MySQL进阶
一、存储引擎
-- 建表时指定存储引擎
CREATE TABLE 表名(
...
) ENGINE=INNODB;
-- 查看当前数据库支持的存储引擎
SHOW ENGINES;InnoDB
InnoDB 是一种兼顾高可靠性和高性能的通用存储引擎,在 MySQL 5.5 之后,InnoDB 是默认的 MySQL 引擎。
特点:
DML 操作遵循 ACID 模型,支持事务
行级锁,提高并发访问性能
支持外键约束,保证数据的完整性和正确性
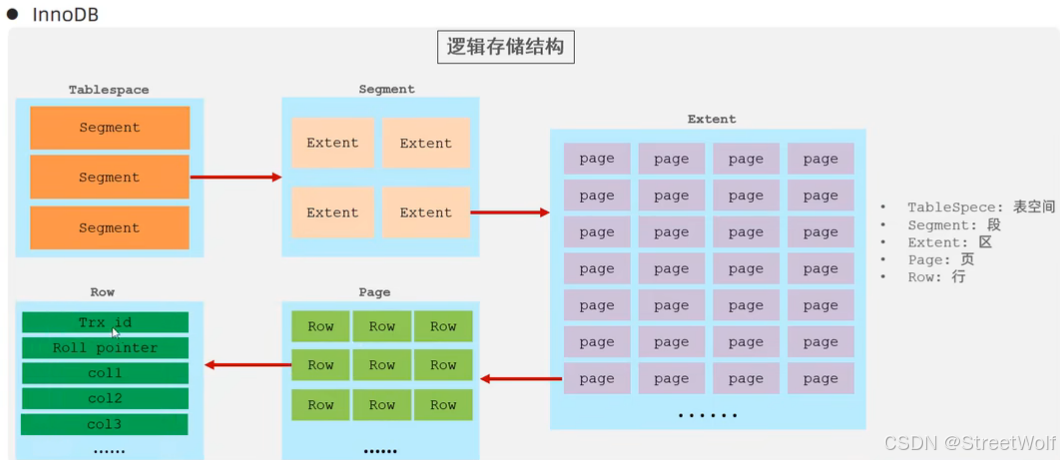
xxxx.idb:一个InnoDB表名为xxxx,InnoDB 引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm、sdi)、数据和索引。
参数:innodb_file_per_table,决定多张表共享一个表空间还是每张表对应一个表空间
从idb文件提取表结构数据:
(在cmd运行)
ibd2sdi xxx.ibd上面的代码在idb文件中提取sdi表结构数据。
MyISAM
MySQL早期的默认存储引擎
特点:
不支持事务,不支持外键
支持表锁,不支持行锁
访问速度快
xxx.sdi: 存储表结构信息
xxx.MYD: 存储数据
xxx.MYI: 存储索引
Memory
Memory 引擎的表数据是存储在内存中的,受硬件问题、断电问题的影响,只能将这些表作为临时表或缓存使用。
特点:
存放在内存中,速度快
hash索引(默认)
xxx.sdi: 存储表结构信息
对比
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全☆ | 支持 | 不支持 | 不支持 |
| 锁机制☆ | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| 全文索引 | 支持(5.6版本之后) | 支持 | 不支持 |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键☆ | 支持 | 不支持 | 不支持 |
选择
- InnoDB: 如果应用对事物的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,则 InnoDB 是比较合适的选择
- MyISAM: 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不高,那这个存储引擎是非常合适的。
- Memory: 将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。Memory 的缺陷是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性
电商中的足迹和评论适合使用 MyISAM 引擎,缓存适合使用 Memory 引擎。
应用
InnoDB:存储业务系统中对于事务、数据完整性要求较高的核心数据。
MyISAM:存储业务系统的非核心事务。
二、索引
概述
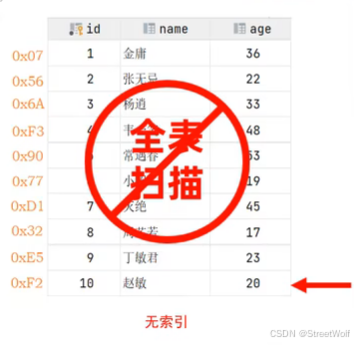
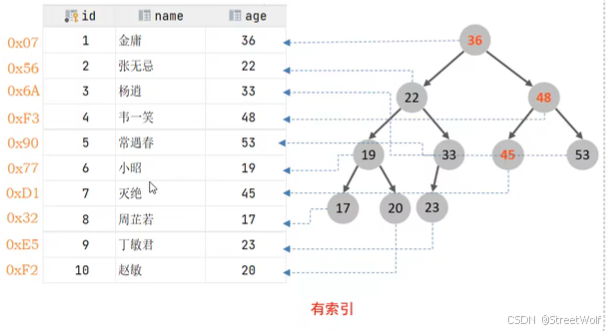
索引是帮助MySQL高效获取数据的有序数据结构。
查找age为45
优点
提高数据检索效率,降低数据库的IO成本
通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
缺点
索引列也是要占用空间的
索引大大提高了查询效率,但降低了更新的速度,比如 INSERT、UPDATE、DELETE
结构
| 索引结构 | 描述 |
|---|---|
| B+Tree | 最常见的索引类型,大部分引擎都支持B+树索引 |
| Hash | 底层数据结构是用哈希表实现,只有精确匹配索引列的查询才有效,不支持范围查询 |
| R-Tree(空间索引) | 空间索引是 MyISAM 引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-Text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式,类似于 Lucene, Solr, ES |
不同索引在存储引擎中的支持情况
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| R-Tree索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本后支持 | 支持 | 不支持 |
基础——二叉树
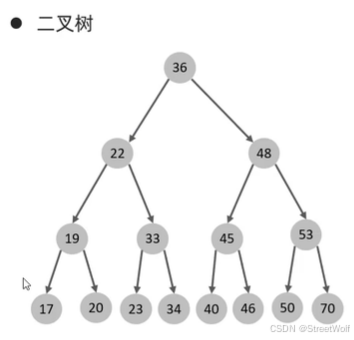
二叉树缺点:
1.顺序插入时,会形成一个链表,查询性能大大降低。
2.大数据量情况下,层级较深,检索速度慢。
对于缺点1:使用红黑树。红黑树是一种自平衡的二叉树
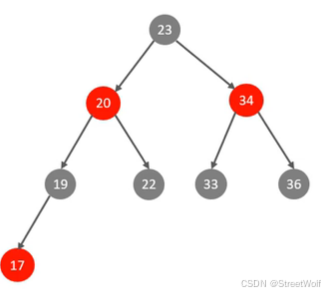
对于缺点2:使用B-Tree。
基础——B-Tree
又称为多路平衡查找树,以一颗最大度数(树的度数是一个节点的子节点个数)为5的B-Tree为例,每个节点最多存储4个KEY,5个指针:
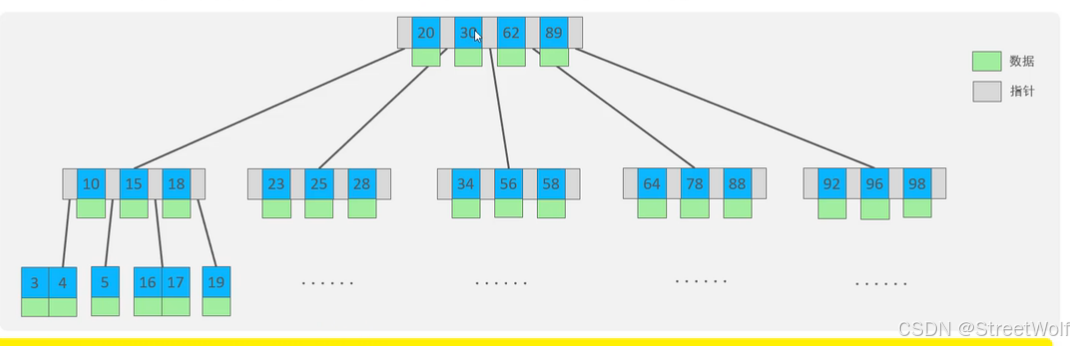
可以访问数据结构可视化网站:B-Tree Visualization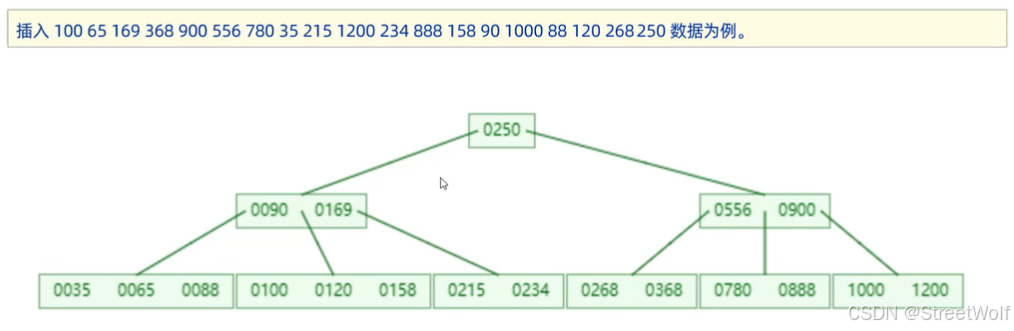
B+Tree☆
所有的元素都会出现在叶子节点,且叶子节点会形成一个单向链表。

可以访问数据结构可视化网站:B+ Tree Visualization
MySQL在原B+Tree的基础上增加了一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高了区间访问的性能。
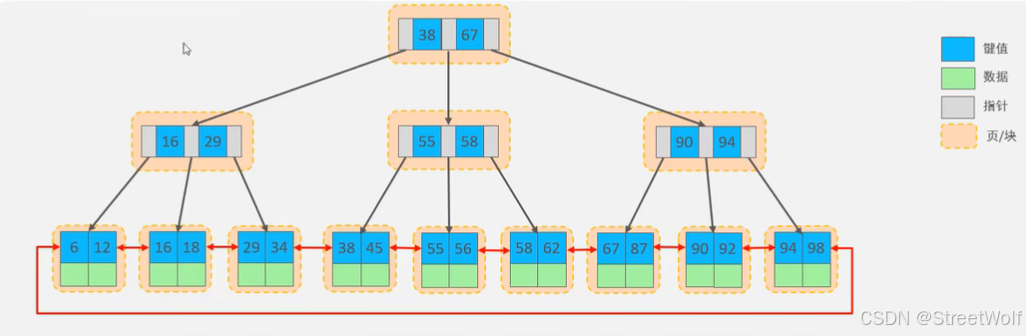
Hash☆
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
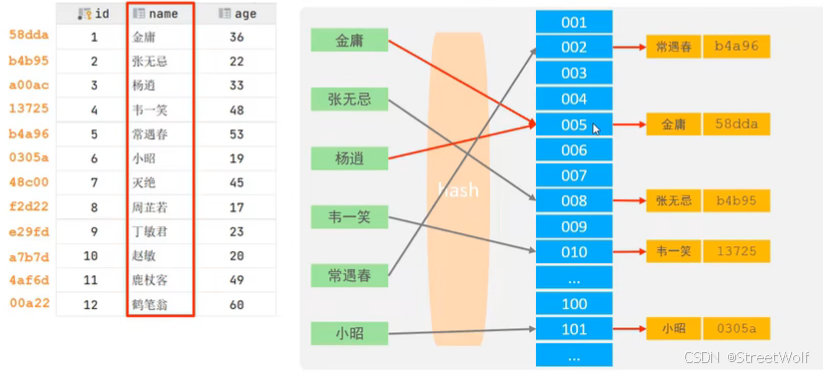
hash索引特点
Hash索引只能用于对等比较(=、in),不支持范围查询(betwwn、>、<、…)
无法利用索引完成排序操作
查询效率高,通常只需要一次检索就可以了,效率通常要高于 B+Tree 索引
如果出现哈希碰撞,则不止需要一次检索,还需要去链表中进行对比查找。
支持hash的存储引擎
Memory。InnoDB可以自适应。
为什么InnoDB存储引擎选择使用B+Tree索引结构
相对于二叉树,层级更少,搜索效率高。
为什么没有采用B树
思考过程:B+树中只有叶子节点存放数据,上面的节点仅仅存放索引。B树的叶子节点和非叶子节点都存放数据。查找数据时必须到B+树中的叶子节点才能找到数据。B+树中的叶子节点形成了双向链表。
对于 B-Tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针也跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低。
为什么没有采用Hash索引
对于hash索引,B+tree支持范围匹配和排序操作。
分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
在InnoDB存储引擎中,根据索引的存储形式,可以分为
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 (Clustered Index) | 将数据存储与索引放一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
二级索引也称为辅助索引、非聚集索引。顾名思义,二级索引指向的也是索引。
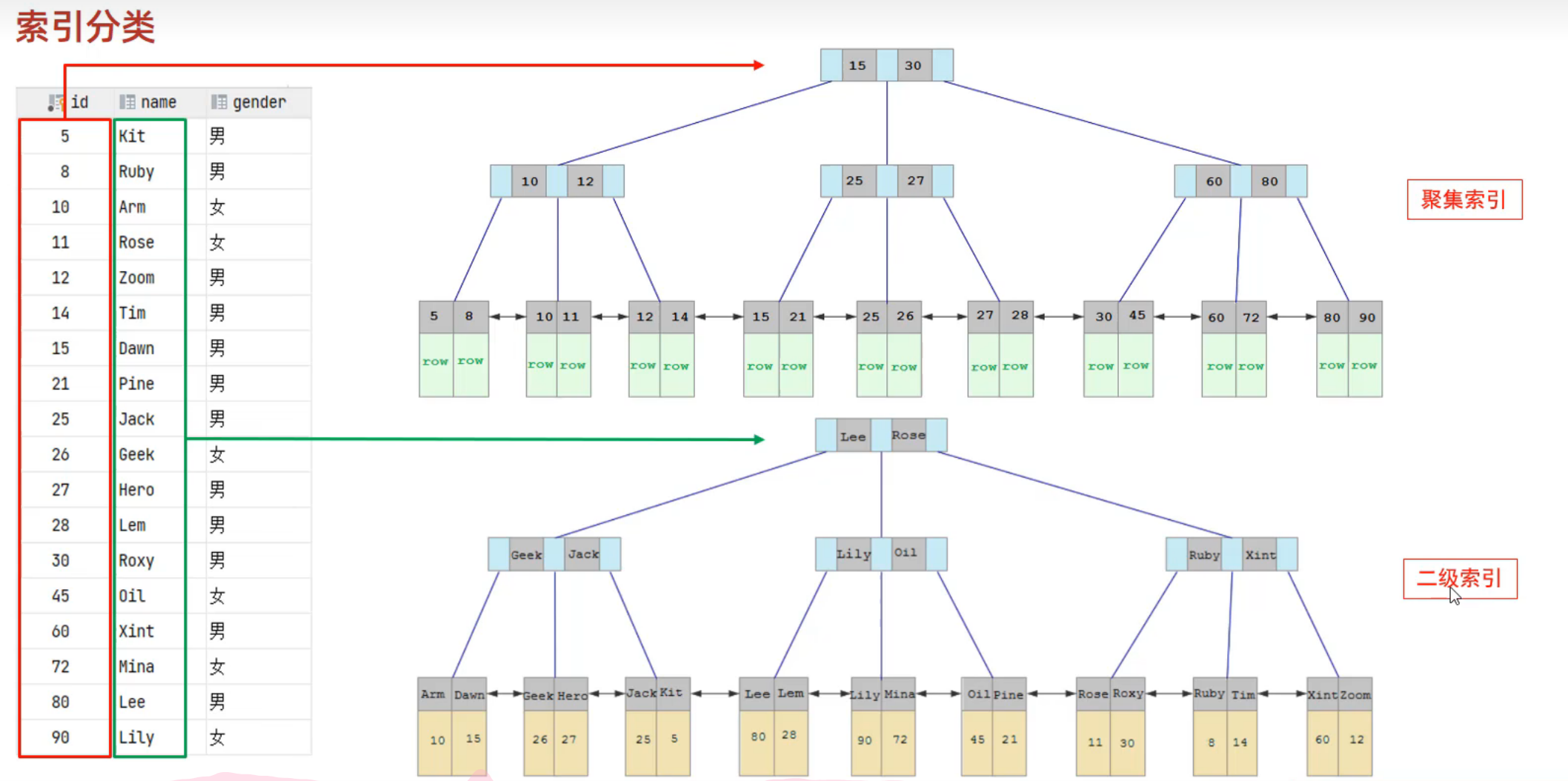
思考

第一条的执行效率高,因为第一条直接走聚集索引,查到数据。第二条要先走二级索引查到id值,再走聚集索引,查到数据,相当于多走了一遍二级索引。(二级索引走完再回表查询)
小提示:根据操作系统的内容,内存和外存都分为一页一页的,存取一次为一页。存取次数少就性能高,所以尽量不要把索引和行数据放在一起。
——————————
待更新2025.3.26