【Linux】文件查找、软硬链接、动静态库
本文章延续此文深入理解Linux文件系统:从磁盘结构到inode与挂载-CSDN博客
linux 基础io
linux - 基础IO之操作与文件描述符全解析:从C语言到系统调用底层实现-CSDN博客
Linux:从文件操作到重定向与缓冲区的底层实现与实战-CSDN博客
深入理解Linux文件系统:从磁盘结构到inode与挂载-CSDN博客
目录
a.软硬链接是什么
b.软硬链接的特征
1.软链接是一个独立的文件,因为有独立的inode number
2.硬链接不是一个独立的文件 ,因为没有独立的inode number,用的是目标文件的inode
3.属性中有一列硬链接数
硬链接数就是文件的磁盘级引用计数
c.软硬链接有什么用(为什么要有软硬链接)场景
1.软链接的作用:
在linux系统当中:软链接通常就是作为一个快捷方式
2.硬链接的作用
作用1:构建Linux的路径结构,让我们可以使用 . .. 来进行路径的定位
作用2:硬链接一般用来做文件备份
动态库与静态库
1.我们使用过C,C++的标准库
2.Linux.so(动态库).a(静态库) windows:dll .lib
静态库
变成.o就是所有方法的实现:gcc -c
使用命令:ar -rc ---> r--->replace ----》c ----> create,将.o文件形成静态库,ar是gnu归档工具
所谓的库文件:本质就是把.o打包形成.a静态库,用于提高开发效率
在路径下以及安装好
在链接时只需要链接我所写的库的真实名字也就是myc
卸载掉一个库:
不安装如何直接使用:
-I(大i) 能直接找到自己头文件
-L(link) 找到lib文件
-l(小l) 跟库的真实名字:
不在命令行写头文件路径的办法(不能写<>会默认在gcc/g++认识的库中去找)
总结:
动态库:
gcc -fPIC -
-shared
方法1(不建议):将动态库直接拷贝到lib下:
方法2:建立软链接
方法3:使用环境变量LD_LIBRARY_PATH(加载库路径)
方法5: /etc/ld.so.conf.d/ 新增动态库搜索的配置文件,idconfi g使其生效
安装ncurses库:
编译测试程序
附加问题:动态库(共享库)是如何加载的 --- 可执行程序和地址空间
编辑
一、动态库加载的核心流程
1. 编译时链接(静态链接阶段)
2. 运行时加载(动态链接阶段)
博客主要内容总结
本文系统讲解了 Linux 文件系统中的 软硬链接 与 动静态库 的核心机制及实践应用,内容涵盖以下重点:
一、软硬链接详解
软链接(符号链接)
创建命令:
ln -s 目标文件 软链接名特性:独立 inode,存储目标文件路径;类似 Windows 快捷方式,删除目标文件后失效。
应用场景:快速访问深层文件(如项目配置、动态库快捷方式)。
硬链接
创建命令:
ln 目标文件 硬链接名特性:共享目标文件 inode,本质是文件名到 inode 的映射;删除原文件不影响硬链接。
应用场景:构建目录结构(如
.和..)、文件备份。二、静态库与动态库的创建与使用
静态库(.a)
创建步骤:
gcc -c 源文件.c # 生成 .o 文件 ar -rc lib库名.a *.o # 打包为静态库使用:编译时通过
-I指定头文件路径,-L指定库路径,-l链接库名。特点:代码嵌入可执行文件,体积大但无运行时依赖。
动态库(.so)
创建步骤:
gcc -fPIC -c 源文件.c # 生成位置无关的 .o gcc -shared *.o -o lib库名.so # 生成动态库使用:需配置运行时路径(方法如下):
- 临时生效:
export LD_LIBRARY_PATH=库路径- 永久生效:
echo "库路径" | sudo tee /etc/ld.so.conf.d/自定义.conf sudo ldconfig- 特点:代码共享、内存占用低,但依赖路径配置。
三、动态库加载机制与进程地址空间
加载流程
编译时:记录依赖信息(如
DT_NEEDED)。运行时:动态链接器(
ld.so)搜索库路径,通过页表映射到进程共享区。符号解析:延迟绑定(PLT/GOT 表)优化性能。
地址空间映射
动态库加载到虚拟地址空间的共享区,多个进程共享同一物理内存。
函数调用通过“库基址 + 偏移量”实现,与可执行程序解耦。
四、实战问题与解决方案
常见错误
找不到头文件:安装
libxxx-dev包或指定-I路径。链接失败:检查
-L和-l参数,确认库文件存在。运行时库缺失:通过
LD_LIBRARY_PATH或系统配置解决。第三方库使用示例
以
ncurses库为例,演示安装、编译与运行:sudo apt install libncurses-dev gcc test.c -o app -lncurses
回顾上节:
文件是如何查找到的
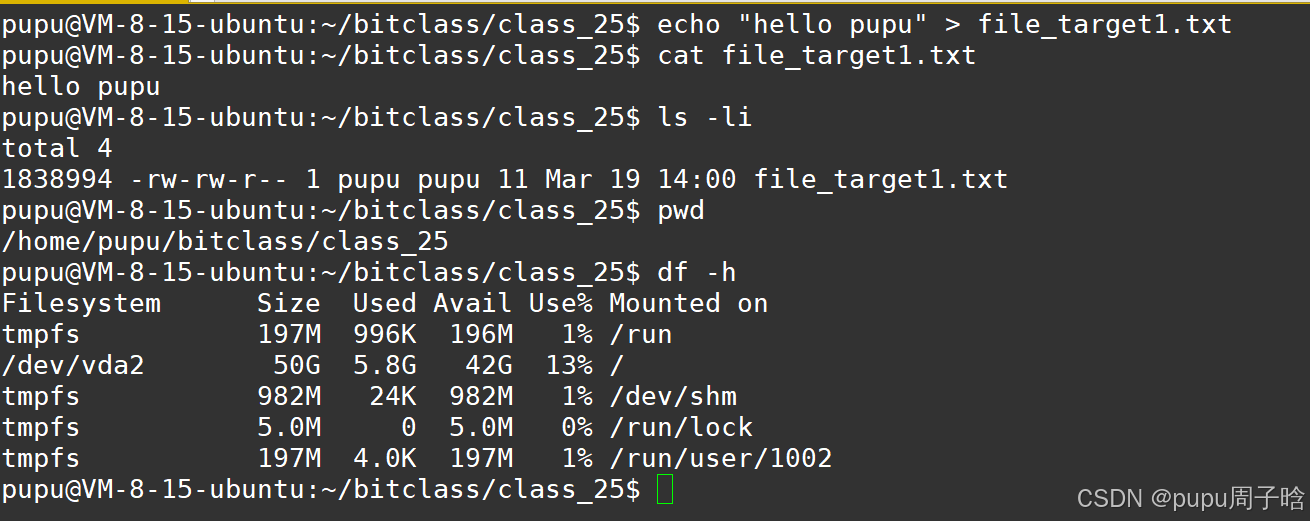
通过我的根目录找到我文件的分区,/dev/vda2挂载在根目录下为我的有效分区,找到我的分区之后,再通过我的inode在/vda2分区下去找我在哪个分组里,最后找到文件和属性。
a.软硬链接是什么
建立软链接:由上面所创建的file_target1.txt继续用
1.ln --- link,s --- soft 用file_soft.link来链接file_target1.txt
ln -s file_target1.txt file_soft.link
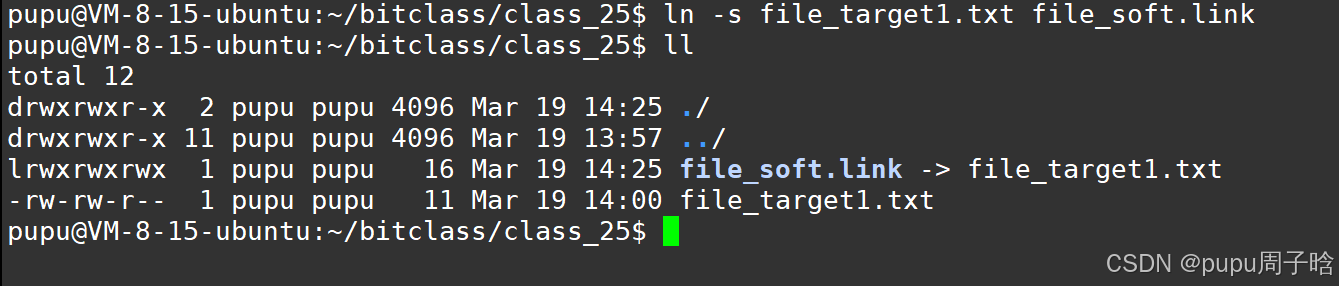
2.inode不同,证明file_target1.txt、file_soft.link都是独立的文件,有独立的inode
ll -i
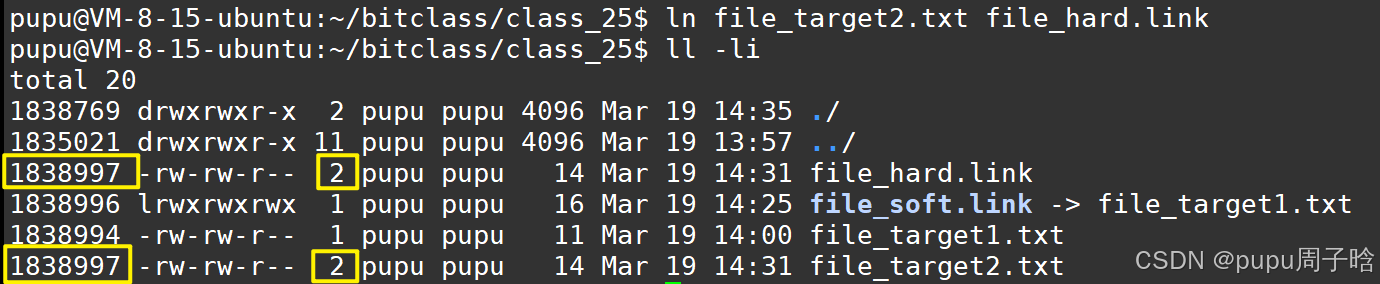
建立硬链接:创建一个新文件file_target2.txt
ln file_target2.txt file_hard.link建立链接后数字为2,并且inode相同


b.软硬链接的特征
1.软链接是一个独立的文件,因为有独立的inode number
软链接的内容,目标文件所对应的路径字符串
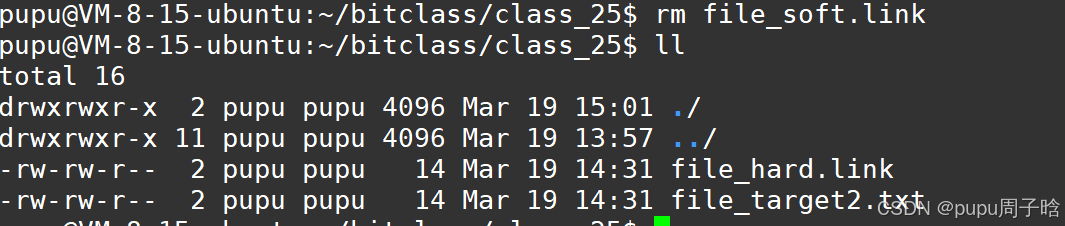
软链接就是windows当中的快捷方式 ,删掉软链接也不会影响目标文件,(只是删掉了快捷方式,拖到回收站也同样在占磁盘容量,回收站的本质也是一个目录(文件),相当于linux中的mv,都得在控制面板中找到软件删除删)
删除掉软链接的目标文件:软链接的目标文件被删,软链接失效
这里可以根据目录直接去看软链接的作用
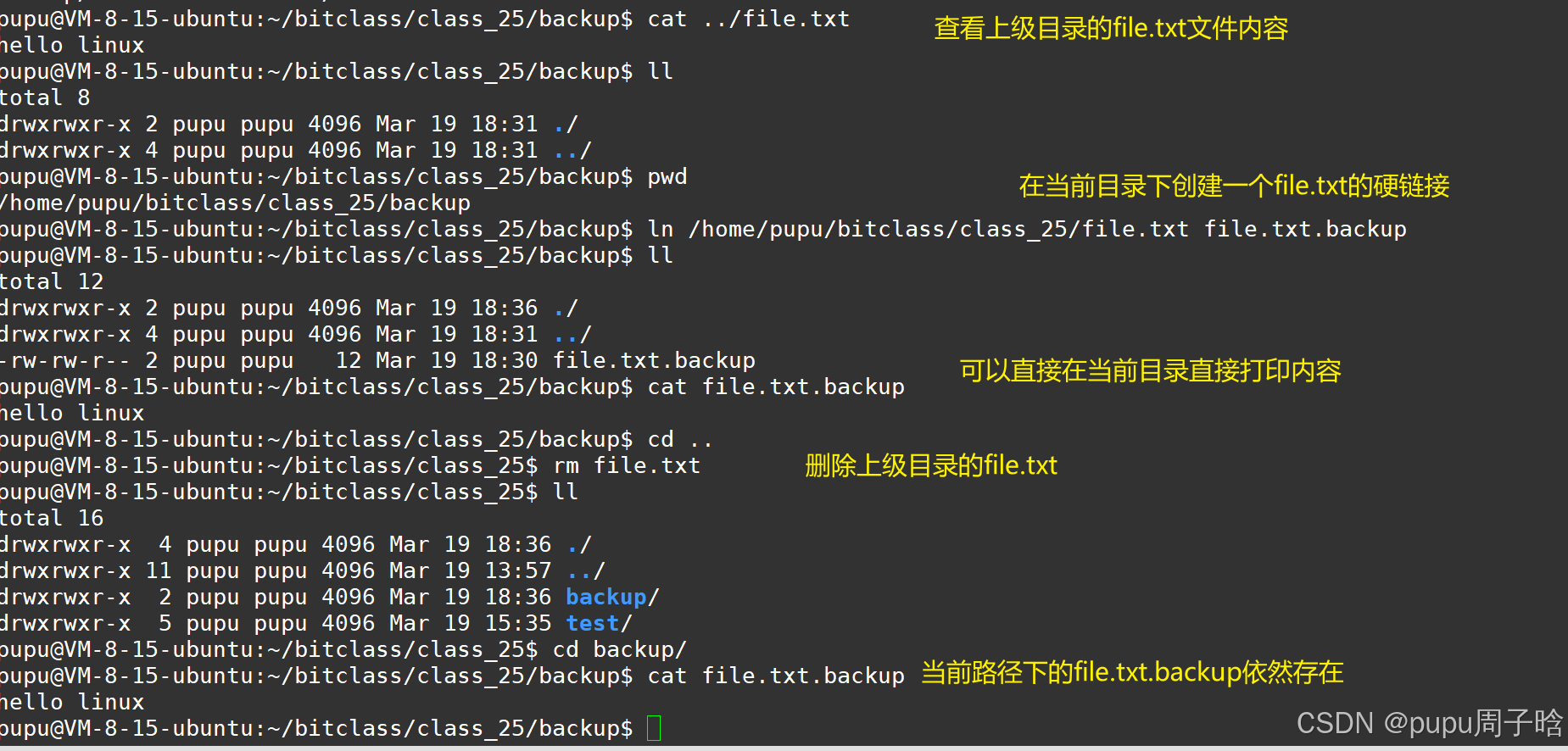
删除一个链接可以使用:rm \ unlink


2.硬链接不是一个独立的文件 ,因为没有独立的inode number,用的是目标文件的inode
删掉目标文件,也不会影响硬链接。
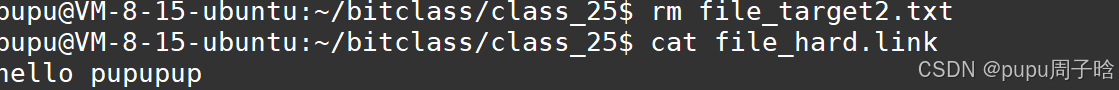
3.属性中有一列硬链接数
当删除掉file_target2.txt,硬链接数变为1
硬链接数就是文件的磁盘级引用计数
文件的磁盘级引用计数:表示的就是有多少个文件名字符串通过inode number指向该文件
硬链接就是一个文件名和inode number的映射关系,建立硬链接,就是在指定目录下,添加一个新的文件名和inode number的映射关系,inode就和一个指针一样,两个inode指向同一个文件属性,因此引用计数就是2,删除一个文件名和inode number的映射关系,引用计数就减少到1 ,引用计数为0,文件就被删除。 删除掉原文件,留下来的硬链接就相当于原文件的重命名。
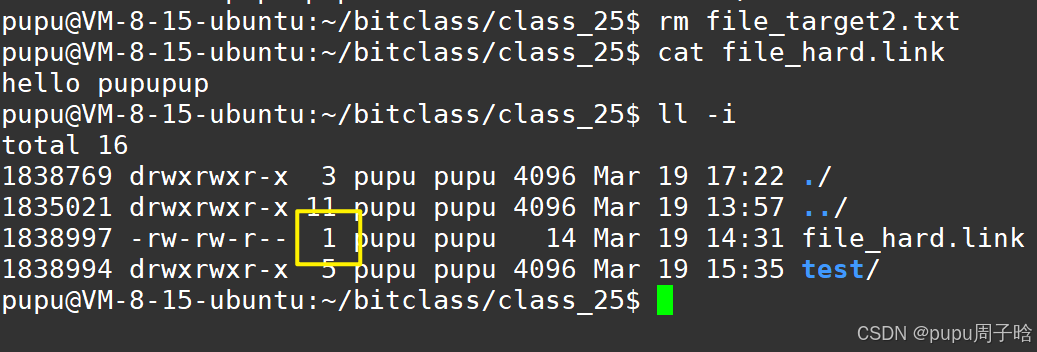
c.软硬链接有什么用(为什么要有软硬链接)场景
1.软链接的作用:
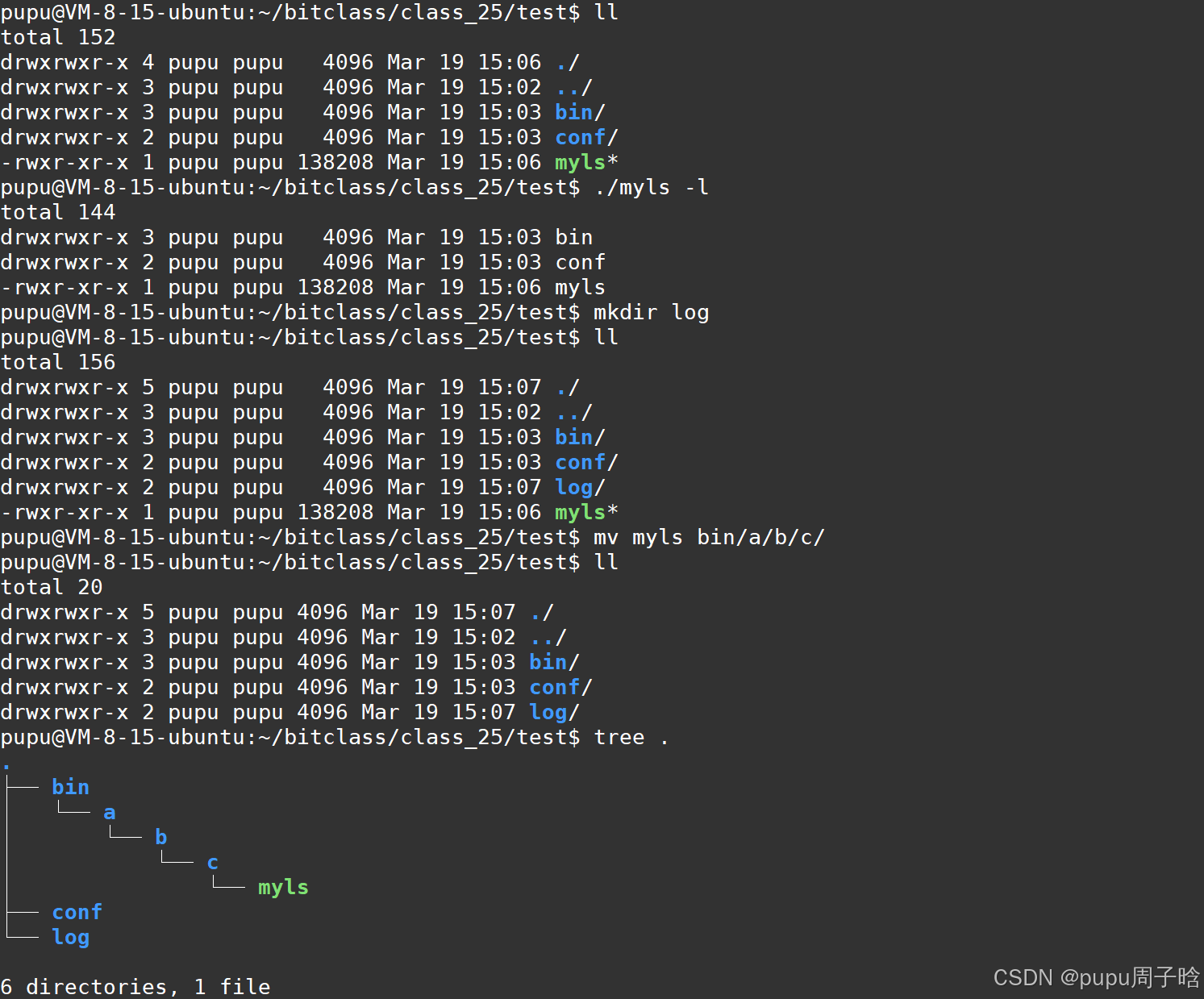
示例一:在未来创建一个项目的时候可能有这样的项目结构:myls(cp /usr/bin/ls myls)
当需要运行myls程序:
1.找到文件再运行
2.创建软链接再运行(就是windows在桌面上使用快捷方式运行文件)
ln -s ./bin/a/b/c/myls run.link

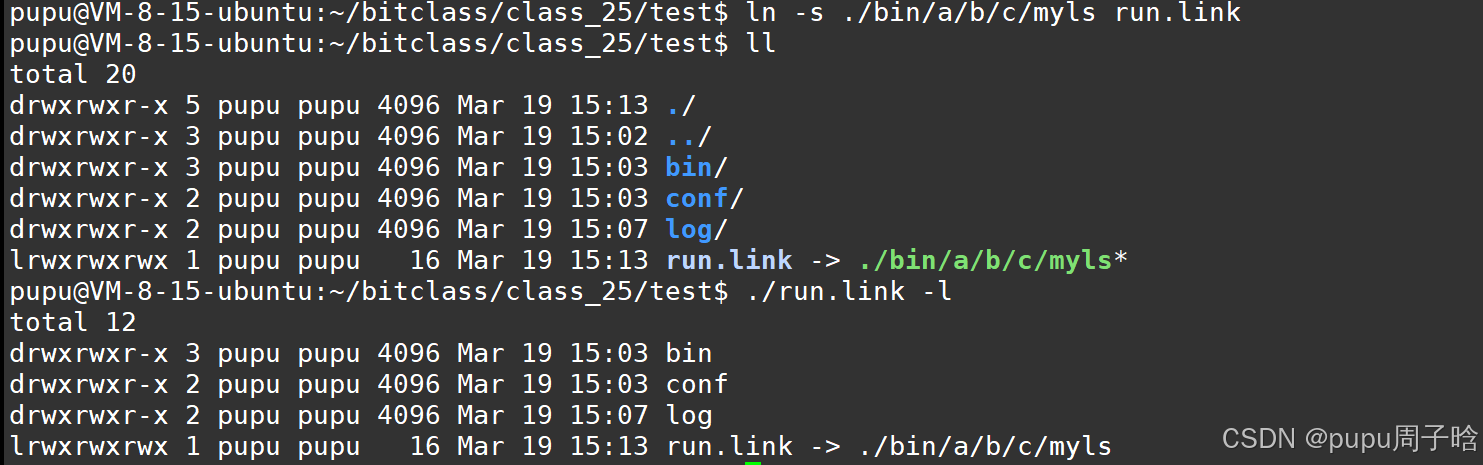
在linux系统当中:软链接通常就是作为一个快捷方式
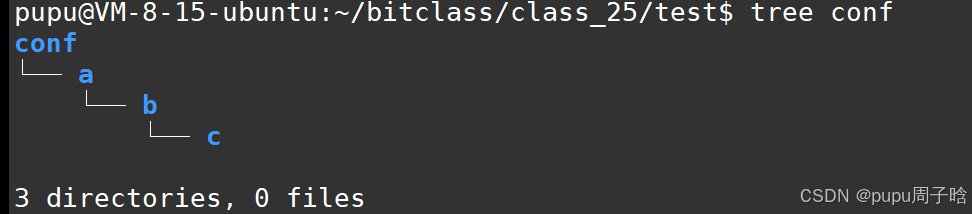
示例二:此时假如配置文件在很深的路径底下想要对他进行编译:
当需要编译文件:
在linux系统中有很多库(动态库静态库,第三方库):方便快速找到,也有许多的软链接
ls /usr/lib -l
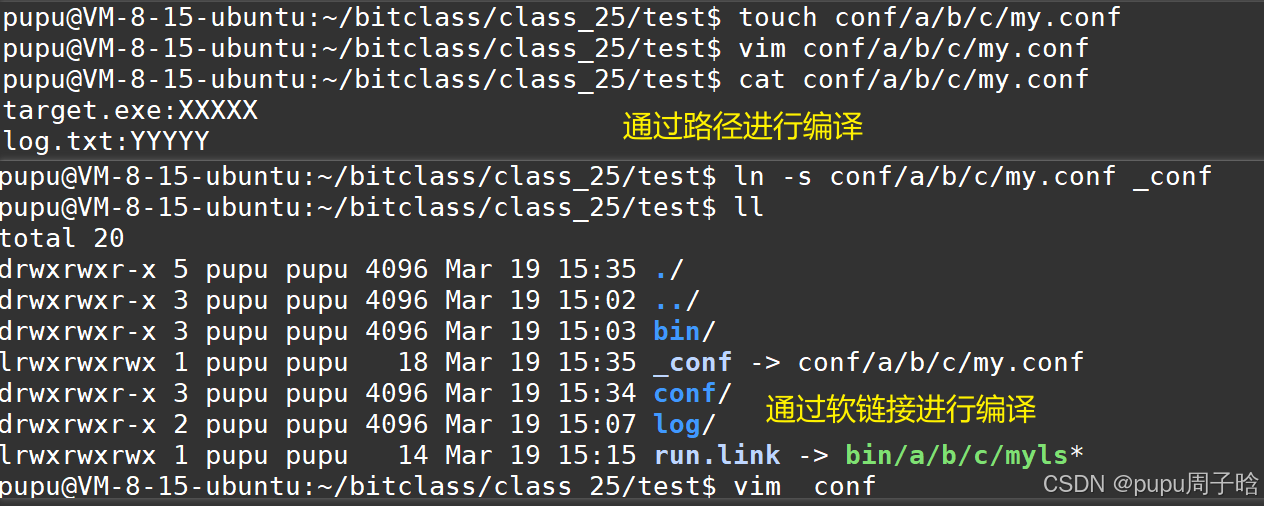
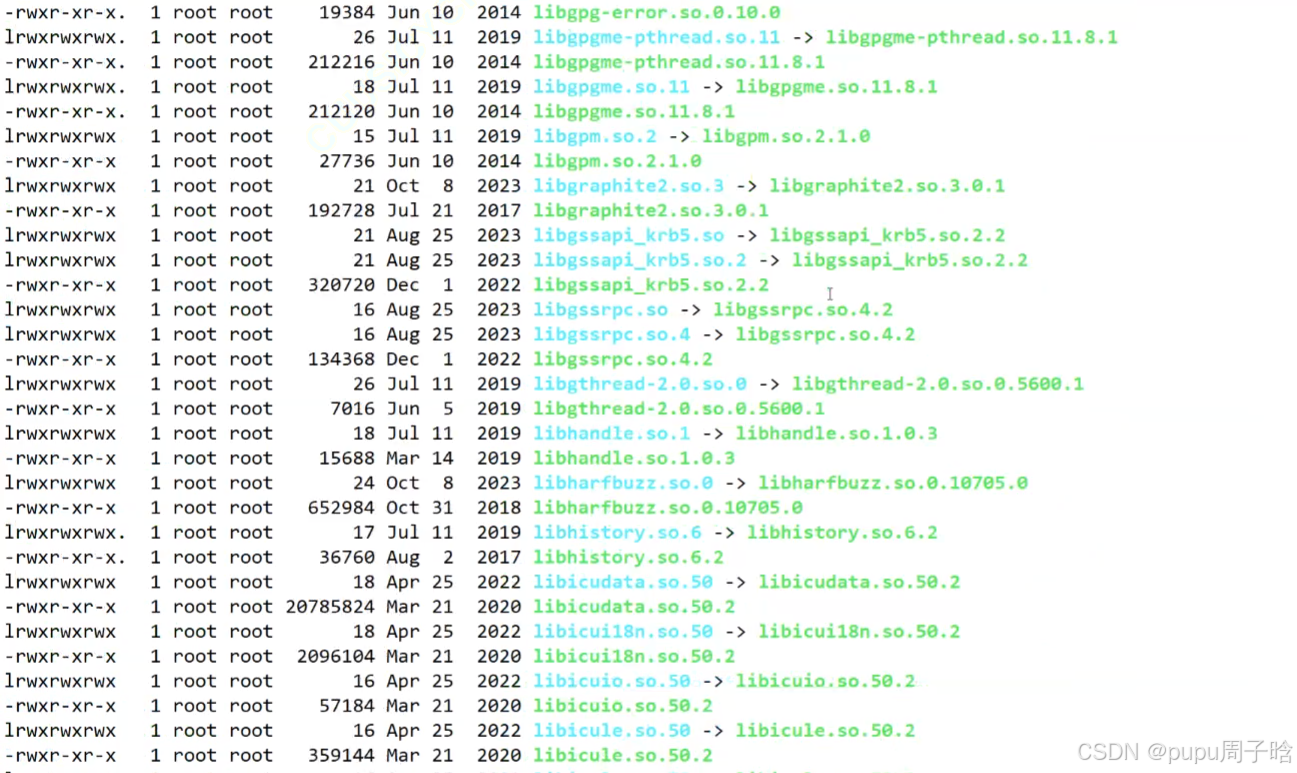
2.硬链接的作用
作用1:构建Linux的路径结构,让我们可以使用 . .. 来进行路径的定位
新创建的文件的引用计数为1,为什么新创建的目录的引用计数是2呢?
如图:任意一个目录下都有. .. ,(一个点是指当前路径,..指上级路径)
因此.就是dir的重命名。
任何一个目录,刚开始新建的时候,引用计数一定是2,目录A内部,新建一个目录,会让A目录的引用计数自动+1。因此一个目录内部有几个目录 == A引用计数-2

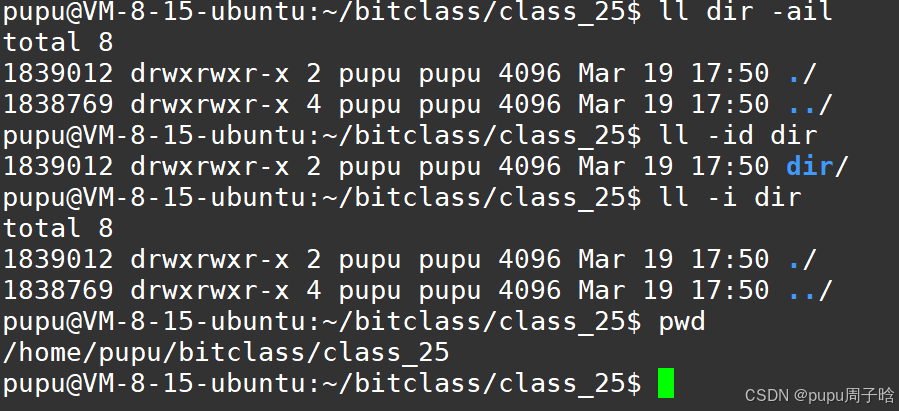
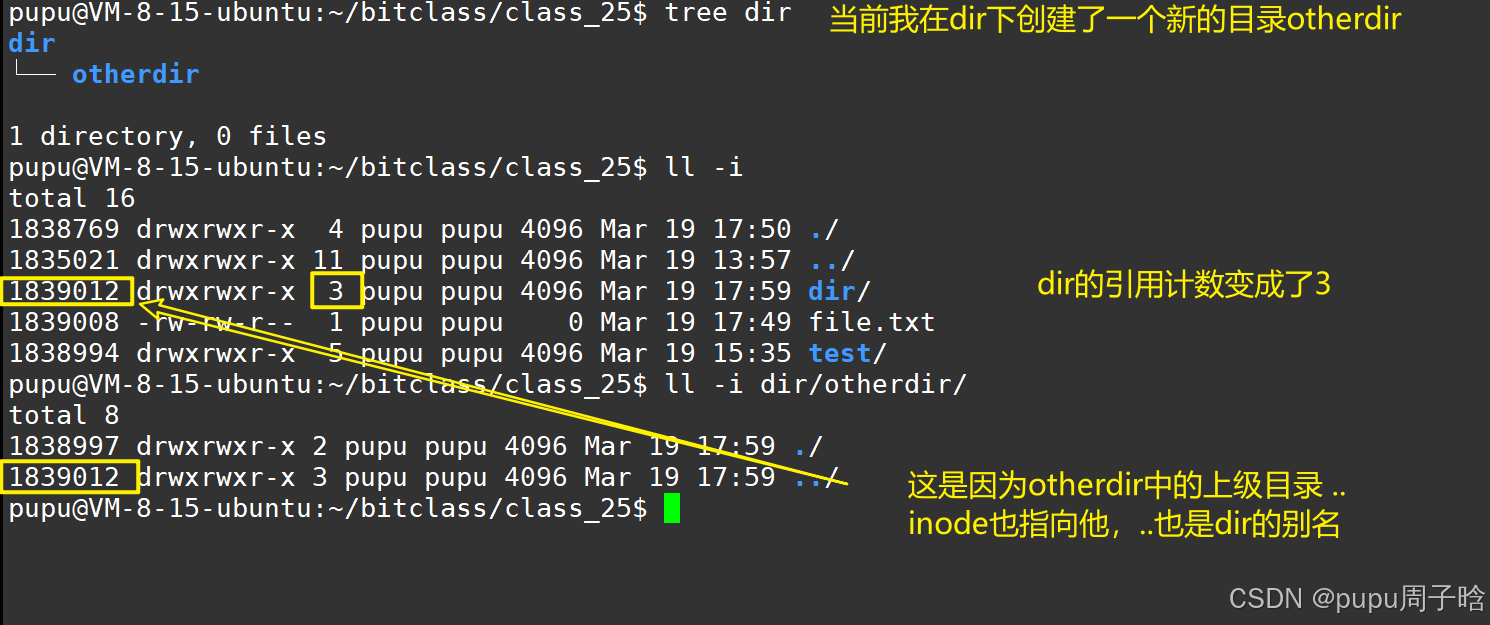
作用2:硬链接一般用来做文件备份
Linux系统中不允许给目录建立硬链接,避免我们自己形成路径环绕。
. ..文件名是固定的,所有的系统指令在设定的时候,几乎都能知道. ..是干什么的
. ..是删不掉的
当前创建了一个文件:并往其中写入hello linux
进入backup


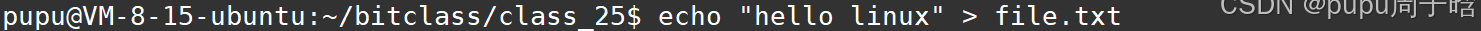
总结学习文件:
打开的文件:与内核,内存有关
未被打开的文件: 与磁盘,文件系统有关
int a =1234567;//4字节 ---> 二进制写入
1234567 ---> "12334567" --->文件(文本写入)
动态库与静态库
在之前我也写过一篇很短的博客,大致讲了一下动静态链接库的区别与使用:
Linux基础-链接 -- 动静态链接 --特点、区别、静态库安装下载-CSDN博客
1.我们使用过C,C++的标准库

所有的实现都在库中
如图我们编写一段c语言代码:
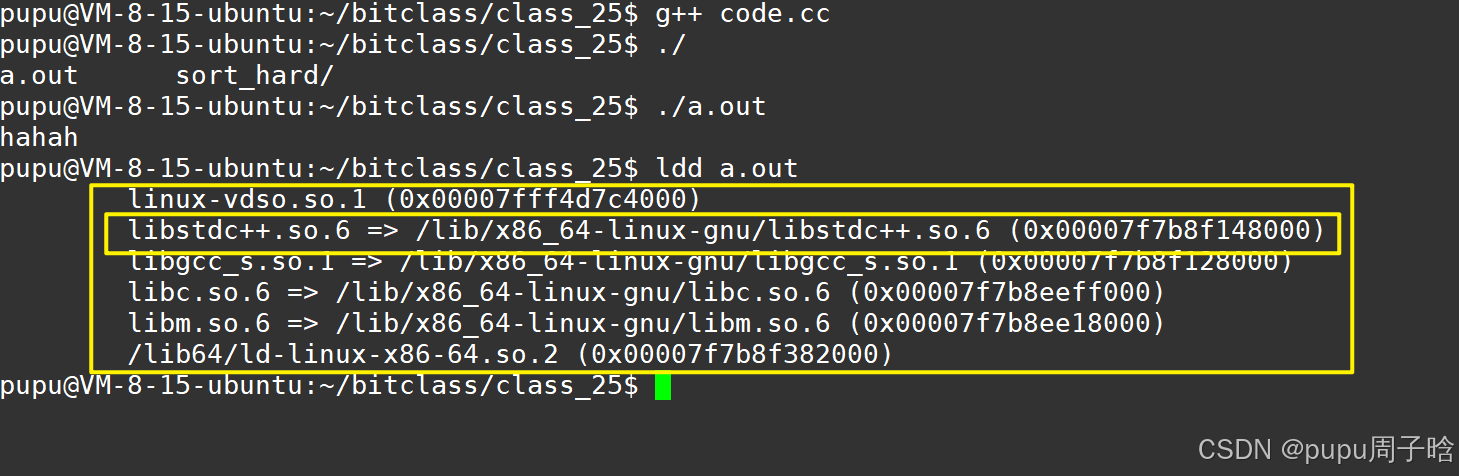
#include<stdio.h> #include<string.h> int main() { char buffer[1024]; strcpy(buffer, "hello C\n"); printf("%s\n", buffer); return 0; }我们的使用只是调用了这些函数的接口。
通过ldd来找到我们的可执行程序,所依赖的库
ldd a.out如图我们所找到的
这就是我们所用到的真正的库


此时我们再编写以个c++的代码:
#include<iostream> #include<string> int main() { std::string name = "hahah"; std::cout << name << std::endl; return 0; }所用到的库:

2.Linux.so(动态库).a(静态库) windows:dll .lib
静态库
我们所用到的Linux大部分指令都是用c语言写的
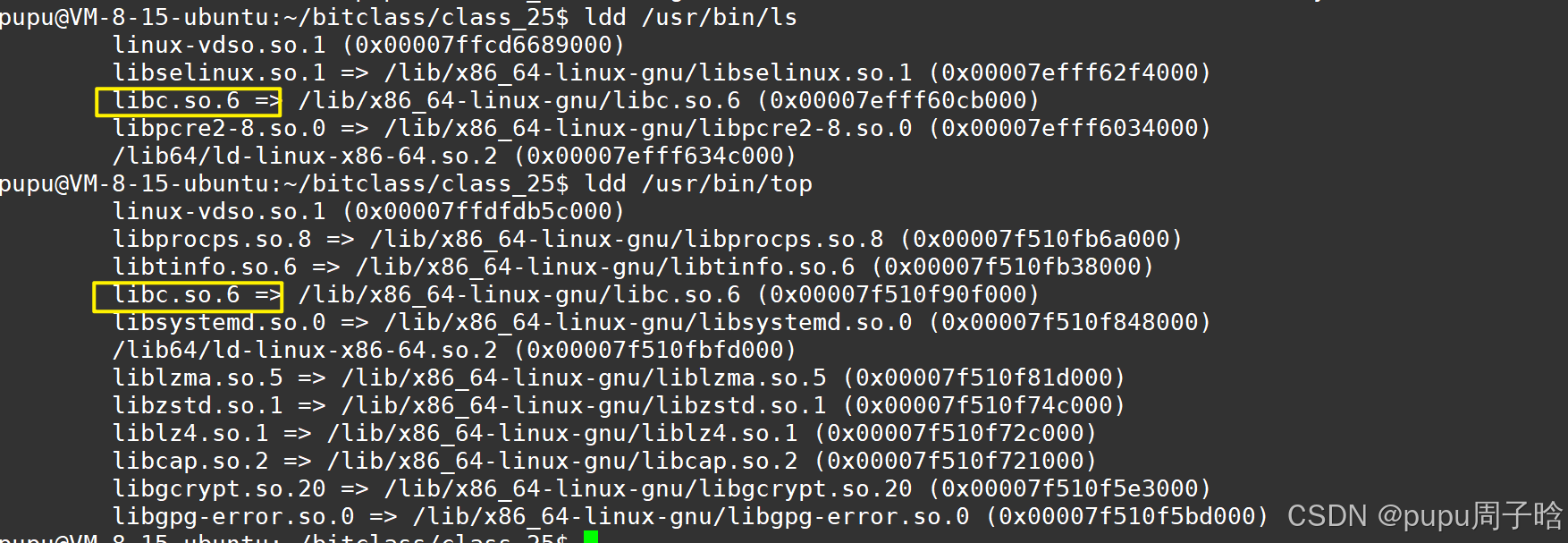
Linux:从文件操作到重定向与缓冲区的底层实现与实战-CSDN博客
如图我现在准备了一个之前写的标准库
mystdio.c
#include"mystdio.h" myFILE* my_fopen(const char *path, const char *flag) { int flag1 = 0; //标记位: int iscreate = 0; //文件的权限 mode_t mode = 0666; if(strcmp(flag, "r") == 0) { flag1 = (O_RDONLY); } else if(strcmp(flag, "w") == 0) { flag1 = (O_WRONLY | O_CREAT | O_TRUNC); iscreate = 1; } else if(strcmp(flag, "a") == 0) { flag1 = (O_WRONLY | O_CREAT | O_APPEND); iscreate = 1; } else {} int fd = 0; if(iscreate) fd = open(path, flag1, mode); else fd = open(path,flag1); if(fd < 0) return NULL; myFILE *fp = (myFILE*)malloc(sizeof(myFILE)); if(!fp) return NULL; fp->fileno = fd; fp->flags = FFLUSH_LINE; fp->cap = LINE_SIZE; fp->pos = 0; return fp; } void my_fflush(myFILE *fp) { write(fp->fileno, fp->cache, fp->pos); fp->pos = 0; } ssize_t my_fwrite(myFILE *fp, const char *data, int len) { //写入操作本质是拷贝,如果条件允许,就刷新,否则不做刷新 memcpy(fp->cache+fp->pos, data, len); //肯定要考虑越界,自动扩容 fp->pos += len; if((fp->flags&FFLUSH_LINE) && fp->cache[fp->pos-1] =='\n') { my_fflush(fp); } return len; } void my_fclose(myFILE *fp) { my_fflush(fp); close(fp->fileno); free(fp); }mystdio.h
#pragma once #include<string.h> #include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> #include<stdlib.h> #include<unistd.h> #define FFLUSH_NOW 1 #define FFLUSH_LINE 2 #define FFLUSH_FULL 4 #define LINE_SIZE 1024 struct _myFILE { unsigned int flags; int fileno;//文件描述符 //缓冲区 char cache[LINE_SIZE]; int cap;//总容量 int pos;//下次写入的位置 }; typedef struct _myFILE myFILE; myFILE* my_fopen(const char *path, const char *flag); void my_fflush(myFILE *fp); ssize_t my_fwrite(myFILE *fp, const char *data, int len); void my_fclose(myFILE *fp);再准备个简单math库
mymath.h
#pragma once int myAdd(int, int); int mySub(int, int);mymath.c
#include"mymath.h" int myAdd(int x, int y) { return x + y; } int mySub(int x, int y) { return x-y; }现在我们有两套方法,一对是与io相关的,一对是与数学相关的
如图:Linux基础 - yum、rzsz、vim 使用与配置、gcc/g++的详细解说以及预处理、编译、汇编、链接的详细步骤ESc 、iso_yum rzsz-CSDN博客详细可以看这个博客对于预处理编译汇编链接的说明解释
变成.o就是所有方法的实现:gcc -c
gcc -c mymath.c gcc -c mystdio.c
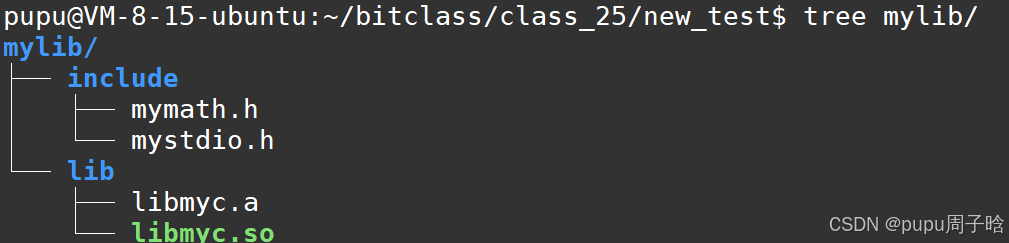
将这两个形成.o的文件以及.h文件放进另一个目录:
此时应该怎么运行这些程序呢?
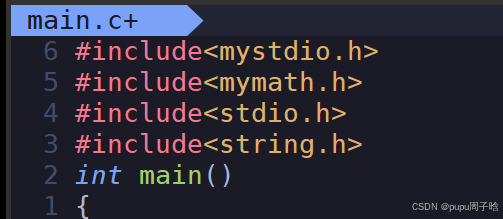
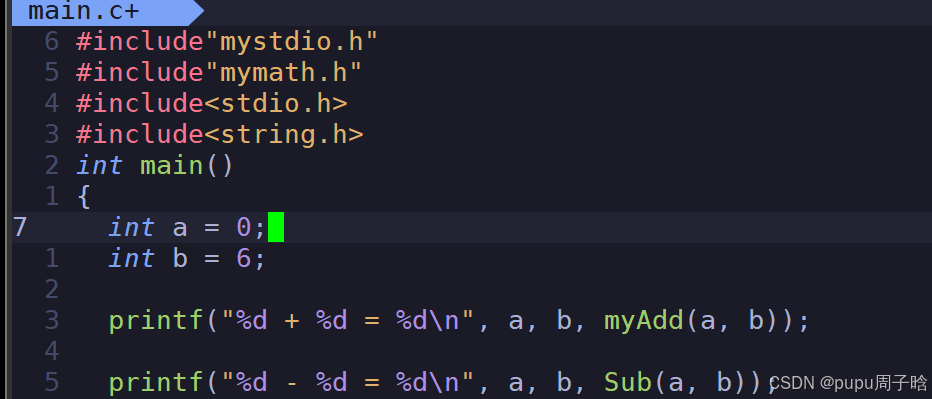
再写一个main函数;
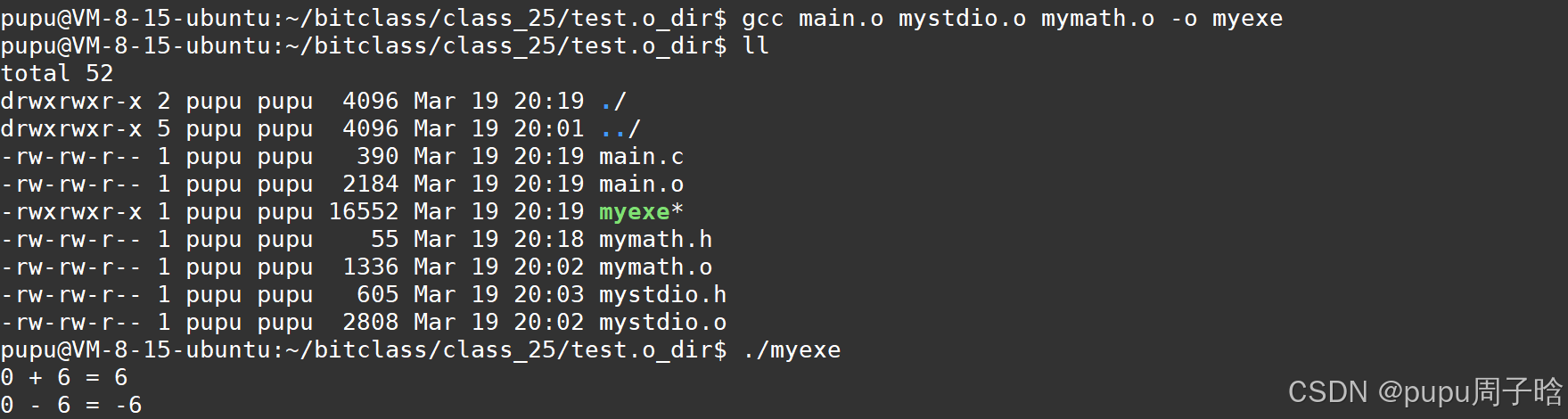
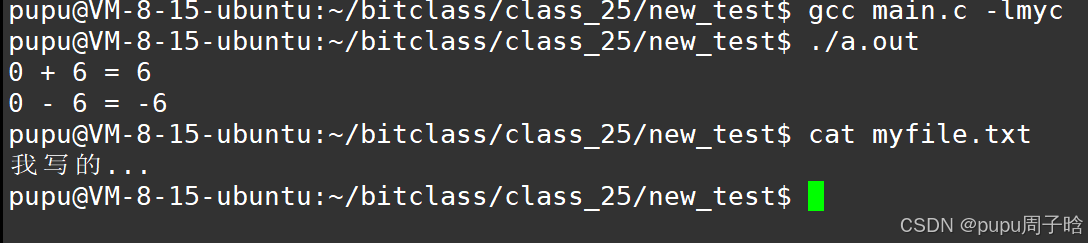
#include"mystdio.h" #include"mymath.h" #include<stdio.h> #include<string.h> int main() { int a = 0; int b = 6; printf("%d + %d = %d\n", a, b, myAdd(a, b)); printf("%d - %d = %d\n", a, b, mySub(a, b)); myFILE *fp = my_fopen("./myfile.txt", "w"); if(!fp) return 1; const char *msg = "我写的...\n"; my_fwrite(fp, msg, strlen(msg)); my_fclose(fp); return 0; }此时直接编译是无法编译通过的;
将main.c也编译成.o后再将所有文件一起编译成可执行文件myexe
gcc main.o mystdio.o mymath.o -o myexe
并且形成了我的文件myfile.txt
因此将一个程序变成一个可执行程序,可以只需要头文件以及方法的实现.o




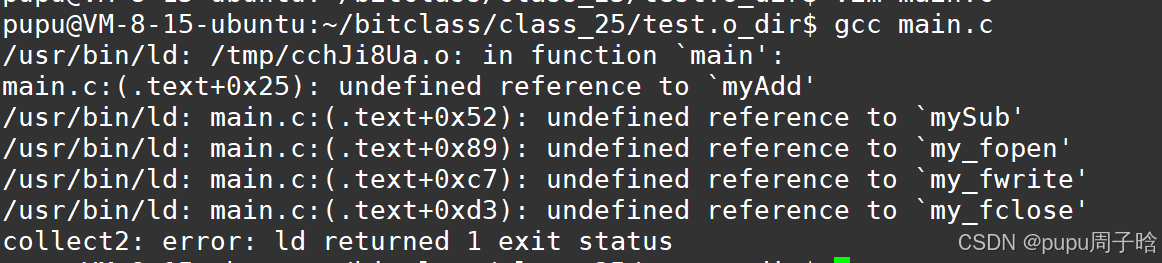
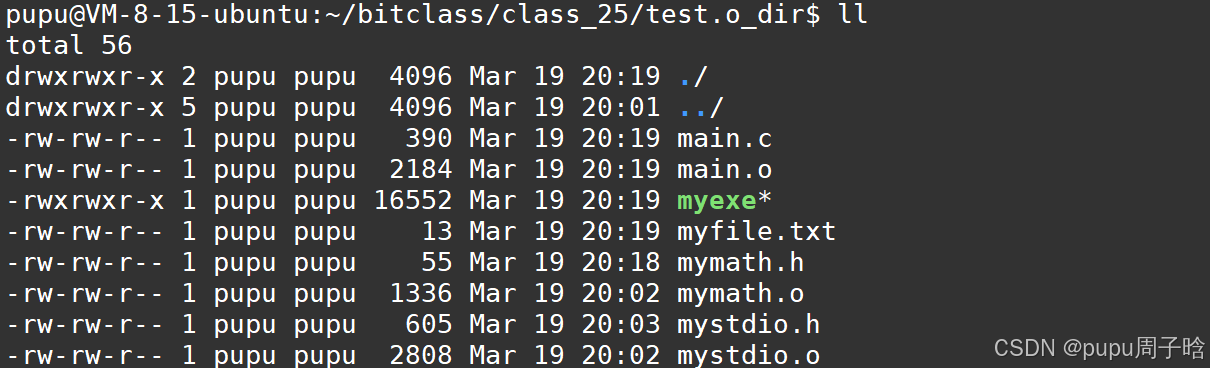
头文件就是一个手册,提供函数的声明,告诉用户怎么使用
.o文件提供实现,只需要补上一个main函数,调用头文件所提供的方法,然后和.o进行链接,就能形成可执行程序
这种办法,需要的.o文件太多,如果误删了一个就会导致程序无法跑起来:
使用命令:ar -rc ---> r--->replace ----》c ----> create,将.o文件形成静态库,ar是gnu归档工具
将所有的.o文件,形成一个libmyc.a的文件
ar -rc libmyc.a *.o
再直接编译:运行成功

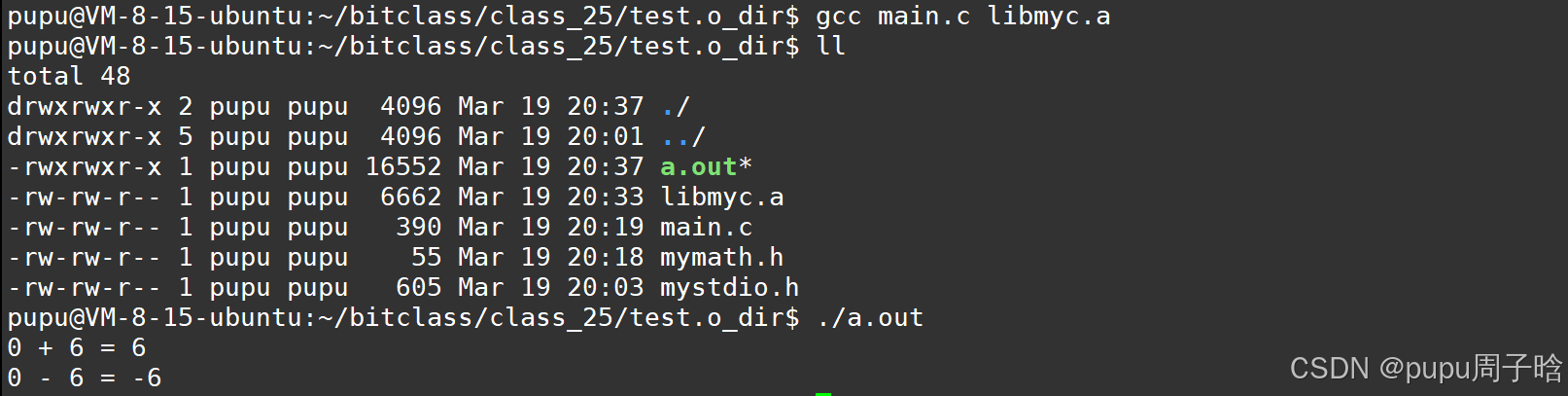

所谓的库文件:本质就是把.o打包形成.a静态库,用于提高开发效率
库的名字一般是:
lib开头中间myc才是库真正的名字.a是静态库的后缀
所谓的库:
1.给别人提供头文件(告诉怎么用)
2.给别人提供静态库(帮助实现)
如图:
相当于给别人形成了头文件和库文件
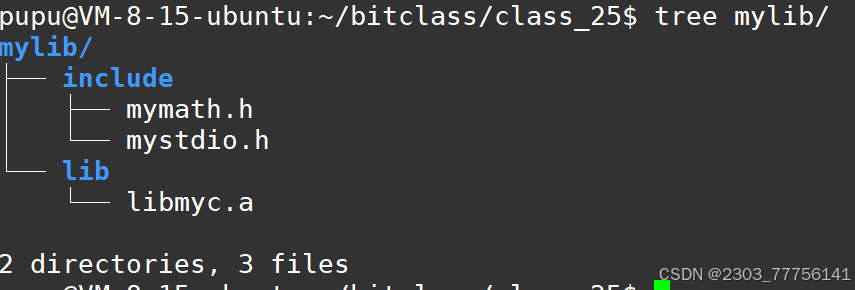
当我们有一个main.c函数:
此时也将库拷贝了过来:
在我们使用库的时候,都是将库安装到本地了的,这里也是如此需要一个安装
此时就可以删除掉mylib(相当于安装包)

在路径下以及安装好
此时就可以将我们所写的头文件当做是系统头文件来使用:
不能使用:
这是因为:C/C++的库,gcc/g++默认是认识C/C++的库,libmyc.a--->对于他们来说是别人写的(第三方提供) --> gcc/g++ 不认识:因此我们在编译的时候还需要一个选项 -l,是为了告诉编译器,不仅要链接C/C++的库,还要链接第三方库
gcc main.c -llibmyc.a上面的方法是错误的,
在链接时只需要链接我所写的库的真实名字也就是myc
gcc main.c -lmyc由此:运行成功


卸载掉一个库:


不安装如何直接使用:
gcc/g++一般只看自己库里的文件因此找不到我们的库
-I(大i) 能直接找到自己头文件
gcc main.c -I ./mylib/include/这里的原理是,gcc本身也是一个进程,在执行这条命令的时候会将自己的路径与./mylib/include/进行拼接,因此就找到了我们的头文件的路径
直接这么写:出现链接报错,但是实际上已经找到了我们的include
-L(link) 找到lib文件
gcc main.c -I ./mylib/include/ -L ./mylib/lib依旧有错
因为一个lib目录下可以有多个库,需要明确的告诉gcc要链接的库的名称
-l(小l) 跟库的真实名字:
gcc main.c -I ./mylib/include/ -L ./mylib/lib -lmyc运行结果:
头文件没有在路径里写的原因是因为在main.c函数已经写清楚了所要用到的头文件
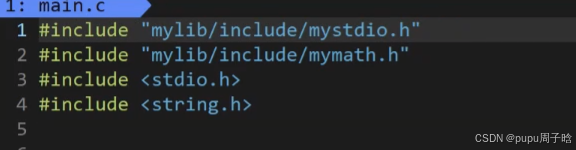
不在命令行写头文件路径的办法(不能写<>会默认在gcc/g++认识的库中去找)
运行结果:




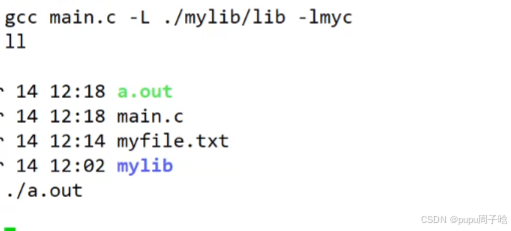
总结:

查看静态库中的目录列表
[root@localhost linux]# ar -tv libmymath.a
rw-r--r-- 0/0 1240 Sep 15 16:53 2017 add.o
rw-r--r-- 0/0 1240 Sep 15 16:53 2017 sub.o
t:列出静态库中的文件
v:verbose 详细信息
[root@localhost linux]# gcc main.c -L. -lmymath
-L 指定库路径-l 指定库名
测试目标文件生成后,静态库删掉,程序照样可以运行
动态库:
我们发现明明使用的有自己的库,但是ldd后并没有
因为在我的路径下只指明了一个静态库,只指明静态库的时候,形成可执行文件时,会进行动态链接,但是当前我的代码里没有动态库,因此编译器将我的程序在形成可执行文件的时候能动态链接的就动态链接了,无法动态链接的就将我的静态库要用到的已实现的方法局部的拷贝到我的这个程序里。

如果指明 -static,就会全部静态链接,没有指明的OS就优先使用动态库,再局部拷贝静态库代码。
通过以下文件制作动态库
生成动态库
- shared: 表示生成共享库格式
- fPIC:产生位置无关码(position independent code)
- 库名规则:libxxx.so
gcc -fPIC -
gcc -fPIC -c mymath.c
gcc -fPIC -c mystdio.c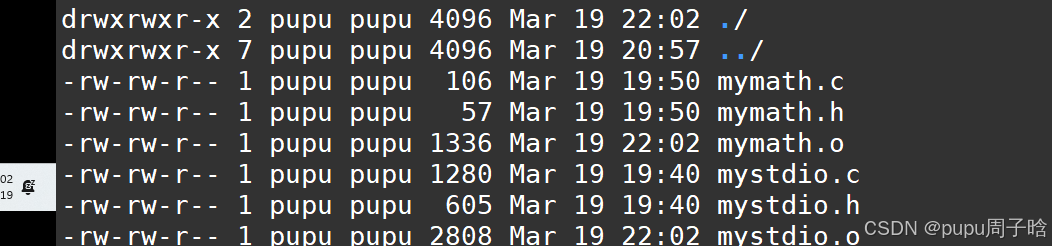
-shared
打包动态库,直接使用gcc 再将.o文件打包成以lib开头,真实名字myc放中间再.so结尾
gcc -shared *.o -o libmyc.so
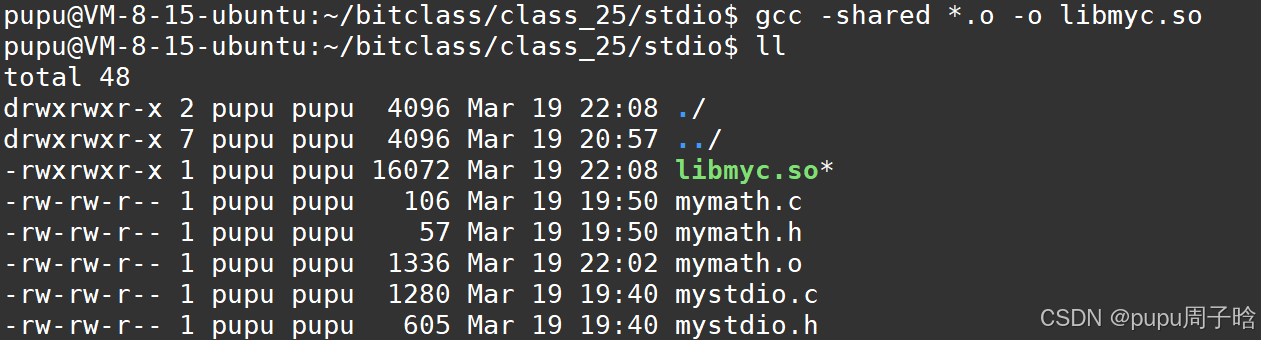
然后将动态库放到lib当中:
要提前将头文件改回来:
运行程序:./a.out,程序在运行时无法找到名为 libmyc.so 的动态链接库(shared library)

因为只告诉gcc/g++动态库的位置,但是OS不知道
因为动态库要在程序运行(./a.out)的时候,要找到动态库加载并运行。
静态库为什么没有这个问题,在编译期间,已经将库中的代码拷贝到我们的可执行程序内部了,加载的时候就和库没有关系了。
在进行程序运行时,OS会自动去找动态库,默认路径是:

方法1(不建议):将动态库直接拷贝到lib下:
sudo cp mylib/lib/libmyc.so /lib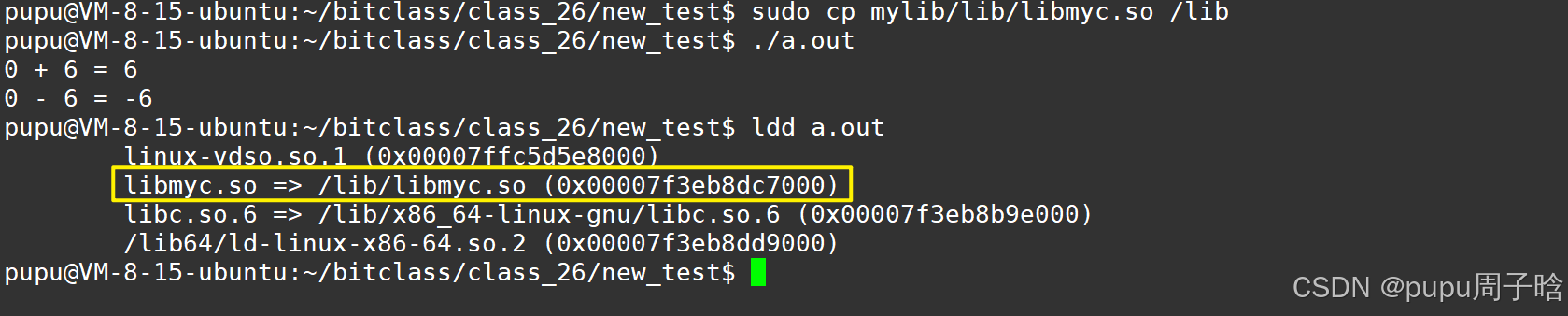
方法2:建立软链接
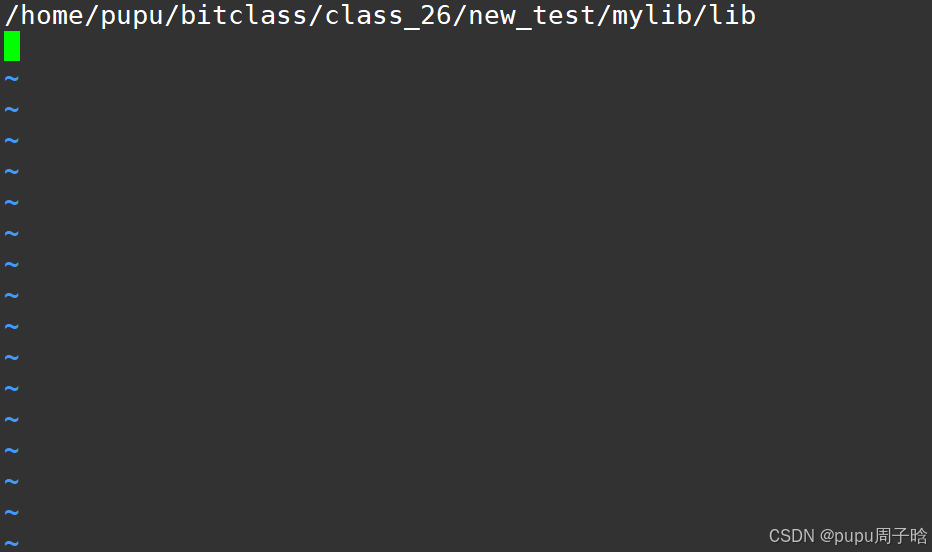
使用libmyc.so的绝对路径,在/lib下建立我们自己动态库的软链接libmyc.so
sudo ln -s /home/pupu/bitclass/class_26/new_test/mylib/lib/libmyc.so /lib/libmyc.so
找到了我们的动态库

方法3:使用环境变量LD_LIBRARY_PATH(加载库路径)
先删除掉刚刚的软链接
sudo unlink /lib/libmyc.so/home/pupu/bitclass/class_26/new_test/mylib/lib有可能你的这个库路径环境变量已经有值了:使用取值加:的方法在后面继续添加lib的绝对路径
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/pupu/bitclass/class_26/new_test/mylib/lib上面的办法不行:
export LD_LIBRARY_PATH=./mylib/lib:$LD_LIBRARY_PATH
以上都是临时有效(环境变量是内存级别的)


永久环境变量:直接在系统.bashrc文件中修改(不建议)
不建议,实际上直接使用软链接就行。如果保存了再进入删除掉使用source 再使配置生效:
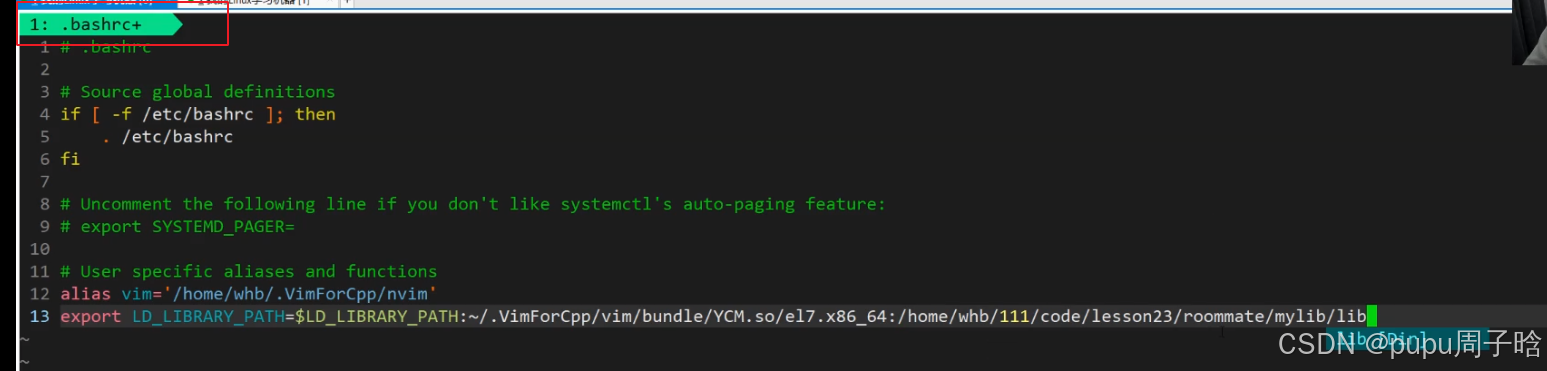

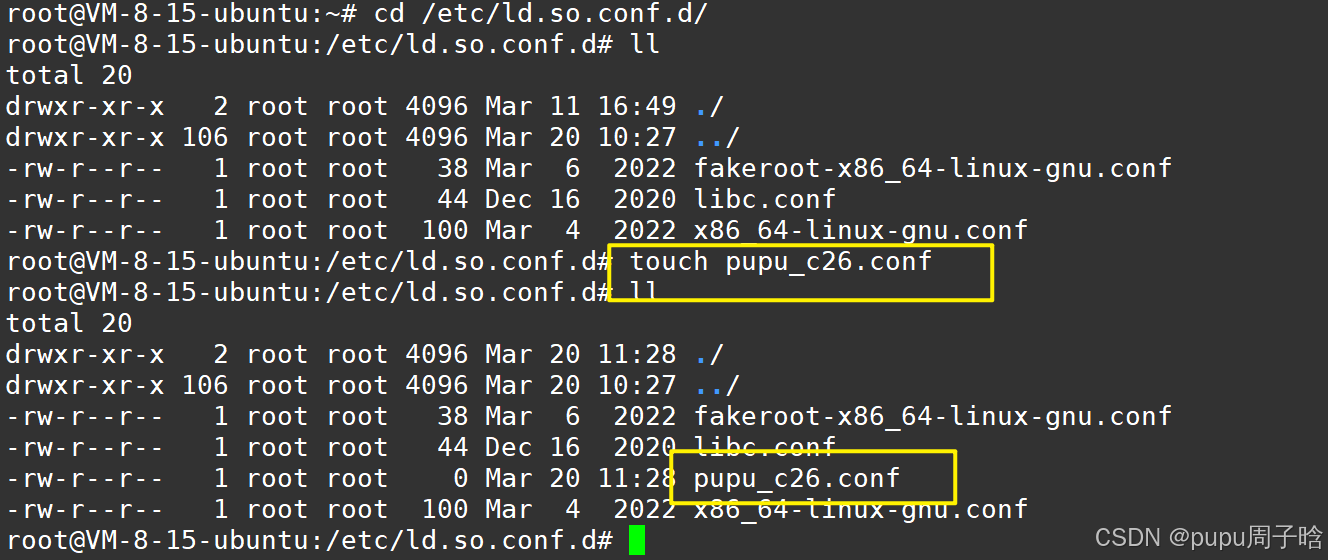
方法5: /etc/ld.so.conf.d/ 新增动态库搜索的配置文件,idconfi g使其生效
特别是ubuntu系统当中会存在一个配置文件包含:
实行方法:
切换到超级用户来执行
将我的库的绝对路径添加到配置文件当中,再在系统上加载一下,使配置永久生效
进入到系统配置文件目录下
cd /etc/ld.so.conf.d/创建一个属于自己的文件:
将我的动态库的绝对路径复制到该文件里面;
/home/pupu/bitclass/class_26/new_test/mylib/lib
保存并退出,并使配置文件生效,使用该命令:
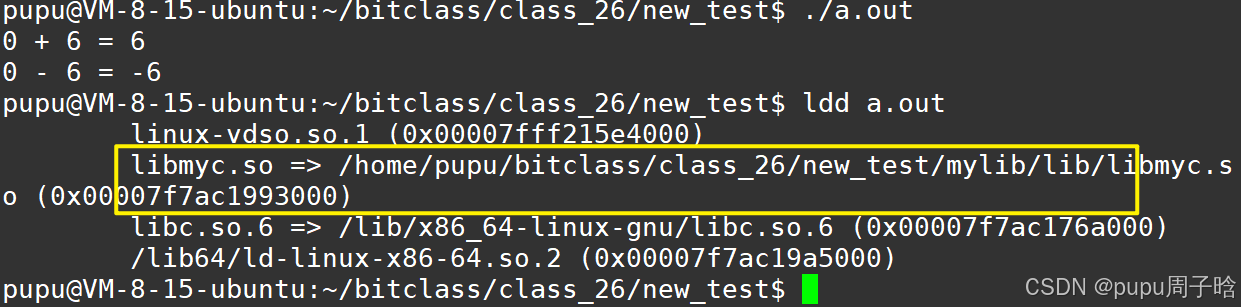
ldconfig再运行,变成功
或者:
将库路径添加到系统配置(永久生效) # 1. 创建配置文件 sudo sh -c "echo $(pwd)/mylib/lib >> /etc/ld.so.conf.d/mylib.conf" # 2. 更新库缓存 sudo ldconfig

当软硬链接同时存在,我们知道会自动选择使用动态库,当想要使用静态库在编译时就直接在后面添加:
-static
gcc main.c -I mylib/include/ -L mylib/lib/ -lmyc -static此时使用静态库编译出来的可执行文件会很大:

如果没有使用-static,并且只提供静态库,那就只能静态链接当前的.a库,其他库正常动态链接
-static的意义:必须强制的将我们的程序进行静态链接,这就要求我们链接的任何库都得提供对应的静态库版本。

因此,在我们使用别人的库的时候:别人应该给我们提供什么呢?
一批头文件 + 一批库文件(.so .a)
比如说这个ncurses库(可以做一个简单的终端,股市的走向,贪吃蛇。。。)
C语言实现简易文本编辑器(新手向) - 知乎

安装ncurses库:
sudo apt update
sudo apt install libncurses-dev检查是否安装成功:这里就会发现ncurses给我们提供了头文件以及一批库(动静态)
# 检查头文件
ls /usr/include/ncurses.h
# 检查动态库
ls /usr/lib/x86_64-linux-gnu/libncurses.so
# 检查静态库
ls /usr/lib/x86_64-linux-gnu/libncurses.a编译测试程序
创建一个测试文件 test.c:
#include <ncurses.h>
int main() {
initscr(); // 初始化 ncurses
printw("Hello, ncurses!"); // 输出字符串
refresh(); // 刷新屏幕
getch(); // 等待用户输入
endwin(); // 结束 ncurses
return 0;
}编译并运行:
gcc test.c -o test -lncurses
./test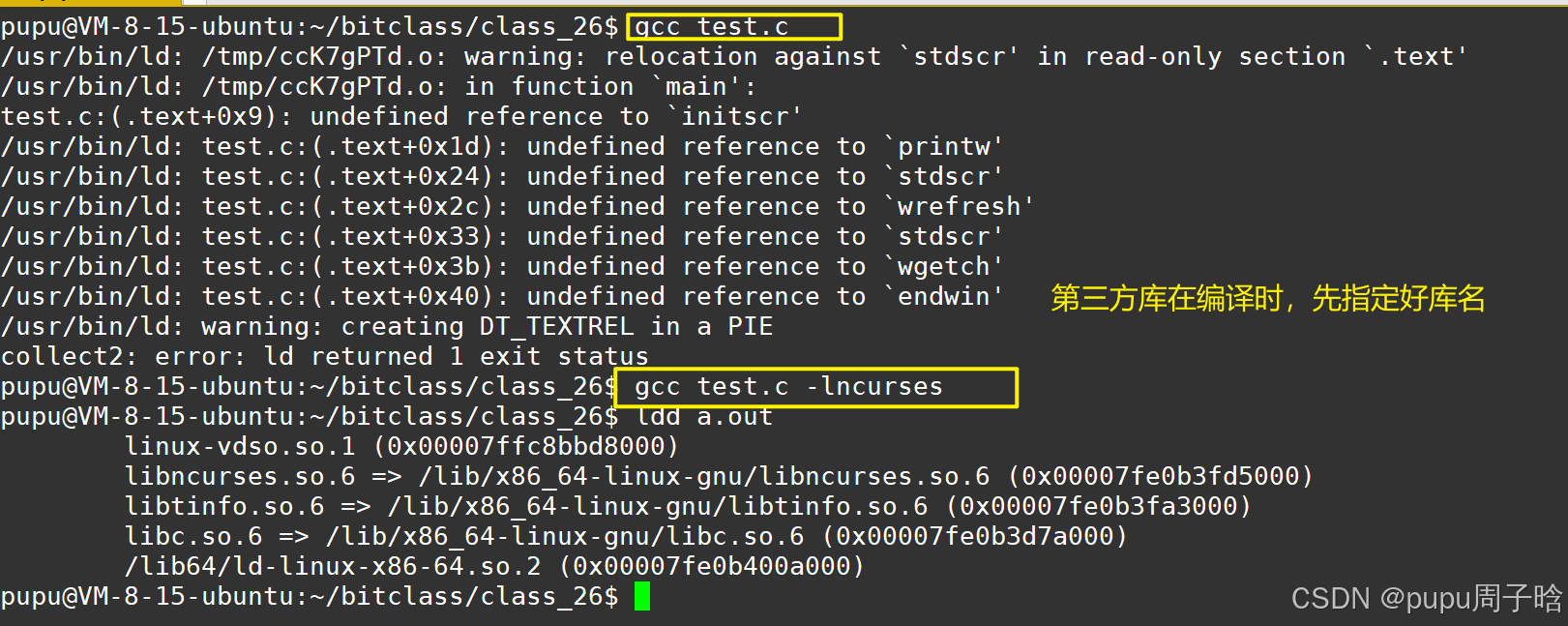
-
如果终端进入全屏并显示 "Hello, ncurses!",说明安装成功。
-

3. 常见问题
找不到
ncurses.h头文件
原因:未安装
libncurses-dev。解决:重新执行
sudo apt install libncurses-dev。链接错误:
undefined reference to 'initscr'
原因:编译时未链接
ncurses库。解决:在编译命令末尾添加
-lncurses。
附加问题:动态库(共享库)是如何加载的 --- 可执行程序和地址空间
(不用考虑静态库因为静态库在编译时已经将内容存在到a.out内了)
库也要经过页表被加载到映射到共享区当中,因此共享区通过页表的映射在内核内存当中找到动态库,在调用myAdd的时候,跳转到地址空间的共享区上再返回到正文代码就可以了:
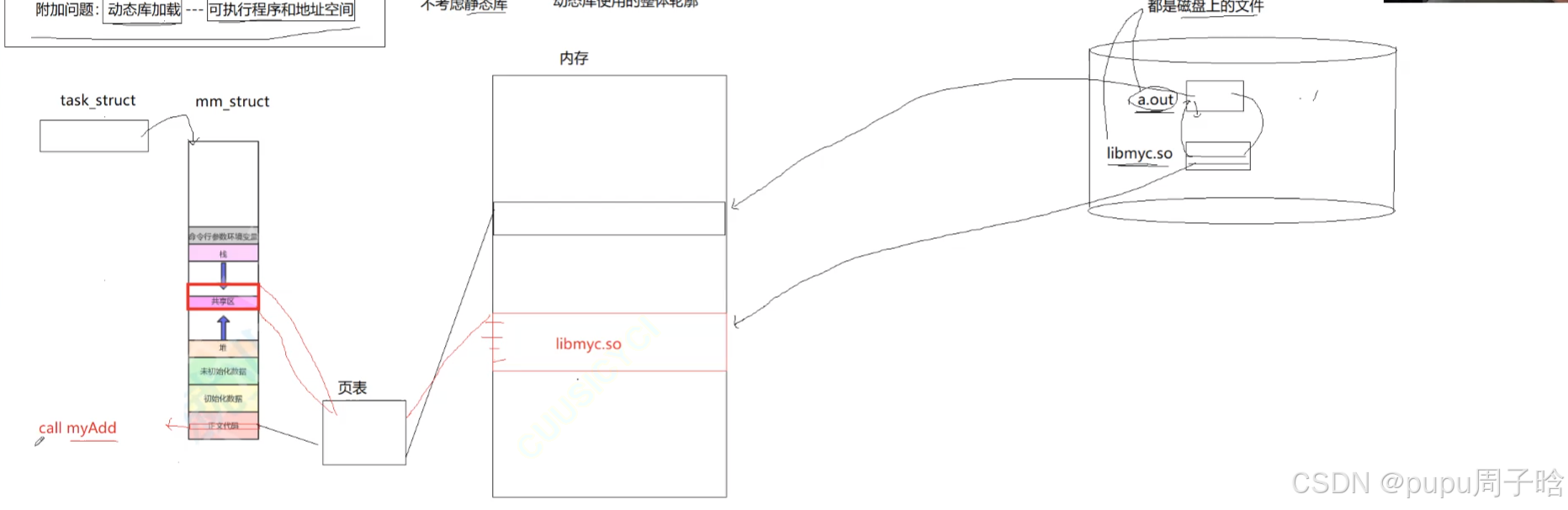
动态库在加载之后,要映射到当前进程的堆栈之间的共享区。一个在共享区的库可以被多个进程使用,将内存里的动态库通过页表映射到每个进程的堆栈之间,就能实现代码级别的共享。
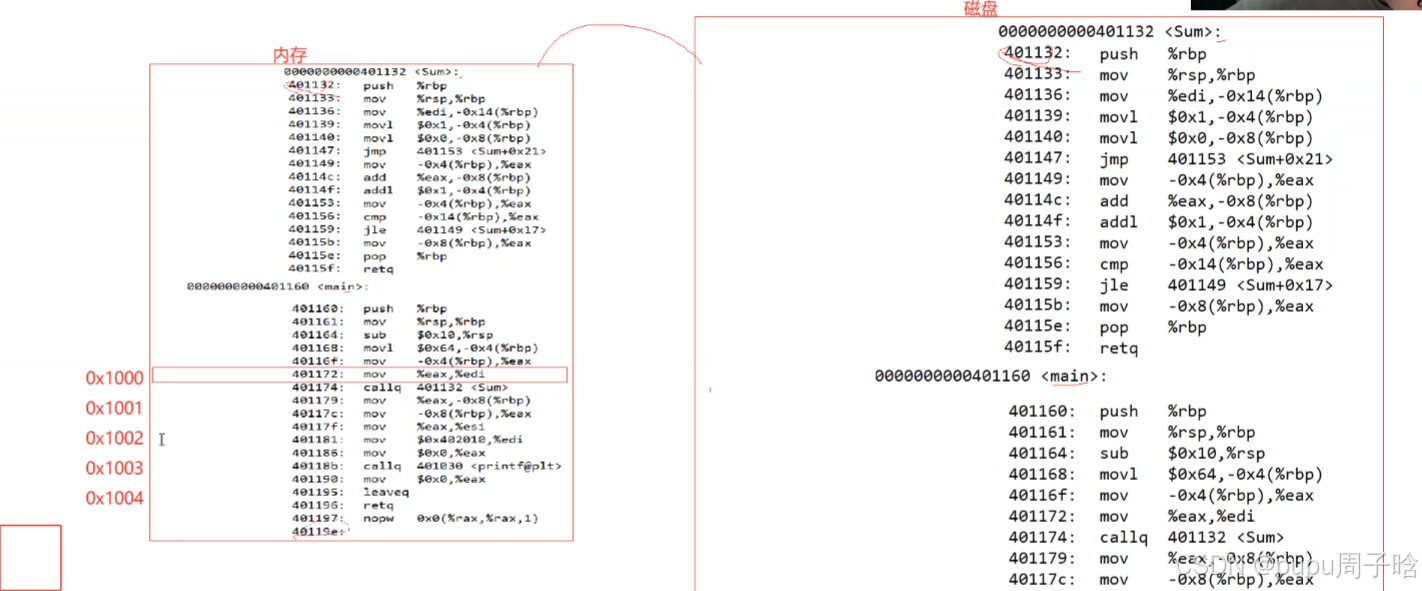
我们的可执行程序,编译成功,没有加载运行,二进制代码中有“地址”吗? 有
提供一个简单代码:
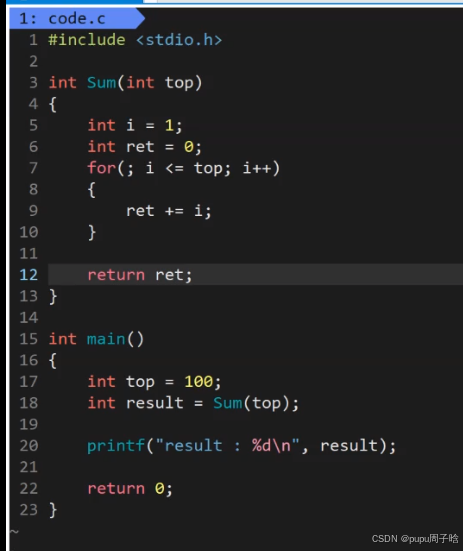
将可执行程序直接反汇编:
objdump -S code > code.svim code.s
我们形成的可执行程序编译后内部是包含函数地址的,调用的时候就是直接调用地址,代码进行编码过后,代码都形成地址。
并且可执行程序已经分好了对应的区

我们直接看源代码,不用加载运行,就可以在大脑中运行这个程序
 形成ELF格式可执行程序的时候,二进制是有自己的固定格式的,elf可执行程序的头部,有可执行程序的属性,可执行程序编译之后,会变成很多行汇编语句,每条汇编语句都有它的地址。我们可以认为这些地址都是虚拟地址
形成ELF格式可执行程序的时候,二进制是有自己的固定格式的,elf可执行程序的头部,有可执行程序的属性,可执行程序编译之后,会变成很多行汇编语句,每条汇编语句都有它的地址。我们可以认为这些地址都是虚拟地址
ELF + 加载器:各个区域的起始和结束地址,main函数的入口地址
一个进程都是先有他的内核数据结构,再加载代码和数据
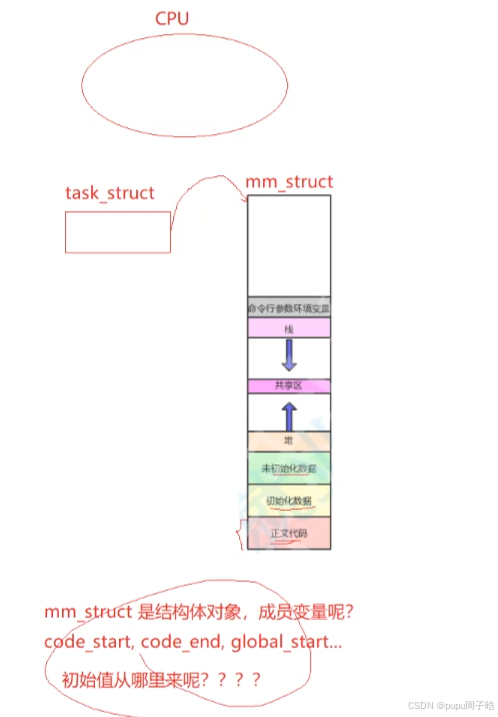
虚拟地址中的数据都是:通过可执行程序的头部信息来初始化这些对象、变量。
当可执行代码被从磁盘拿到内存,内存也有物理地址,对于每行代码来说,有两个地址,在内存的物理地址,和虚拟地址:
在要执行的时候,拿内存的物理地址构建页表的右侧,代码的虚拟地址构建页表的左侧。
cpu就开始运行了,通过pc指针,根据虚拟地址找到内存物理地址。读取到指令,识别到代码区中。
库实际上也是类似的原理
最后就是库的起始虚拟地址加上偏移量就能找到库中的方法的虚拟地址以实现函数调用
库被映射到虚拟地址空间的什么位置都不重要,因为找方法需要的是库的起始地址+不变的偏移量。
库函数调用,其实也是在我的地址空间返回来回跳转
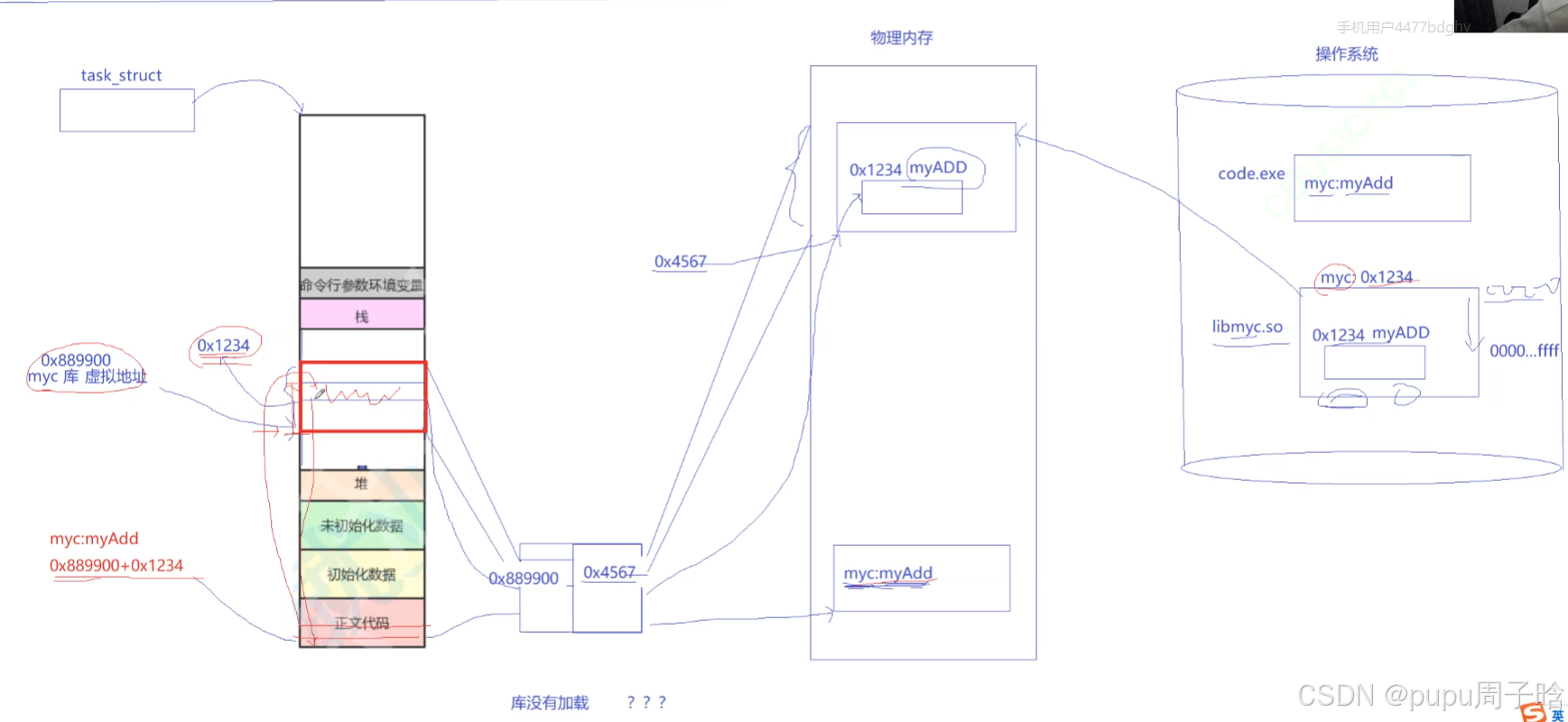
操作系统会怎么去管理已经被加载的库(可以同时有多个库被加载)呢?
先描述再组织:
也会有对应的描述结构体(多个库链接器起来)
因此在形成动态库最重要的一环是 -fPIC,使动态库能够被独立加载,和可执行程序没有关系,不能被拷贝到可执行程序当中,自己成为一个可执行程序一般也要做完全编址,在物理空间当中任意加载,地址空间当中任意映射这样的代码逻辑
一、动态库加载的核心流程
1. 编译时链接(静态链接阶段)
目的:记录依赖关系,但不将库代码嵌入可执行文件。
过程:
头文件声明:代码中通过
#include引入库的头文件(如#include <stdio.h>)。符号引用:编译器生成对库函数(如
printf)的未解析引用(符号)。链接器操作:
- 使用
-l指定库名(如-lm链接数学库)。- 链接器在
-L指定路径和系统默认路径(如/usr/lib)中查找.so文件。- 生成可执行文件时,记录动态库的依赖信息(如
DT_NEEDED条目)。2. 运行时加载(动态链接阶段)
目的:在程序启动时或运行时动态加载库并解析符号。
过程:
加载可执行文件:操作系统读取可执行文件的头部信息,识别动态链接器路径(如
/lib64/ld-linux-x86-64.so.2)。启动动态链接器:由动态链接器(
ld.so或ld-linux.so)接管后续加载流程。解析依赖库:
根据可执行文件的
DT_NEEDED条目,递归加载所有依赖的动态库。搜索路径包括:
LD_LIBRARY_PATH环境变量指定的路径。/etc/ld.so.cache缓存中的路径(由/etc/ld.so.conf配置)。- 默认系统路径(如
/usr/lib、/lib)。
符号绑定:
立即绑定:在加载时解析所有符号(较少用)。
延迟绑定(PLT/GOT):通过 过程链接表(PLT) 和 全局偏移表(GOT),在函数首次调用时解析符号(默认方式)。
重定位:调整库中的地址偏移,使其在进程地址空间中正确定位。
结语:
随着这篇关于题目解析的博客接近尾声,我衷心希望我所分享的内容能为你带来一些启发和帮助。学习和理解的过程往往充满挑战,但正是这些挑战让我们不断成长和进步。我在准备这篇文章时,也深刻体会到了学习与分享的乐趣。
在此,我要特别感谢每一位阅读到这里的你。是你的关注和支持,给予了我持续写作和分享的动力。我深知,无论我在某个领域有多少见解,都离不开大家的鼓励与指正。因此,如果你在阅读过程中有任何疑问、建议或是发现了文章中的不足之处,都欢迎你慷慨赐教。
你的每一条反馈都是我前进路上的宝贵财富。同时,我也非常期待能够得到你的点赞、收藏,关注这将是对我莫大的支持和鼓励。当然,我更期待的是能够持续为你带来有价值的内容,让我们在知识的道路上共同前行。
