Llama3大模型本地部署与调用
Llama3大模型本地部署与调用
1. 硬件配置分析
- 在本地对8B版本的Llama3进行部署测试,最低硬件配置为:
- CPU:Intel Core i7 或 AMD 等价(至少4个核心)
- GPU:NVIDIA GeForce GTX 1060 或 AMD Radeon RX 580(至少6 GB VRAM)
- 内存:至少16 GB的RAM
- 操作系统:Ubuntu 20.04 或更高版本,或者 Windows 10 或更高版本
- 部署环境对各个包的版本有严格要求,需要注意。
- 特别注意的包版本:
- transformers:版本需大于4.39.0(例如4.40.1)
- pytorch和cuda:torch 2.1.0 + cu118(因为transformers对cuda版本有要求)
2. Llama3模型介绍
- Llama3是Meta于2024年4月18日开源的LLM(大型语言模型)。
- 开放的版本:8B和70B,支持最大为8192个token的序列长度(GPT-4支持128K)。
- 预训练环境:Meta自制的两个24K GPU集群,使用15T的训练数据,其中5%为非英文数据。
- 中文能力稍弱,Meta认为Llama3是目前最强的开源大模型。
3. Model Scope在线平台部署Llama3
- 启动环境
- 登录魔搭社区,选择机器资源,配置为:8核32G内存,24G显存;预装ModelScope预装镜像为ubuntu22.04-cuda12.1.0-py310-torch2.1.2-tf2.14.0-1.13.3。
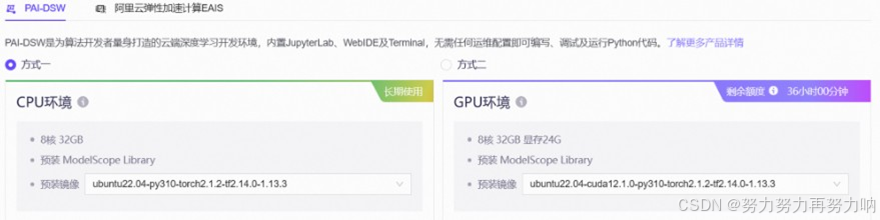
点击启动
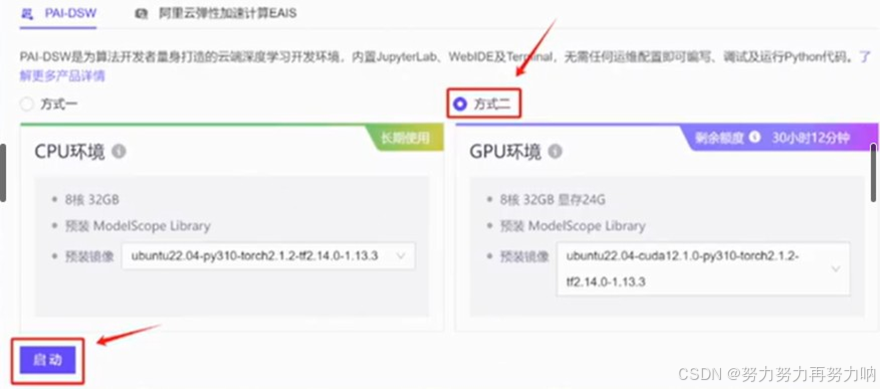
- 登录魔搭社区,选择机器资源,配置为:8核32G内存,24G显存;预装ModelScope预装镜像为ubuntu22.04-cuda12.1.0-py310-torch2.1.2-tf2.14.0-1.13.3。
启动后点击进入terminal,检查机器配置。
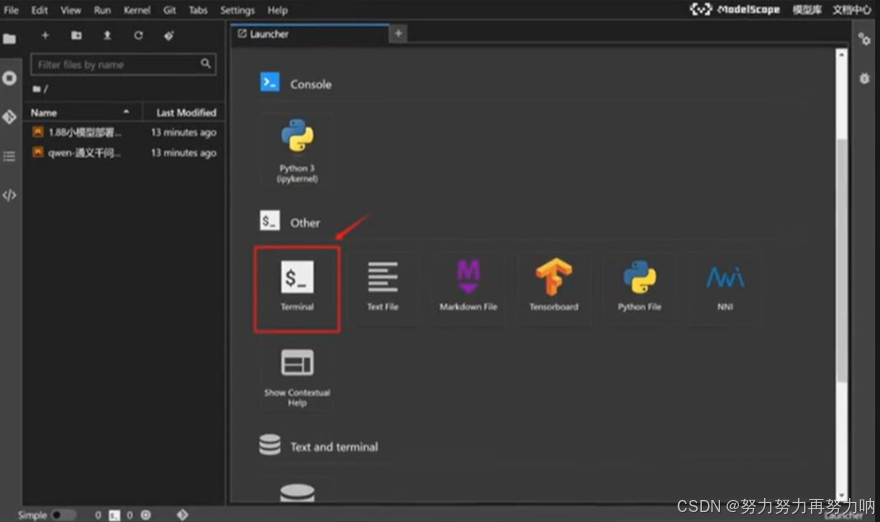
进入命令行界面
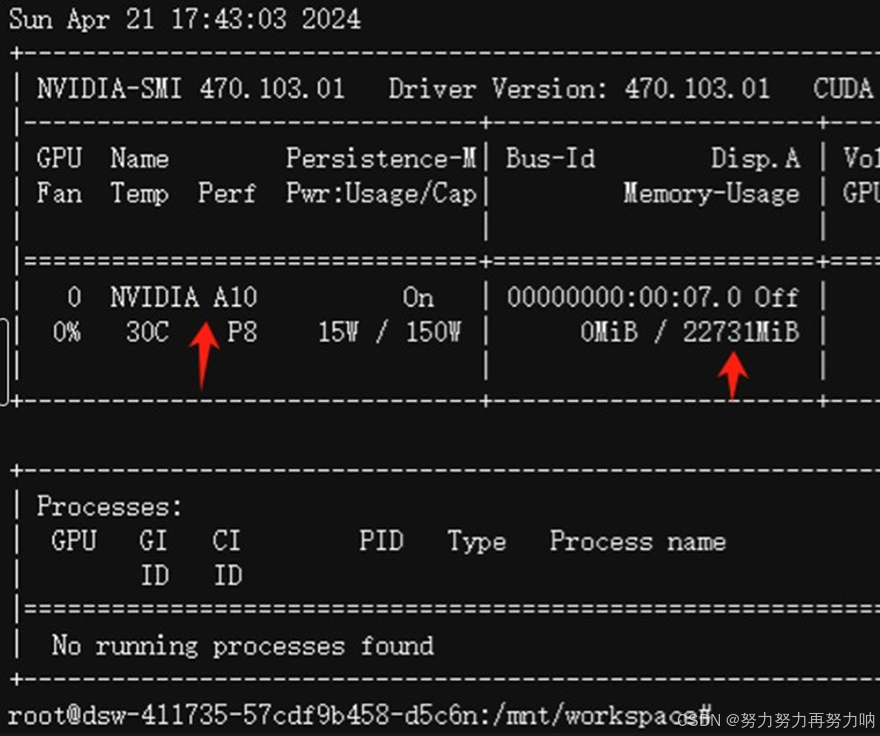
输入invdia-smi, 可以看到自己显卡的信息
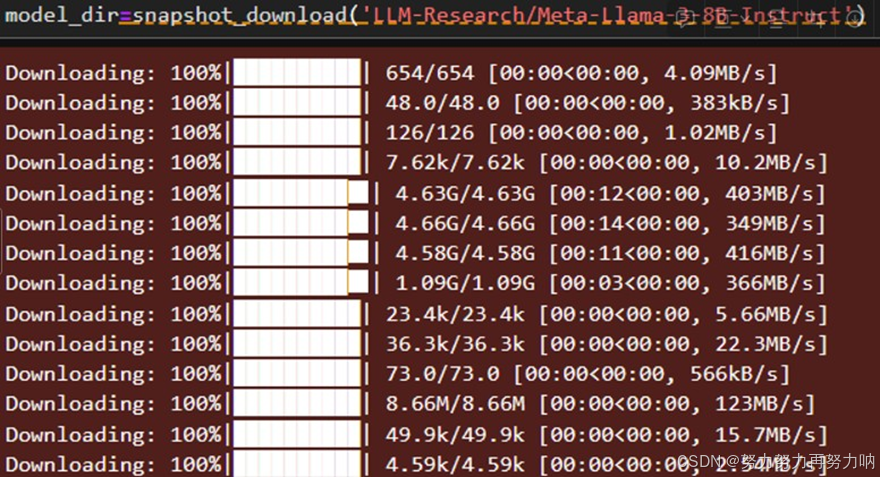
2、 模型下载
使用modelscope进行模型下载:
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct', cache_dir=("/mnt/workspace/Llama3-8B"))
print(model_dir)
下载速度非常快,因为是从modelscope的托管平台下载到modelscope的云平台。
3、运行本地大模型
1、使用transformers运行本地大模型:
1.1加载模型
device = "cuda"
model = AutoModelForCausalLM.from_pretrained(model_dir, torch_dtype='auto', device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_dir)
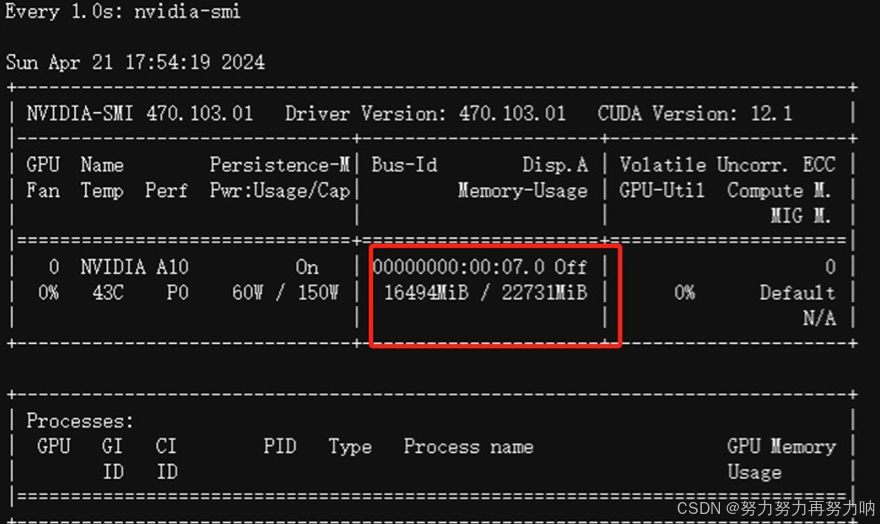
1.2检查GPU使用情况(加载完成后占用约17G显存)。
1.3使用transformers调用大模型
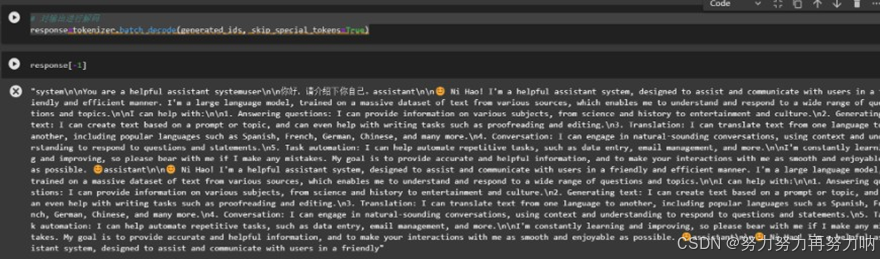
prompt = "你好,请详细介绍下你自己。"
messages = [{'role':'system','content':'You are a helpful assistant system'}, {'role': 'user','content': prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to('cuda')
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
1.4、成功返回