如何在自己的数据集上跑通DEIM(CVPR2025)
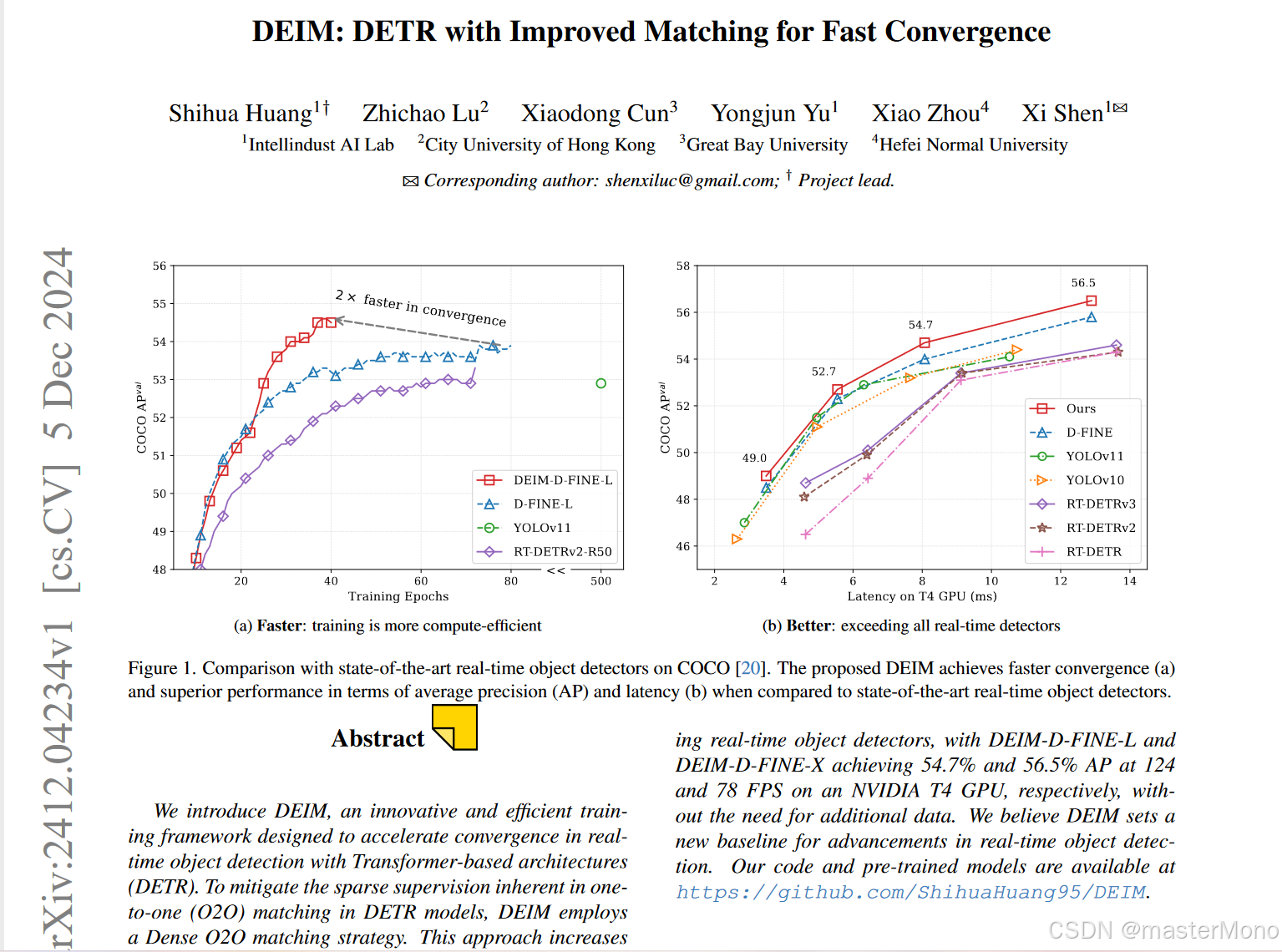
DEIM: DETR with Improved Matching for Fast Convergence提出了一种名为DEIM(DETR with Improved Matching)的创新训练框架,旨在加速基于Transformer的实时目标检测架构的收敛速度。目前该训练框架可用于直接训练RTDETR和DFine。
代码:DEIM下载链接
论文:DEIM论文链接
1 环境配置
不过多赘述,安装训练深度学习所需的各种依赖工具。
DEIM所需的特殊库可在requirements文件中找到。
2 数据集准备
DEIM训练所需的数据集格式为ms coco格式,若你的数据集为voc或yolo格式的,则需要转换。
转换代码:深度学习数据集格式转换代码_python使用cuda深度学习转码-CSDN博客
3 代码调试
代码下载完成后,为训练自定义数据集,需要对几个文件进行修改。
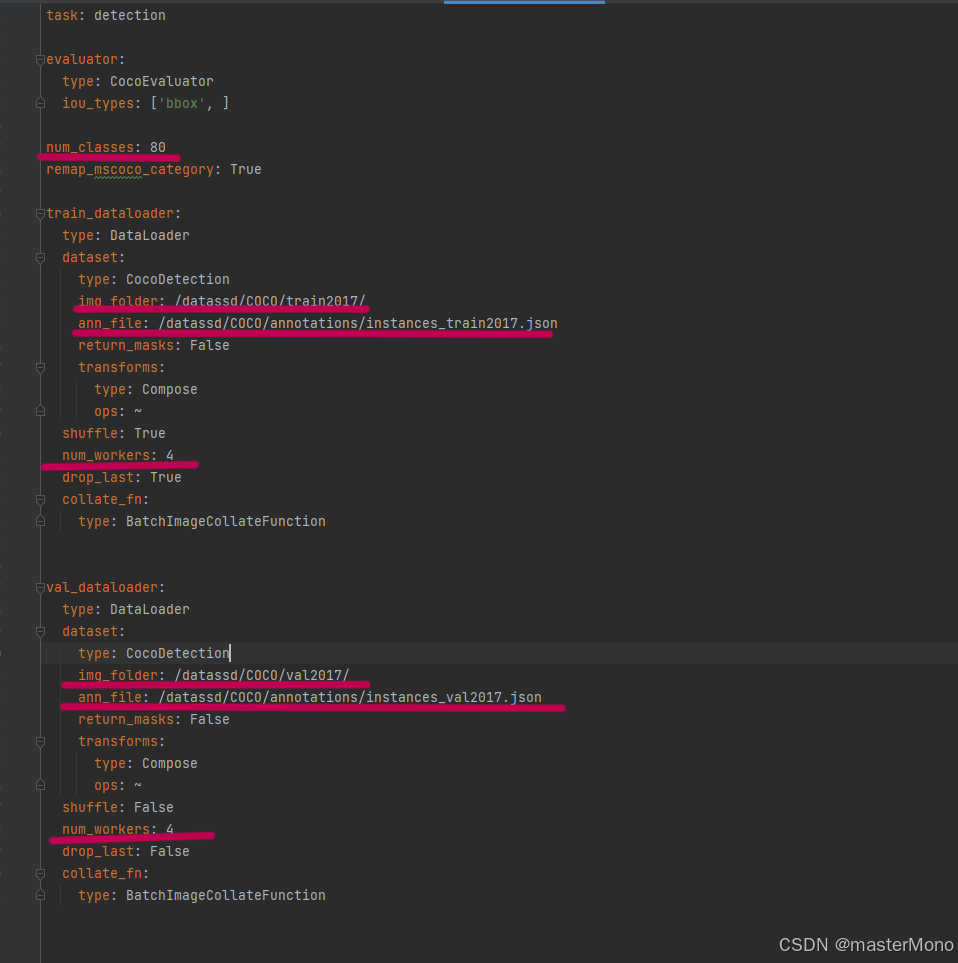
在configs/dataset目录中找到coco_detection.yml文件,需要修改的地方在下图中使用横线标出。
也可以复制coco_detection.yml一份并按照自己的习惯重命名。
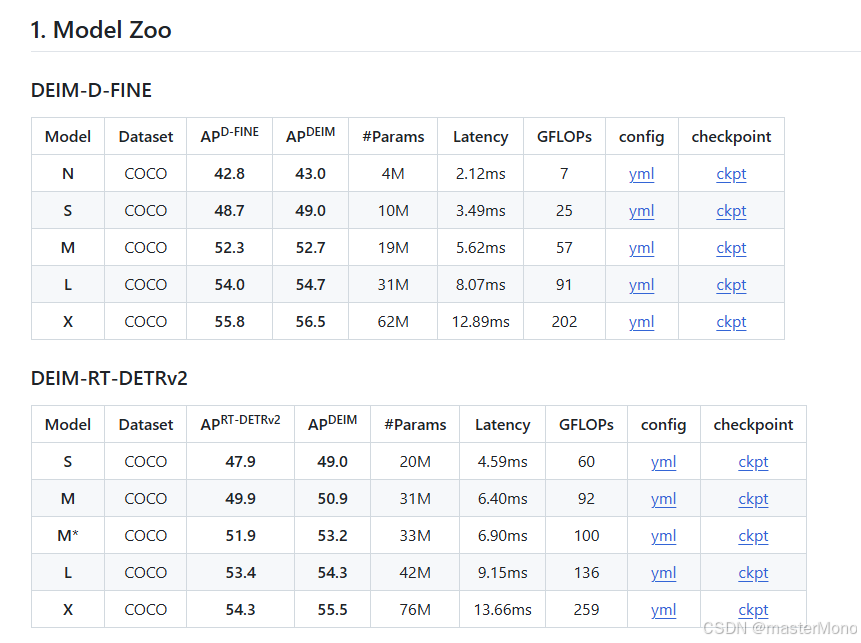
下一步取决于你想要训练哪个模型,以DFine为例。
在作者的github中给出的DFine和RTDETR的不同大小模型。建议GPU显存较小的选择参数量低的模型。
在configs/deim_dfine目录中有模型配置文件,模型配置文件同样需要进行修改。
以dfine_hgnetv2_s_coco为例
文件_include_中的内容为导入的内容,如你重命名了数据集配置文件,其中的coco_detection.yml就需要修改。
output_dir可自定义。
__include__: [
'../dataset/coco_detection.yml',
'../runtime.yml',
'../base/dataloader.yml',
'../base/optimizer.yml',
'../base/dfine_hgnetv2.yml',
]
output_dir: ./output/dfine_hgnetv2_s_coco
DEIM:
backbone: HGNetv2
HGNetv2:
name: 'B0'
return_idx: [1, 2, 3]
freeze_at: -1
freeze_norm: False
use_lab: True
DFINETransformer:
num_layers: 3 # 4 5 6
eval_idx: -1 # -2 -3 -4
HybridEncoder:
in_channels: [256, 512, 1024]
hidden_dim: 256
depth_mult: 0.34
expansion: 0.5
optimizer:
type: AdamW
params:
-
params: '^(?=.*backbone)(?!.*norm|bn).*$'
lr: 0.0001
-
params: '^(?=.*backbone)(?=.*norm|bn).*$'
lr: 0.0001
weight_decay: 0.
-
params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
weight_decay: 0.
lr: 0.0002
betas: [0.9, 0.999]
weight_decay: 0.0001
# Increase to search for the optimal ema
epoches: 132 # 120 + 4n
train_dataloader:
dataset:
transforms:
policy:
epoch: 120
collate_fn:
stop_epoch: 120
ema_restart_decay: 0.9999
base_size_repeat: 20
在train_dataloader中,你可以添加以下代码,以自定义训练的batch size。
total_batch_size: 8同样的,你也可以以下代码,来自定义验证的batch size。
val_dataloader:
total_batch_size: 8如需修改其它参数,你可以在模型配置文件中直接重新声明,也可以直接去源文件中修改。
4 模型训练
配置文件均修改完成后,在命令行输入训练指令(该指令为单卡训练的指令):
CUDA_VISIBLE_DEVICES=0 torchrun --master_port=7777 --nproc_per_node=1 train.py -c configs/deim_dfine/dfine_hgnetv2_s_pest.yml --use-amp --seed=0CUDA_VISIBLE_DEVICES表示使用几号gpu训练,若你只挂载了一个显卡,则CUDA_VISIBLE_DEVICES=0 ,nproc_per_node=1,configs/deim_dfine/dfine_hgnetv2_s_pest.yml表示模型配置文件,需要根据你自己的实际情况修改。
多卡训练的指令可参考官方,同时使用四张gpu训练。
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deim_dfine/deim_hgnetv2_${model}_coco.yml --use-amp --seed=0运行成功截图
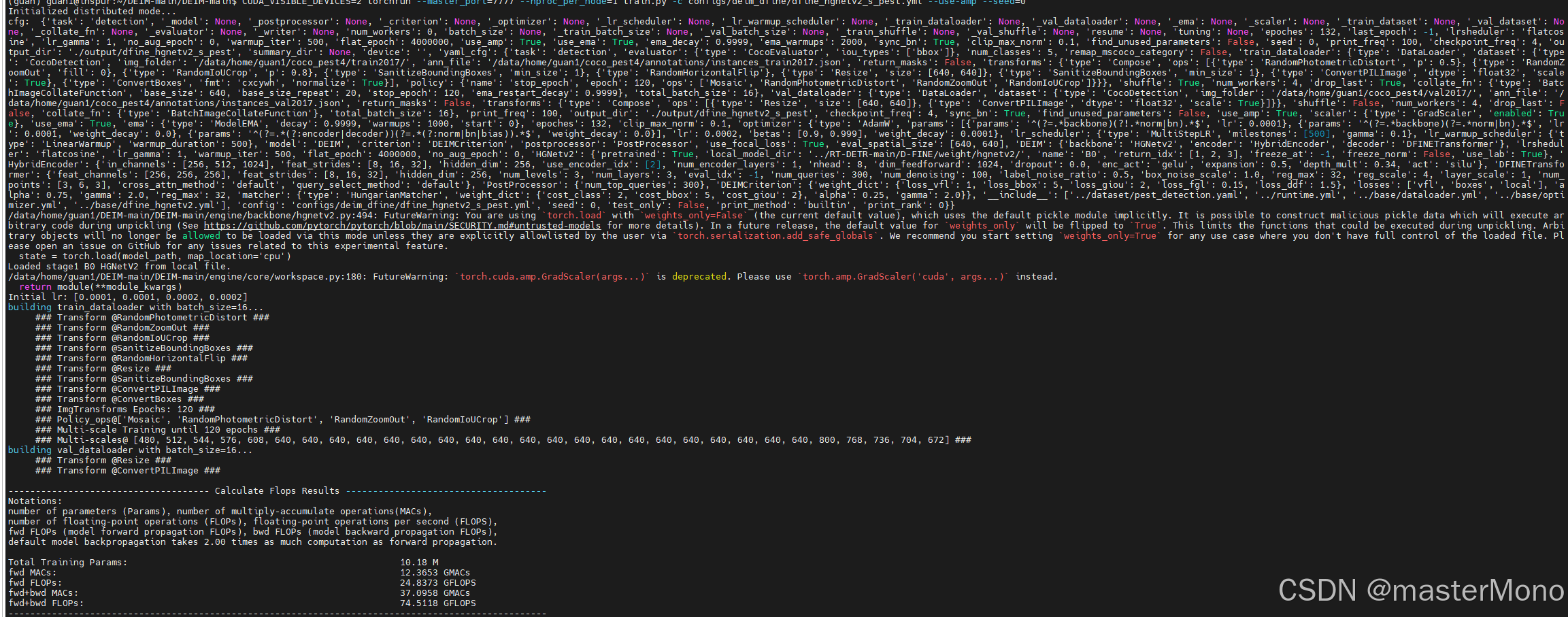
 我训练的是deim-dfines模型,batch设置为16,使用2号卡单卡训练,占用了12000+MiB的显存,以供参考。
我训练的是deim-dfines模型,batch设置为16,使用2号卡单卡训练,占用了12000+MiB的显存,以供参考。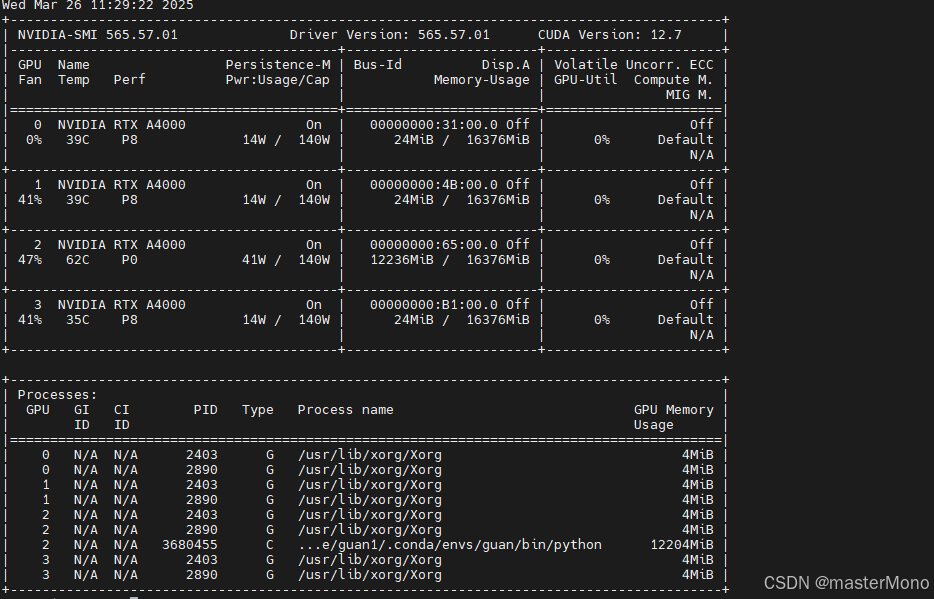
5 模型测试
对于训练好的模型,如何在测试集上获取其性能指标?
将数据集配置文件中的val_dataloader修改,其实就是把路径中的val改成test,示例如下:
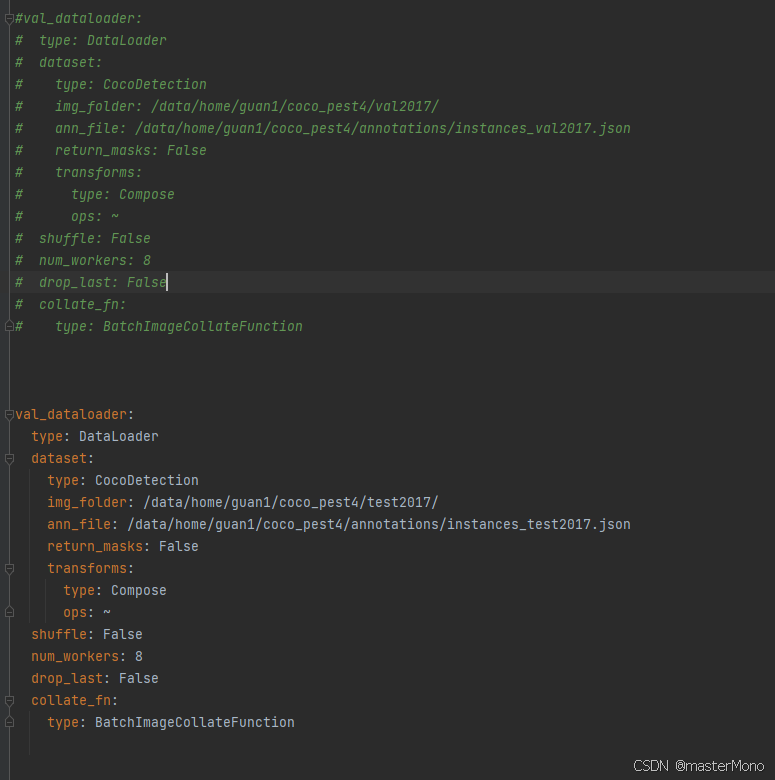
测试指令的示例如下,使用时需要根据实际情况修改配置文件和权重路径。
CUDA_VISIBLE_DEVICES=0 torchrun --master_port=7777 --nproc_per_node=1 train.py -c configs/deim_dfine/dfine_hgnetv2_s_pest.yml --test-only -r output/dfine_hgnetv2_s_pest/best_stg1.pth测试完成后会输出在测试集上的coco指标
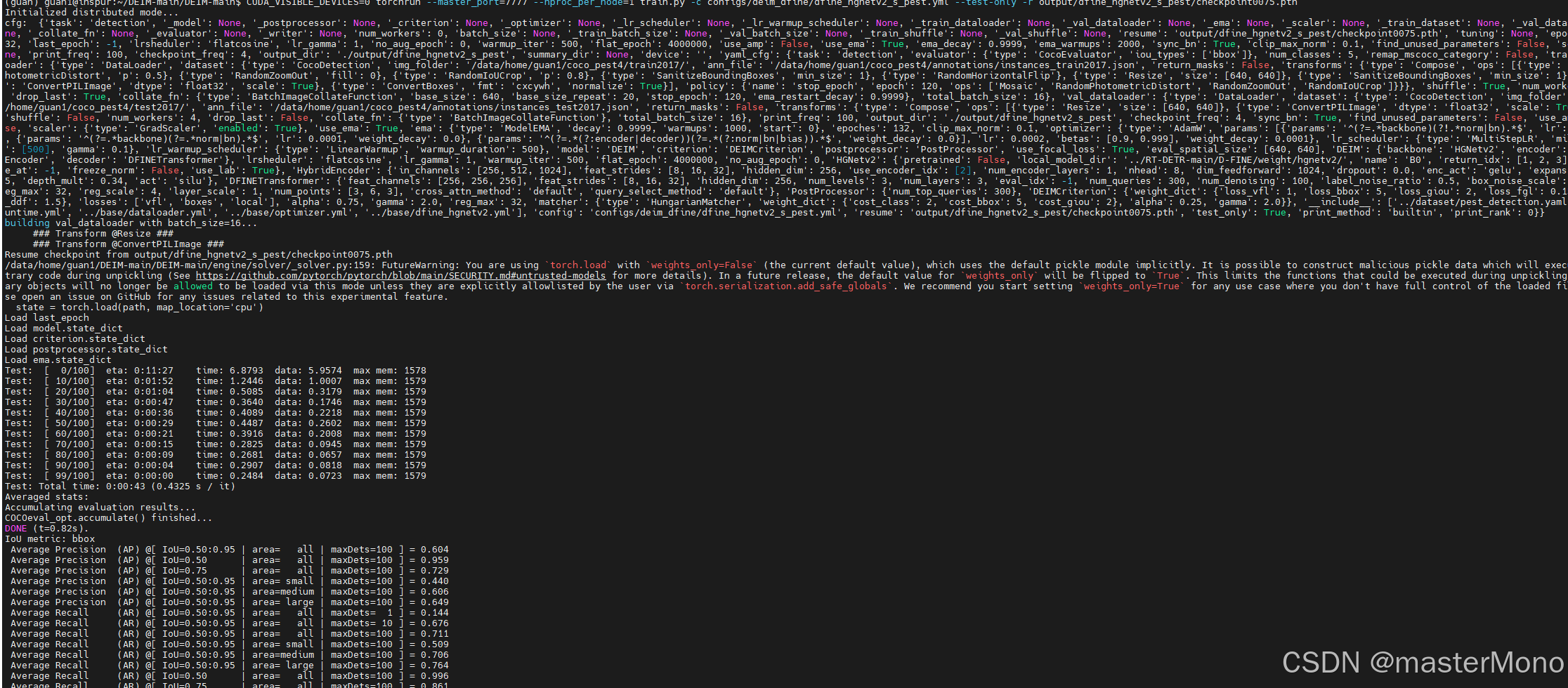
错误汇总
- 在首次尝试跑通DEIM的时候,发生一个错误,其内容是faster-coco-eval尝试将json标注文件中的imageid转化为int格式的时发生错误。这个问题的根源出在数据集中的图像命名方式问题,若图像名含有字母(a,b,c......)或特殊字符(-_%......),导致json文件中的imageid也带有这种字符,imageid自然就无法被该库转化为int格式的了。如何解决?将图像名改为纯数字格式的即可,然后重新构建json标注文件。
- 暂无遇见其它错误。