【回归算法解析系列12】分位数回归(Quantile Regression)
【回归算法解析系列】分位数回归(Quantile Regression)
1. 分位数回归:超越均值预测的回归方法
在数据科学的广阔领域中,回归分析是探索变量之间关系的重要工具。然而,传统的基于均值的回归方法,如普通最小二乘法(OLS)回归,往往只能提供变量关系的平均趋势信息。分位数回归(Quantile Regression)作为一种创新的回归方法,打破了这一局限,通过估计条件分位数,为我们展现了数据背后更为丰富的信息,具有不可忽视的核心价值。
1.1 核心价值
- 全分布视角:分位数回归能够揭示变量关系在不同分位点的差异。传统回归关注的是因变量的均值与自变量的关系,而分位数回归可以让我们了解在不同的分位点(例如,第10百分位、第50百分位、第90百分位等)上,自变量对因变量的影响。这就好比我们在研究员工薪资与工作经验的关系时,普通回归只能告诉我们平均来说工作经验如何影响薪资,但分位数回归可以进一步揭示低薪、中等薪资和高薪群体中,工作经验对薪资的不同影响模式,帮助我们更全面地理解数据分布特征。
- 异常值鲁棒性:在实际数据中,异常值的存在常常会干扰回归模型的准确性。基于均值的回归方法对极端值较为敏感,一个或几个异常值可能会显著影响模型的参数估计和预测结果。而分位数回归对极端值的敏感度低于基于均值的回归。以房价数据为例,少数价格极高的豪宅作为异常值,在普通回归中可能会拉高整体房价的均值,从而影响对一般房价趋势的判断。但分位数回归通过特定的损失函数设计,能够在一定程度上减少这些异常值的干扰,更稳健地反映数据的真实特征。
- 预测区间估计:分位数回归可以直接输出任意置信度的预测区间。在实际应用中,我们不仅关心预测的点估计值,更关注预测的可靠性。分位数回归通过估计不同分位点的数值,为我们提供了构建预测区间的便利。比如在预测股票价格走势时,我们可以利用分位数回归得到不同置信水平下的价格区间,这对于投资者制定合理的投资策略具有重要意义。
1.2 适用场景
- 金融风险价值(VaR)计算:在金融领域,风险价值(VaR)是衡量投资组合在一定置信水平下可能遭受的最大损失的重要指标。分位数回归能够直接估计特定分位点的数值,这与VaR的计算需求高度契合。通过分位数回归,金融分析师可以更准确地评估投资组合的风险水平,为风险管理提供有力支持。
- 医疗费用分布预测:医疗费用的分布往往呈现出复杂的形态,不同患者的费用差异较大。分位数回归可以帮助我们了解不同分位点上医疗费用与各种因素(如年龄、疾病类型、治疗方式等)之间的关系,从而更全面地预测医疗费用的分布情况,为医疗资源的合理分配和保险定价提供依据。
- 需要关注极端值的工业质量控制:在工业生产中,产品质量的极端值可能会对生产过程和产品性能产生重大影响。分位数回归能够帮助工程师关注到产品质量指标在不同分位点的变化情况,及时发现可能出现的质量问题,尤其是极端质量情况,从而采取相应的措施进行质量控制和改进。
2. 数学原理:非对称损失函数与优化
2.1 分位数损失函数(Quantile Loss)
分位数回归的核心是其独特的分位数损失函数。对于τ分位数,损失函数定义如下:
[
L_\tau(y, \hat{y}) =
\begin{cases}
\tau |y - \hat{y}| & \text{if } y \geq \hat{y} \
(1-\tau) |y - \hat{y}| & \text{otherwise}
\end{cases}
]
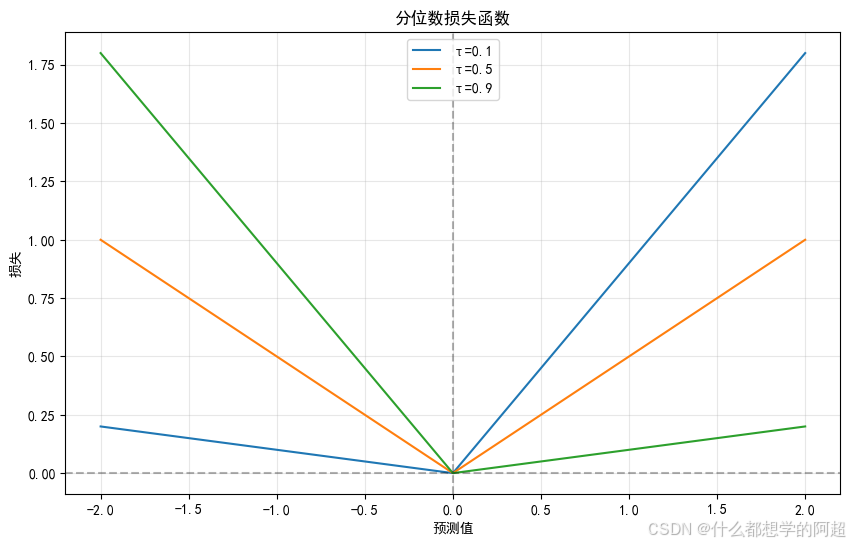
这个损失函数具有非对称性,τ的取值决定了对不同误差方向的惩罚程度。当τ = 0.5时,该损失函数等价于平均绝对误差(MAE)损失,此时分位数回归对应中位数回归。中位数回归对于异常值的鲁棒性较强,因为它只关注数据的中间位置,不受极端值的过度影响。为了更直观地理解这个损失函数,我们可以通过一个简单的示例来展示。假设有一组数据点,真实值 ( y ) 分别为[1, 2, 3, 4, 5],预测值 ( \hat{y} ) 为3。当τ = 0.3时,对于 ( y = 1 ) 和 ( y = 2 ),损失为 ( (1 - 0.3) \times |y - \hat{y}| );对于 ( y = 4 ) 和 ( y = 5 ),损失为 ( 0.3 \times |y - \hat{y}| )。从这个示例可以看出,损失函数根据 ( y ) 与 ( \hat{y} ) 的大小关系以及τ的值,对误差进行了不同程度的惩罚。
2.2 参数估计
对于线性模型 ( \hat{y} = \mathbf{x}^T \beta ),分位数回归的目标是求解参数 ( \beta ),使得损失函数最小化,即:
[
\hat{\beta}\tau = \arg\min{\beta} \sum_{i = 1}^n L_\tau(y_i, \mathbf{x}_i^T \beta)
]
在实际计算中,常用的优化方法包括线性规划或迭代加权最小二乘(IRLS)。线性规划通过在满足一系列约束条件下,最大化或最小化目标函数,能够有效地求解分位数回归的参数。迭代加权最小二乘法则是一种迭代算法,通过不断调整权重,逐步逼近最优解。这两种方法各有优缺点,在不同的数据规模和问题复杂度下,可以选择合适的方法进行参数估计。
3. 代码实战:医疗费用预测
3.1 数据预处理
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# 加载医疗费用数据集(来源:Kaggle)
data = pd.read_csv("insurance.csv")
data['smoker'] = data['smoker'].map({'yes':1, 'no':0})
data = pd.get_dummies(data, columns=['region','sex'])
# 对数变换应对右偏分布
data['log_charges'] = np.log1p(data['charges'])
# 划分特征与目标
X = data.drop(['charges', 'log_charges'], axis = 1)
y = data['log_charges']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
在这个案例中,我们使用来自Kaggle的医疗费用数据集进行分析。首先,对数据集中的分类变量进行编码,将“smoker”变量映射为数值型,同时使用get_dummies函数对“region”和“sex”进行独热编码。由于医疗费用数据通常呈现右偏分布,为了使数据更符合正态分布的假设,提高模型的拟合效果,我们对“charges”进行对数变换,得到“log_charges”。最后,将数据集划分为训练集和测试集,用于后续的模型训练和评估。
3.2 训练分位数回归模型
import statsmodels.api as sm
# 训练多个分位数模型
quantiles = [0.1, 0.5, 0.9]
models = {}
for q in quantiles:
model = sm.QuantReg(y_train, X_train)
result = model.fit(q = q, max_iter = 1000)
models[q] = result
print(f"τ={q}模型参数:\n{result.params}\n")
我们使用statsmodels库中的QuantReg类来训练分位数回归模型。在这个过程中,我们选择了三个不同的分位数(0.1、0.5和0.9)进行模型训练。通过循环遍历这些分位数,分别构建并训练模型,并输出每个模型的参数估计结果。这些参数反映了在不同分位点上,各个自变量对因变量(对数医疗费用)的影响程度。
3.3 预测结果可视化
import matplotlib.pyplot as plt
# 生成样本预测
X_pred = X_test.copy()
X_pred['age'] = np.linspace(18, 65, 100) # 固定其他特征,观察年龄影响
preds = {q: models[q].predict(X_pred) for q in quantiles}
# 绘制分位数回归曲线
plt.figure(figsize = (10, 6))
plt.scatter(data['age'], data['log_charges'], alpha = 0.3, label = '原始数据')
for q in quantiles:
plt.plot(X_pred['age'], preds[q],
label = f'τ={q}', linewidth = 2)
plt.xlabel('年龄')
plt.ylabel('对数医疗费用')
plt.title('分位数回归:年龄与医疗费用的关系')
plt.legend()
plt.show()
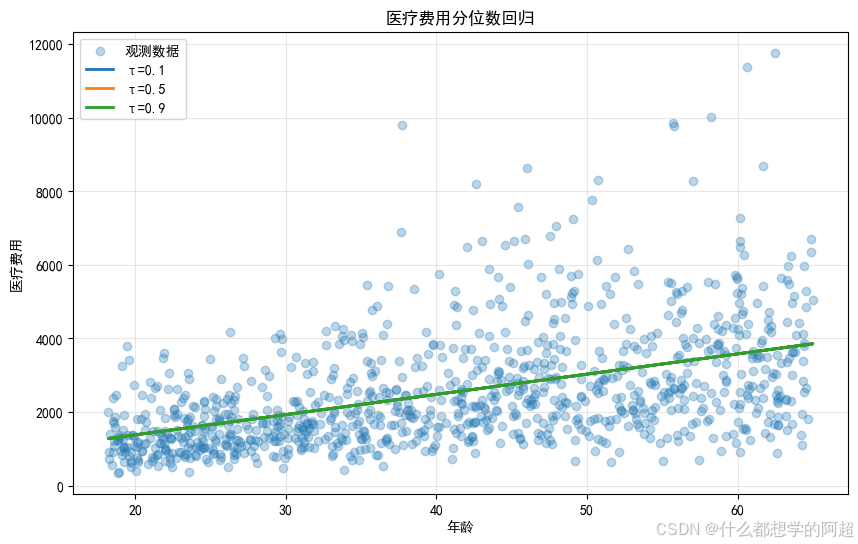
为了直观地展示分位数回归的结果,我们固定其他特征,仅改变“age”特征的值,生成预测数据。然后,使用训练好的模型对这些数据进行预测,并绘制不同分位数下的回归曲线。从图中可以清晰地看到,不同分位数的曲线呈现出不同的趋势,反映了年龄对医疗费用在不同分位点上的影响差异。例如,在低医疗费用群体(τ = 0.1)中,年龄的增长对医疗费用的影响相对较小;而在高医疗费用群体(τ = 0.9)中,年龄的增长可能会导致医疗费用有更明显的上升趋势。
4. 应用案例:金融风险价值(VaR)计算
4.1 数据准备(股票收益率)
import yfinance as yf
# 获取标普500指数数据
sp500 = yf.download('^GSPC', start='2018-01-01', end='2023-01-01')
returns = sp500['Close'].pct_change().dropna() * 100 # 百分比收益率
# 构建特征:滞后收益率
lags = 5
for i in range(1, lags + 1):
returns[f'lag_{i}'] = returns['returns'].shift(i)
returns = returns.dropna()
在金融风险价值(VaR)计算的应用案例中,我们首先使用yfinance库获取标普500指数在2018年1月1日至2023年1月1日期间的收盘价数据。通过计算收盘价的百分比收益率,得到收益率序列。为了构建预测模型,我们引入滞后收益率作为特征,即过去几天的收益率。这里我们选择了过去5天的收益率作为滞后特征,通过shift函数实现,并最终删除含有缺失值的数据行。
4.2 计算5% VaR
# 训练τ=0.05分位数模型
model_var = sm.QuantReg(returns['returns'], returns.drop('returns', axis = 1))
result_var = model_var.fit(q = 0.05)
# 预测未来一天VaR
last_data = returns.iloc[-1:].drop('returns', axis = 1)
var_5 = result_var.predict(last_data).values[0]
print(f"次日5% VaR预测值: {var_5:.2f}%")
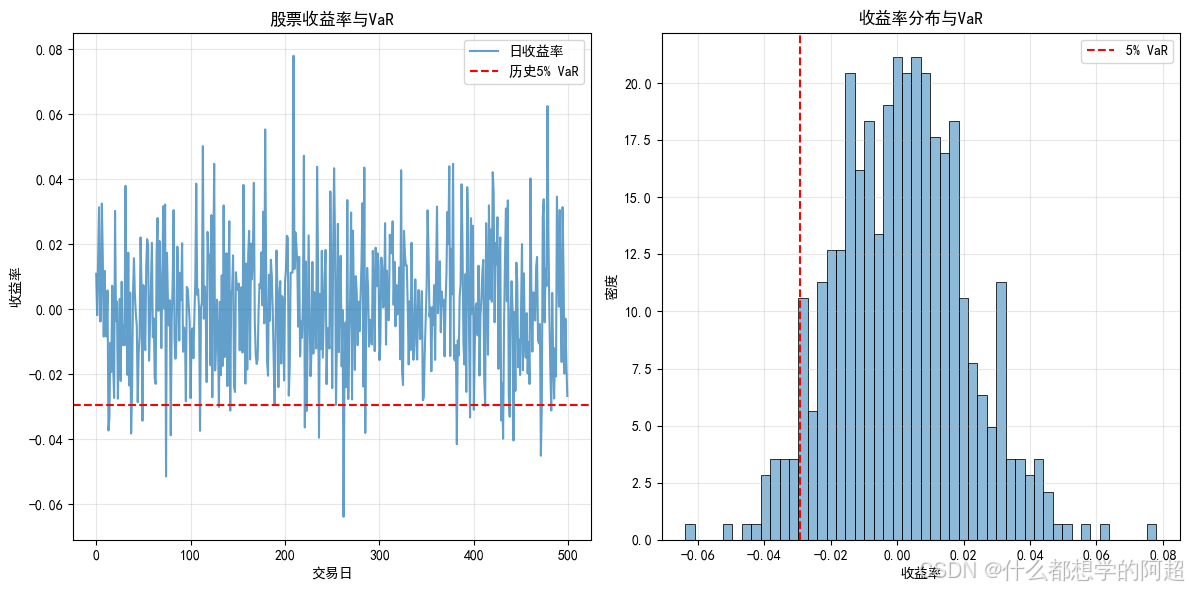
我们使用分位数回归来计算5%的VaR。具体来说,训练一个τ = 0.05的分位数回归模型,以滞后收益率为自变量,当前收益率为因变量。训练完成后,使用模型对最后一天的数据进行预测,得到次日5% VaR的预测值。这个预测值表示在95%的置信水平下,标普500指数次日可能的最大损失率。
5. 与传统回归的对比分析
| 维度 | 分位数回归 | OLS回归 |
|---|---|---|
| 损失函数 | 非对称(τ控制) | 对称(MSE) |
| 输出信息 | 条件分位数曲线 | 条件均值 |
| 异常值敏感度 | 低(τ接近0或1时) | 高 |
| 计算复杂度 | 高(需求解线性规划) | 低(解析解) |
| 应用场景 | 风险分析、费用预测、异方差数据 | 均值趋势分析、简单预测 |
分位数回归与传统的OLS回归在多个方面存在差异。从损失函数来看,分位数回归的损失函数是非对称的,通过调整τ的值可以灵活控制对不同误差方向的惩罚程度;而OLS回归使用的是对称的均方误差(MSE)损失函数,对误差的处理较为平均。在输出信息方面,分位数回归提供的是条件分位数曲线,能够展示变量关系在不同分位点的特征;OLS回归则主要输出条件均值。对于异常值敏感度,分位数回归在τ接近0或1时对异常值的敏感度较低,能够更稳健地处理数据;而OLS回归对异常值较为敏感。计算复杂度上,分位数回归通常需求解线性规划,计算复杂度较高;OLS回归则有解析解,计算相对简单。在应用场景上,分位数回归更适用于风险分析、费用预测以及处理异方差数据等场景;OLS回归则常用于均值趋势分析和简单预测任务。
6. 分位数回归的工程优化
6.1 大规模数据加速
在处理大规模数据时,传统的分位数回归方法可能会面临计算效率低下的问题。为了提高计算速度,我们可以使用keras实现分位数回归神经网络。
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential
model = Sequential([
Dense(64, activation='relu', input_shape=(X_train.shape[1],)),
Dense(32, activation='relu'),
Dense(1) # 输出层无激活函数
])
def quantile_loss(q):
def loss(y_true, y_pred):
err = y_true - y_pred
return tf.reduce_mean(tf.maximum(q*err, (q - 1)*err))
return loss
# 编译τ=0.9模型
model.compile(optimizer='adam', loss = quantile_loss(0.9))
model.fit(X_train, y_train, epochs = 50, batch_size = 128)
通过构建神经网络模型,利用其强大的学习能力和并行计算优势,可以有效加速分位数回归的计算过程。在这个示例中,我们构建了一个简单的多层感知机(MLP),包含两个隐藏层。定义了一个根据分位数τ计算损失的函数quantile_loss,并使用adam优化器对模型进行编译和训练。这样,在处理大规模数据时,神经网络分位数回归模型能够更快地收敛,提高计算效率。
7. 总结与系列展望
7.1 核心结论
分位数回归凭借其独特的非对称损失函数,为我们揭示了变量关系的分布特征,使我们能够从全分布视角理解数据。在风险管理和费用预测等场景中,分位数回归具有传统回归方法不可替代的价值。同时,通过将分位数回归与神经网络相结合,能够有效处理高维非线性问题,进一步拓展了其应用范围。
7.2 下一篇预告
下一篇:《神经网络回归:深度学习的回归之道》
将深入讲解:
- 多层感知机的回归实现:详细介绍多层感知机在回归任务中的具体实现方式,包括网络结构设计、参数调整以及训练过程中的注意事项。
- 自编码器在特征提取中的应用:探讨自编码器如何在回归任务中进行特征提取,通过对数据的编码和解码过程,挖掘数据的潜在特征,提高回归模型的性能。
- 注意力机制处理时序回归任务:分析注意力机制在时序回归任务中的应用原理和优势,展示如何利用注意力机制让模型更好地捕捉时间序列数据中的重要信息,提升预测的准确性。
8. 延伸阅读
- 《Quantile Regression》权威著作:全面深入地介绍分位数回归的理论、方法和应用,是深入学习分位数回归的重要参考书籍。
- Statsmodels分位数回归文档:提供了
statsmodels库中关于分位数回归的详细使用说明和示例代码,帮助读者快速上手实践。 - 分位数神经网络论文:介绍了分位数回归与神经网络相结合的相关研究成果,为进一步探索分位数回归的工程优化提供了理论支持。
9. 讨论问题
你在哪些场景下使用过分位数回归?如何处理高维数据下的计算效率问题?欢迎分享实战经验!