任务型多轮对话(二)| 意图识别
原文:https://zhuanlan.zhihu.com/p/12038702395
一、简介
1. 基本介绍
在任务型多轮对话中,意图识别是一个关键的环节。意图识别是指从用户输入的对话内容(如文本、语音等形式)中分析并判断出用户的目的或者意图。例如,在一个智能客服对话系统中,用户输入“我想要查询一下我的订单状态”,系统通过意图识别就能判断出用户的意图是查询订单状态。意图识别的具体作用如下:
- 有效引导对话流程:它能够帮助对话系统理解用户想要做什么,从而决定对话的走向。如果系统正确识别了用户是要查询订单状态,就可以引导用户提供订单相关的信息,如订单号等,以便完成查询任务。
- 提高对话效率:准确的意图识别可以避免系统对用户的回答驴唇不对马嘴。比如,当用户意图是退货,系统不会误解为换货而提供错误的引导步骤,从而让用户更快地得到想要的服务,减少对话的轮数。
- 增强用户体验:当系统能够精准理解用户意图时,用户会感觉自己的需求被重视和理解。相反,如果意图识别错误,用户可能会因为反复解释或者得不到正确的服务而感到沮丧。
2. 单多轮意图
在任务型多轮对话中,可以分为单轮意图识别和多轮意图识别:
- 单轮意图识别:是指仅针对用户的单句输入进行意图判断。例如,在一个问答系统中,用户问 “今天的天气如何?”,系统只需要分析这一个句子,就能识别出用户是想查询天气信息的意图。它聚焦于独立的、一次性的用户表达,不考虑之前或之后可能的对话内容。单轮意图识别相对简单,因为它只需要处理一个句子的语义理解。通常可以通过关键词匹配、简单的语法分析和基于单句的机器学习模型来实现。例如,通过查找句子中是否存在 “天气”“查询” 等关键词来判断意图,不需要考虑上下文对话的变化和逻辑连贯性。
- 多轮意图识别:涉及对用户在一系列对话轮次中的意图进行识别。比如在一个智能客服对话场景下,用户先问 “我买的商品坏了怎么办?”,客服回答后,用户又问 “那维修需要多长时间?”,多轮意图识别需要综合考虑这两轮对话,判断出用户最初是想了解商品损坏后的解决方案,后续是想知道维修时长,并且理解这两个意图之间的关联。多轮意图识别要复杂得多,它需要考虑对话的历史信息,包括之前轮次的意图、对话的主题转移、用户情绪的变化等诸多因素。例如,用户可能一开始询问产品功能,然后因为对回答不满意而转为抱怨服务质量,多轮意图识别系统需要能够及时捕捉到这种意图的转变,并准确理解每个意图在整个对话流程中的作用。
接下来,我们将分别从单轮、多轮来分别介绍下如何来实现。
二、单轮意图
常用于简单的问答系统,如知识查询平台。例如,在一个百科知识问答网站中,用户输入一个问题,系统只需要根据这一个问题识别意图并提供答案,不需要考虑其他因素。还有一些简单的语音指令系统,如智能音箱的单句指令识别,像 “播放音乐” 这样的单句指令,通过单轮意图识别就能完成任务。
下面我们来介绍4种常见的方案:基于规则、向量检索、深度学习、大模型
1. 基于规则
基于规则的方案往往需要应用到分词器,例如jieba、hanlp等。通过分词后,会返回预先设置的关联短语或词汇(没命中返回空即可),然后返回意图。
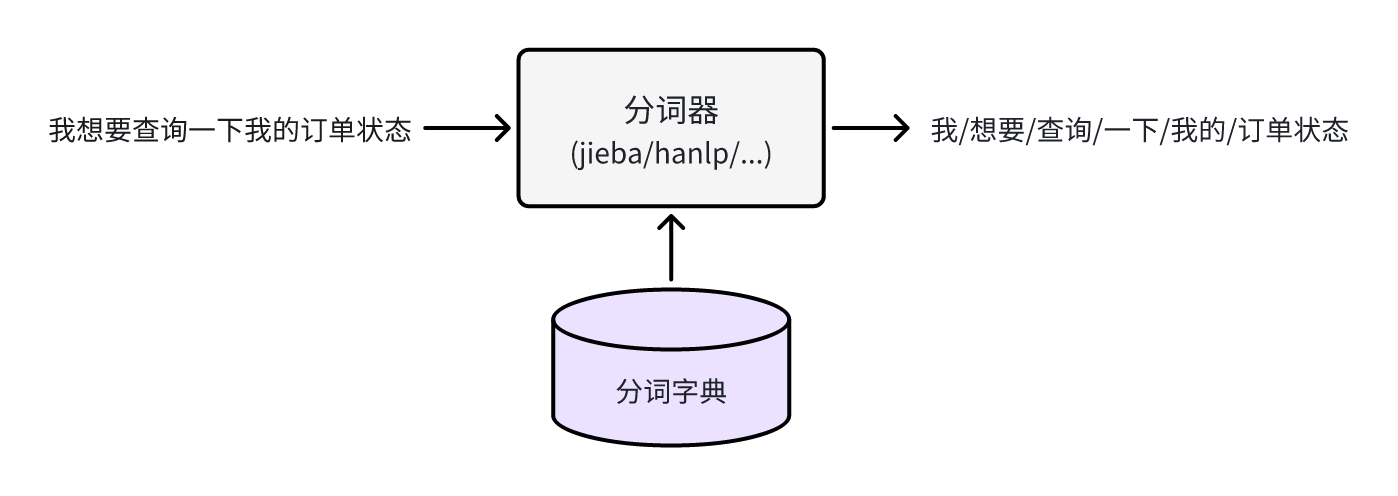
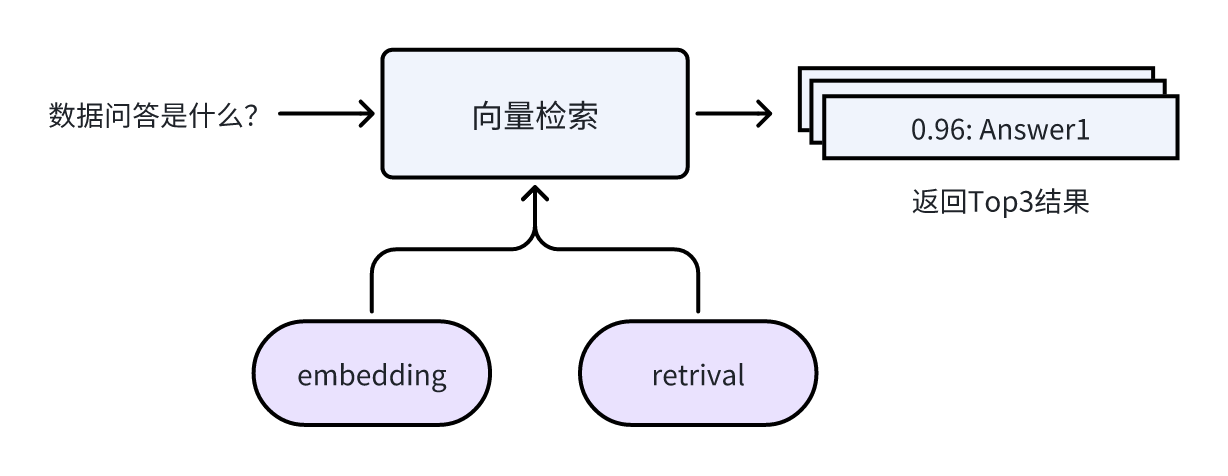
2. 向量检索
向量检索的目的是将输入query匹配到知识库里面与之相似的其他query。这里需要使用embedding(向量化)和retrival(检索),向量化的模型很多,例如bge、simcse 和 promcse等;检索的工具也有很多,例如Faiss、Milvus 和 Hologres等。通过向量检索后,会返回top3相似query及相似度值。
3. 深度学习
使用深度学习的方法来做意图识别是一种常见的方法,一般是文本分类深度学习框架,例如:预训练模型(RoBERTa、ALBERT等) + TextCNN。这里需要人工设定分类类别和标注数据,然后使用分类模型训练与推理部署。
- 数据集构建
| text | label |
|---|---|
| xxxxxxxxxxxxxx | A001 |
| xxxxxxxxxxxxxx | A002 |
| xxxxxxxxxxxxxx | A003 |
| xxxxxxxxxxxxxx | A004 |
| xxxxxxxxxxxxxx | A005 |
- 深度学习框架
这里推荐使用roberta+textcnn,也是比较经典的一个文本分类深度学习框架。
4. 大模型
使用大模型的方法来做意图识别是一种越来越流行的方法,这里分为2种,第一种不需要微调,直接使用prompt的形式给到大模型,然后大模型返回意图结果;另一种需要微调,意味着需要人工标注一定量的数据,然后给大模型微调训练。
- 不微调
如果没有太多资源做人工标注,并且想快速实现分类,在大模型时代也是有解法的,用过大模型prompt的小伙伴应该也都非常清楚,下面是一个prompt例子:
query = "xxxxxxxxxx"
prompt = """你是一个NLP专家,请根据以下多个意图的描述,确保将[输入]映射到其中一个意图上。
意图类别有:A001 | A002 | A003 | A004 | A005。
各个意图的描述和关键词如下,其中【】为意图名称,()为关键词:
【A001】:xxxxxxxxxx,包含关键词(xxxxxxxxxx);
【A002】:xxxxxxxxxx,包含关键词(xxxxxxxxxx);
【A003】:xxxxxxxxxx,包含关键词(xxxxxxxxxx);
【A004】:xxxxxxxxxx,包含关键词(xxxxxxxxxx);
【A005】:xxxxxxxxxx,包含关键词(xxxxxxxxxx);
注意,优先匹配关键词,最终输出上述意图列表中的一个意图, 不要输出推理过程.
示例如下:
[输入]:xxxxxxxxxx 。[输出]:xxxxxxxxxx
[输入]:xxxxxxxxxx 。[输出]:xxxxxxxxxx
[输入]:xxxxxxxxxx 。[输出]:xxxxxxxxxx
[输入]:{%s}"""%(query)其中,query为用户的输入。
- 微调
如果对准确率有非常高的要求,且有人工标注资源,这个时候使用大模型进行微调会是一个比较不错的选择。使用大模型微调需要注意以下几点:1.大模型选择;2.文本长度设置;3.标注数据的质量和数量,以后后续模型迭代的便捷性等。
当使用大模型微调时,也需要指令数据集给大模型学习,例如(一条样本):
sample = {
"human": "你是一个NLP专家,请根据以下多个意图的描述,确保将[输入]映射到其中的一个意图上。 \n意图类别有:A001 | A002 | A003 | A004 | A005。\n[输入]:xxxxxx。",
"assistant": "A001"
}
print(sample["human"])
# 你是一个NLP专家,请根据以下多个意图的描述,确保将[输入]映射到其中的一个意图上。
# 意图类别有:A001 | A002 | A003 | A004 | A005。
# [输入]:xxxxxx。关于大模型微调,我推荐使用Qwen大模型,对比了几个感觉它的效果还不错。
5. 方案融合
在实际项目中,意图识别往往并不能被单一模型完成,因为准确率、业务逻辑、上线效率等都是需要考虑的因素。所以,一个串并行同时存在且进行排序的意图框架往往是我们所需要的。下面,我介绍一种方案:
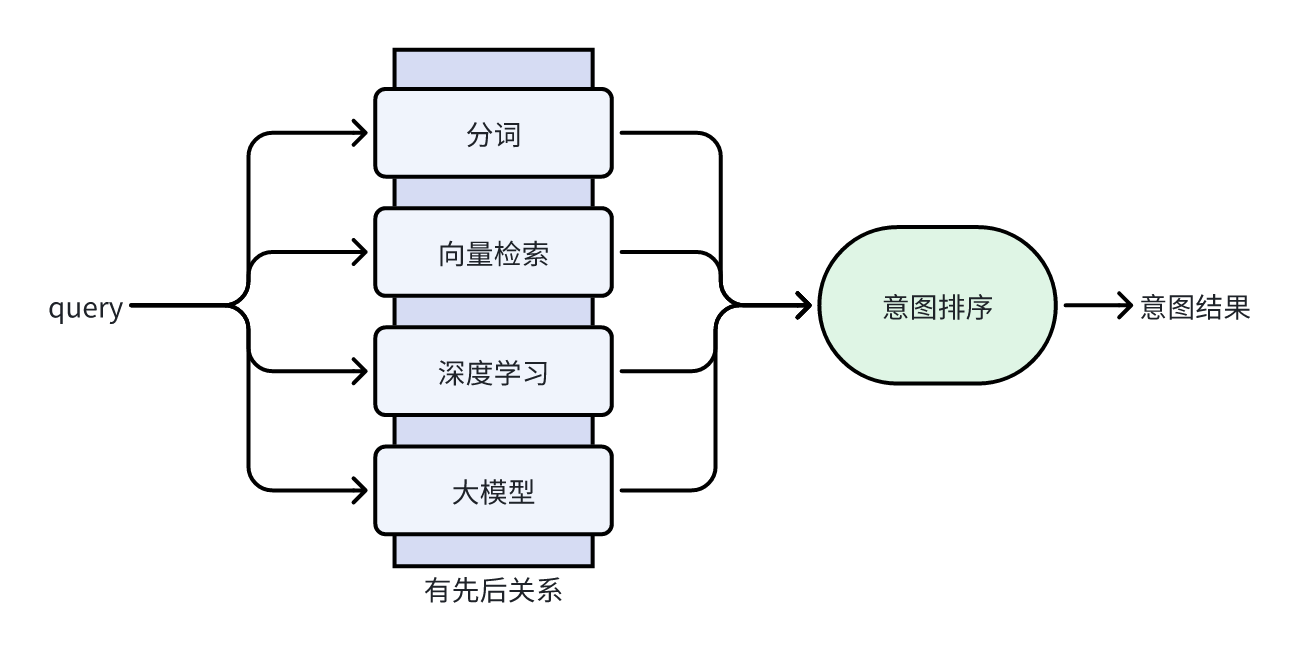
这里,我们注意2点:先后关系 和 意图排序,可以根据实际需求采取不同的策略。例如,通过关键词可以快速召回意图,可以放置在最前面;通过大模型配置prompt召回部分意图等。
三、多轮意图
广泛应用于复杂的对话系统,如智能客服、智能聊天机器人等。在智能客服场景中,用户和客服之间的对话往往是多轮的,涉及产品咨询、故障报修、投诉处理等多种复杂的意图,需要多轮意图识别来提供精准的服务。在智能聊天机器人用于情感陪伴等场景时,也需要多轮意图识别来理解用户情绪的变化和聊天主题的转换,从而给出更合适的回应。
1. Pipeline
在pipeline的多轮对话中,仅仅使用当前query往往不一定能给出正确的意图,还需要查看历史的对话信息。
- 如何判断上下文是否关联?
这里主要通过2种途径,第1种是基于上下文语义上的,第2种是上下文槽位信息的。
基于上下文语义分割
User: 前天武汉的天气?
System: 前天武汉的天气是15-25度,xxxxxx。
User: 那北京的呢?
System: 前天北京的天气是10-20度,xxxxxx。关于如何实现上下文语义分割,当前主要是基于深度学习或大模型方法。如果使用深度学习方法,可以基于NER算法框架来实现,从而来判断上下文衔接是否可分;如果使用大模型,需要标注一少部分数据,再微调大模型,从而来判断上下文是否可分。
基于上下文槽位关联
如果将 "那北京的呢?" 改成 "北京",仅从语义上看,并不能判断User是否想问 "前天北京的天气?",但是通过槽位(地点)可以判断需要继承用户想问天气的意图。
User: 前天武汉的天气?
System: 前天武汉的天气是15-25度,xxxxxx。
User: 北京
System: 前天北京的天气是10-20度,xxxxxx。如果仅通过槽位进行上下文关联时,有时候会出现错误,这也是过往仅基于槽位多轮意图的问题。
2. End-to-End
- 指令数据集构建
在端到端的多轮意图中,构建指令数据集可能是工作量最大的一部分,不过好在大模型在多轮意图上的理解能力是可以随着指令数据集的扩展来进行迭代优化的,当然前提是大模型基座的能力是ok的。
下面,我介绍一种多轮意图指令数据集构建的方法:
sample = {
"human": "你是一个NLP专家,请根据历史对话信息,来判断当前对话[USER-current]的意图。 \n意图类别有:A001 | A002 | A003 | A004 | A005。\n历史对话信息如下:\n[USER]: xxxxxxx\n[ROBOT]: xxxxxxx\n[USER]: xxxxxxx\n[ROBOT]: xxxxxxx\n当前对话如下:\n[USER-current]: xxxxxxx",
"assistant": "A001"
}
print(sample["human"])
# 你是一个NLP专家,请根据历史对话信息,来判断当前对话[USER-current]的意图。
# 意图类别有:A001 | A002 | A003 | A004 | A005。
# 历史对话信息如下:
# [USER]: xxxxxxx
# [ROBOT]: xxxxxxx
# [USER]: xxxxxxx
# [ROBOT]: xxxxxxx
# 当前对话如下:
# [USER-current]: xxxxxxx如果没有历史对话信息,可以构建这样的指令数据:
sample = {
"human": "你是一个NLP专家,请根据上下文的对话信息,来判断当前对话[USER-current]的意图。 \n意图类别有:A001 | A002 | A003 | A004 | A005。\n历史对话信息如下:无历史对话。\n当前对话如下:\n[USER-current]: xxxxxxx",
"assistant": "A001"
}
print(sample["human"])
# 你是一个NLP专家,请根据上下文的对话信息,来判断当前对话[USER-current]的意图。
# 意图类别有:A001 | A002 | A003 | A004 | A005。
# 历史对话信息如下:无历史对话。
# 当前对话如下:
# [USER-current]: xxxxxxx- 大模型微调
关于大模型微调,这里也推荐使用Qwen大模型。
3. 多级意图
在实际项目中,往往存在多级意图。例如,用户说"帮我定一张武汉去北京的机票",它可能有一级意图"出行"和二级意图"机票预定"。又比如,用户说 “我想听音乐”,这是一个初步意图,可能接着会有 “播放某歌手的歌曲”“切换到下一首”“调高音量” 等后续的多级意图。
四、业界产品体验
1. 豆包
例子1:
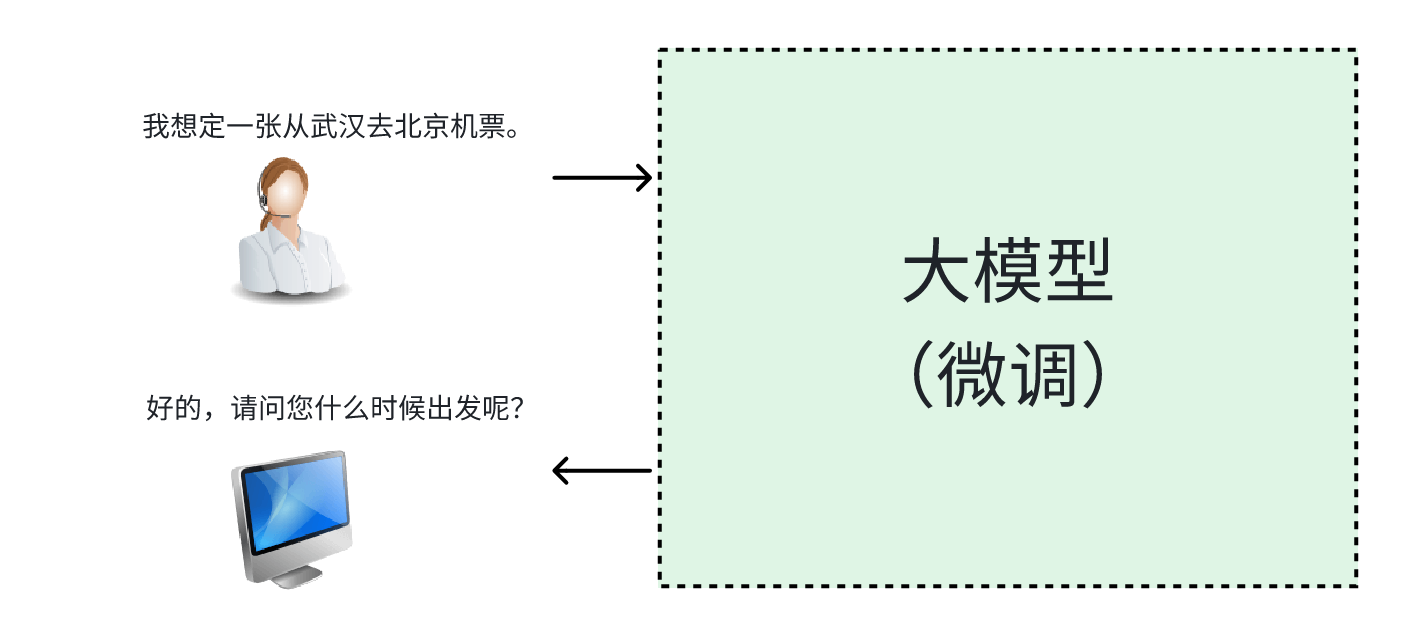
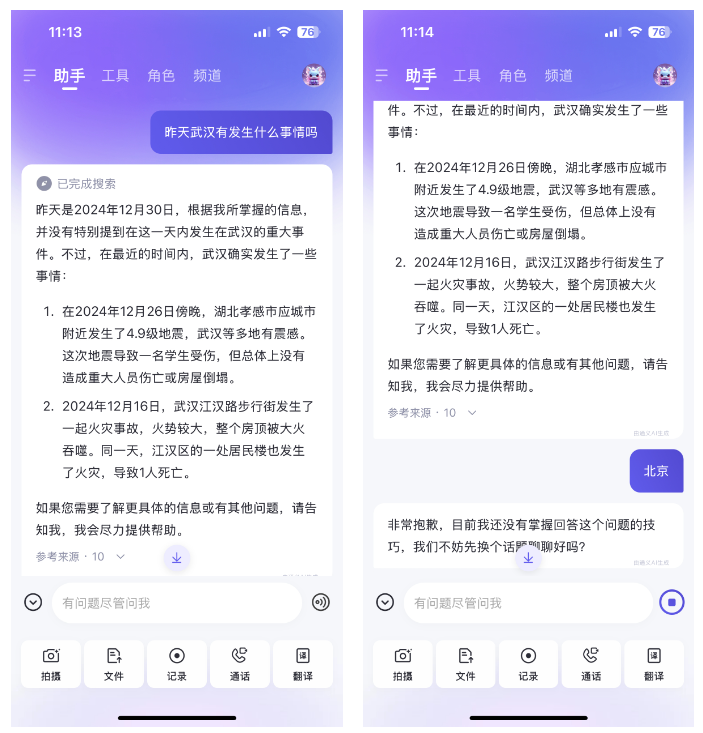
我:昨天武汉有发生什么事情吗?
豆包:[如下图所示]
我:北京
豆包:[如下图所示]
可以发现,首先"昨天武汉有发生什么事情吗?"在意图识别上,应该识别到类似"实事查询"的意图,其次"北京"在意图识别上,豆包做的非常好,它关联到了上文的意图,并且做到了语义信息的继承。
例子2:
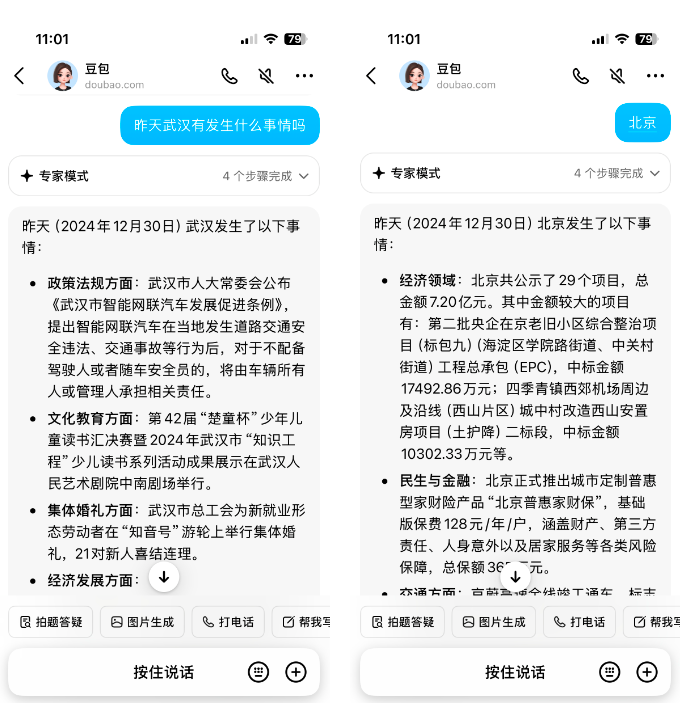
我:武汉周边有哪些城市?
豆包:[如下图所示]
我:那北京呢?
豆包:[如下图所示]
可以发现,在上下文的意图继承上,豆包的回复存在问题,"那北京呢?"应该返回北京周边有哪些城市。
2. Kimi
例子1:
我:昨天武汉有发生什么事情吗?
Kimi:[如下图所示]
我:北京
Kimi:[如下图所示]
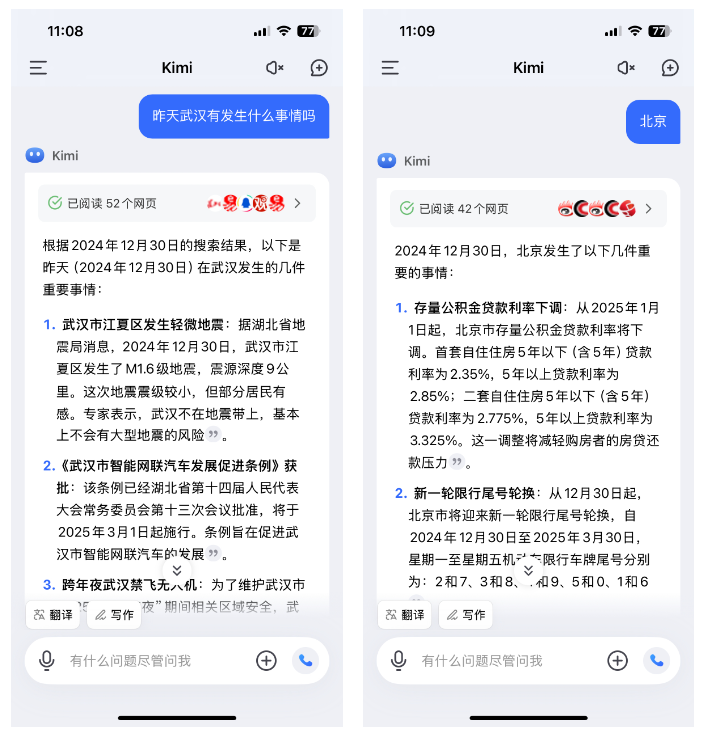
可以发现,Kimi在多轮意图的理解上也还是不错的,和豆包差不多。
例子2:
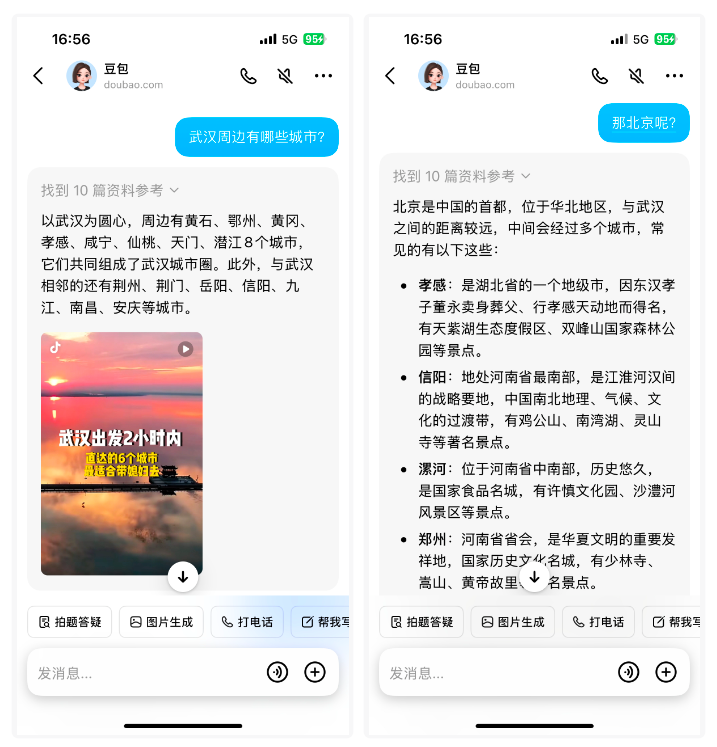
我:武汉周边有哪些城市?
Kimi:[如下图所示]
我:那北京呢?
Kimi:[如下图所示]
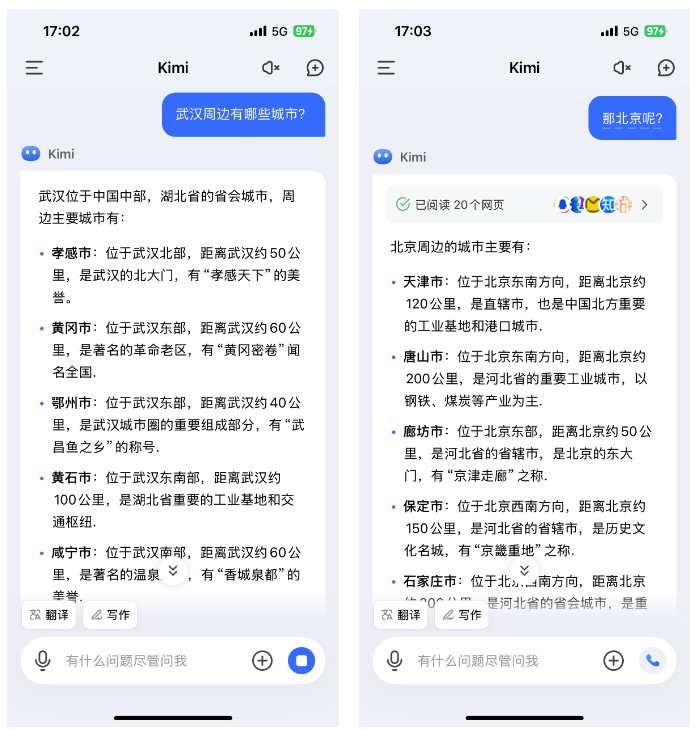
可以看到,Kimi 在上下文语义分割的能力上还是不错的,它理解了我想知道 "北京周报的城市有哪些?"。
3. 通义千问
例子1:
我:昨天武汉有发生什么事情吗?
通义:[如下图所示]
我:北京
通义:[如下图所示]
可以发现,首先"昨天武汉有发生什么事情吗?"在意图识别上,通义请问识别到类似"实事查询"的意图,但是因为在二次查询和大模型生成上的能力不行,导致回复不准确;其次"北京"在意图识别上,没有继承上文意图,导致回复不准确。
例子2:
我:武汉周边有哪些城市?
通义:[如下图所示]
我:那北京呢?
通义:[如下图所示]
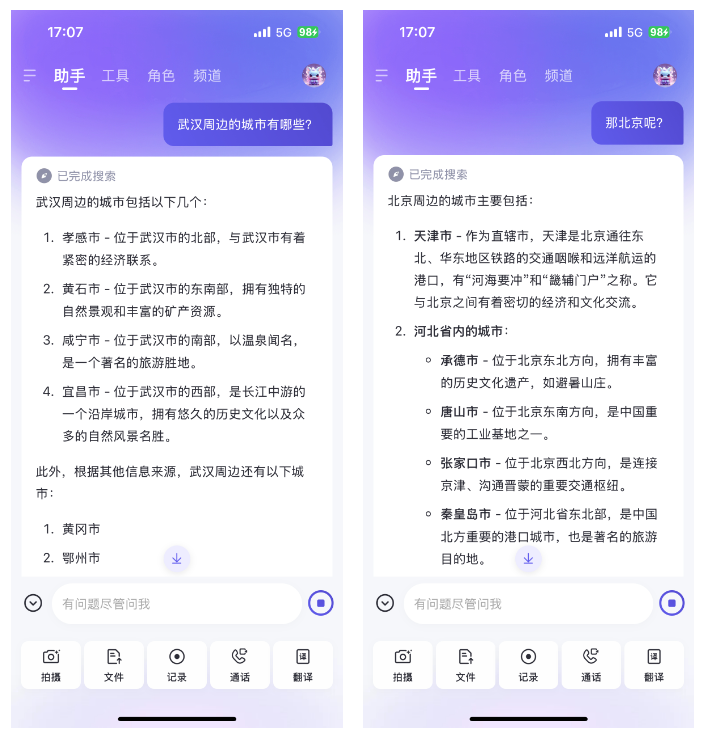
可以看到,通义千问 在上下文语义分割的能力上也还行,只是回复的内容上差一点。
编辑于 2025-01-08 17:10・IP 属地湖北