URL在呈现时会对这些特殊字符进行转义。
转义的规则如下:
- 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。
- urlencode:将字符转换成为16进制。
- urlecode:将16进制数据转换成字符。
比如当我们搜索C++时,由于+加号在URL当中也是特殊符号,而+字符转为十六进制后的值就是0x2B,因此一个+就会被编码成一个%2B。
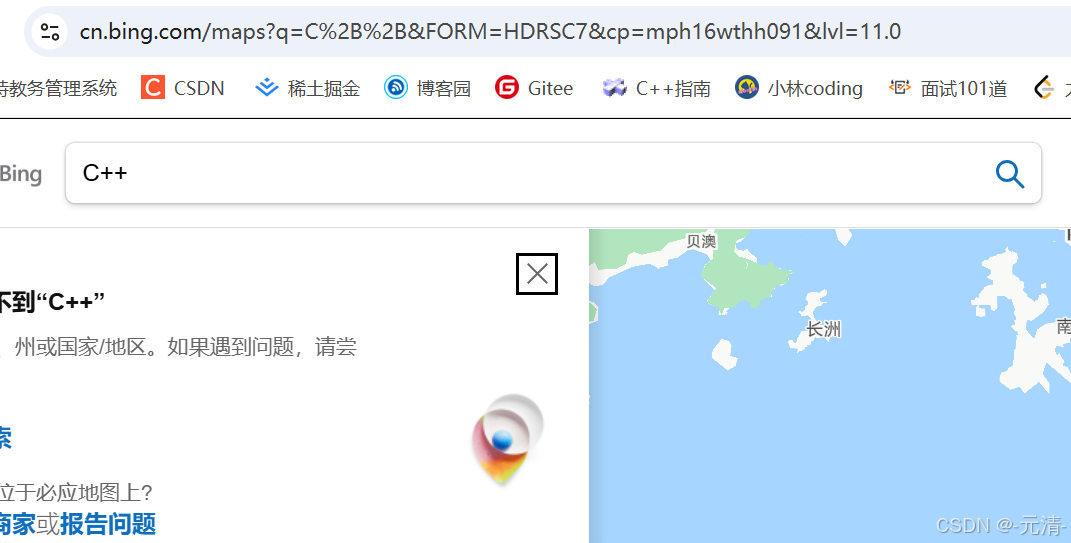
说明一下: URL当中除了会对这些特殊符号做编码,对中文也会进行编码。
HTTP协议格式
HTTP请求
HTTP 协议规定,请求从客户端发出,最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收到请求之前不会发送响应。
HTTP请求协议格式如下:
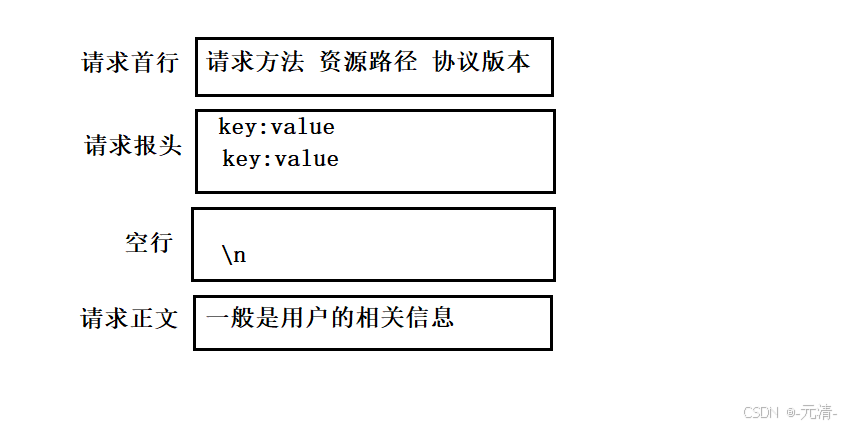
HTTP请求由以下四部分组成:
- 请求行:请求方法 + 资源路径 + 协议版本
- 请求报头:请求的属性,这些属性都是以key: value的形式按行陈列的。
- 空行:遇到空行表示请求报头结束
- 请求正文:请求正文允许为空字符串,如果请求正文存在,则在请求报头中会有一个Content-Length属性来标识请求正文的长度。
其中,前面三部分是一般是HTTP协议自带的,是由HTTP协议自行设置的,而请求正文一般是用户的相关信息或数据,如果用户在请求时没有信息要上传给服务器,此时请求正文就为空字符串。
比如我们在我们的浏览器中搜索 C++,然后按F12打开开发者工具,此时我们再选择 Network,其中 Name表示请求资源的名称,Status表示状态码,Type表示状态类型
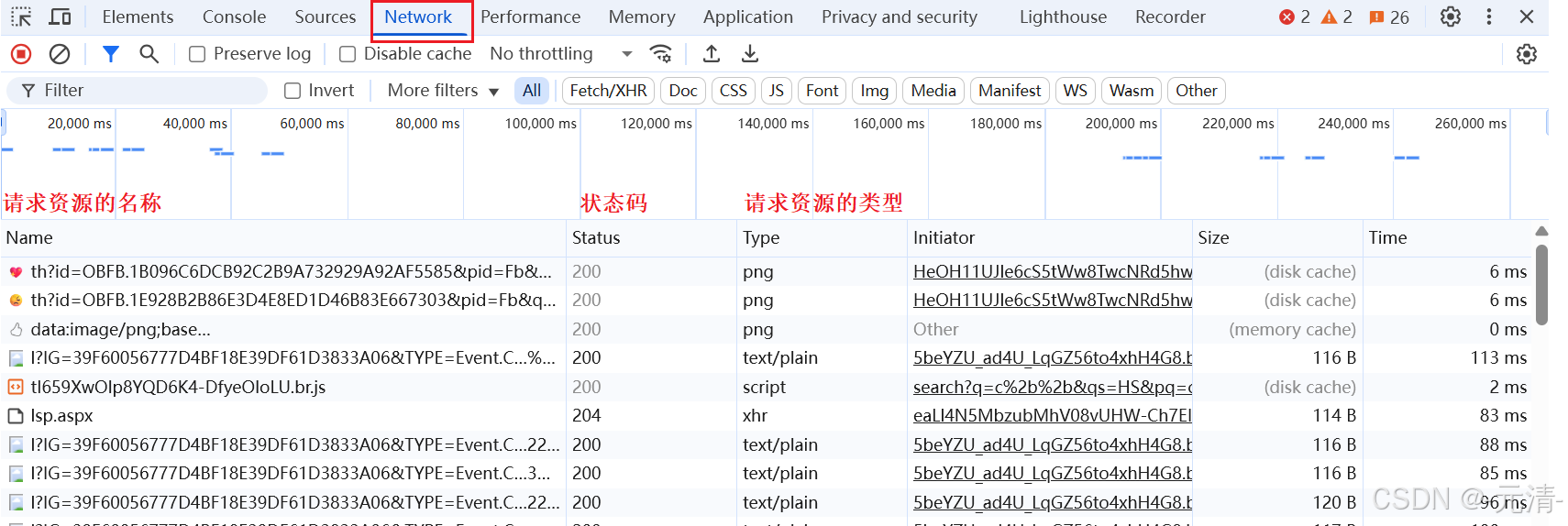
我们按F5 刷新一下,然后我们点击一个资源,划到最后。
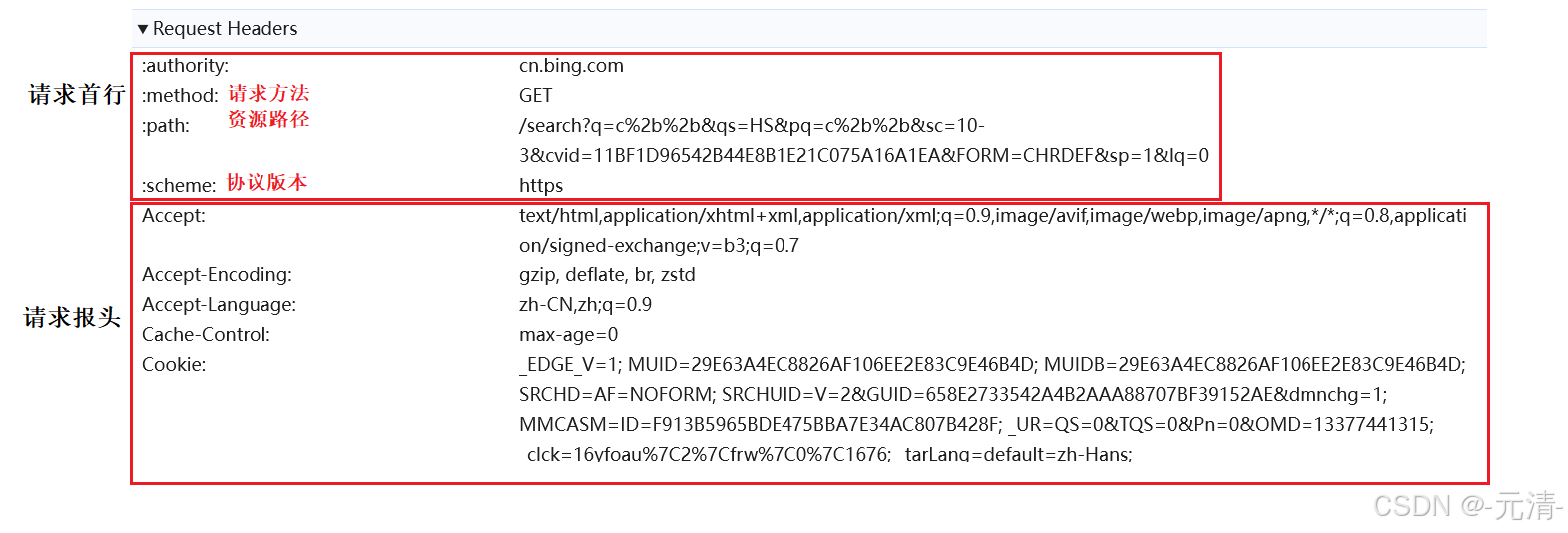
如何将HTTP请求的报头与有效载荷进行分离?
当应用层收到一个HTTP请求时,它必须想办法将HTTP的报头与有效载荷进行分离。对于HTTP请求来讲,这里的请求行和请求报头就是HTTP的报头信息,而这里的请求正文实际就是HTTP的有效载荷。
我们可以根据HTTP请求当中的空行来进行分离,当服务器收到一个HTTP请求后,就可以按行进行读取,如果读取到空行则说明已经将报头读取完毕,实际HTTP请求当中的空行就是用来分离报头和有效载荷的。
如果将HTTP请求想象成一个大的线性结构,此时每行的内容都是用\n隔开的,因此在读取过程中,如果连续读取到了两个\n,就说明已经将报头读取完毕了,后面剩下的就是有效载荷了。
获取客户端(浏览器)的HTTP请求
在网络协议栈中,应用层的下层是传输层,而HTTP协议底层通常使用的传输层协议是TCP协议,因此我们可以用套接字编写一个TCP服务器,然后启动浏览器访问我们的这个服务器。
由于我们的服务器是直接用TCP套接字读取浏览器发来的HTTP请求,此时在服务端没有应用层对这个HTTP请求进行过任何解析,因此我们可以直接将浏览器发来的HTTP请求进行打印输出,此时就能看到HTTP请求的基本构成。
#include <iostream>
#include <fstream>
#include <string>
#include <cstring>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
using namespace std;
int main()
{
// 创建 TCP 套接字(IPv4协议,流式套接字)
int listen_sock = socket(AF_INET, SOCK_STREAM, 0);
if (listen_sock < 0)
{
cerr << "socket error!" << endl;
return 1;
}
// 配置服务器地址结构
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET; // IPv4 地址族
local.sin_port = htons(8888); // 绑定端口 8081(主机字节序转网络字节序)
local.sin_addr.s_addr = htonl(INADDR_ANY); // 绑定所有可用网络接口
// 将套接字与地址绑定
if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0)
{
cerr << "bind error!" << endl;
return 2;
}
// 开始监听连接请求,最大等待队列长度为5
if (listen(listen_sock, 5) < 0)
{
cerr << "listen error!" << endl;
return 3;
}
// 主循环持续接受客户端连接
struct sockaddr peer;
memset(&peer, 0, sizeof(peer));
socklen_t len = sizeof(peer);
for (;;)
{
// 接受新连接,生成用于通信的套接字
int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);
if (sock < 0)
{
cerr << "accept error!" << endl;
continue; // 跳过本次错误,继续监听
}
// 创建子进程处理请求(第一层 fork)
if (fork() == 0)
{
// 子进程代码区域
close(listen_sock); // 子进程不需要监听套接字
// 第二次 fork 创建孙子进程(避免僵尸进程)
if (fork() > 0)
{
// 父进程(即第一层子进程)立即退出
exit(0);
}
/* 孙子进程代码区域(由 init 进程接管)*/
char buffer[1024];
// 读取客户端发送的 HTTP 请求(未处理完整数据)
recv(sock, buffer, sizeof(buffer), 0);
// 打印原始 HTTP 请求内容
cout << "--------------------------http request begin--------------------------" << endl;
cout << buffer << endl;
cout << "---------------------------http request end---------------------------" << endl;
close(sock); // 关闭通信套接字
exit(0); // 孙子进程退出
}
// 主进程(爷爷进程)代码区域
close(sock); // 主进程不需要通信套接字
// 等待所有子进程结束(回收第一层子进程)
waitpid(-1, nullptr, 0);
}
return 0;
}运行服务器程序后,然后用客户端(浏览器)进行访问,此时我们的服务器就会收到客户端(浏览器)发来的HTTP请求,并将收到的HTTP请求进行打印输出。
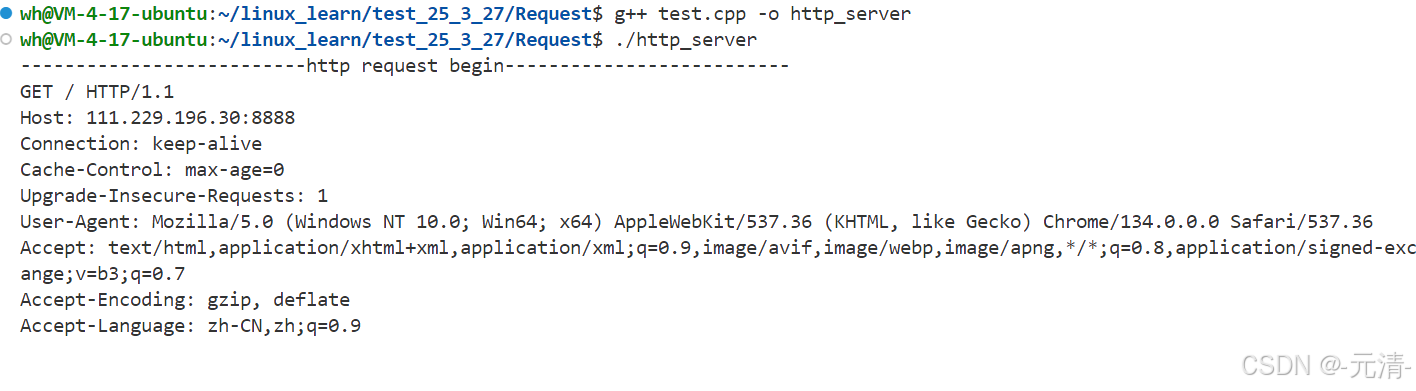
说明:
1、浏览器重复请求原因
-
若服务器未返回 HTTP 响应,浏览器会认为请求失败,触发自动重试机制。
-
示例:访问
http://111.229.196.30:8888后无响应 → 浏览器自动重试 3~5 次(具体次数由浏览器实现决定)。
2、URL 协议省略规则
-
浏览器默认使用 HTTP 协议,输入
example.com等效于http://example.com。 -
例外:若网站强制 HTTPS(如配置 HSTS),浏览器会自动跳转至 HTTPS。
3、URL 中的 / 含义
-
/表示 Web 根目录,由服务器配置指定,与操作系统根目录无关。 -
示例:
-
Nginx 配置中
root /var/www/html;→ 访问/对应服务器上的/var/www/html。 -
Apache 配置中
DocumentRoot "/home/user/web"→/对应/home/user/web。
-
4、最后有两行空行的原因
- 而请求报头当中全部都是以
key: value形式按行陈列的各种请求属性,请求属性陈列完后紧接着的就是一个空行。 - 空行后的就是本次HTTP请求的请求正文,此时请求正文为空字符串,因此这里有两个空行。
HTTP响应
HTTP响应协议格式如下:
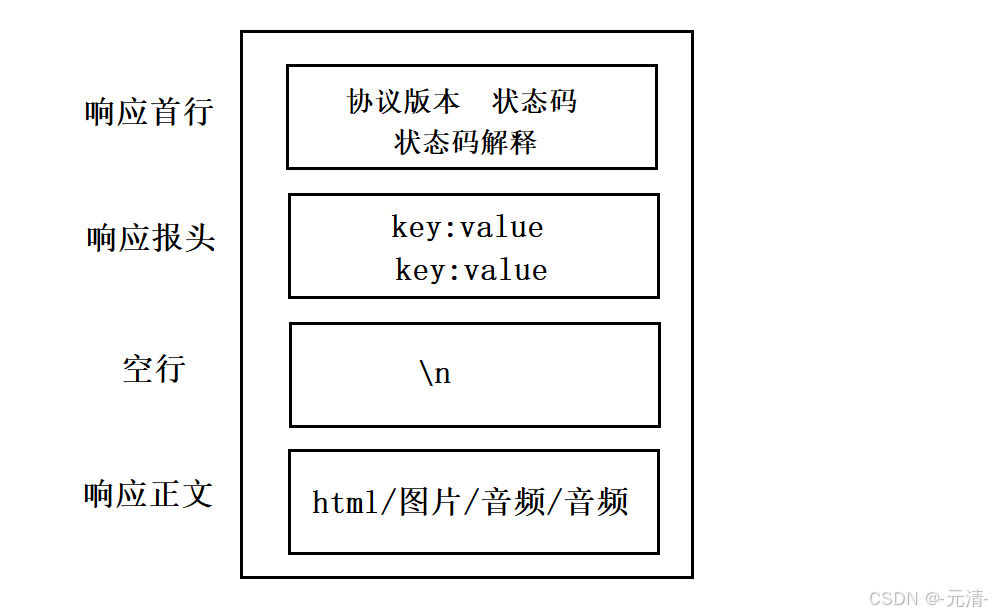
HTTP响应由以下四部分组成:
- 状态行:协议版本 + 状态码 + 状态码解释
- 响应报头:响应的属性,这些属性都是以key: value的形式按行陈列的。
- 空行:遇到空行表示响应报头结束。
- 响应正文:响应正文允许为空字符串,如果响应正文存在,则响应报头中会有一个Content-Length属性来标识响应正文的长度。比如服务器返回了一个html页面,那么这个html页面的内容就是在响应正文当中的。
响应客户端(浏览器)的HTTP请求
-
设定网站根目录
-
将服务器程序运行的当前目录作为网站内容存储位置(Web根目录)
-
-
创建默认首页文件
-
在Web根目录下创建 test
.html文件,编写简单的HTML内容(如欢迎页面)
-
-
接收请求(不解析)
-
当浏览器发起任意HTTP请求时(如访问
/或/abc),服务器均不分析请求内容,直接进入响应流程
-
-
固定响应策略
-
无视请求路径:无论浏览器请求什么资源,始终强制返回 test
.html文件内容 -
读取文件:打开 test
.html并读取其全部文本内容
-
-
构造HTTP响应包
-
在响应头中标注:
✓ 协议版本HTTP/1.1 200 OK
✓ 内容类型Content-Type: text/html
✓ 文件长度Content-Length -
将 test
.html内容作为响应正文
-
-
完成交互
-
将构建好的HTTP响应发送给浏览器
-
立即关闭连接(短连接模式)
-
// test.html
<html>
<head></head>
<body>
<h1>Hello HTTP</h1>
<h2>Hello XO</h2>
</body>
</html>#include <iostream>
#include <fstream>
#include <string>
#include <cstring>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
using namespace std;
int main()
{
// 创建监听套接字,使用IPv4协议和TCP流式传输
int listen_sock = socket(AF_INET, SOCK_STREAM, 0);
if (listen_sock < 0)
{
cerr << "socket error!" << endl;
return 1;
}
// 初始化服务器地址结构体
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET; // 使用IPv4地址族
local.sin_port = htons(8888); // 监听8888端口(主机字节序转网络字节序)
local.sin_addr.s_addr = htonl(INADDR_ANY); // 绑定所有可用网络接口
// 绑定套接字与地址
if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0)
{
cerr << "bind error!" << endl;
return 2;
}
// 开始监听,设置等待队列最大长度为5
if (listen(listen_sock, 5) < 0)
{
cerr << "listen error!" << endl;
return 3;
}
// 主服务循环
struct sockaddr peer; // 用于存储客户端地址信息
socklen_t len = sizeof(peer); // 地址结构体长度
for (;;)
{
// 接受客户端连接请求,创建通信套接字
int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);
if (sock < 0)
{
cerr << "accept error!" << endl;
continue; // 继续等待其他连接
}
// 创建子进程处理请求(父进程继续监听新连接)
if (fork() == 0) // 子进程(第一层,简称父进程)
{
close(listen_sock); // 子进程不需要监听,关闭监听套接字
// 创建孙进程处理实际请求(双fork避免僵尸进程)
if (fork() > 0) // 父进程(第一层子进程)
{
exit(0); // 立即退出,使子进程成为孤儿进程
}
/* ========== 孙进程(实际处理请求)========== */
char buffer[1024];
recv(sock, buffer, sizeof(buffer), 0); // 读取客户端HTTP请求
// 打印原始请求信息(用于调试)
cout << "--------------------------http request begin--------------------------" << endl;
cout << buffer << endl;
cout << "---------------------------http request end---------------------------" << endl;
// 定义网页文件路径
#define PAGE "test.html"
// 读取网页文件内容
ifstream in(PAGE);
if (in.is_open())
{
// 获取文件大小
in.seekg(0, in.end);
int len = in.tellg();
in.seekg(0, in.beg);
// 读取文件内容到内存
char* file = new char[len];
in.read(file, len);
in.close();
// 构建HTTP响应报文
string status_line = "HTTP/1.1 200 OK\n"; // 状态行
string response_header = "Content-Length: " + to_string(len) + "\n"; // 内容长度头
string blank = "\n"; // 空行(应使用\r\n符合HTTP标准)
string response_text(file, len); // 响应正文
string response = status_line + response_header + blank + response_text;
// 发送响应到客户端
send(sock, response.c_str(), response.size(), 0);
delete[] file; // 释放文件内存
}
close(sock); // 关闭通信套接字
exit(0); // 孙进程退出
}
// 主进程(祖父进程)处理
close(sock); // 主进程不需要通信套接字
waitpid(-1, nullptr, 0); // 等待子进程退出(防止僵尸进程)
}
return 0;
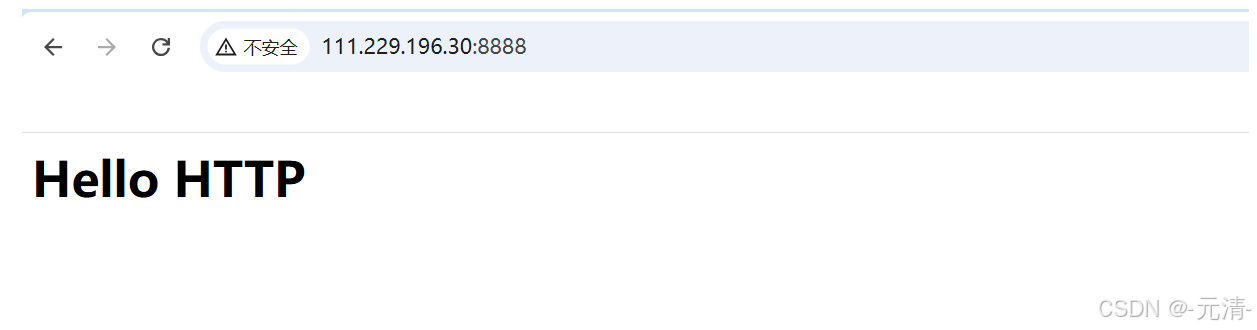
}我们使用客户端(浏览器)访问我们的TCP服务端,可以直接看到我们使用客户端(浏览器)访问后,TCP服务端响应了,并且 test.html 文件被浏览器解释后就显示出相应的内容 Hello HTTP
HTTP协议请求方法
HTTP常见的方法如下:
| 方法名称 | 作用 | 支持的协议版本 | 备注 |
|---|---|---|---|
| GET | 请求获取指定资源,参数通过 URL 传递,无请求体。 | HTTP/0.9、1.0、1.1、2.0+ | 最早支持的方法,用于读取数据239。 |
| POST | 提交数据到服务器(如表单、文件上传),参数可通过 URL 或请求体传递。 | HTTP/1.0、1.1、2.0+ | 常用于创建或修改资源,支持复杂数据269。 |
| HEAD | 与 GET 类似,但仅返回响应头(无响应体),用于检查资源元信息或有效性。 | HTTP/1.0、1.1、2.0+ | 常用于资源缓存验证269。 |
| PUT | 上传或替换指定资源的最新内容。 | HTTP/1.1、2.0+ | 需配合验证机制使用(如 RESTful API)29。 |
| DELETE | 请求删除指定资源。 | HTTP/1.1、2.0+ | 通常需权限控制29。 |
| OPTIONS | 查询服务器对指定资源支持的 HTTP 方法列表。 | HTTP/1.1、2.0+ | 用于跨域请求预检(CORS)269。 |
| TRACE | 回显客户端请求,用于诊断或测试代理服务器路径。 | HTTP/1.1 | 因安全风险(如 XST 攻击)较少使用29。 |
| CONNECT | 建立与代理服务器的隧道连接(如 HTTPS 代理)。 | HTTP/1.1、2.0+ | 用于加密通信通道269。 |
| PATCH | 对资源进行局部修改(非全量替换)。 | HTTP/1.1(扩展) | 由 RFC 5789 定义,需服务器明确支持9。 |
GET方法
-
核心功能:客户端通过
GET方法向服务器请求指定资源(如 HTML 文件、图片、数据等)。 -
参数传递:请求参数通常附加在 URL 的查询字符串中(如
/page?name=Alice&age=20)。
GET /path/to/resource?param1=value1¶m2=value2 HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0
Accept: text/html
POST方法
-
数据提交:客户端通过
POST方法向服务器提交数据(如表单内容、文件、JSON 等)。 -
参数传递:POST方法是通过正文传参的。
-
非幂等操作:多次相同的 POST 请求可能导致不同结果(如重复提交订单会创建多个记录)。
使用POST方法传参更加私密,因为POST方法不会将你的参数回显到url当中,此时也就不会被别人轻易看到。不能说POST方法比GET方法更安全,因为POST方法和GET方法实际都不安全,要做到安全只能通过加密来完成。
| 特性 | GET | POST |
|---|---|---|
| 数据位置 | URL 查询字符串 | 请求正文(Body) |
| 数据长度 | 受 URL 长度限制(通常不超过 2048 字符) | 无限制 |
| 缓存性 | 可被缓存 | 不可缓存 |
| 安全性 | 参数可见(不适合敏感数据) | 参数不可见(相对更安全) |
| 使用场景 | 获取数据(搜索、页面跳转) | 提交数据(登录、文件上传) |
使用Postman工具
Postman 是一款用于 API 开发与测试 的跨平台工具,支持 HTTP 请求构建、响应分析、自动化测试等功能。
我们如何去使用呢,我们直接去浏览器搜索Postman,点击官网并且注册登录即可
点击个人项目
 并且切换到调式模式
并且切换到调式模式
测试HTTP协议请求方法
GET方法
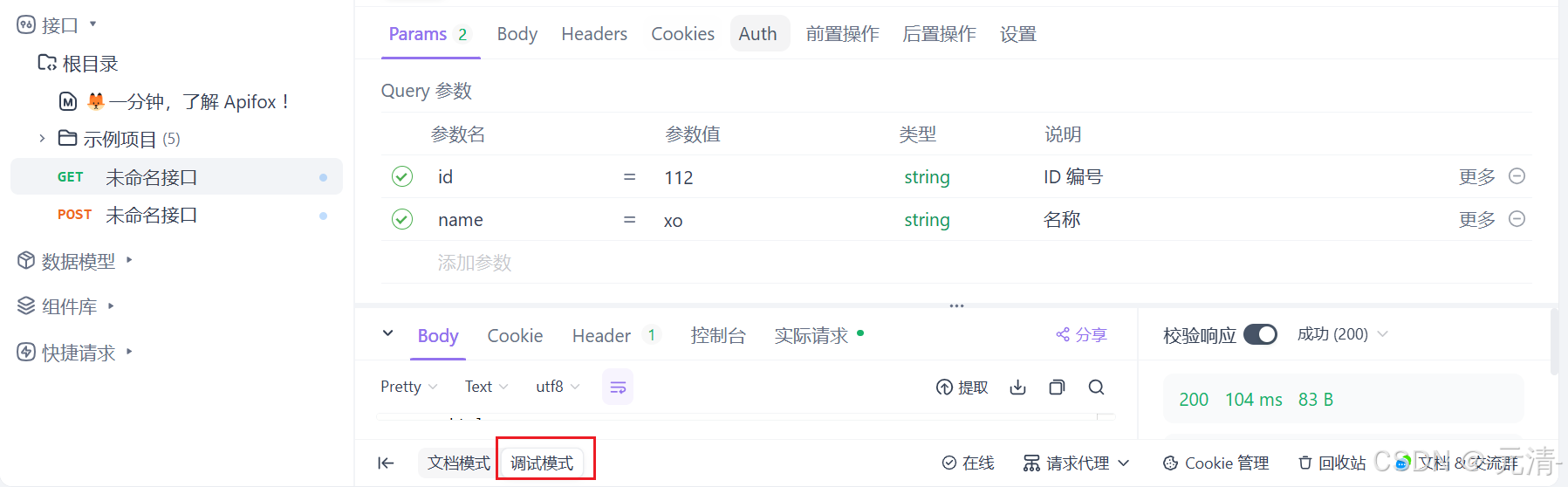
如果访问我们的服务器时使用的是GET方法,此时应该通过url进行传参,可以在Params下进行参数设置,因为Postman当中的Params就相当于url当中的参数,你在设置参数时可以看到对应的url也在随之变化。
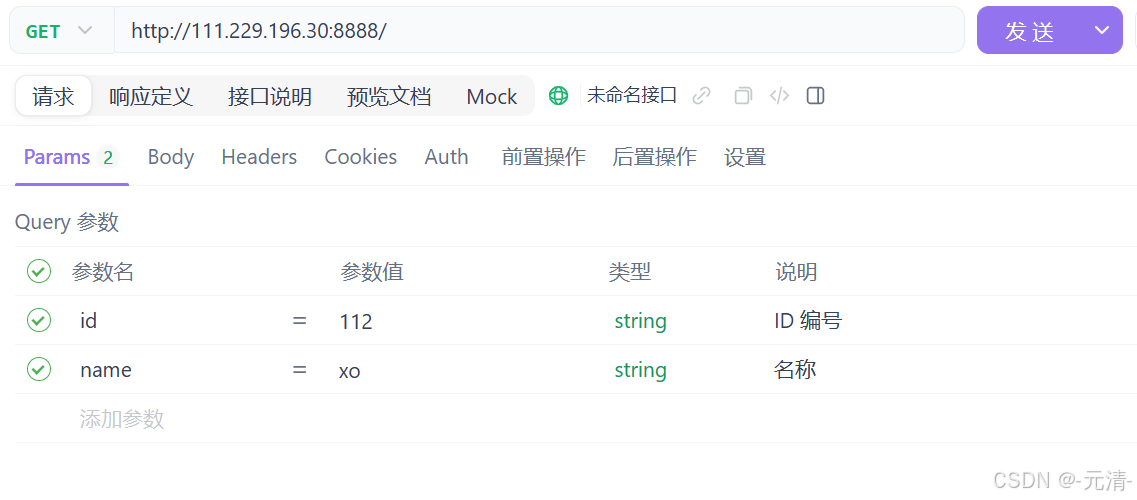
此时在我们的TCP服务器收到的HTTP请求当中,可以看到请求行中的url就携带上了我们刚才在Postman当中设置的参数
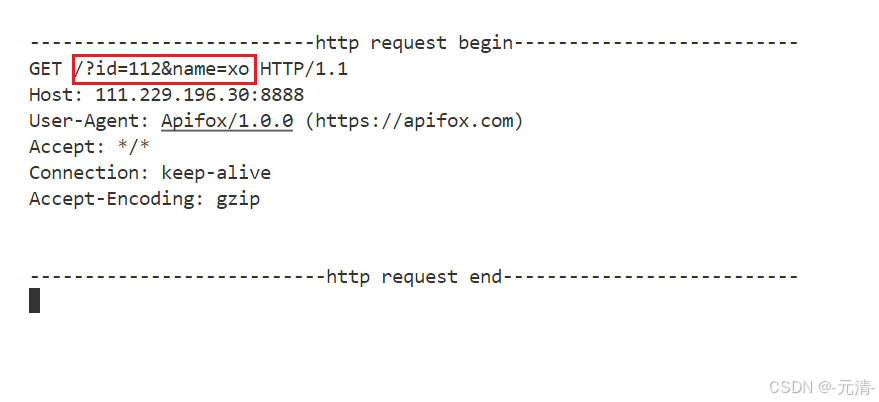
POST方法
如果我们使用的是POST方法,此时就应该通过正文进行传参,可以在Body下进行参数设置,在设置时可以选中Postman当中的raw方式传参,表示原始传参,也就是你输入的参数是什么样的实际传递的参数就是什么样的。
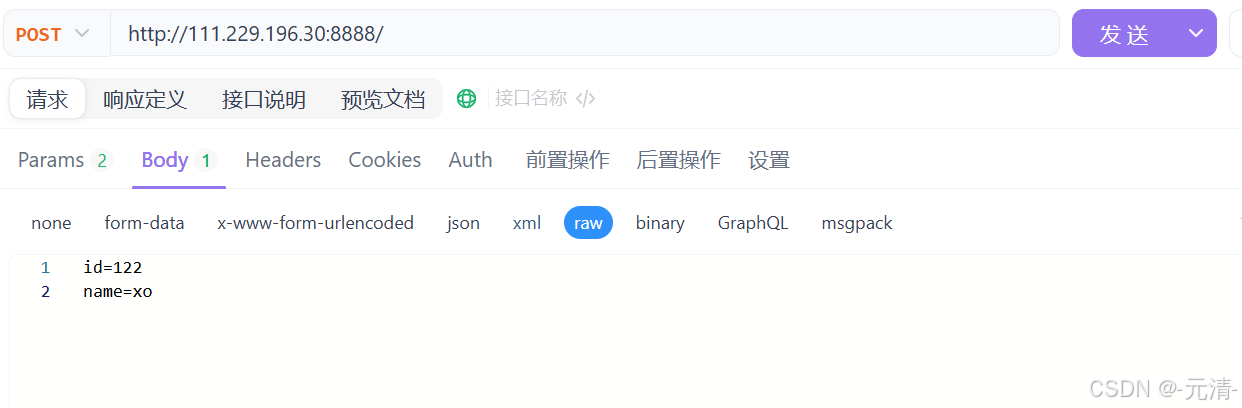
此时服务器收到的HTTP请求的请求正文就不再是空字符串了,而是我们通过正文传递的参数。
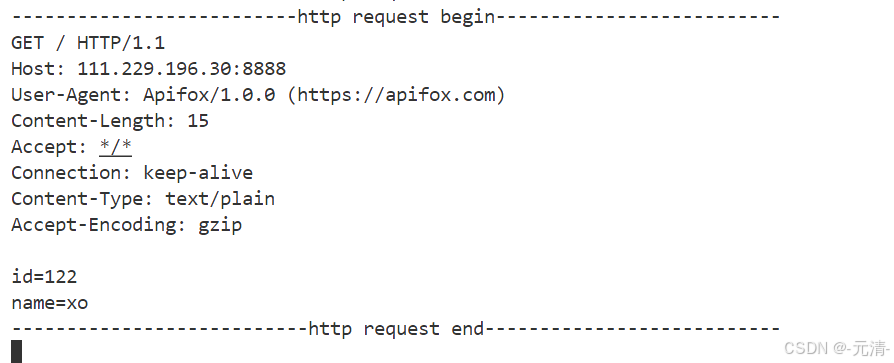
HTTP状态码
HTTP 状态码是服务器对客户端请求的响应状态标识,由三位数字和状态短语组成(如 200 OK)。它们分为五类,通过首位数字区分:
| 代码 | 类型 | 常见状态码 |
|---|---|---|
| 1xx | 信息 | 100, 101 |
| 2xx | 成功 | 200, 201, 204, 206 |
| 3xx | 重定向 | 301, 302, 304, 307 |
| 4xx | 客户端错误 | 400, 401, 403, 404, 405 |
| 5xx | 服务器错误 | 500, 502, 503, 504 |
1xx(信息性状态码)
表示请求已被接收,需要继续处理。
-
100 Continue
→ 客户端应继续发送请求正文(用于大文件上传前的确认) -
101 Switching Protocols
→ 服务器同意切换协议(如从 HTTP 升级到 WebSocket)
2xx(成功状态码)
表示请求已被服务器成功接收、理解并处理。
-
200 OK
→ 请求成功(通用成功响应,如返回网页或数据) -
201 Created
→ 资源创建成功(常用于POST请求,响应头应包含Location: 新资源路径) -
204 No Content
→ 请求成功,但无返回内容(如删除操作成功) -
206 Partial Content
→ 分片请求成功(用于大文件断点续传)
3xx(重定向状态码)
表示客户端需进一步操作以完成请求。
-
301 Moved Permanently
→ 资源已永久迁移(搜索引擎会更新链接,响应头需带Location: 新URL) -
302 Found
→ 资源临时重定向(浏览器下次仍访问原URL) -
304 Not Modified
→ 资源未修改(客户端可使用缓存副本,需配合If-Modified-Since等头使用) -
307 Temporary Redirect
→ 临时重定向(强制要求保持原请求方法,如POST请求不会变为GET)
4xx(客户端错误状态码)
表示请求存在语法错误或无法完成。
-
400 Bad Request
→ 请求格式错误(如参数缺失或格式非法) -
401 Unauthorized
→ 未认证(需提供身份验证,如登录后访问受保护资源) -
403 Forbidden
→ 无权限访问(认证成功但权限不足) -
404 Not Found
→ 资源不存在(路径错误或文件被删除) -
405 Method Not Allowed
→ 请求方法不被允许(如用GET访问只支持POST的接口) -
408 Request Timeout
→ 请求超时(服务器等待超时) -
415 Unsupported Media Type
→ 不支持的媒体类型(如上传文件的格式服务器无法处理) -
429 Too Many Requests
→ 请求过于频繁(用于限流防护)
5xx(服务器错误状态码)
表示服务器处理请求时发生错误。
-
500 Internal Server Error
→ 服务器内部错误(通用错误,如代码异常) -
501 Not Implemented
→ 服务器不支持请求的功能(如未实现的 HTTP 方法) -
502 Bad Gateway
→ 网关或代理服务器收到无效响应(常见于反向代理配置错误) -
503 Service Unavailable
→ 服务不可用(服务器过载或维护) -
504 Gateway Timeout
→ 网关超时(代理服务器未能及时获取响应)
Redirection(重定向状态码)
重定向就是通过各种方法将各种网络请求重新定个方向转到其它位置,此时这个服务器相当于提供了一个引路的服务。
重定向又可分为临时重定向和永久重定向,其中状态码301表示的就是永久重定向,而状态码302和307表示的是临时重定向。
临时重定向和永久重定向本质是影响客户端的标签,决定客户端是否需要更新目标地址。如果某个网站是永久重定向,那么第一次访问该网站时由浏览器帮你进行重定向,但后续再访问该网站时就不需要浏览器再进行重定向了,此时你访问的直接就是重定向后的网站。而如果某个网站是临时重定向,那么每次访问该网站时如果需要进行重定向,都需要浏览器来帮我们完成重定向跳转到目标网站。
将我们的TCP服务器重定向到 www.qq.com
#include <iostream>
#include <fstream>
#include <string>
#include <cstring>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
using namespace std;
int main()
{
// 创建 TCP 套接字(IPv4协议,流式套接字)
int listen_sock = socket(AF_INET, SOCK_STREAM, 0);
if (listen_sock < 0)
{
cerr << "socket error!" << endl;
return 1;
}
// 配置服务器地址结构
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET; // IPv4 地址族
local.sin_port = htons(8888); // 绑定端口 8888(主机字节序转网络字节序)
local.sin_addr.s_addr = htonl(INADDR_ANY); // 绑定所有可用网络接口
// 将套接字与地址绑定
if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0)
{
cerr << "bind error!" << endl;
return 2;
}
// 开始监听连接请求,最大等待队列长度为5
if (listen(listen_sock, 5) < 0)
{
cerr << "listen error!" << endl;
return 3;
}
// 主循环持续接受客户端连接
struct sockaddr peer;
memset(&peer, 0, sizeof(peer));
socklen_t len = sizeof(peer);
for (;;)
{
// 接受新连接,生成用于通信的套接字
int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);
if (sock < 0)
{
cerr << "accept error!" << endl;
continue; // 跳过本次错误,继续监听
}
// 创建子进程处理请求(第一层 fork)
if (fork() == 0)
{
// 子进程代码区域
close(listen_sock); // 子进程不需要监听套接字
// 第二次 fork 创建孙子进程(避免僵尸进程)
if (fork() > 0)
{
// 父进程(即第一层子进程)立即退出
exit(0);
}
/* 孙子进程代码区域(由 init 进程接管)*/
char buffer[1024];
// 读取客户端发送的 HTTP 请求(未处理完整数据)
recv(sock, buffer, sizeof(buffer), 0);
// 打印原始 HTTP 请求内容
cout << "--------------------------http request begin--------------------------" << endl;
cout << buffer << endl;
cout << "---------------------------http request end---------------------------" << endl;
//构建HTTP响应
string status_line = "http/1.1 307 Temporary Redirect\n"; //状态行
string response_header = "Location: https://blog.csdn.net/weixin_74268082?type=blog\n"; //响应报头
string blank = "\n"; //空行
string response = status_line + response_header + blank; //响应报文
//响应HTTP请求
send(sock, response.c_str(), response.size(), 0);
close(sock); // 关闭通信套接字
exit(0); // 孙子进程退出
}
// 主进程(爷爷进程)代码区域
close(sock); // 主进程不需要通信套接字
// 等待所有子进程结束(回收第一层子进程)
waitpid(-1, nullptr, 0);
}
return 0;
}此时当浏览器访问我们的服务器时,就会立马跳转到CSDN元清的首页。
HTTP常见Header
请求头(Request Headers)
| Header 名称 | 作用描述 | 示例 |
|---|---|---|
| Host | 指定请求的目标域名(HTTP/1.1 必需字段) | Host: example.com |
| User-Agent | 标识客户端类型(浏览器、设备等) | User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) |
| Content-Type | 请求体数据的格式(如 JSON、表单等) | Content-Type: application/json |
| Authorization | 携带身份凭证(如 Token、Basic 认证) | Authorization: Bearer abcdef12345 |
| Cookie | 携带客户端存储的 Cookie 信息 | Cookie: sessionId=abc123; username=alice |
| Accept | 声明客户端可接受的响应格式 | Accept: text/html, application/json |
| Accept-Language | 声明客户端优先接受的语言 | Accept-Language: en-US, zh-CN |
| Referer | 表示当前请求的来源页面 URL | Referer: https://example.com/page1 |
| Origin | 标识跨域请求的源域名(用于 CORS) | Origin: https://client-site.com |
| Cache-Control | 控制客户端或代理的缓存行为 | Cache-Control: no-cache |
Content-Length | 请求体的字节长度 |
响应头(Response Headers)
| Header 名称 | 作用描述 | 示例 |
|---|---|---|
| Content-Type | 响应体数据的格式(如 HTML、JSON) | Content-Type: text/html; charset=utf-8 |
| Content-Length | 响应体的字节长度 | Content-Length: 1024 |
| Set-Cookie | 服务器设置 Cookie 到客户端 | Set-Cookie: sessionId=abc123; Path=/; Max-Age=3600 |
| Cache-Control | 控制客户端或代理的缓存行为 | Cache-Control: max-age=3600 |
| Location | 重定向目标 URL(配合 3xx 状态码) | Location: https://example.com/new-page |
| Access-Control-Allow-Origin | 允许跨域请求的源(CORS 关键头) | Access-Control-Allow-Origin: * |
| ETag | 资源唯一标识符(用于缓存验证) | ETag: "33a64df5" |
| Server | 标识服务器软件信息 | Server: nginx/1.18.0 |
| X-Content-Type-Options | 禁止浏览器猜测内容类型(安全防护) | X-Content-Type-Options: nosniff |
| WWW-Authenticate | 要求客户端进行身份认证(配合 401 状态码) | WWW-Authenticate: Basic realm="User Visible Realm" |
安全相关
-
X-Content-Type-Options: nosniff
→ 禁止浏览器猜测内容类型 -
X-Frame-Options: SAMEORIGIN
→ 防止页面被嵌入 iframe
一句话总结:
日常开发关注 Content-Type、Authorization、Cache-Control、Access-Control-Allow-Origin 即可覆盖 80% 场景。
Cookie
1. HTTP 无状态协议的本质问题
HTTP 协议本身是无状态的,意味着服务器默认不会记录客户端的历史请求信息。若没有额外技术支持,每次客户端发起请求时,服务器都会将其视为全新独立的交互。这将导致:
-
重复身份认证:用户每次访问受保护资源(如 VIP 视频、个人账户)时,需重新输入账号密码。
-
体验割裂:例如,视频网站有数千个 VIP 视频,用户点击每个视频时均需重新登录,操作繁琐且不现实。
2. Cookie 技术的核心价值
Cookie 是 HTTP 协议中为解决无状态问题而设计的状态管理机制,其核心功能是在客户端与服务器之间维持会话状态,实现“一次认证,持续访问”。
典型场景:
- 首次认证:用户登录时输入账号密码,服务器验证合法性。
- 状态标记:若认证通过,服务器生成唯一标识(如
Session ID),通过响应头Set-Cookie发送给浏览器。
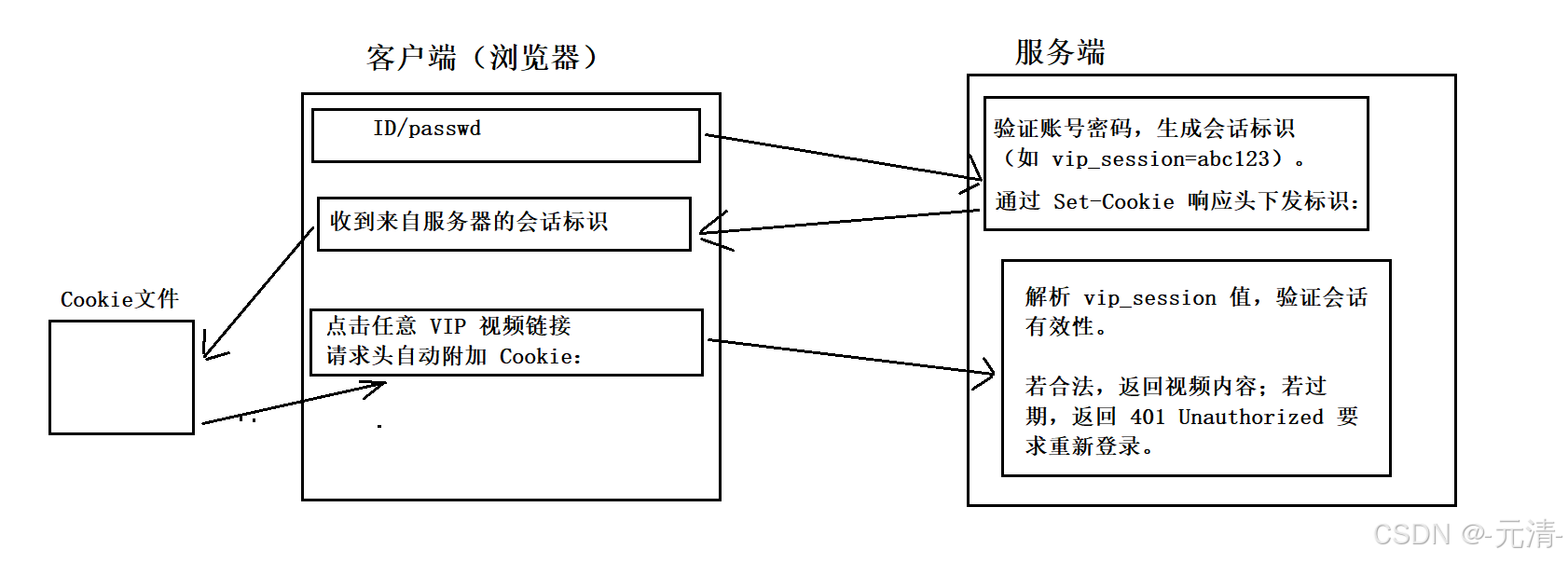
3. Cookie 的工作流程详解
以视频网站 VIP 身份验证为例:
一、登录阶段
-
客户端:提交账号密码至
/login接口。 -
服务端:
-
验证账号密码,生成会话标识(如
vip_session=abc123)。 -
通过
Set-Cookie响应头下发标识:
-
HTTP/1.1 200 OK
Set-Cookie: vip_session=abc123; Path=/; Max-Age=86400; Secure; HttpOnly二、资源访问阶段
-
客户端:点击任意 VIP 视频链接,请求头自动附加 Cookie:
GET /videos/premium/123 HTTP/1.1
Cookie: vip_session=abc123-
服务端:
-
解析
vip_session值,验证会话有效性。 -
若合法,返回视频内容;若过期,返回
401 Unauthorized要求重新登录。
-
4. Cookie 的存储与管理
-
浏览器存储:
-
Cookie 被保存在浏览器本地(内存或持久化文件中)。
-
按
Domain和Path隔离,不同网站无法互相访问。
-
-
生命周期:
-
会话 Cookie:浏览器关闭即失效(未设置
Expires或Max-Age)。 -
持久 Cookie:根据有效期长期存在(如
Max-Age=86400保存 24 小时)。
-
Session
一、Cookie 的安全隐患与 SessionID 的引入
-
Cookie 盗取风险
-
问题本质:浏览器存储的 Cookie 若被恶意程序窃取(如木马、钓鱼链接),攻击者可利用其冒充用户身份访问网站。
-
示例场景:用户点击恶意链接后,程序扫描浏览器 Cookie 目录并上传至攻击者服务器,攻击者将 Cookie 植入自身浏览器以伪装成用户。
-
-
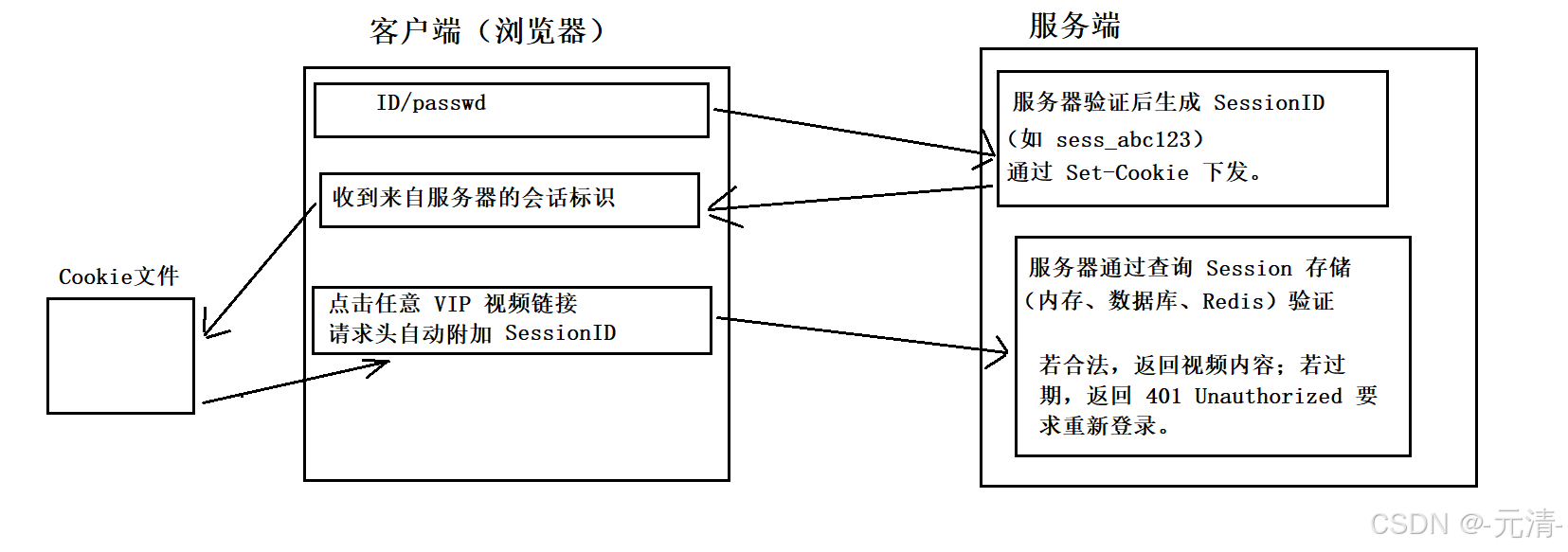
SessionID 的设计初衷
-
敏感信息隔离:服务器不再将用户账号密码存入 Cookie,而是生成无意义的随机字符串 SessionID,将其与用户身份绑定后存储在服务端。
-
流程优化:
-
首次登录:用户提交账号密码,服务器验证后生成 SessionID(如
sess_abc123),通过Set-Cookie下发。 -
后续请求:浏览器自动携带 SessionID,服务器通过查询 Session 存储(内存、数据库、Redis)验证用户身份。
-
-
二、SessionID 的安全机制与局限性
-
SessionID 的优势
-
最小化敏感信息暴露:网络传输中仅传递 SessionID,而非原始账号密码。
-
服务端可控性:
-
过期策略:设置 Session 有效期(如 1 小时),超时后需重新登录。
-
主动销毁:用户主动登出或检测异常时,服务器可立即删除对应 SessionID。
-
-
-
SessionID 的潜在风险
-
会话劫持:若 SessionID 被盗,攻击者可在有效期内冒充用户(如通过中间人攻击)。
-
示例攻击链:
-
用户访问钓鱼网站,SessionID 被恶意脚本窃取。
-
攻击者使用该 SessionID 发起请求,服务器误判为合法用户。
-
-
三、服务器端安全增强策略
-
多维度风控检测
-
IP 归属分析:检测登录 IP 的地理位置突变(如 10 分钟内从北京跳转至纽约)。
-
设备指纹:结合 User-Agent、屏幕分辨率、插件列表等生成唯一设备标识,识别异常设备。
-
行为模式分析:监控请求频率、操作路径(如突然大量转账触发预警)。
-
-
动态验证机制
-
二次认证:关键操作(如支付、修改密码)需重新输入密码或短信验证码。
-
短期 Token:为敏感操作生成一次性 Token(有效期 5 分钟),防止重放攻击。
-
-
Session 管理优化
-
分布式存储:使用 Redis 集群存储 Session,确保高可用性与一致性。
-
加密传输:强制 HTTPS 加密 SessionID,防止网络嗅探。
-
SameSite 属性:设置
SameSite=Strict,阻止跨站请求伪造(CSRF)。
-
四、安全相对性与防御成本
-
安全的经济学原则
-
成本-收益平衡:若破解成本远超收益(如破解银行系统需数十年计算资源),则视为“相对安全”。
-
动态对抗:安全措施需持续升级(如定期更换加密算法、修补漏洞)。
-
-
用户端防护责任
-
警惕钓鱼攻击:避免点击不明链接或下载未经验证的文件。
-
定期清理 Cookie:减少敏感信息长期暴露风险。
-
启用多因素认证(MFA):结合密码、短信、生物特征等多层验证。
-
五、SessionID 的实际应用案例
场景:银行网站登录与交易
-
登录阶段:用户输入账号密码,服务器验证后生成 SessionID 并存储至 Redis,返回
Set-Cookie: session_id=sess_abc123。 -
查询余额:浏览器自动携带 SessionID,服务器验证后返回余额数据。
-
转账操作:服务器检测到敏感操作,要求二次输入密码或短信验证码。
-
异常检测:若同一 SessionID 从新设备发起请求,触发风控系统冻结账户并短信通知用户。
六、未来安全趋势
-
无状态 Token(JWT)
-
将用户信息加密为 Token(如
Header.Payload.Signature),服务端无需存储 Session,通过签名验证合法性。 -
优势:适合微服务架构,减少服务端存储压力。
-
风险:Token 泄露后无法主动失效,需结合短期有效期与黑名单机制。
-
-
生物特征认证
-
逐步替代传统密码,如指纹、面部识别、声纹验证。
-
-
零信任架构(Zero Trust)
-
默认不信任任何设备或用户,每次访问需动态验证身份与权限。
-
总结
SessionID 通过隔离敏感信息与动态管理机制,显著提升了身份认证的安全性,但安全防护需多层防御与持续演进。开发者应结合加密传输、风控检测、用户教育等手段,构建纵深防御体系,而用户需提高安全意识,共同应对网络威胁。绝对安全虽不存在,但通过技术与策略的叠加,可将风险降至可接受范围。
HTTPS VS HTTP
一、HTTP 协议的安全隐患
-
明文传输的本质缺陷
-
数据暴露风险:HTTP 协议下,所有数据(包括账号密码、Cookie、交易信息)均以明文形式在网络中传输。
-
中间人攻击:攻击者可通过抓包工具(如 Wireshark)轻易截获并解析通信内容。
-
典型场景:
-
公共 Wi-Fi 中窃取用户登录凭证。
-
篡改网页内容插入恶意脚本(如广告劫持)。
-
-
-
历史背景
-
早期互联网应用(如论坛、电商网站)普遍使用 HTTP,导致大规模用户数据泄露事件频发。
-
例如:2013 年某社交平台因未加密用户会话,导致数百万用户隐私数据泄露。
-
二、HTTPS 的核心机制
-
加密层的引入
-
协议架构:HTTPS = HTTP + SSL/TLS,在应用层与传输层之间插入安全套接层(SSL/TLS)。
-
分层加密流程:
步骤 发送方(客户端) 接收方(服务器) 1 应用层生成明文数据(HTTP) 传输层接收加密数据(TCP) 2 加密层(SSL/TLS)加密数据 加密层(SSL/TLS)解密数据 3 传输层发送加密数据(TCP) 应用层处理明文数据(HTTP)
-
-
混合加密技术
-
非对称加密:用于密钥交换(如 RSA 算法),确保通信双方安全协商对称密钥。
-
对称加密:后续通信使用 AES 等高效算法加密数据。
-
完整性校验:通过 HMAC 算法防止数据篡改。
-
-
数字证书与 CA 信任链
-
证书作用:验证服务器身份,防止中间人伪造服务器。
-
CA 机构:由受信任的第三方(如 Let's Encrypt、DigiCert)签发证书,确保证书合法性。
-
证书内容:包含域名、公钥、签发机构、有效期等信息,并由 CA 私钥签名。
-
三、HTTPS 的工作流程(TLS 握手)
-
Client Hello:客户端发送支持的 TLS 版本、加密套件列表、随机数(Client Random)。
-
Server Hello:服务器选择 TLS 版本、加密套件,返回随机数(Server Random)和数字证书。
-
证书验证:客户端验证证书有效性(是否过期、域名匹配、CA 签名合法性)。
-
密钥交换:客户端生成预主密钥(Pre-Master Secret),用服务器公钥加密后发送。
-
生成会话密钥:双方基于 Client Random、Server Random、Pre-Master Secret 生成对称密钥。
-
加密通信:使用对称密钥加密后续 HTTP 数据,实现高效安全传输。
四、HTTPS 的核心优势
-
数据机密性:加密传输内容,防止敏感信息(如密码、银行卡号)被窃听。
-
数据完整性:通过哈希算法校验数据,确保传输过程中未被篡改。
-
身份认证:数字证书验证服务器身份,抵御钓鱼网站和中间人攻击。
五、HTTPS 的实践优化
-
性能优化
-
TLS 1.3 协议:减少握手延迟(1-RTT 甚至 0-RTT),提升速度。
-
会话复用:通过 Session ID 或 Session Ticket 复用已协商的密钥,减少重复握手开销。
-
-
安全增强
-
HSTS(HTTP Strict Transport Security):强制浏览器仅通过 HTTPS 访问,防止 SSL 剥离攻击。
-
OCSP Stapling:由服务器主动提供证书状态信息,避免客户端查询 CA 的延迟。
-
六、HTTPS 的行业影响
-
浏览器强制策略
-
主流浏览器(Chrome、Firefox)将 HTTP 网站标记为“不安全”,推动 HTTPS 普及。
-
截至 2023 年,全球超 90% 的网页加载使用 HTTPS(来源:W3Techs)。
-
-
法规合规要求
-
GDPR、PCI DSS 等法规要求敏感数据传输必须加密。
-
苹果 App Store 和 Google Play 强制要求 App 使用 HTTPS 连接。
-
-
未来趋势
-
全站 HTTPS:包括静态资源(图片、CSS/JS)的全面加密。
-
QUIC 协议:基于 UDP 的下一代传输协议,默认集成 TLS 1.3,进一步提升安全与速度。
-
总结
HTTPS 通过加密传输、身份认证、数据完整性保护三重机制,彻底解决了 HTTP 的明文传输缺陷,成为现代互联网安全的基石。尽管初期存在性能损耗担忧,但通过协议优化与硬件加速,HTTPS 已在性能与安全之间实现平衡。对于开发者而言,部署 HTTPS 不再是可选项,而是保障用户信任、满足合规要求的必由之路。