mysql学习-索引规则
1、概述
索引是一种数据结构,为了提升搜索效率。
索引分类:主键索引、唯一索引、普通索引、组合索引、以及全文索引。
主键索引
非空唯一索引,一个表只有一个主键索引;在innodb中,主键索引的B+树包含表数据信息
PRIMARY KEY(key1, key2)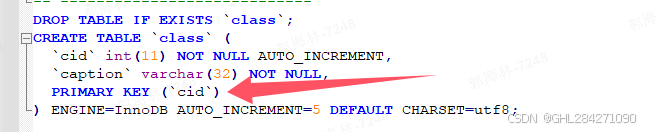
唯一索引
不可以出现相同的值,可以有NULL值
UNIQUE(key)普通索引
允许出现相同的索引内容;
INDEX(KEY)
-- or
KEY(key[,...])
组合索引
对表上的多个列进行索引
INDEX idx(key1,key2[,...]);
UNIQUE(key1,key2[,...]);
PRIMARY KEY(key1,key2[,...]);全文索引
将存储在数据库当中的整本书和整篇文章中的任意内容信息查找出来的技术;关键词FULLTEXT;
在短字符串中用LIKE %;在全文索引中用match和against;
2、索引规则
2.1、最左匹配原则
对于组合索引,从左到右依次匹配,第一个满足,再匹配下一个,遇到<> between like就停止匹配。
举例说明:
关键字EXPLAIN作用于优化器,
KEY `name_cid_idx` (`name`, `cid`):将name和cid作为一个组合索引。
CREATE TABLE `left_match_t` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) DEFAULT NULL,
`cid` INT(11) DEFAULT NULL,
`age` SMALLINT DEFAULT 0,
PRIMARY KEY (`id`),
KEY `name_cid_idx` (`name`, `cid`)
)ENGINE = INNODB AUTO_INCREMENT=0 DEFAULT CHARSET = utf8;
INSERT INTO `left_match_t` (`name`, `cid`, `age`)
VALUES
('aa', 10001, 12),
('bb', 10002, 13),
('cc', 10003, 14),
('dd', 10004, 15)
SHOW INDEX FROM `left_match_t`;
# 作用优化器
EXPLAIN SELECT * FROM `left_match_t` WHERE `name` = 'aa';
EXPLAIN SELECT * FROM `left_match_t` WHERE `cid` = 1;EXPLAIN SELECT * FROM `left_match_t` WHERE `name` = 'aa';
where条件name为组合索引中第一个;运行结果type为ref,说明使用索引进行数据的查找。

EXPLAIN SELECT * FROM `left_match_t` WHERE `cid` = 1;
最左匹配原则要先匹配name,再匹配cid。
where条件cid为组合索引第二个;不符合最左匹配原则。
运行结果type为all,代表全表扫描,效率比较低的。

2.2、覆盖索引
从辅助索引中就能找到数据,而不需要再通过聚集索引查找;
辅助索引:除了主键索引,其他索引都是辅助索引,辅助索引的叶子节点中,除了包含索引信息,还包含聚集索引信息。
举例说明:
PRIMARY KEY (`id`):id为主键
KEY `name_cid_idx` (`name`, `cid`):name 和 cid为组合索引。
CREATE TABLE `covering_index_t` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) DEFAULT NULL,
`cid` INT(11) DEFAULT NULL,
`age` SMALLINT DEFAULT 0,
`score` SMALLINT DEFAULT 0,
PRIMARY KEY (`id`),
KEY `name_cid_idx` (`name`, `cid`)
)ENGINE = INNODB AUTO_INCREMENT=0 DEFAULT CHARSET = utf8;
INSERT INTO `covering_index_t` (`name`, `cid`, `age`, `score`)
VALUES
('aa', 10001, 12, 99),
('bb', 10002, 13, 98),
('cc', 10003, 14, 97),
('dd', 10004, 15, 100);
EXPLAIN SELECT * FROM `covering_index_t` WHERE `name` = 'aa';
EXPLAIN SELECT `name`, `cid`, `id` FROM `covering_index_t` WHERE `name` = 'aa';EXPLAIN SELECT * FROM `covering_index_t` WHERE `name` = 'aa';
查找过程:
1、where条件name为组合索引第一个,从辅助索引B+树的叶子节点中,找到主键(id)信息
2、根据id,搜索聚集索引B+树,找到对应索引,获取相关信息
3、备注:这里找了2次,第一次查找辅助索引B+树,第二次查找聚集索引B+树。
辅助索引B+树叶子节点有:name、cid、id
聚集索引B+树叶子节点有:id、name、cid、age、score
EXPLAIN SELECT `name`, `cid`, `id` FROM `covering_index_t` WHERE `name` = 'aa';
查找过程:
1、where条件name为组合索引第一个,从辅助索引B+树的叶子节点中,找到name cid id信息
2、备注:这里找了1次,查找辅助索引B+树,获取name、cid、id
using_index:采用覆盖索引,直接从索引中读取数据,而不用访问数据表

2.3、索引下推
为了减少回表次数,提升查询效率,在mysql 5.6版本开始推出。
mysql架构分为server层和存储引擎层。
没有索引下推机制之前:server层向存储引擎层请求数据,在server层根据索引条件判断进行数据过滤;
有索引下推机制之后:将部分索引条件判断下推到存储引擎中过滤数据,最终由存储引擎将数据汇总返回给server层;
2.4、索引失效
1、看select ....where A and B 若A 和 B中有一个不包含索引,则索引失效
2、索引字段参与运算,则索引失效,例如:from_unixtime(idx) = '2021-04-30';
3、LIKE模糊查询,通配符%开头,则索引失效,例如:select * from user where name like '%aa';
4、在索引字段上使用NOT <> !=索引失效,如果判断id<>0 则修改为idx > 0 or idx < 0;
5、组合索引中,没有第一列索引,则索引失效(没有符合最左匹配原则)
举例说明:
DROP TABLE IF EXISTS `index_failure_t`;
CREATE TABLE `index_failure_t` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) DEFAULT NULL,
`cid` INT(11) DEFAULT NULL,
`age` SMALLINT DEFAULT 0,
`score` SMALLINT DEFAULT 0,
`phonenumber` VARCHAR(20),
PRIMARY KEY (`id`),
KEY `name_idx` (`name`),
KEY `phone_idx` (`phonenumber`)
)ENGINE = INNODB AUTO_INCREMENT=0 DEFAULT CHARSET = utf8;
INSERT INTO `index_failure_t` (`name`, `cid`, `age`, `score`, `phonenumber`)
VALUES
('谢某某', 10001, 12, 99, '13100000000'),
('廖某某', 10002, 13, 98, '13700000000'),
('吴某某', 10003, 14, 97, '17300000000'),
('王某某', 10004, 15, 100, '13900000000');
explain select * from index_failure_t where name like '%谢';
explain select * from index_failure_t where name like '谢%';
explain select * from index_failure_t where length(name) = 9;
explain select * from index_failure_t where id = 3-1;
explain select * from index_failure_t where id+1 = 3;LIKE模糊查询,通配符%开头,索引失效

索引字段参与运算,索引失效

MySQL 遇到字符串和数字比较时,会自动将字符串转换为数字

2.5、索引原则
1、查询频次较高且数据量大的表建立索引;索引选择使用频次较高,过滤效果好的列或者组合;
2、使用短索引;节点包含的信息多,较少磁盘 IO 操作;比如: smallint , tinyint ;
3、对于很长的动态字符串,考虑使用前缀索引;
4、对于组合索引,考虑最左侧匹配原则、覆盖索引;
5、不要 select * ; 尽量只列出需要的列字段;方便使用覆盖索引;
6、索引列,列尽量设置为非空;
学习链接:https://github.com/0voice