【趣谈】了解语音拼写检查算法的内部机制
【趣谈】了解语音拼写检查算法的内部机制
推荐超级课程:
- 本地离线DeepSeek AI方案部署实战教程【完全版】
- Docker快速入门到精通
- Kubernetes入门到大师通关课
- AWS云服务快速入门实战
目录
- 【趣谈】了解语音拼写检查算法的内部机制
- 了解Soundex,一种语音拼写检查算法。
- 语音拼写检查算法是如何工作的?
- 如何使用
- 局限性
- 结束笔记
了解Soundex,一种语音拼写检查算法。
拼写检查是任何搜索系统中最重要的部分之一,它在纠正常见拼写错误和增强搜索结果的相关性方面发挥着重要作用。
用户可能会因为多种原因输入错误的拼写。这包括键盘输入错误(如“the”和“thw”)、语音错误(如“wiskee”和“whisky”)、错误合并的单词(如“youare”和“you are”)等等。为了解决这些问题,搜索系统通常会采用一系列针对不同问题的算法,以实现最佳的结果。
然而,在这篇文章中,我们只会关注一种名为Soundex的语音拼写检查算法。那么,让我们开始吧。
语音拼写检查算法是如何工作的?
语音拼写检查算法的基础在于单词的语音表示。这些算法旨在将具有相似发音或语音特征的单词映射到相同的或相似的表示形式。通过这样做,它们能够根据其语音相似性而不是其确切的文本形式来识别和纠正拼写错误。但是,这是如何实现的呢?
整个过程中的关键部分是生成一个单词的语音哈希,然后将其与其他单词进行比较。虽然不同的算法会产生不同的哈希值,但Soundex,例如,会生成一个四字母代码。
按照下面的算法来理解如何使用Soundex生成一个单词的语音哈希。
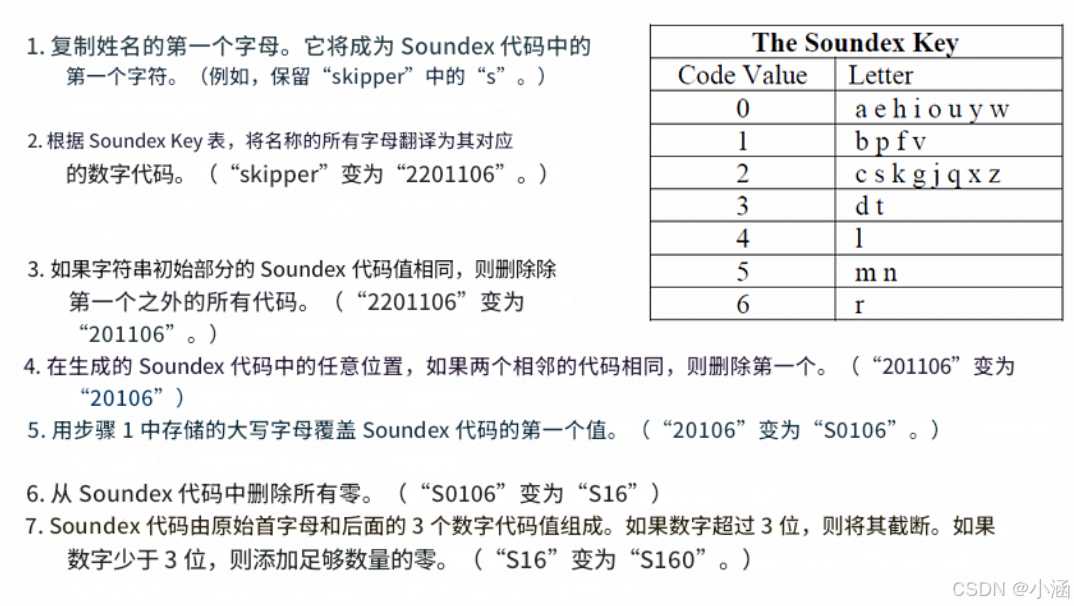
Soundex算法
正如你所观察到的,Soundex算法非常简单,但能够处理具有挑战性的情况。为了说明其有效性,让我们通过一个涉及品牌名称Skullcandy及其各种语音错误的例子来进行分析。下面是同一内容的图像。
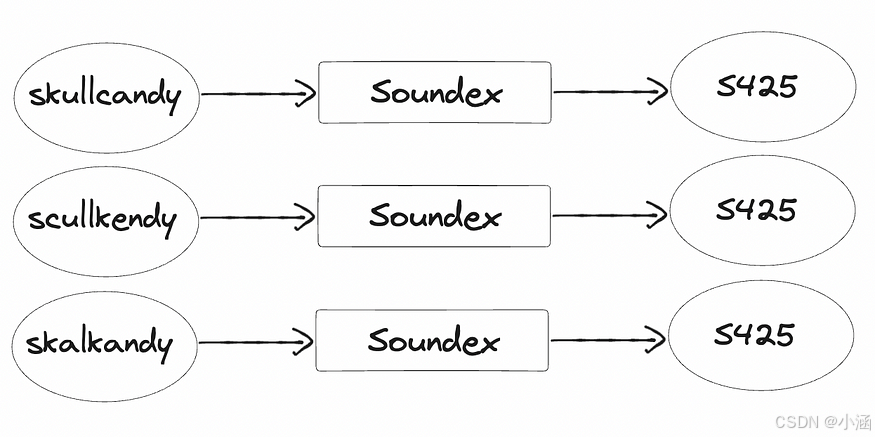
Soundex算法的示例案例
在这个例子中,只有一个拼写(skullcandy)是正确的,而另外两个(scullkendy和skalkandy)听起来相似但不正确。有趣的是,尽管它们之间存在差异,但这三个拼写都共享相同的语音哈希(S425),因此它们将被视为同一个单词。
如果你想要自己尝试这个算法,可以使用这个在线工具。
如何使用
本节将简要介绍任何拼写检查算法如何在现实世界的搜索系统中使用。
当用户提交一个查询时,它最初会根据空格分成单独的标记。例如,将短语“Livais jeens”分词会产生一个包含[“Livais”, “jeens”]的标记列表。
分词后,我们为每个标记计算语音哈希。例如,使用Soundex,生成的哈希值将是[“L120”, “J520”]。
现在,我们进入一个稍微复杂一点的步骤。对于每个标记,我们搜索倒排索引以检索具有相同语音哈希的单词列表。这个步骤是在运行时之前预先计算好的,以避免计算开销。值得注意的是,这个阶段,称为候选生成,可以为每个哈希标记产生多个候选词。
真正的挑战在于对这些候选词进行排名并选择最合适的词。通常,这个排名过程,称为候选选择,是由搜索系统的另一个组件实现的。
进入排名部分将超出本文的范围。然而,从一般的角度来看,一个基本的方法是有一个包含所有可能单词的列表,以及它们各自的频率存储在数据库中。这些数据可以帮助根据出现频率对候选词列表进行排序,通常在许多情况下都能产生满意的结果。
如果一切正常,那么你很可能会得到“Levis jeans”作为“Livais jeens”搜索短语的正确查询。
局限性
正如我们在前面的章节中所看到的,Soundex是一个非常简单但强大的语音拼写校正算法。尽管如此,它仍然存在一些局限性。其中一些如下:
- 它主要针对英语。调整它以符合目标语言的语音规则和特征可能需要大量的努力和迭代。
- 由于保留了第一个字母,一些听起来相似的名称可能有不同的语音哈希。例如“Clara as C460”和“Klara as K460”。
- Soundex代码是固定长度的,可能无法充分表示较长或较短的名称。较长的名称可能被截断,从而导致信息丢失,而较短的名称可能无法提供足够的语音细节。
结束笔记
构建拼写检查系统需要的不仅仅是本文中解释的内容。但是,了解它的基本原理可以帮助你独立探索信息检索系统的世界。