【读点论文】Object Storage on CRAQ
论文 Chain Replication for SupportingHigh Throughput and Availability 提出了链式复制(Chain Replication)的方案,用于在保证强一致性的同时,提供支持高吞吐和高可用的存储服务。
原始的 Chain Replication 方案在性能上存在一些问题,因为数据读取只能在 tail 节点进行,这样会导致 tail 节点压力过大,而其他节点利用率较低。后续普林斯顿大学发表了论文Object Storage on CRAQ,提出了 CRAQ 的方案,通过将数据读请求分摊到所有节点的方式提高了读取性能。
这里我们来详细读下 CRAQ 的论文,看看其是如何解决原始 Chain Replication 方案的性能问题的。
CRAQ 基本原理
原始的 Chain Replication 读写数据流程是:
- 写请求发送到 header 节点,依次向后传播,直到 tail 节点写入成功后,由 tail 节点响应给客户端。
- 读请求发送到 tail 节点,由 tail 节点响应给客户端。
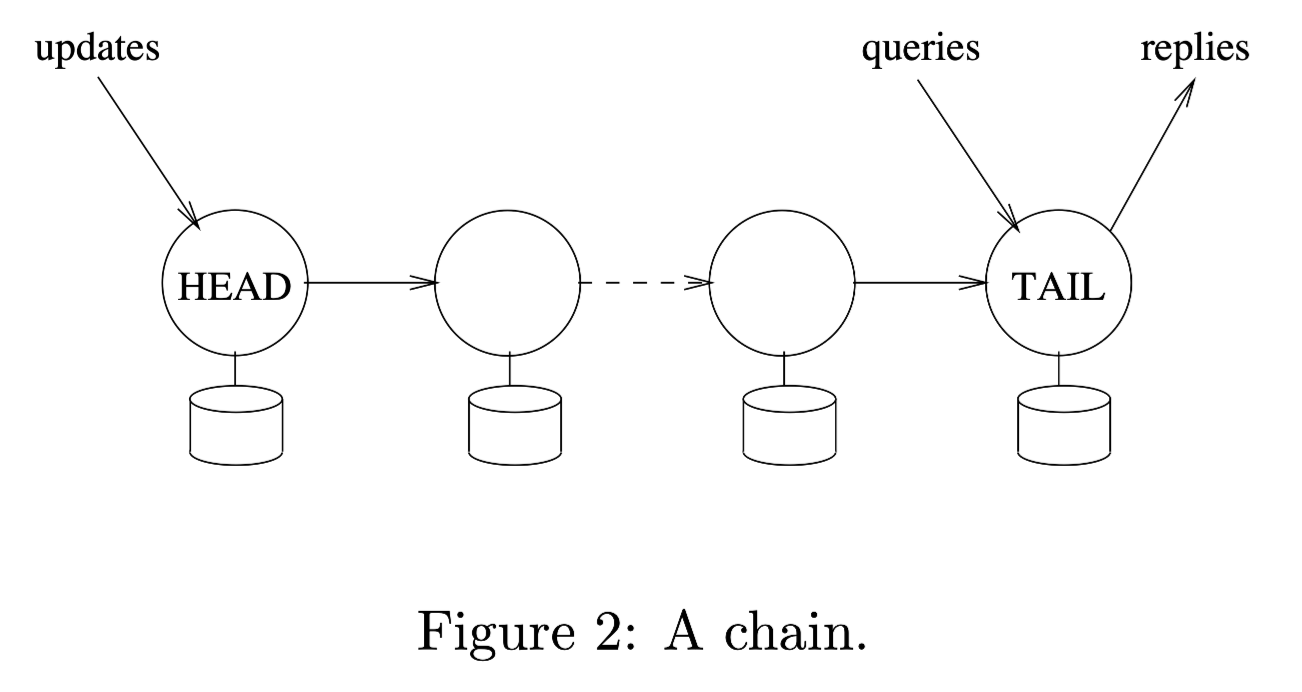
可以看到真正对外提供访问的只有 header 和 tail 节点,其他节点只是单纯的负责数据备份,造成了一定程度的资源浪费。
CRAQ 全称为 Chain Replication with Apportioned Queries,顾名思义就是将查询进行了分摊(Apportioned),其将负载分摊到所有节点,提高了读取性能。整个读写过程变成了下面这样:
写操作
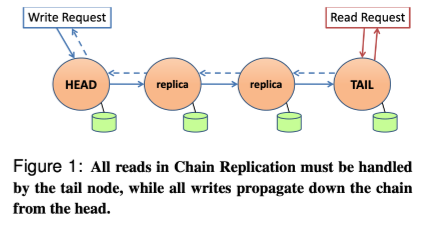
如图中蓝色的箭头所示:
-
写请求依然发送到 header 节点,并沿着链向后传递到 tail 节点,但 tail 节点写入成功后不在直接响应给客户端,而是基于 TCP 协议通信,向其 predecessor 节点响应 ACK 消息,节点在收到 ACK 消息后确认写入成功。
-
每个 object 会有一个单调递增的版本号(本质就是一个逻辑时钟),每次更新都会导致版本号递增。同时维护一个状态属性,默认为
clean,当有写请求进来更新 object 时,节点将版本号递增,同时存储两个版本的数据,并设置最新版本的状态为dirty。 -
节点在收到 successor 节点的 ACK 后,确认写入成功,会将旧版本数据清理并更新对象状态为
clean。
读操作
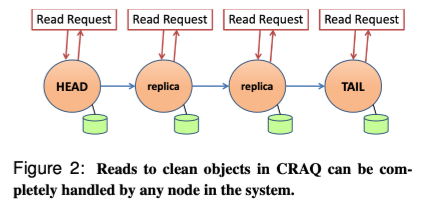
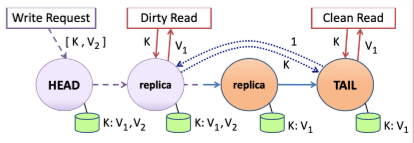
-
读请求可以发送到任意节点。
-
如果节点对应 object 的状态为
clean,则直接响应给客户端。 -
如果节点对应 object 的状态为
dirty,则节点会向 tail 节点发送请求,查询对应 object 的数据,最终以 tail 节点的数据为准进行返回
可以看到,采用 CRAQ 方案时,服务的读性能与链的长度呈线性关系。对于写负载的高的场景,可能过多的 dirty 数据会导致 tail 节点要频繁的执行版本查询,一个优化方案是将 tail 节点只作为版本查询的处理使用,不对外提供查询服务。