PyTorch深度学习框架60天进阶学习计划-第27天:模型量化原理(一)
PyTorch深度学习框架60天进阶学习计划-第27天:模型量化原理(一)
欢迎来到我们的PyTorch进阶学习计划第27天!昨天我们学习了如何在移动端部署优化后的模型,今天我们将深入探讨背后的核心技术——模型量化的基本原理和实现方法。量化技术是模型压缩和加速的关键手段,掌握它将让你能够在资源受限的环境中部署高效的深度学习模型。
量化,简单来说,就是将模型参数从高精度(如FP32)转换为低精度(如INT8)的过程。这看似简单的操作背后蕴含着丰富的理论和技术细节。今天,我们将揭开模型量化的神秘面纱,从理论原理到实际操作,全方位掌握这一强大的优化技术!
学习目标
- 理解量化感知训练(QAT)的基本原理与实现流程
- 比较对称量化与非对称量化的优缺点及应用场景
- 掌握混合精度推理的内存优化策略
- 能够独立实现和评估不同量化方案
目录
- 量化基础理论
- 量化感知训练流程
- 对称量化与非对称量化
- 混合精度推理优化
1. 量化基础理论
1.1 什么是模型量化?
模型量化是将深度学习模型的权重和激活值从高精度(通常是32位浮点数)转换为低精度表示(如8位整数)的过程。这一过程旨在减少模型大小和计算复杂度,同时尽可能保持模型的准确性。
1.2 量化的数学基础
量化的核心公式如下:
q = round((r / scale) + zero_point)
其中:
r是原始浮点值q是量化后的整数值scale是缩放因子zero_point是零点偏移
反量化公式为:
r = scale * (q - zero_point)
量化参数计算方法:
对于浮点值范围 [rmin, rmax]:
- 对称量化:
scale = max(|rmin|, |rmax|) / (qmax/2),zero_point = 0 - 非对称量化:
scale = (rmax - rmin) / (qmax - qmin),zero_point = round(qmin - rmin / scale)
其中 qmin 和 qmax 是整数范围的最小值和最大值(例如,对于8位整数,qmin=-128 和 qmax=127)。
1.3 量化类型
| 量化类型 | 描述 | 精度 | 压缩率 | 复杂度 |
|---|---|---|---|---|
| 动态量化 | 权重在训练后量化,激活值在推理时动态量化 | 中 | 2-4x | 低 |
| 静态量化 | 权重和激活值在训练后基于校准数据量化 | 高 | 2-4x | 中 |
| 量化感知训练 | 在训练过程中模拟量化效果,模型适应量化误差 | 最高 | 2-4x | 高 |
2. 量化感知训练流程
量化感知训练(QAT)是指在训练过程中模拟量化操作,使网络学习适应量化引入的误差,从而在实际量化后保持更高的精度。
2.1 QAT的基本流程
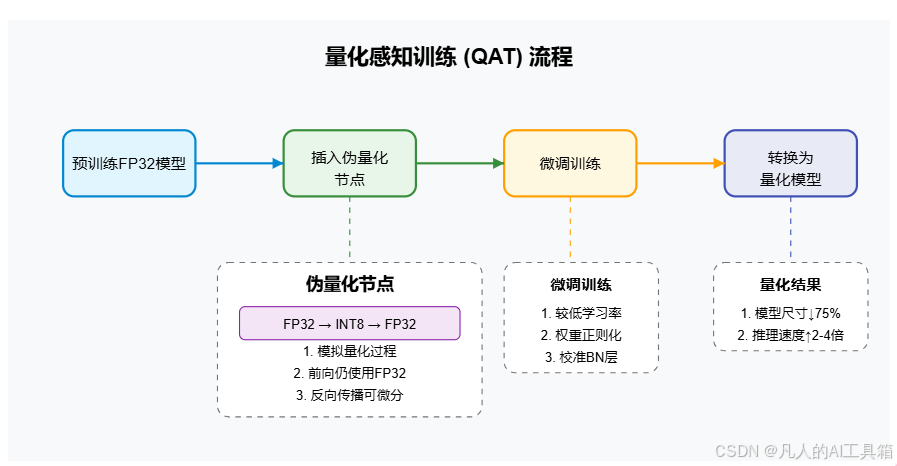
2.2 QAT的核心组件:伪量化器
伪量化器(Fake Quantizer)是QAT的核心组件,它在前向传播中模拟量化-反量化操作,但在反向传播中允许梯度通过。
import torch
import torch.nn as nn
class FakeQuantize(nn.Module):
"""
伪量化器模块:模拟量化-反量化过程,但保持可微分性
参数:
bits (int): 量化位数,默认为8
symmetric (bool): 是否使用对称量化,默认为False
min_value (float, optional): 预设的最小值,默认为None(由数据决定)
max_value (float, optional): 预设的最大值,默认为None(由数据决定)
"""
def __init__(self, bits=8, symmetric=False, min_value=None, max_value=None):
super(FakeQuantize, self).__init__()
self.bits = bits
self.symmetric = symmetric
# 量化后的整数范围
if self.symmetric:
self.qmin = -(2 ** (bits - 1))
self.qmax = 2 ** (bits - 1) - 1
else:
self.qmin = 0
self.qmax = 2 ** bits - 1
# 如果提供了min_value和max_value,则使用它们作为静态范围
self.register_buffer('min_val', torch.tensor(min_value) if min_value is not None else torch.tensor(float('inf')))
self.register_buffer('max_val', torch.tensor(max_value) if max_value is not None else torch.tensor(float('-inf')))
# 是否已经校准
self.calibrated = min_value is not None and max_value is not None
def update_range(self, min_val, max_val):
"""
更新量化范围
"""
self.min_val = min_val
self.max_val = max_val
self.calibrated = True
def forward(self, x):
"""
前向传播:执行伪量化操作
如果在训练模式且范围未校准,则更新范围
然后执行量化-反量化操作
"""
if self.training and not self.calibrated:
# 在训练期间动态更新范围
curr_min = x.detach().min()
curr_max = x.detach().max()
# 更新全局最小值和最大值
self.min_val = torch.min(self.min_val, curr_min)
self.max_val = torch.max(self.max_val, curr_max)
if not self.calibrated and not self.training:
# 如果未校准且在评估模式,给出警告
print("警告:伪量化器未校准,可能导致不准确的结果")
return x
# 执行伪量化
if self.symmetric:
# 对称量化
scale = torch.max(self.max_val.abs(), self.min_val.abs()) / self.qmax
zero_point = 0
else:
# 非对称量化
scale = (self.max_val - self.min_val) / (self.qmax - self.qmin)
zero_point = self.qmin - torch.round(self.min_val / scale)
# 量化操作(STE: Straight-Through Estimator)
x_q = torch.round(x / scale + zero_point)
x_q = torch.clamp(x_q, self.qmin, self.qmax)
# 反量化操作
x_dq = (x_q - zero_point) * scale
# STE: 在反向传播时直接传递梯度
# PyTorch autograd将自动处理这一点
return x_dq
2.3 QAT实践:量化感知训练实现
下面是一个完整的量化感知训练示例,展示如何在PyTorch中实现QAT:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import time
import copy
from tqdm import tqdm
# 导入我们的伪量化器
from fake_quantize import FakeQuantize
# 定义可量化卷积层
class QuantizableConv2d(nn.Conv2d):
"""
可量化的卷积层
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0,
dilation=1, groups=1, bias=True, bits=8, symmetric=False):
super(QuantizableConv2d, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
# 为权重和输入添加伪量化器
self.weight_quantizer = FakeQuantize(bits=bits, symmetric=symmetric)
self.activation_quantizer = FakeQuantize(bits=bits, symmetric=symmetric)
self.quantize_enabled = False
def forward(self, x):
if self.quantize_enabled:
# 量化激活值
x = self.activation_quantizer(x)
# 量化权重
weight = self.weight_quantizer(self.weight)
# 使用量化后的权重进行卷积
return nn.functional.conv2d(
x, weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
else:
# 正常卷积
return super().forward(x)
# 定义可量化线性层
class QuantizableLinear(nn.Linear):
"""
可量化的全连接层
"""
def __init__(self, in_features, out_features, bias=True, bits=8, symmetric=False):
super(QuantizableLinear, self).__init__(in_features, out_features, bias)
# 为权重和输入添加伪量化器
self.weight_quantizer = FakeQuantize(bits=bits, symmetric=symmetric)
self.activation_quantizer = FakeQuantize(bits=bits, symmetric=symmetric)
self.quantize_enabled = False
def forward(self, x):
if self.quantize_enabled:
# 量化激活值
x = self.activation_quantizer(x)
# 量化权重
weight = self.weight_quantizer(self.weight)
# 使用量化后的权重进行线性变换
return nn.functional.linear(x, weight, self.bias)
else:
# 正常线性变换
return super().forward(x)
# 定义简单CNN模型
class SimpleCNN(nn.Module):
def __init__(self, num_classes=10, quantize=False, bits=8, symmetric=False):
super(SimpleCNN, self).__init__()
self.quantize = quantize
self.bits = bits
self.symmetric = symmetric
# 特征提取层
self.features = nn.Sequential(
QuantizableConv2d(3, 32, kernel_size=3, stride=1, padding=1,
bits=bits, symmetric=symmetric),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
QuantizableConv2d(32, 64, kernel_size=3, stride=1, padding=1,
bits=bits, symmetric=symmetric),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
QuantizableConv2d(64, 128, kernel_size=3, stride=1, padding=1,
bits=bits, symmetric=symmetric),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 分类层
self.classifier = nn.Sequential(
QuantizableLinear(128 * 4 * 4, 512, bits=bits, symmetric=symmetric),
nn.ReLU(inplace=True),
QuantizableLinear(512, num_classes, bits=bits, symmetric=symmetric),
)
# 输出量化器
self.output_quantizer = FakeQuantize(bits=bits, symmetric=symmetric)
# 初始化量化开关
self.set_quantize_state(quantize)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
# 量化最终输出(如果启用)
if self.quantize:
x = self.output_quantizer(x)
return x
def set_quantize_state(self, enabled=True):
"""
设置模型中所有可量化层的量化状态
"""
self.quantize = enabled
for m in self.modules():
if isinstance(m, (QuantizableConv2d, QuantizableLinear)):
m.quantize_enabled = enabled
# 训练函数
def train_model(model, dataloaders, criterion, optimizer, scheduler, num_epochs=10, device='cuda'):
"""
训练模型函数
"""
start_time = time.time()
# 保存最佳模型
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch+1}/{num_epochs}')
print('-' * 10)
# 每个epoch都有训练和验证阶段
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
# 遍历数据
for inputs, labels in tqdm(dataloaders[phase]):
inputs = inputs.to(device)
labels = labels.to(device)
# 梯度清零
optimizer.zero_grad()
# 前向传播
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 如果是训练阶段,则反向传播+优化
if phase == 'train':
loss.backward()
optimizer.step()
# 统计
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train' and scheduler is not None:
scheduler.step()
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# 如果是最佳验证精度,保存模型
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - start_time
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best val Acc: {best_acc:.4f}')
# 加载最佳模型权重
model.load_state_dict(best_model_wts)
return model
# 准备数据加载器
def get_dataloaders(batch_size=64):
"""
准备CIFAR-10数据加载器
"""
# 数据转换
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
# 加载CIFAR-10数据集
trainset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_train)
trainloader = DataLoader(
trainset, batch_size=batch_size, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform_test)
testloader = DataLoader(
testset, batch_size=batch_size, shuffle=False, num_workers=2)
return {'train': trainloader, 'val': testloader}
# 校准量化器函数
def calibrate_model(model, dataloader, num_batches=10, device='cuda'):
"""
使用校准数据集校准模型中的量化器
"""
# 收集每层激活值和权重的范围
model.eval()
model.set_quantize_state(False) # 关闭量化,以便收集原始值
# 遍历部分校准数据
with torch.no_grad():
for i, (inputs, _) in enumerate(dataloader):
if i >= num_batches:
break
inputs = inputs.to(device)
_ = model(inputs) # 前向传播
# 此时,所有伪量化器应该已经收集了范围信息
# 开启量化
model.set_quantize_state(True)
return model
# 评估函数
def evaluate_model(model, dataloader, criterion, device='cuda'):
"""
评估模型函数
"""
model.eval()
running_loss = 0.0
running_corrects = 0
# 关闭梯度计算
with torch.no_grad():
for inputs, labels in tqdm(dataloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 统计
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
# 计算总体损失和准确率
dataset_size = len(dataloader.dataset)
loss = running_loss / dataset_size
acc = running_corrects.double() / dataset_size
print(f'Test Loss: {loss:.4f} Acc: {acc:.4f}')
return loss, acc
# 量化感知训练的主流程
def main():
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 获取数据加载器
dataloaders = get_dataloaders(batch_size=64)
# 第1步:训练浮点模型
print("步骤1: 训练浮点模型")
fp_model = SimpleCNN(num_classes=10, quantize=False).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(fp_model.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
fp_model = train_model(fp_model, dataloaders, criterion, optimizer, scheduler, num_epochs=5, device=device)
# 保存浮点模型
torch.save(fp_model.state_dict(), 'fp_model.pth')
# 第2步:校准量化器
print("\n步骤2: 校准量化器")
qat_model = SimpleCNN(num_classes=10, quantize=True, bits=8, symmetric=False).to(device)
qat_model.load_state_dict(fp_model.state_dict()) # 加载预训练权重
# 校准
calibrate_model(qat_model, dataloaders['train'], num_batches=10, device=device)
# 评估校准后的模型
print("校准后模型评估:")
evaluate_model(qat_model, dataloaders['val'], criterion, device=device)
# 第3步:执行量化感知训练
print("\n步骤3: 量化感知微调")
# 注意:使用较小的学习率
qat_optimizer = optim.SGD(qat_model.parameters(), lr=0.001, momentum=0.9, weight_decay=5e-4)
qat_scheduler = optim.lr_scheduler.StepLR(qat_optimizer, step_size=30, gamma=0.1)
# 执行量化感知训练
qat_model = train_model(qat_model, dataloaders, criterion, qat_optimizer, qat_scheduler, num_epochs=3, device=device)
# 保存量化感知训练后的模型
torch.save(qat_model.state_dict(), 'qat_model.pth')
# 第4步:评估量化模型
print("\n步骤4: 评估量化模型")
print("量化感知训练后的模型评估:")
evaluate_model(qat_model, dataloaders['val'], criterion, device=device)
# 比较模型性能
print("\n模型性能比较:")
print("浮点模型 vs 量化模型")
print("---------------------")
# 评估浮点模型
fp_model.set_quantize_state(False)
fp_loss, fp_acc = evaluate_model(fp_model, dataloaders['val'], criterion, device=device)
# 评估量化模型
qat_model.set_quantize_state(True)
qat_loss, qat_acc = evaluate_model(qat_model, dataloaders['val'], criterion, device=device)
# 打印比较结果
print("\n精度对比:")
print(f"浮点模型准确率: {fp_acc:.4f}")
print(f"量化模型准确率: {qat_acc:.4f}")
print(f"精度损失: {fp_acc - qat_acc:.4f} ({(fp_acc - qat_acc) / fp_acc * 100:.2f}%)")
# 测量模型大小
fp_size = sum(p.numel() * 4 for p in fp_model.parameters()) / (1024 * 1024) # 浮点模型大小 (MB)
qat_size = sum(p.numel() * 1 for p in qat_model.parameters()) / (1024 * 1024) # 量化模型大小 (MB),假设使用INT8
print("\n模型大小对比:")
print(f"浮点模型大小: {fp_size:.2f} MB")
print(f"量化模型大小: {qat_size:.2f} MB")
print(f"压缩比: {fp_size / qat_size:.2f}x")
# 测量推理速度
def measure_inference_time(model, dataloader, device, num_iterations=100):
model.eval()
batch = next(iter(dataloader))
inputs = batch[0].to(device)
# 预热
with torch.no_grad():
for _ in range(10):
_ = model(inputs)
# 计时
torch.cuda.synchronize()
start_time = time.time()
with torch.no_grad():
for _ in range(num_iterations):
_ = model(inputs)
torch.cuda.synchronize()
end_time = time.time()
avg_time = (end_time - start_time) / num_iterations
return avg_time
# 测量浮点模型速度
fp_model.set_quantize_state(False)
fp_time = measure_inference_time(fp_model, dataloaders['val'], device)
# 测量量化模型速度
qat_model.set_quantize_state(True)
qat_time = measure_inference_time(qat_model, dataloaders['val'], device)
print("\n推理速度对比:")
print(f"浮点模型推理时间: {fp_time*1000:.2f} ms")
print(f"量化模型推理时间: {qat_time*1000:.2f} ms")
print(f"加速比: {fp_time / qat_time:.2f}x")
if __name__ == '__main__':
main()
3. 对称量化与非对称量化
量化方案主要可分为对称量化和非对称量化两种类型,它们各有优缺点。理解两者的差异对于选择合适的量化方案至关重要。
3.1 对称量化与非对称量化的原理
3.2 对称量化与非对称量化的特点对比
| 特性 | 对称量化 | 非对称量化 |
|---|---|---|
| 数值范围 | [-128, 127] (INT8) | [0, 255] (UINT8) 或 [-128, 127] (INT8) |
| 零点 (Zero Point) | 0 | 通常不为0 |
| 量化公式 | q = round(r / scale) | q = round(r / scale + zero_point) |
| 计算复杂度 | 低(无需减去zero_point) | 高(需要减去zero_point) |
| 内存效率 | 高 | 高 |
| 精度保持 | 对称分布数据较好 | 非对称分布数据较好 |
| 典型应用 | 权重量化 | 激活值量化 |
| 硬件友好度 | 高 | 中等 |
3.3 实现对称和非对称量化的示例
下面是同时实现对称和非对称量化的代码示例:
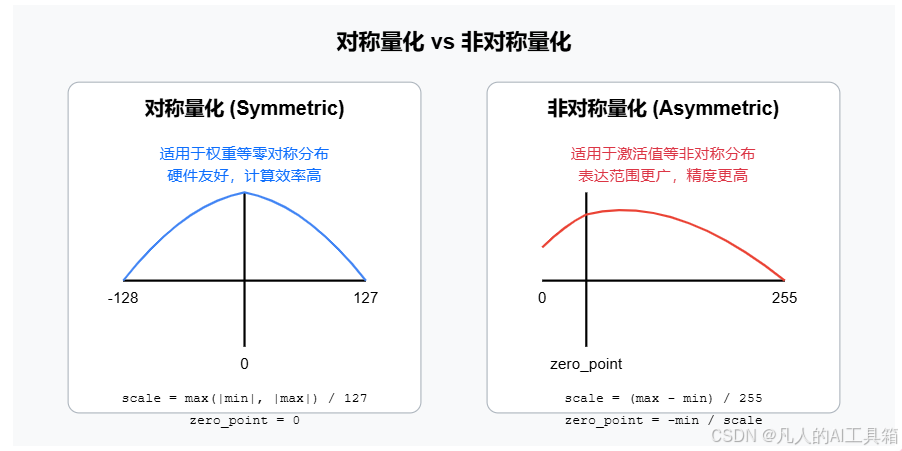
上面的代码提供了对称量化和非对称量化的实现,并且比较了它们在不同类型数据上的表现。结果表明,对于权重等近似对称分布的数据,对称量化效果较好;而对于偏向一侧的激活值,非对称量化通常表现更佳。
4. 混合精度推理优化
在实际应用中,并非所有层都需要相同的精度。混合精度推理是一种优化策略,它根据每层的敏感度选择不同的精度,从而在保持高精度的同时实现高效推理。
4.1 混合精度量化原理
混合精度量化的核心思想是:
- 对计算密集型层(如卷积层)使用低精度(INT8)
- 对精度敏感的层(如第一层和最后一层)保持高精度(FP16或FP32)
- 根据每层对精度的敏感度和对计算量的贡献,动态选择最合适的精度
4.2 混合精度内存优化策略
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import time
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
import copy
class LayerSensitivityAnalyzer:
"""
分析模型中每一层对量化的敏感度
"""
def __init__(self, model, dataloader, criterion, device='cuda'):
self.model = model
self.dataloader = dataloader
self.criterion = criterion
self.device = device
self.sensitivity_cache = {}
def analyze_layer_sensitivity(self, bits=8, num_batches=10):
"""
分析每一层对量化的敏感度
参数:
bits: 量化位数
num_batches: 用于分析的批次数
返回:
层敏感度字典 {layer_name: sensitivity_score}
"""
# 记录原始性能
original_accuracy = self._evaluate_model(self.model, num_batches)
print(f"原始模型准确率: {original_accuracy:.4f}")
sensitivity_dict = {}
# 遍历每一层
for name, module in self.model.named_modules():
if isinstance(module, (nn.Conv2d, nn.Linear)):
# 跳过已经分析过的层
if name in self.sensitivity_cache:
sensitivity_dict[name] = self.sensitivity_cache[name]
continue
# 保存原始权重
original_weight = module.weight.data.clone()
# 量化该层权重
module.weight.data = self._quantize_tensor(original_weight, bits)
# 测量量化后的准确率
quantized_accuracy = self._evaluate_model(self.model, num_batches)
# 计算敏感度分数 (准确率下降的百分比)
sensitivity = (original_accuracy - quantized_accuracy) / original_accuracy
sensitivity_dict[name] = sensitivity
self.sensitivity_cache[name] = sensitivity
# 恢复原始权重
module.weight.data = original_weight
print(f"层 {name} 敏感度: {sensitivity:.6f}")
return sensitivity_dict
def _quantize_tensor(self, tensor, bits):
"""简单的对称量化实现"""
qmin = -(2 ** (bits - 1))
qmax = 2 ** (bits - 1) - 1
scale = torch.max(torch.abs(tensor)) / qmax
tensor_q = torch.round(tensor / scale).clamp(qmin, qmax)
tensor_dq = tensor_q * scale
return tensor_dq
def _evaluate_model(self, model, num_batches):
"""评估模型在子集上的准确率"""
model.eval()
correct = 0
total = 0
with torch.no_grad():
for i, (inputs, labels) in enumerate(self.dataloader):
if i >= num_batches:
break
inputs, labels = inputs.to(self.device), labels.to(self.device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return correct / total
class MixedPrecisionQuantizer:
"""
混合精度量化器
根据每一层的敏感度分配不同的量化位宽
"""
def __init__(self, model, sensitivity_dict, bits_options=[8, 4, 2], default_bits=8):
self.model = model
self.sensitivity_dict = sensitivity_dict
self.bits_options = bits_options
self.default_bits = default_bits
# 排序敏感度
self.sorted_layers = sorted(sensitivity_dict.items(), key=lambda x: x[1], reverse=True)
def auto_mixed_precision(self, threshold_percentile=0.7):
"""
自动混合精度量化
根据敏感度阈值确定每层的位宽
参数:
threshold_percentile: 高敏感度的百分比阈值
返回:
位宽分配字典 {layer_name: bits}
"""
# 确定敏感度阈值
sensitivities = [s for _, s in self.sorted_layers]
threshold = np.percentile(sensitivities, threshold_percentile * 100)
# 分配位宽
bits_allocation = {}
for name, sensitivity in self.sorted_layers:
if sensitivity > threshold:
# 高敏感度层使用最高精度
bits_allocation[name] = max(self.bits_options)
else:
# 低敏感度层根据敏感度分配不同位宽
norm_sensitivity = sensitivity / threshold
# 线性映射敏感度到位宽选项
idx = min(int(norm_sensitivity * len(self.bits_options)), len(self.bits_options) - 1)
bits_allocation[name] = sorted(self.bits_options)[idx]
return bits_allocation
def apply_mixed_precision(self, bits_allocation):
"""
应用混合精度量化
参数:
bits_allocation: 位宽分配字典 {layer_name: bits}
返回:
量化后的模型
"""
# 创建模型的深拷贝
quantized_model = copy.deepcopy(self.model)
# 应用不同位宽的量化
for name, module in quantized_model.named_modules():
if isinstance(module, (nn.Conv2d, nn.Linear)) and name in bits_allocation:
bits = bits_allocation[name]
# 量化权重
module.weight.data = self._quantize_tensor(module.weight.data, bits)
print(f"层 {name} 使用 {bits}位量化")
return quantized_model
def _quantize_tensor(self, tensor, bits):
"""简单的对称量化实现"""
qmin = -(2 ** (bits - 1))
qmax = 2 ** (bits - 1) - 1
scale = torch.max(torch.abs(tensor)) / qmax
scale = max(scale, 1e-8) # 避免除以0
tensor_q = torch.round(tensor / scale).clamp(qmin, qmax)
tensor_dq = tensor_q * scale
return tensor_dq
def visualize_allocation(self, bits_allocation):
"""
可视化位宽分配
"""
layer_names = list(bits_allocation.keys())
bits_values = list(bits_allocation.values())
sensitivities = [self.sensitivity_dict[name] for name in layer_names]
# 绘制敏感度和位宽分配
fig, ax1 = plt.subplots(figsize=(12, 6))
# 敏感度柱状图
bars = ax1.bar(range(len(layer_names)), sensitivities, alpha=0.7, color='skyblue')
ax1.set_xlabel('网络层')
ax1.set_ylabel('敏感度', color='blue')
ax1.tick_params(axis='y', labelcolor='blue')
ax1.set_xticks(range(len(layer_names)))
ax1.set_xticklabels(layer_names, rotation=90)
# 位宽折线图
ax2 = ax1.twinx()
ax2.plot(range(len(layer_names)), bits_values, 'ro-', linewidth=2)
ax2.set_ylabel('量化位宽', color='red')
ax2.tick_params(axis='y', labelcolor='red')
# 为每个柱子标注位宽
for i, v in enumerate(bits_values):
ax2.text(i, v + 0.1, str(v), ha='center', color='red', fontweight='bold')
plt.title('网络层敏感度分析与位宽分配')
fig.tight_layout()
plt.savefig('mixed_precision_allocation.png')
plt.close()
class MemoryOptimizer:
"""
内存优化器
在推理过程中优化内存使用
"""
def __init__(self, model):
self.model = model
def estimate_memory_usage(self, input_shape=(1, 3, 224, 224), dtype=torch.float32):
"""
估计模型的内存使用情况
参数:
input_shape: 输入张量形状
dtype: 数据类型
返回:
每层的内存使用估计 (MB)
"""
# 清空CUDA缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()
memory_usage = {}
hooks = []
def get_layer_memory(name):
def hook(module, input, output):
# 估计激活值的内存使用
if isinstance(output, torch.Tensor):
output_size = output.nelement() * output.element_size()
memory_usage[name]['output'] = output_size / (1024 * 1024) # MB
elif isinstance(output, tuple) and len(output) > 0:
output_size = sum(out.nelement() * out.element_size() for out in output if isinstance(out, torch.Tensor))
memory_usage[name]['output'] = output_size / (1024 * 1024) # MB
# 估计参数的内存使用
params_size = sum(p.nelement() * p.element_size() for p in module.parameters() if p.requires_grad)
memory_usage[name]['params'] = params_size / (1024 * 1024) # MB
# 估计梯度的内存使用
grads_size = sum(p.nelement() * p.element_size() for p in module.parameters() if p.requires_grad and p.grad is not None)
memory_usage[name]['grads'] = grads_size / (1024 * 1024) # MB
return hook
# 注册钩子
for name, module in self.model.named_modules():
if isinstance(module, (nn.Conv2d, nn.Linear, nn.BatchNorm2d)):
memory_usage[name] = {'output': 0, 'params': 0, 'grads': 0}
hooks.append(module.register_forward_hook(get_layer_memory(name)))
# 执行前向传播
x = torch.randn(input_shape, dtype=dtype)
if torch.cuda.is_available():
x = x.cuda()
self.model.cuda()
with torch.no_grad():
self.model(x)
# 移除钩子
for hook in hooks:
hook.remove()
return memory_usage
def optimize_memory_footprint(self, mixed_precision_bits, input_shape=(1, 3, 224, 224)):
"""
基于混合精度配置优化内存占用
参数:
mixed_precision_bits: 混合精度位宽分配
input_shape: 输入形状
返回:
优化前后的内存使用对比
"""
# 估计浮点模型内存使用
fp32_memory = self.estimate_memory_usage(input_shape)
# 估计混合精度模型内存使用
mixed_memory = copy.deepcopy(fp32_memory)
for name, bits in mixed_precision_bits.items():
if name in mixed_memory:
# 根据位宽缩放参数内存
scale_factor = bits / 32 # 相对于FP32的比例
mixed_memory[name]['params'] *= scale_factor
# 计算总内存使用
fp32_total = sum(layer['params'] + layer['output'] for layer in fp32_memory.values())
mixed_total = sum(layer['params'] + layer['output'] for layer in mixed_memory.values())
savings = (fp32_total - mixed_total) / fp32_total * 100
print(f"FP32模型总内存占用: {fp32_total:.2f} MB")
print(f"混合精度模型总内存占用: {mixed_total:.2f} MB")
print(f"内存节省: {savings:.2f}%")
# 可视化内存使用对比
self._visualize_memory_usage(fp32_memory, mixed_memory, mixed_precision_bits)
return {'fp32': fp32_memory, 'mixed': mixed_memory, 'savings': savings}
def _visualize_memory_usage(self, fp32_memory, mixed_memory, bits_allocation):
"""
可视化内存使用对比
"""
layer_names = list(fp32_memory.keys())
fp32_params = [mem['params'] for mem in fp32_memory.values()]
mixed_params = [mem['params'] for mem in mixed_memory.values()]
# 获取对应的位宽
bits = [bits_allocation.get(name, 32) for name in layer_names]
# 绘制参数内存使用对比
plt.figure(figsize=(12, 6))
x = np.arange(len(layer_names))
width = 0.35
plt.bar(x - width/2, fp32_params, width, label='FP32', color='blue', alpha=0.7)
plt.bar(x + width/2, mixed_params, width, label='混合精度', color='green', alpha=0.7)
plt.xlabel('网络层')
plt.ylabel('内存占用 (MB)')
plt.title('FP32 vs 混合精度参数内存占用')
plt.xticks(x, layer_names, rotation=90)
plt.legend()
# 添加位宽标签
for i, (b, m) in enumerate(zip(bits, mixed_params)):
plt.text(i + width/2, m + 0.1, f"{b}bit", ha='center', va='bottom', fontsize=8, rotation=90)
plt.tight_layout()
plt.savefig('memory_usage_comparison.png')
plt.close()
def demonstration():
"""混合精度量化的演示"""
# 设置随机种子
torch.manual_seed(42)
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 加载数据
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 使用CIFAR-10数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers=2)
# 创建简单的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(128 * 28 * 28, 512),
nn.ReLU(inplace=True),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 初始化模型
model = SimpleCNN().to(device)
# 为了演示目的,我们只训练几个epoch
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
print("训练模型...")
model.train()
for epoch in range(2): # 只训练2个epoch用于演示
running_loss = 0.0
for i, (inputs, labels) in enumerate(tqdm(trainloader)):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print(f'[{epoch + 1}, {i + 1}] loss: {running_loss / 100:.3f}')
running_loss = 0.0
print("模型训练完成")
# 评估原始模型
correct = 0
total = 0
model.eval()
with torch.no_grad():
for inputs, labels in tqdm(testloader):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'原始模型准确率: {100 * correct / total:.2f}%')
# 1. 层敏感度分析
print("\n1. 开始层敏感度分析...")
analyzer = LayerSensitivityAnalyzer(model, testloader, criterion, device)
sensitivity_dict = analyzer.analyze_layer_sensitivity(bits=8, num_batches=5)
# 2. 自动混合精度量化
print("\n2. 应用混合精度量化...")
quantizer = MixedPrecisionQuantizer(model, sensitivity_dict, bits_options=[8, 4, 2])
bits_allocation = quantizer.auto_mixed_precision(threshold_percentile=0.7)
# 可视化位宽分配
quantizer.visualize_allocation(bits_allocation)
# 应用混合精度量化
quantized_model = quantizer.apply_mixed_precision(bits_allocation)
# 3. 内存优化分析
print("\n3. 分析内存优化...")
memory_optimizer = MemoryOptimizer(model)
memory_stats = memory_optimizer.optimize_memory_footprint(bits_allocation, input_shape=(1, 3, 224, 224))
# 评估量化后的模型
correct = 0
total = 0
quantized_model.eval()
with torch.no_grad():
for inputs, labels in tqdm(testloader):
inputs, labels = inputs.to(device), labels.to(device)
outputs = quantized_model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'混合精度量化模型准确率: {100 * correct / total:.2f}%')
# 4. 对比不同量化策略
print("\n4. 对比不同量化策略...")
# 全部8位量化
bits_all_8 = {name: 8 for name in bits_allocation.keys()}
model_all_8 = quantizer.apply_mixed_precision(bits_all_8)
# 全部4位量化
bits_all_4 = {name: 4 for name in bits_allocation.keys()}
model_all_4 = quantizer.apply_mixed_precision(bits_all_4)
# 评估全8位模型
correct = 0
total = 0
model_all_8.eval()
with torch.no_grad():
for inputs, labels in tqdm(testloader):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model_all_8(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc_all_8 = 100 * correct / total
print(f'全8位量化模型准确率: {acc_all_8:.2f}%')
# 评估全4位模型
correct = 0
total = 0
model_all_4.eval()
with torch.no_grad():
for inputs, labels in tqdm(testloader):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model_all_4(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc_all_4 = 100 * correct / total
print(f'全4位量化模型准确率: {acc_all_4:.2f}%')
# 比较不同量化策略的内存使用
memory_all_8 = memory_optimizer.optimize_memory_footprint(bits_all_8)
memory_all_4 = memory_optimizer.optimize_memory_footprint(bits_all_4)
# 可视化比较
strategies = ['FP32', '混合精度', '全8位', '全4位']
memory_sizes = [
sum(layer['params'] for layer in memory_stats['fp32'].values()),
sum(layer['params'] for layer in memory_stats['mixed'].values()),
sum(layer['params'] for layer in memory_all_8['mixed'].values()),
sum(layer['params'] for layer in memory_all_4['mixed'].values())
]
accuracies = [
100 * correct / total, # 原始FP32准确率,重用之前的计算
100 * correct / total, # 混合精度准确率,重用之前的计算
acc_all_8,
acc_all_4
]
# 绘制内存大小和准确率的对比
fig, ax1 = plt.subplots(figsize=(10, 6))
color = 'tab:blue'
ax1.set_xlabel('量化策略')
ax1.set_ylabel('内存占用 (MB)', color=color)
bars = ax1.bar(strategies, memory_sizes, color=color, alpha=0.7)
ax1.tick_params(axis='y', labelcolor=color)
# 添加数据标签
for bar in bars:
height = bar.get_height()
ax1.annotate(f'{height:.2f}',
xy=(bar.get_x() + bar.get_width() / 2, height),
xytext=(0, 3), # 3点垂直偏移
textcoords="offset points",
ha='center', va='bottom', color=color)
ax2 = ax1.twinx()
color = 'tab:red'
ax2.set_ylabel('准确率 (%)', color=color)
line = ax2.plot(strategies, accuracies, color=color, marker='o', linestyle='-', linewidth=2)
ax2.tick_params(axis='y', labelcolor=color)
# 添加数据标签
for i, acc in enumerate(accuracies):
ax2.annotate(f'{acc:.2f}%',
xy=(i, acc),
xytext=(0, -15),
textcoords="offset points",
ha='center', va='bottom', color=color)
plt.title('不同量化策略的内存占用与准确率对比')
fig.tight_layout()
plt.savefig('quantization_strategies_comparison.png')
plt.close()
print("\n演示完成,结果已保存为图片。")
if __name__ == "__main__":
demonstration()
上面的代码实现了一个完整的混合精度量化系统,包括层敏感度分析、自动位宽分配和内存优化策略。这个系统可以根据每一层对量化的敏感度,动态分配不同的量化位宽,在保证模型精度的同时最大化内存和计算效率。
4.3 混合精度量化的内存优化策略
在实际部署中,我们可以采用以下策略进一步优化混合精度推理的内存使用:
- 激活值重用:在前向传播时,及时释放不再需要的中间激活值内存
- 权重预取:针对不同精度的权重,实现高效的内存访问模式
- 计算调度优化:根据内存占用和计算需求,动态调整计算顺序
- 量化感知内存分配:在模型编译时,考虑不同层的精度需求,合理分配内存
下表总结了不同精度量化的内存和性能影响:
| 精度类型 | 内存占用 | 计算速度 | 典型精度损失 | 适用层类型 |
|---|---|---|---|---|
| FP32 | 高 | 慢 | 无损失 | 精度敏感层、第一层、最后一层 |
| FP16 | 中 | 中 | <0.1% | 精度敏感层、复杂激活函数 |
| INT8 | 低 | 快 | 0.5-1% | 卷积层、全连接层主体 |
| INT4 | 极低 | 极快 | 1-5% | 参数冗余的大型层 |
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!