强化学习(赵世钰版)-学习笔记(完)(10.Actor-Critic方法)
这是本课程的最后一课,讲的是在基于策略的基础上,添加基于值相关的内容。
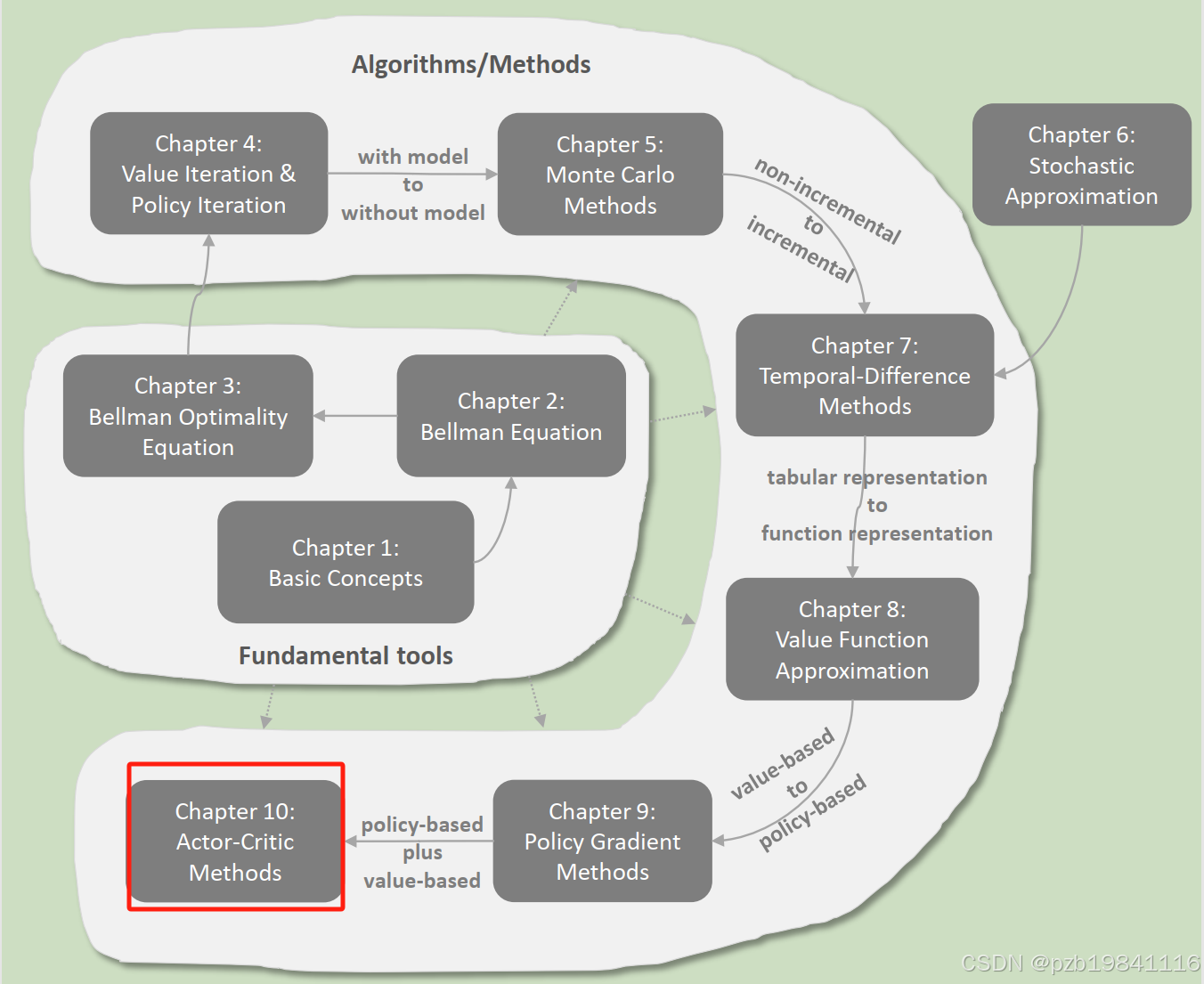
Actor-Critic方法也是个基于策略梯度的方法,将策略梯度与值方法整合在了一起。Actor的作用是策略更新,Critic的作用是策略评估或值估计。

上节课介绍的策略梯度法,其数学表达式中就包含了Actor和Critic的相关部分。3)中的整个式子是Actor,标蓝的部分是Critic。

其中这个行为值的获取方法有两种,一个是用MC的方法获取(上节课介绍的),叫REINFORCE方法。另一个方法使用TD方法,这种方法就叫做Actor-Critic方法。

最简单的Actor-Critic算法伪代码如下所示:

接下来是对最简单的QAC算法进行扩展,添加一个偏置项(baseline,为什么用基线这个词?)来减少均方差,这个方法叫做advantage actor-critic(A2C)方法,表达式如下所示。

为什么添加这个有效果?第一步证明了添加这一项对期望没有影响,第二步证明了能改变均方差。

目标是找到一个最有的baseline,使均方差最小。

最优的baseline太复杂,对其进行简化发现,次优解就是状态值。

将状态值当做偏置项带入到梯度上升算法中,红框中的这个就是advantage function(算法名中advantage的由来)。

用TD算法对行为值进行近似,可以简化成如下公式,优点是只需要一个网络来近似策略值,而不是两个(另一个网络近似行为值)。

对A2C算法的方程进行数学变换,也能获取到一个β,跟上节课一样,可以调节探索与开发的比重。

这个是A2C算法的伪代码,这是个On-Policy的算法,因为用到的采样数据,也是用这个策略得到的。

如何将算法改造成Off-Policy算法(好处是可以用其他已有的数据,来对当前策略进行学习),这里引入了一个重要的概念-重要性采样(Importance Sampling)。具体方法是利用数学技巧,将两个不同的概率联系到一起。
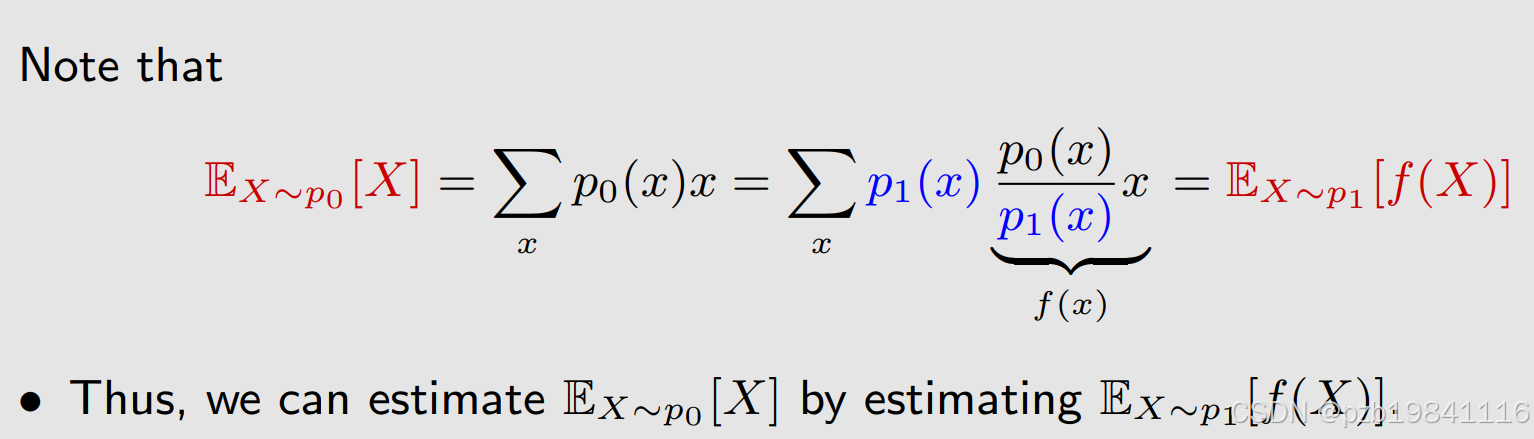
这个比值叫做重要性权重(importance weight)。

这个做的原因是,当前的概率p0是未知的。

那么改造成Off-Policy模式,就是用现有的数据对策略进行学习。

这个策略梯度公式中,前后两个期望的概率分布发生了变化,这个是On-Policy转换到Off-Policy的原因。

这里将状态值当做baseline,带入到梯度上升公式,经过化简得到了最后的公式。

Off-Policy的算法伪代码如下所示

最后是确定性的(Deterministic)Actor-Critic算法,之前的算法可以成为随机版本的,因为每个状态下各行为发生的概率都不为零。而DAC算法的优点是,可以处理连续行为空间的情况。

确定行动策略,状态与行为之间,可以抽象成一个函数,这个函数可以用神经网络等方法表示。

确定性的策略梯度策略,与之前随机性的有些区别。这里选择d0概率分布的方式有两种,一个是将第一个状态的概率设为1,其他为0.请一个方法是用稳定概率(就是马尔科夫过程稳定下来后的概率)。

稳定策略梯度理论包含折扣率的情况如下所示。

稳定策略梯度的Actor-Critic算法伪代码如下所示。

这是个Off-Policy,其中的β可以是另一个分布,也可是当前分布加噪声的形式。而函数q可以用线性方程表征,也可以采用神经网络的形式。
