大模型重点5【Agent构建】
重点:
带多个tools和返回数据校验的调用逻辑:
from pydantic import BaseModel, Field
from typing import List, Optional
import openai
import json
# ======================
# 天气查询工具定义
# ======================
class WeatherData(BaseModel):
location: str = Field(..., description="城市名称")
temperature: float = Field(..., description="温度数值")
unit: str = Field(default="celsius", description="温度单位")
weather_condition: str = Field(..., description="天气状况描述")
def get_current_weather(location: str, unit: str = "celsius") -> WeatherData:
"""获取指定地点的当前天气"""
return WeatherData(
location=location,
temperature=25.5,
unit=unit,
weather_condition="晴"
)
# ======================
# 股票查询工具定义
# ======================
class StockData(BaseModel):
symbol: str = Field(..., description="股票代码")
price: float = Field(..., description="当前价格")
unit: str = Field(default="USD", description="货币单位")
timestamp: str = Field(..., description="报价时间")
def get_stock_price(symbol: str) -> StockData:
"""获取指定股票的当前价格"""
return StockData(
symbol=symbol,
price=150.0,
unit="USD",
timestamp="2023-10-05 15:00:00"
)
# ======================
# 工具列表配置
# ======================
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取指定城市的当前天气信息",
"parameters": WeatherData.schema()
}
},
{
"type": "function",
"function": {
"name": "get_stock_price",
"description": "获取指定股票的实时价格",
"parameters": StockData.schema()
}
}
]
# ======================
# 调用处理逻辑
# ======================
openai.api_key = "your_api_key"
def process_user_query(query: str):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=[{"role": "user", "content": query}],
tools=tools
)
message = response.choices[0].message
if message.get("function_call"):
function_name = message["function_call"]["name"]
arguments = json.loads(message["function_call"]["arguments"])
# 创建函数映射表
function_map = {
"get_current_weather": get_current_weather,
"get_stock_price": get_stock_price
}
if function_name in function_map:
result = function_map[function_name](**arguments)
print("函数调用结果:")
print(result.dict())
# 这里可以继续将结果返回给GPT生成最终回复
# 例如添加系统消息包含函数结果
else:
print(f"未知函数调用:{function_name}")
else:
print(message["content"])
# 测试不同查询
process_user_query("北京今天气温多少?")
process_user_query("AAPL的当前股价是多少?")
一 简单构建Agent
1.1 Functional Call of OpenAI
之前我们讲解过pydantic object, 就是用来自定义LLM返回的格式,包括自定义的字段以及types. 然而,openAI自己也实现了这套逻辑,也叫做functional call, 就是返回用户自定义的Json的structure。
Functional Call of OpenAI 是 OpenAI 提供的一种功能,允许用户定义特定的函数,模型可以根据输入的内容决定是否调用这些函数,并以 JSON 格式返回函数调用的参数。以下是对其的详细理解:
工作原理:
-
定义函数:用户在请求中定义一个或多个函数,每个函数都有名称、描述以及参数的 JSON Schema。
-
模型判断:模型根据输入内容和上下文,判断是否需要调用某个函数。
-
返回函数调用:如果模型决定调用函数,它会返回一个包含函数名称和参数的 JSON 格式响应。
-
执行函数:用户根据模型返回的函数调用信息,实际执行相应的函数,并将结果反馈给模型。
-
生成最终回复:模型根据函数执行的结果,生成最终的回复给用户。
定义函数:
在请求中,通过 tools 参数定义函数,每个函数的定义包括:
-
type:固定为 "function"。 -
function:包含函数的具体定义,包括:-
name:函数名称。 -
description:函数的描述,帮助模型理解函数的用途。 -
parameters:函数参数的 JSON Schema,定义了参数的类型、是否必填等信息。
-
示例代码:
import openai
import json
# 定义函数
def get_current_weather(location, unit="celsius"):
# 这里可以添加实际的天气查询逻辑
return f"当前 {location} 的天气是 25 度"
# 定义函数调用的工具
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取指定地点的当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,例如:San Francisco"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
}
]
# 设置 OpenAI API 密钥
openai.api_key = "your_api_key"
# 调用 OpenAI API
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=[
{"role": "user", "content": "北京今天的天气怎么样?"}
],
tools=tools
)
# 处理模型返回的响应
if response.choices[0].finish_reason == "function_call":
# 如果模型决定调用函数,解析函数调用信息
function_call = json.loads(response.choices[0].message.function_call.arguments)
function_name = response.choices[0].message.function_call.name
# 执行相应的函数
if function_name == "get_current_weather":
result = get_current_weather(**function_call)
print(result)
else:
# 如果模型没有调用函数,直接输出回复
print(response.choices[0].message.content)1.2 结合Pydantic Object 使用
Pydantic 是一个 Python 库,用于数据验证和设置管理。它允许你定义数据模型(schemas),这些模型可以用于验证和解析数据,确保数据符合预期的结构和类型。在与大型语言模型(LLM)交互时,Pydantic Object 可以用来定义 LLM 返回的格式,确保输出符合特定的数据结构。
核心概念:
-
数据模型(Schemas):通过定义 Pydantic 模型,你可以指定数据的结构,包括字段名称、类型、默认值和验证规则。
-
数据验证:Pydantic 会自动验证传入的数据是否符合模型定义的结构和类型,如果不符,会抛出详
在 Pydantic 中,schema() 是一个方法,用于生成模型的 JSON Schema 表示。JSON Schema 是一种基于 JSON 的格式,用于描述 JSON 数据的结构和约束。通过 schema() 方法,可以将 Pydantic 模型转换为 JSON Schema,这在与外部系统(如 OpenAI 的 Functional Call)交互时非常有用,因为它可以清晰地定义数据的格式和验证规则。
from pydantic import BaseModel, Field
from typing import List, Optional
# 定义一个 Pydantic 模型
class WeatherData(BaseModel):
location: str
temperature: float
unit: str = Field(default="celsius", description="温度单位")
weather_condition: str
# 定义一个函数
def get_current_weather(location: str, unit: str = "celsius") -> WeatherData:
# 这里可以添加实际的天气查询逻辑
return {
"location": location,
"temperature": 25.5,
"unit": unit,
"weather_condition": "晴"
}
# 在 OpenAI Functional Call 中使用
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取指定地点的当前天气",
"parameters": WeatherData.schema()
}
}
]
# 设置 OpenAI API 密钥
openai.api_key = "your_api_key"
# 调用 OpenAI API
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=[
{"role": "user", "content": "北京今天的天气怎么样?"}
],
tools=tools
)
# 处理模型返回的响应
if response.choices[0].finish_reason == "function_call":
# 如果模型决定调用函数,解析函数调用信息
function_call = json.loads(response.choices[0].message.function_call.arguments)
function_name = response.choices[0].message.function_call.name
# 执行相应的函数
if function_name == "get_current_weather":
result = get_current_weather(**function_call)
print(result)
else:
# 如果模型没有调用函数,直接输出回复
print(response.choices[0].message.content)1.3 langchain 格式化返回结果
deepseek调用方式:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(
openai_api_base="https://api.deepseek.com/v1",
openai_api_key="your_deepseek_api_key",
model="deepseek-coder-16b",
temperature=0
)主代码:
# 导入openai api key
import os
from dotenv import load_dotenv, find_dotenv
# .env 存储api_key
load_dotenv()
from langchain_community.utils.openai_functions import (
convert_pydantic_to_openai_function,
)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model = "gpt-4", temperature=0)
from langchain_core.utils.function_calling import convert_to_openai_function
class Discovery(BaseModel):
"""著名的科学家的发现"""
name: str = Field(description="科学家名字")
discovery: str = Field(description="科学家的成就")
# 转换成openai_funtions, 其实就是json_schema
openai_functions = [convert_to_openai_function(Discovery)]
prompt = ChatPromptTemplate.from_messages(
[("system", "你是一个助手"), ("user", "{input}")]
)
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
parser = JsonOutputFunctionsParser()
chain = prompt | llm.bind(functions=openai_functions) | parser
chain.invoke({"input": "讲一个著名科学家的事迹"})
# {'name': '阿尔伯特·爱因斯坦', 'discovery': '相对论'}二 Agent
2.1 什么是Agent?
-
解决比较复杂的问题, 如果我们的问题是一问一答,实际上不太需要Agent。
-
复杂的问题拆解成若干个简单的问题; 把每个简单的问题解决,之后整合成答案。 (planning)
-
会用到若干个工具(外部)。大模型训练的时候用到的数据是过时的,比如GPT-4数据应该是到23年4月份;网上的,实时的数据,如何获取?
-
具体用什么工具来解决什么问题?(planning)
2.2 Agent的例子
任务: ”生成一个短视频,讲述大模型在金融领域的应用,特别是24年落地的应用场景,生成出来的短视频脚本不能喂饭抖音的规定,不能出现特定的关键词
任务拆解(planning):
-
由大模型来做任务拆解。
-
通过Bing API去搜索网页,“大模型+金融领域应用+24年落地+应用场景” (reasoning),搜索完之后,获取相应的内容Text(Action:search_for_bing (参数如上), observation: 内容Text
-
基于Text,总结成300字以内的精华内容。 交给GPT去做总结 (Action: summarzation_by_GPT, Observation: summaried text),4-5步是loop, 直到满足抖音的条件
-
对于生成的精华内容做进一步验证,判断是否违反了抖音的规则。 (Action: varified_by_douyin_api, Observation: 是/否)
-
假如第4步,返回的是“是”,重新生成,返回第四步骤;
-
把脚本分成10个镜头(Action: segment_script_by_GPT, Observation: 分镜之后的文本)
-
每个分镜通过调用Stable Diffusion生成图片(Action: call_sd, Parameters: 文本,sytle.. Observation: list of 图片)
-
图片合成视频(Action: generate_video_by_xxx_tool, output: video)
角色: Agent (LLM)
Tools: 工具 (提前准备好的),只要知道工具的url, 输入参数,会返回相应的结果
任务:生成面向开发工程师的大模型课程:
- 生成大纲,10章的内容,每个章节不少于5个小节
- 针对于每个小节,生成具体的内容,选择题 ......
- xxxxxxxxx
2.3 Agent和Chain之间的区别?
在自然语言处理与自动化任务处理中,Agent(智能体)和Chain(链式流程)是两种常见的任务执行模式,它们的核心区别体现在动态决策能力与静态流程预设上。以下从技术实现、应用场景和底层逻辑三个维度进行深度解析,同样点:都是一步一步完成一系列任务,从而最终完成复杂的任务。 不同点:
-
Chain是提前定义好的,也就是第一步要做什么,第二步要做什么,第三步骤要什么。适用于提前知道每一步具体要做什么事情。 静态的。
-
假如给Agent提供5个工具, 针对于不同的用户问题,任务的顺序是可能不一样的。 动态的。
| 维度 | Chain | Agent |
|---|---|---|
| 流程控制 | 硬编码的线性流程(if-else或DAG图) | 动态决策(基于LLM的推理或策略网络) |
| 工具调用 | 固定顺序调用预定义工具 | 根据上下文实时选择工具 |
| 状态管理 | 有限状态机(明确的状态转移规则) | 基于记忆的上下文感知(如VectorDB) |
| 错误处理 | 预设异常处理分支 | 自主尝试替代路径(如ReAct模式) |
示例对比:
处理电商退货请求时:
-
Chain:
订单验证 → 物流查询 → 退款计算 → 执行退款(严格顺序) -
Agent:可能先调用
情感分析工具判断用户情绪,再动态选择快速退款通道或人工客服介入
2.4 典型的 Agent
这是典型的 Agent(智能体) 实现,核心特征包括:
-
动态工具选择(即使只有一个工具)
-
基于ReAct模式的多轮推理
-
自主决策的思考链生成
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent, load_tools
from langchain.agents.agent_types import AgentType
tools = load_tools(
["llm-math"], llm
)
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke(
{
"input": "What is 134292 times 282393?",
}
)
> Entering new AgentExecutor chain...
I need to multiply these two numbers together.
Action: Calculator
Action Input: 134292 * 282393Answer: 37923120756I now know the final answer.
Final Answer: 37923120756
> Finished chain.
{'input': 'What is 134292 times 282393?', 'output': '37923120756'}
2.5 Python Agent tools
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent, create_openai_functions_agent,load_tools
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0.0)
tools = load_tools(
["arxiv","wikipedia"],
)
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke(
{
"input": "What's the paper 1605.08386 about?",
}
)> Entering new AgentExecutor chain... I should use the arxiv tool to search for the paper with the identifier 1605.08386. Action: arxiv Action Input: 1605.08386Published: 2016-05-26 Title: Heat-bath random walks with Markov bases Authors: Caprice Stanley, Tobias Windisch Summary: Graphs on lattice points are studied whose edges come from a finite set of allowed moves of arbitrary length. We show that the diameter of these graphs on fibers of a fixed integer matrix can be bounded from above by a constant. We then study the mixing behaviour of heat-bath random walks on these graphs. We also state explicit conditions on the set of moves so that the heat-bath random walk, a generalization of the Glauber dynamics, is an expander in fixed dimension.I now know the paper 1605.08386 is about heat-bath random walks with Markov bases. Final Answer: The paper 1605.08386 is about heat-bath random walks with Markov bases. > Finished chain.
2.6 custom tools
from langchain.tools import BaseTool, StructuredTool, tool
@tool
def coolest_guy(text: str) -> str:
'''Returns the name of the coolest guy in the universe'''
return "Mike"
tools = tools + [coolest_guy]
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke(
{
"input": "Who is the coolest guy in the universe?",
}
)> Entering new AgentExecutor chain... I should use the coolest_guy tool to find out who the coolest guy is. Action: coolest_guy Action Input: MikeI should provide the final answer now. Final Answer: Mike > Finished chain.
@tool
def some_api_call(text: str) -> str:
'''可以定义自己的API Call!'''
return api_result
from datetime import datetime
@tool
def get_time(text: str) -> str:
'''Returns the current time. Use this for any questions
regarding the current time. Input is an empty string and
the current time is returned in a string format. Only use this function
for the current time. Other time related questions should use another tool'''
return str(datetime.now())
tools = tools + [get_time]
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke(
{
#"input": "How many years has been past since Einstein died?",
"input": "How many months past since when the paper titled REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS been published?"
}
)
agent_executor.invoke(
{
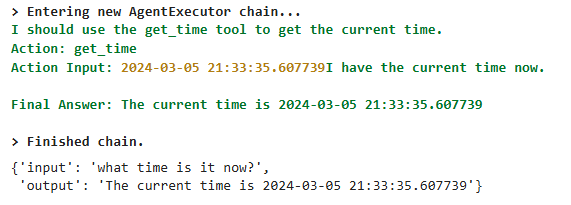
"input": "what time is it now?",
}
)
2.7 常见的Agent

三 ReAct from scratch(从头开始ReAct)
ReAct 模式核心原理
ReAct = Reasoning(推理) + Acting(行动)
通过交替进行 思考生成 和 工具调用 解决复杂问题,其本质是构建一个 自动化的思维链(Chain-of-Thought)系统。
import openai
import re
import httpx
class ChatBot:
def __init__(self, system=""):
self.system = system
self.messages = []
if self.system:
self.messages.append({"role": "system", "content": system})
def __call__(self, message):
self.messages.append({"role": "user", "content": message})
result = self.execute()
self.messages.append({"role": "assistant", "content": result})
return result
def execute(self):
completion = llm.invoke(self.messages)
return completion.content
prompt = """
You run in a loop of Thought, Action, PAUSE, Observation.
At the end of the loop you output an Answer
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you - then return PAUSE.
Observation will be the result of running those actions.
Your available actions are:
calculate:
e.g. calculate: 4 * 7 / 3
Runs a calculation and returns the number - uses Python so be sure to use floating point syntax if necessary
wikipedia:
e.g. wikipedia: Django
Returns a summary from searching Wikipedia
simon_blog_search:
e.g. simon_blog_search: Django
Search Simon's blog for that term
Always look things up on Wikipedia if you have the opportunity to do so.
Example session:
Question: What is the capital of France?
Thought: I should look up France on Wikipedia
Action: wikipedia: France
PAUSE
You will be called again with this:
Observation: France is a country. The capital is Paris.
You then output:
Answer: The capital of France is Paris
""".strip()
action_re = re.compile('^Action: (\w+): (.*)$')
def query(question, max_turns=5):
i = 0
bot = ChatBot(prompt)
next_prompt = question
while i < max_turns:
i += 1
result = bot(next_prompt)
print(result)
print (bot.messages)
actions = [action_re.match(a) for a in result.split('\n') if action_re.match(a)]
if actions:
# There is an action to run
action, action_input = actions[0].groups()
if action not in known_actions:
raise Exception("Unknown action: {}: {}".format(action, action_input))
print(" -- running {} {}".format(action, action_input))
observation = known_actions[action](action_input)
print("Observation:", observation)
next_prompt = "Observation: {}".format(observation)
else:
return
def wikipedia(q):
return httpx.get("https://en.wikipedia.org/w/api.php", params={
"action": "query",
"list": "search",
"srsearch": q,
"format": "json"
}).json()["query"]["search"][0]["snippet"]
def simon_blog_search(q):
results = httpx.get("https://datasette.simonwillison.net/simonwillisonblog.json", params={
"sql": """
select
blog_entry.title || ': ' || substr(html_strip_tags(blog_entry.body), 0, 1000) as text,
blog_entry.created
from
blog_entry join blog_entry_fts on blog_entry.rowid = blog_entry_fts.rowid
where
blog_entry_fts match escape_fts(:q)
order by
blog_entry_fts.rank
limit
1""".strip(),
"_shape": "array",
"q": q,
}).json()
return results[0]["text"]
def calculate(what):
return eval(what)
known_actions = {
"wikipedia": wikipedia,
"calculate": calculate,
"simon_blog_search": simon_blog_search
}
#query("Has Simon been to Madagascar?")
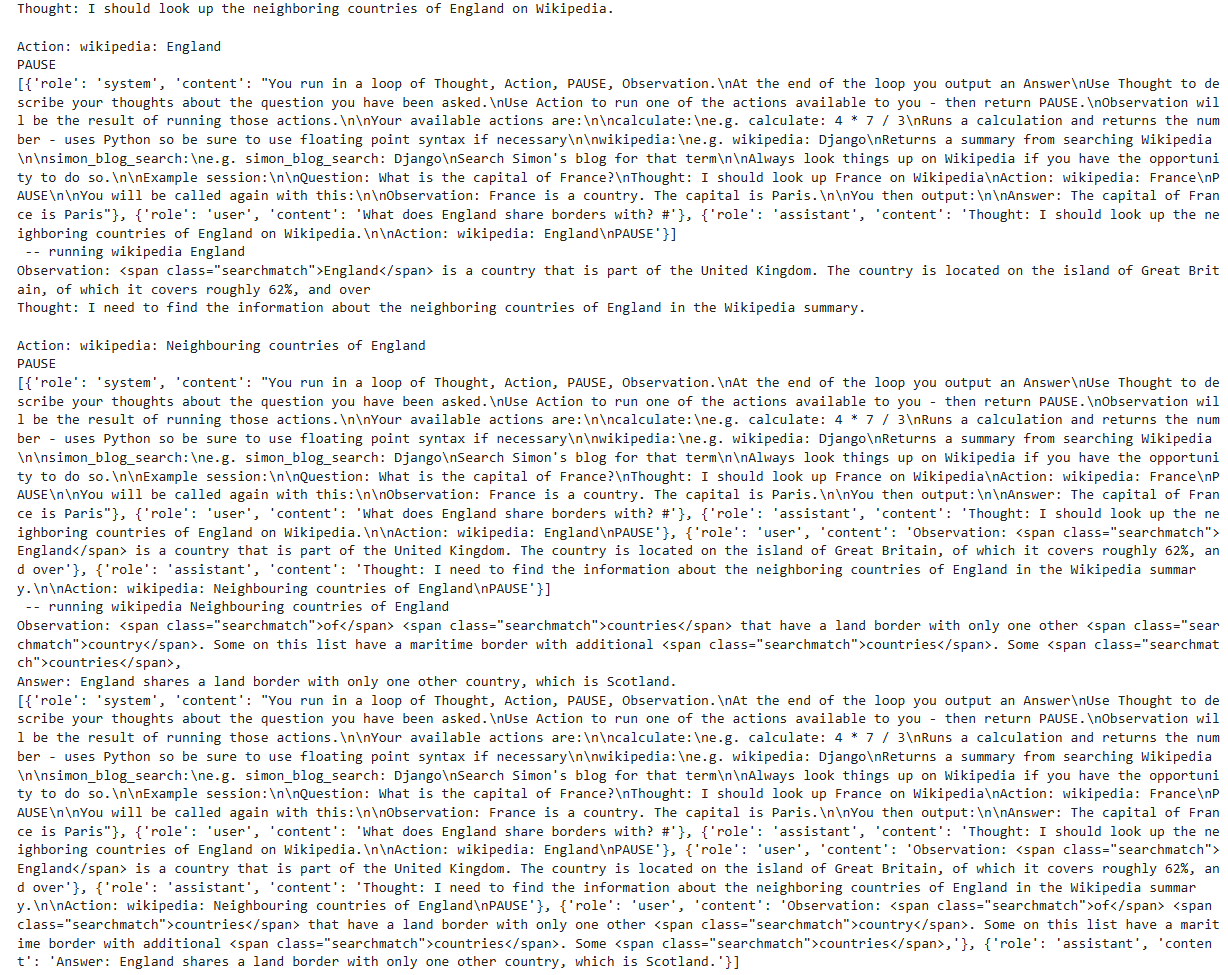
query("What does England share borders with? #")