AI大模型:(二)1.1 deepseek+ollama本地快速部署
DeepSeek号称模型界的拼夕夕,凭借其先进的算法+蒸馏技术,使得低成本小尺寸模型拥有顶尖模型的能力。有力推动了国内AI技术的发展,用户数量的快速增长导致服务器一度繁忙。为缓解这一问题,用户可选择在本地电脑上部署:只需下载Ollama和DeepSeek-R模型,且对电脑配置无硬性要求。当然,硬件配置越高,推理性能和响应速度也会相应提升。
1 本地部署要求及适用场景
| 模型参数 | CPU要求 | 内存要求 | 显存要求 | 硬盘要求 | 适用场景 |
|---|---|---|---|---|---|
| 1.5B | 最低4核,推荐8核 | 8GB+ | 纯CPU或4GB+显存 | 3GB+ SSD | 基础文本生成、嵌入式设备、教育演示 |
| 7B | 最低8核,推荐16核 | 16GB+ | 8GB+(如RTX 3060) | 8GB+ SSD | 代码生成、创意写作、轻量级客服25 |
| 14B | 12核以上,推荐32核 | 32GB+ | 16GB+(如RTX 4090) | 15GB+ NVMe SSD | 合同分析、长文本生成、多语言翻译 |
| 32B | 16核以上,推荐64核 | 64GB+ | 24GB+(如A100或双卡3090) | 30GB+高速SSD | 医疗/法律咨询、多模态预处理 |
| 70B | 32核以上(服务器级) | 128GB+ | 多卡集群(如2xA100 80G) | 70GB+企业级SSD | 科研级生成任务、复杂数据挖掘 |
| 671B(满血版) | 64核以上(服务器级) | 512GB+ | 8x A100/H100 | 400GB+企业级SSD | 强大的深度推理能力,前沿科研,如基因组学、量子计算等复杂研究。然而,其硬件成本高昂,仅建议国家重点实验室或校企联合项目尝试 |
关键规律:参数越多,语言理解/生成能力越强,但硬件成本指数级增长。
2 ollama安装
2.1 ollama介绍
Ollama 是一个开源的大型语言模型(LLM)服务工具,旨在简化本地部署和运行大型语言模型的过程。它支持多种流行的开源模型(如 LLaMA、Mistral、Gemma 等),并提供命令行交互和类似 OpenAI 的 API 接口,方便开发者快速集成和使用。
2.2 ollam安装
Ollama官方下载,支持macOS, Linux, and Windows。
这里我们下载windows版:
或者ollama可以运行在docker上
在 DeepSeek 部署中,使用 docker 可以确保 deepseek - r1 在不同环境中具有一致的运行状态。无论在开发环境、测试环境还是生产环境,只要安装了 docker,就可以运行相同的 deepseek - r1 容器,避免了因环境差异导致的兼容性问题。
docker run -d --gpus=all -p 11434:11434 --name ollama ollama/ollama3 deepseek安装运行
安装了ollama,我们就可以快速的下载和运行deepseek。当然不是非得用ollama,有的大模型不一定支持ollama安装运行。
这里我们选择7b版:
deepseek-r1:7b
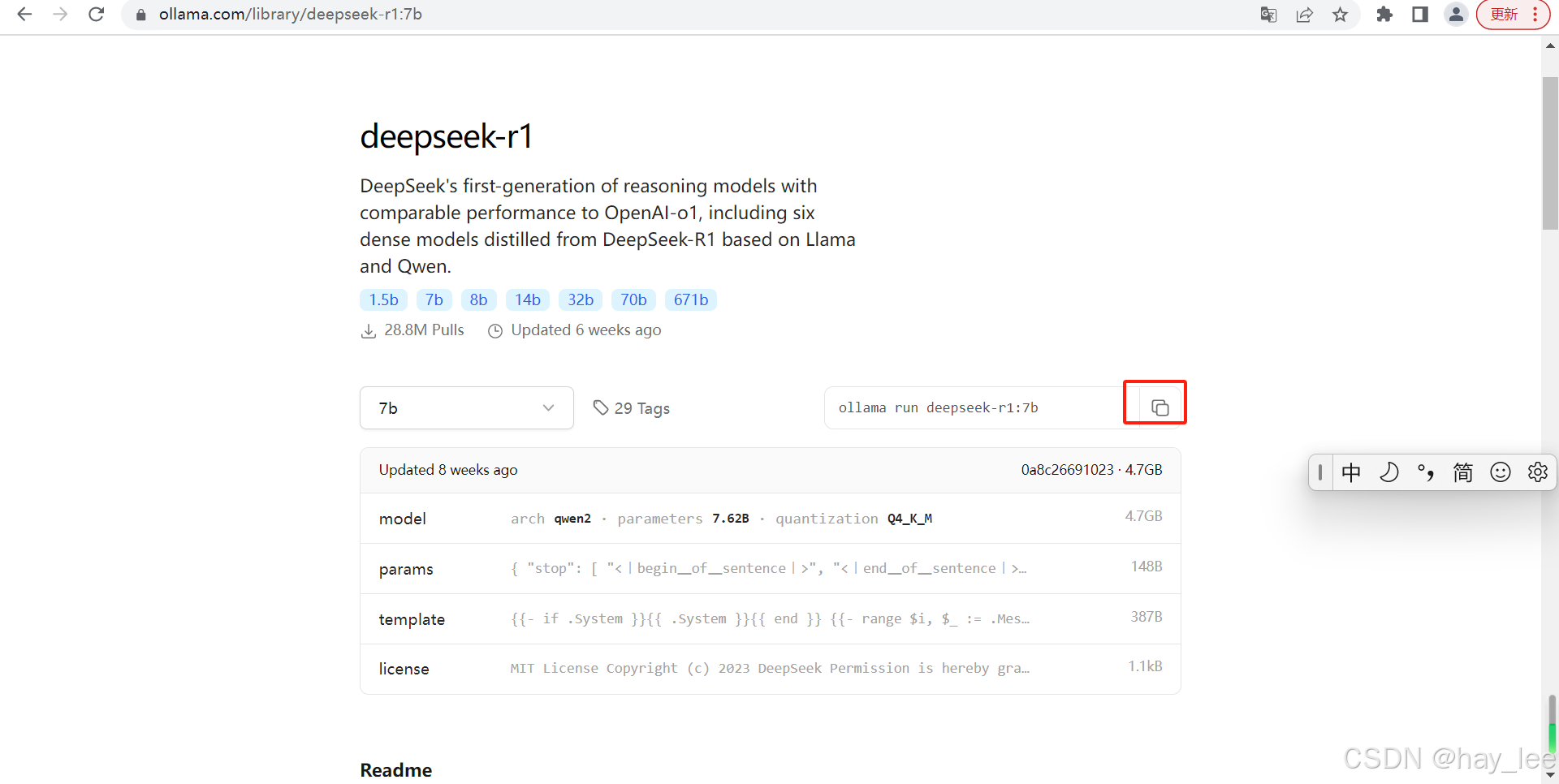
复制命令直接在本地运行
拉取完就可以直接运行,就可以在此窗口跟deepseek聊天了。
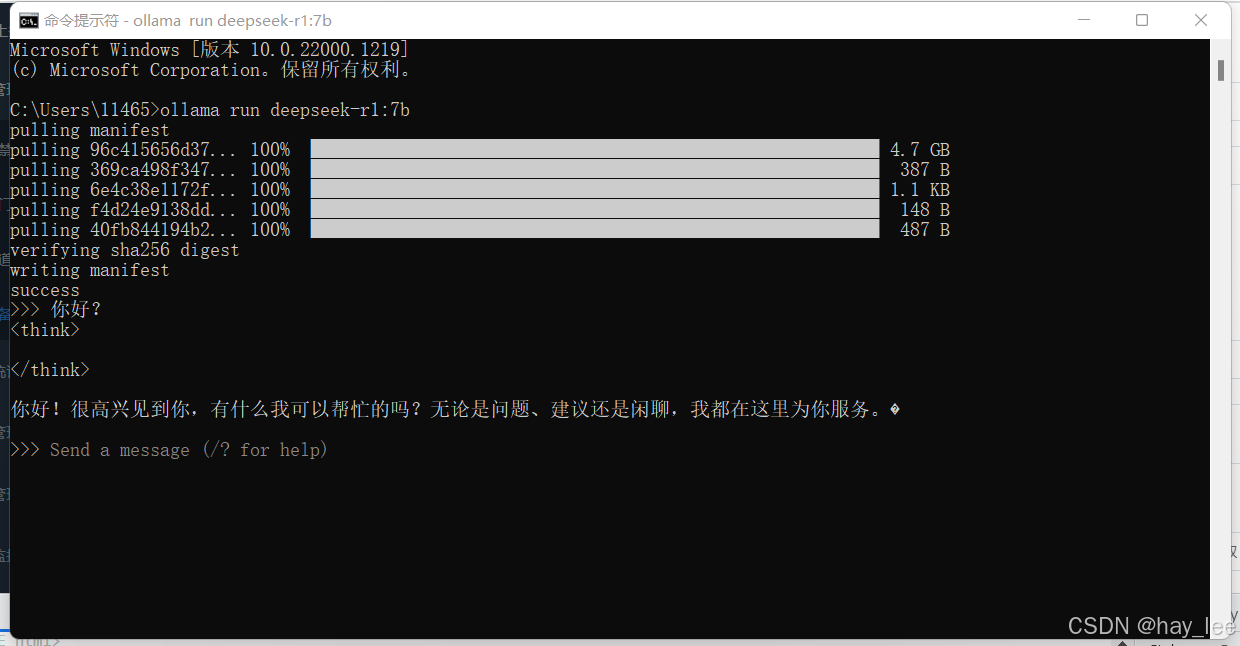
也可以查看ollama安装的模型:

不使用了也可以删除:
