半导体过程控制篇6 设计质量控制SPC
设计质量控制
设计定义与过程
ISO9001对设计的定义:将对客体的要求转换为对其更详细的要求的一组过程
设计质量的定义:所设计的产品是否能够满足顾客需求,是否易于制造和维护,经济性是否合理,对生态环境是否造成危害风险,是否最小等。
控制质量要素包括:标识因素,误差因素,控制因素,信号因素。
产品质量设计模型包含的基本要素:信号因素(即收入因素),误差因素(即噪声因素),设计参数(即可控因素),质量特性(即输出特性)
产品质量设计模型的流程:
1.首先明确,产品的质量特性值Y与对其有影响的设计参数X和误差因素Z有关。
这种变量或变量组间的相关性可用函数表示:
y
=
f
(
x
,
z
)
y=f(x,z)
y=f(x,z)
2.如果通过一组的实验,观测到产品质量特性的一组值(相当于实验室的同学或同事直接给你他实验所得的数据),我们称这一组为实验组。这样就可以计算该组值的均值为:
y
‾
∑
y
i
\overline{y}\sum y_i
y∑yi
标准差为:
s
=
1
N
−
1
∑
(
y
i
−
y
‾
)
s=\sqrt{\frac{1}{N-1}\sum(y_i-\overline{y})}
s=N−11∑(yi−y)
3.为例验证产品的性能稳定,应使得设计输出结果的均值满足实验组产品特性的均值等于目标特征值:
y
‾
恒等于
y
9
\overline{y}恒等于y_9
y恒等于y9
标准差满足实验组的产品特征值的标准差小于目标标准差极限偏差与某一常数的比值:
∣
s
∣
<
q
k
∣
Δ
y
∣
|s|<\frac{q}{k}|\Delta y|
∣s∣<kq∣Δy∣
k为常数。
设计质量特性
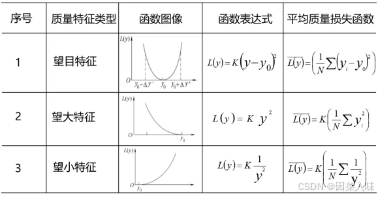
设计质量评价指标(定量描述):部分缺陷、功能特性指数、质量损失函数、质量信息熵函数
这些评价指标拥有不同的特性,对这些特性进行分类,能得到“设计质量特性的分类”:
(1)输出特性和原因特性
(2)计量特性和计数特性
(3)静态特性和动态特性
(4)望目特性、望大特性、望小特性
其中质量损失函数的质量特征类型有望目特性、望大特性、望小特性
质量功能展开(QFD)
质量功能展开(QFD)的含义(QFD包含两层含义):
(1)狭义的质量功能展开,即用目的手段,将形成质量的功能乃至业务,以不同的层次展开到具体的部分;
(2)质量展开,是将顾客的需要转换为图样和设计要求及产品生产过程中各阶段的要求,以确定产品的设计质量,并将其系统、关联地展开到设计要求、零部件要求、工艺要求以及工序要求等过程。
TRIZ理论
TRIZ设计理论所用的工具:
(1)产品的进化分析
(2)矛盾矩阵
(3)39个通用工程参数
(5)分离原理
(4)40条发明原理
(6)分离原理与发明原理的关系
稳健设计方法(田口设计方法)
稳健设计方法中稳健设计的定义:稳健设计是一种低成本、高质量的统计分析设计方法
国际上又称为“田口方法”。
产品的设计优化过程分为三个阶段:系统设计、参数设计、容差设计。
稳健设计方法(田口设计方法)中稳健设计的基本原理:在设计产品或工艺时,就考虑到产品在制造和使用中各种因素发生偏差,以及在规定的寿命期间内产品发生老化、性能变差时,都要求能使产品的性能保持稳定。
稳健设计方法的流程:
1.系统设计:产品设计的第一次设计称为系统设计,是指决定产品功能和结构的设计。
2.参数设计:产品设计的第二次设计称为参数设计,它是稳健设计的核心。这一阶段是为了提高和保证产品性能,同时考虑成本因素,以优化产品性能为目标,设计出质量稳定、成本合理的产品。
3.容差设计:产品设计的第三次设计称为容差设计。容差设计就是在产品质量设计过程中,通过控制可控因素的容差,衰减或缩小误差因
素所引起的产品质量波动,调整产品质量与成本关系的一种设计方法。
正交实验设计
正交实验设计的目的:运用正交试验设计技术可构造一些正交向量,从许多试验因素组合中选择出最具有代表性的少量试验,就能获得可靠的试验结果。
正交试验设计的步骤为:
1)应先确定各个试验因素的个数及其水平数;
2)分析各个影响因素之间是否有相互作用;
3)根据人力、物力、时间、费用等确定大概的试验次数;
4)最后选用合适的正交表,安排试验。
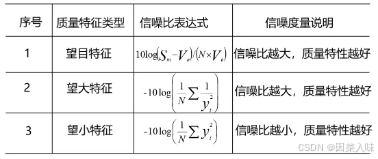
信噪比(SN比)
稳健设计方法(田口设计方法)中信噪比(SN比)的定义:SN比指影响产品质量特性的主效应与误差效应的比值(其中主效应相当于信号,误差效应相当于噪音)。
信噪比作用:在设计质量控制中,用信噪比模拟误差因素(即噪音效应)对产品设计质量特性的影响。
用信噪比表示的质量损失函数,即信噪比的计算公式:
应用举例
在我们这个半导体行业中,稳健设计方法可以应用于芯片设计、制造和测试等方面。以下是一些具体的例子:
(1)芯片设计:在芯片设计过程中,稳健设计方法可以用于优化电路的可靠性和抗干扰能力。
例如,通过增加几余电路和错误检测与纠正电路,可以提高芯片的容错性,减少故障率。
此外,稳健设计方法还可以用于优化电路的功耗和性能,以确保芯片在各种工作条件下都能稳定运行。
(2)制造过程:在半导体芯片的制造过程中,稳健设计方法可以用于提高制造工艺的稳定性和一致性。
例如,通过使用统计分析和过程控制技术,可以减少制造过程中的变异性,提高芯片的质量和可靠性。
此外,稳健设计方法还可以用于优化材料选择合适的工艺参数,以提高芯片的性能和可靠性。
(3)测试和可靠性验证:在芯片测试和可靠性验证过程中,稳健设计方法可以用于设计测试方案和评估芯片的可靠性。
例如,通过使用故障注入和故障模拟技术,可以评估芯片在不同故障条件下的性能和可靠性。
此外,稳健设计方法还可以用于设计可靠性测试和可靠性验证方案,以确保芯片在各种工作条件下都能稳定运行。
总之,稳健设计方法在半导体行业中可以应用于芯片设计、制造和测试等方面,以
提高芯片的可靠性、性能和一致性。
统计过程控制SPC技术(过程能力分析)
shewhat(休哈特)对过程的定义:共同作用产生某个特定结果的任意一组条件或因素。
shewhat(休哈特)对控制的定义:为了当前的某个目的,如果我们利用过去的经验,能够在一定范围内预测一个现象在未来会如何变化,那么我们就说这个现象是受控制的
shewhat(休哈特)发明了我们接下来要学的控制图。控制图的目的,就是让数据能说话,说我们能轻松听懂的话。
过程能力分析
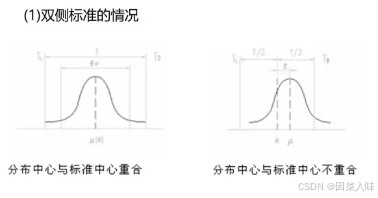
过程能力Process Caoability的定义:处于稳定状态下的过程满足质量要求的能力。
过程能力指数的定义:表示过程能力对过程质量标准的满足程度。
过程能力指数的计算
双侧标准时:
单侧标准的情况:
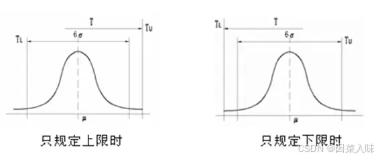
分布中心与标准中心重合时的总不合格率:
分布中心与标准中心不重合的总不合格率:
{
P
=
P
u
+
P
L
,
分布中心向标准上限偏移时
/
/
P
=
P
u
+
P
L
,
分布中心向标准下限偏移时
\begin{cases} P=P_u+P_L,分布中心向标准上限偏移时//P=P_u+P_L,分布中心向标准下限偏移时 \end{cases}
{P=Pu+PL,分布中心向标准上限偏移时//P=Pu+PL,分布中心向标准下限偏移时
质量问题的类型包括:结构式质量问题、半结构式质量问题、病态结构质量问题
质量问题与质量改进的关系:质量改进是在受控质量系统的基础上,通过发现和解决长期影响质量水平的系统性问题使系统的变异水平达到一个前所未有的低水平。
质量改进的过程(即PDCA循环):PDCA是英语Plan-Do-Check-Action(策划-实施-检查-处理)三个英文首字母的组合。
6 σ \sigma σ系统
6西格玛管理的统计意义:产品或过程的规格界限(Specification Limits)实际上体现的是顾客的需求情况,它是指顾客对产品或过程的规格、性能所能容忍的波动范围。
6 σ \sigma σ是一种以减少过程变异和缺陷为目标的质量管理方法。
6
σ
\sigma
σ的目标是将过程的缺陷率控制在每百万个机会中不超过3.4个。
6西格玛管理中产品或过程的规格界限:(specification limits)的含义:实际上体现的是顾客的需求情况,它是指顾客对产品或过程的规格、性能所能容忍的波动范围。
6西格玛管理中质量改进方法的五个步骤:Define,Measure,Analyze,Improve,Control
6 σ \sigma σ结合了统计方法和管理理念,通过DMAIC(Define, Measure, Analyze, Improve, Control)的阶段性循环来改进和优化过程。
6 σ \sigma σ管理中PDCA模式的内容: PDCA(Plan, Do, Check, Act)循环是一种基本的质量管理方法,也被称为德鲁克循环。它通过制定计划、执行计划、检查结果和采取行动的循环过程,实现过程改进和问题解决。PDCA循环强调持续改进和逐步优化。
6 σ \sigma σ的应用举例:
假设你是一家半导体制造公司的工艺工程师,负责改进芯片制造过程中的某个关键步骤。你希望通过六西格玛设计方法来减少制造过程中的变异性,提高产品的一致性和质量。
1.首先,你需要确定关键的质量指标和目标。例如,你可以选择芯片的性能参数作为质量指标,如功耗、速度等。然后,你需要设定合理的目标值,即希望芯片在制造过程中达到的性能水平。
2.接下来,你需要收集和分析数据,以了解当前制造过程中的变异性和缺陷情况。这可以包括收集芯片的测试数据、制造过程的参数和设备的性能数据等。通过统计分析和数据挖掘技术,你可以确定制造过程中的主要变异源和影响因素。
3.然后,你可以使用六西格玛工具,如控制图、因果图、流程图和实验设计等,来识别和优化制造过程中的关键参数。例如,你可以使用因果图来分析制造过程中的各种因素和变异源之间的关系,以确定影响芯片性能的主要因素。然后,你可以使用实验设计方法来优化这些关键参数,以达到目标值并减少变异性。
4.在实施优化方案之后,你需要进行验证和监控。通过收集和分析实际生产数据,你可以评估优化方案的效果,并进行必要的调整和改进。这可以包括使用统计过程控制方法来监控制造过程的稳定性和一致性。
通过应用六西格玛设计方法,你可以在半导体制造中改进关键步骤的质量和效率。这可以帮助提高产品的一致性和可靠性,减少缺陷率和废品率,从而提高公司的竞争力和客户满意度。
SPC与各种图表类型
SPC的定义:SPC是统计过程控制(Statistical Process Control)的缩写。它是一种用于监控和改进过程稳定性和质量的统计方法。
统计过程控制的目标是通过收集、分析和解释过程中的数据,以了解过程的性能,并采取相应的措施来保持过程在可接受的变异范围内。
SPC可以应用于制造业和服务业中的各种过程,包括生产线、服务交付、质量检验等。
SPC主要包括以下几个方面的内容:
1. 数据收集:通过收集过程中的数据来了解过程的性能。数据可以是来自样本的测量结果,如尺寸、重量、时间等。
2. 统计分析:对收集到的数据进行统计分析,以了解过程的中心位置、变异程度和分布特征。常用的统计分析方法包括均值、范围、方差、直方图、控制图等。
3. 控制图:使用控制图来监控过程的稳定性。控制图是一种图表,通过绘制过程数据的统计指标,如均值、范围或标准差,以及控制限线,来判断过程是否处于统计控制状态。常见的控制图包括Xbar-R图、Xbar-S图、P图、C图等。
Xbar是$\overline{x}$的读法
4. 过程改进:当控制图显示过程出现异常或超出控制限时,需要进行相应的分析和改进措施。通过识别和消除特殊因素,改善过程的稳定性和质量。
上文第4步中“通过识别和消除特殊因素”一句中的特殊因素,就是所谓的“波动”。
在生产过程中,产品的加工尺寸的波动是不可避免的。它是由人、机器、材料、方法和环境等基本因素的波动影响所致。
波动分为两种:正常波动和异常波动。
正常波动是偶然性原因(不可避免因素)造成的。它对产品质量影响较小,在技术上难以消除,在经济上也不值得消除。
异常波动是由系统原因(异常因素)造成的。它对产品质量影响很大,但能够采取措施避免和消除。
过程控制的目的就是消除、避免异常波动,使过程处于正常波动状态。
接下来,我们详细分析一下SPC中的第3步:控制图。
控制图又分为两种——属性控制图和变量控制图
属性控制图
控制图的定义:控制图是一种图表,通过绘制过程数据的统计指标,如均值、范围或标准差,以及控制限线,来判断过程是否处于统计控制状态。常见的控制图包括Xbar-R图、Xbar-S图、P图、C图等。
Xbar是
x
‾
\overline{x}
x的读法
绘制控制图表的目的:用来检测过程性能中变化的发生,以便采取深入检查和正确的动作
控制图表的组成:中心线,代表对应于一个控制下状态特性的平均值;上限控制线UCL(中心值向上取3
σ
\sigma
σ)(要求的上限USL);要求的控制下限LCL(中心值向下取
3
σ
3\sigma
3σ)(要求的下限LSL)
UCL、LSL本质目的就是构建一个置信区间
我们都希望过程在控制之中。判断过程在控制之中的标准包括:
1.大约三分之二的点将落在中心线附近
2.一些点将接近控制界限
3.这些点将落在中心线两侧
4.中心线两侧的点数将保持平衡
5.控制界限之外没有点
6.如果我似统计所有的点,并把他们画在图的一侧,将形成一个近似的对称分布
过程"失去控制"的原则性定义:
1.有点落在了它的控制界限之外,意味着过程受到特殊原因所扰乱(这是最简单的判断过程失去控制的方法);
2.过程呈现非自然模式,比如多个点连续在中线以下或以上,预示过程可能或潜在处于失控状态。
非自然状态
非自然状态nonnatural,又称为非随机模式(nonrandom)
判断非自然模式(即如何判断控制图的异常)的一组规则:
(1)任一单个点处于3
σ
\sigma
σ控制限之外
(2)3个连续点中有2个处在2
σ
\sigma
σ警示限之外
(3)5个连续点中有4个处于1
σ
\sigma
σ警示限之外(B区)
(4)9个连续点处在中心线同侧
(5)6个连续点持续增加或减少
(6)14个连续点交替上升和下降
(7)15个连续点处于1
σ
\sigma
σ的两侧
(8)连续8个点落在中心线两侧,且无一在1
σ
\sigma
σ范围内
以上规则分别应用于8种模式,用于判别可能的、潜在的失控行为
不符合分值图表(缺陷存在概率图表,或叫p图表)
p图:代表缺陷单元在总数中所占的比例,也就是缺陷部件的比例。在辨别特殊变化原因时,该图是最灵敏的第三种制图
一般步骤:

对“一般步骤”中的各项参数进行详细解释:
p
=
D
n
p=\frac{D}{n}
p=nD
{
U
C
L
=
p
+
3
p
(
1
−
p
)
n
中心线
=
p
L
C
L
=
p
−
3
p
(
1
−
p
)
n
\begin{cases} UCL=p+3\sqrt{\frac{p(1-p)}{n}}\\ 中心线=p\\LCL=p-3\sqrt{\frac{p(1-p)}{n}} \end{cases}
⎩
⎨
⎧UCL=p+3np(1−p)中心线=pLCL=p−3np(1−p)
UCL中的u指upper,LCL中的l指lower
如果在第i组样本中有
D
i
D_i
Di件含有缺陷的样品,则个体存在缺陷的平均概率为:
p
i
=
D
i
n
p_i=\frac{D_i}{n}
pi=nDi
个体存在缺陷的平均概率为: p ‾ = 1 m n ∑ i = 1 m n D i \overline{p}=\frac{1}{mn} \sum_{i=1}^{mn} D_i p=mn1i=1∑mnDi
将 p i = D i n p_i=\frac{D_i}{n} pi=nDi代入得到: p ‾ = 1 m ∑ i = 1 m n p i \overline{p}=\frac{1}{m} \sum_{i=1}^{mn} p_i p=m1i=1∑mnpi
此时p图标的中心线和两个控制界限(即图表的参数)为: { U C L = p ‾ + 3 p ‾ ( 1 − p ‾ ) n 中心线 = p ‾ L C L = p ‾ − 3 p ‾ ( 1 − p ‾ ) n \begin{cases} UCL=\overline{p}+3\sqrt{\frac{\overline{p}(1-\overline{p})}{n}}\\ 中心线=\overline{p}\\LCL=\overline{p}-3\sqrt{\frac{\overline{p}(1-\overline{p})}{n}} \end{cases} ⎩ ⎨ ⎧UCL=p+3np(1−p)中心线=pLCL=p−3np(1−p)
Z i = p i − p p ( 1 − p ) n i Z_i=\frac{p_i-p}{\sqrt{\frac{p(1-p)}{n_i}}} Zi=nip(1−p)pi−p
p图表计算上下控制限的例题
例1 考虑一个连线操作。假定从30个芯片中已经收集到尺寸为n = 50的30个样本。给定总数为347个找到的缺陷连线,为这个过程建立±30 p图表。
首先确定参数。每个芯片上有50(n=50)个晶粒,有这样的芯片30(m=30)个。缺陷的总数
∑
i
=
1
m
n
D
i
\sum_{i=1}^{mn} D_i
∑i=1mnDi。
由公式
p
‾
=
1
m
n
∑
i
=
1
m
n
D
i
\overline{p}=\frac{1}{mn} \sum_{i=1}^{mn} D_i
p=mn1∑i=1mnDi得到
p
‾
=
347
30
⋅
50
=
0.2313
\overline{p}=\frac{347}{30\cdot 50}=0.2313
p=30⋅50347=0.2313
再由公式 { U C L = p ‾ + 3 p ‾ ( 1 − p ‾ ) n 中心线 p ‾ L C L = p ‾ − 3 p ‾ ( 1 − p ‾ ) n \begin{cases} UCL=\overline{p}+3\sqrt{\frac{\overline{p}(1-\overline{p})}{n}}\\中心线\overline{p}\\LCL=\overline{p}-3\sqrt{\frac{\overline{p}(1-\overline{p})}{n}} \end{cases} ⎩ ⎨ ⎧UCL=p+3np(1−p)中心线pLCL=p−3np(1−p)可以求得 U C L = 0.41 , L C L = 0.052 UCL=0.41,LCL=0.052 UCL=0.41,LCL=0.052
例2 假设某家电公司每天生产1000件产品,他们每天都会检查产品的质量,并记录下每天的缺陷数。他们收集了连续20天的数据,如下所示:
| 天数 | 缺陷数 |
|---|---|
| 1 | 30 |
| 2 | 20 |
| 3 | 40 |
| 4 | 10 |
| 5 │ 20 | |
| 6 | 30 |
| 7 | 20 |
| 8 | 50 |
| 9 | 30 |
| 10 | 20 |
| 11 | 40 |
| 12 | 10 |
| 13 | 20 |
| 14 | 30 |
| 15 | 20 |
| 16 | 40 |
| 17 | 10 |
| 18 | 20 |
| 19 | 30 |
| 20 | 10 |
求得平均缺陷率$\overline{p}=2.5%$,标准差$\sigma=0.49%$,由此求得上控制限和下控制限
p图表的局限性
构造一个P图表,要求样本尺寸、取样频率和控制界宽度都要给出。取样尺寸和取样频率是相关联的。
如果p非常小,则n必须充分大,p图表才有效。足够大的n才能使得p图表具有一个正的下控制界。
因此提出了另一种图表——缺陷图标(c图表)
缺陷图表(c图表)
直接控制缺陷的数量,而不是缺陷存在的概率。
u图:用于每单元缺陷数的控制图
c图:用于缺陷数的控制图
np图:用于缺陷单元数的控制图
用c代表泊松分布的参数,得到: P ( x ) = e − x c x x ! P(x)=\frac{e^{-x}c^x}{x!} P(x)=x!e−xcx
{
U
C
L
=
c
+
3
c
中心线
=
c
L
C
L
=
c
−
3
c
\begin{cases} UCL=c+3\sqrt{c}\\ 中心线=c\\LCL=c-3\sqrt{c} \end{cases}
⎩
⎨
⎧UCL=c+3c中心线=cLCL=c−3c
当LCL计算得到一个负值时,取
L
C
L
=
0
LCL=0
LCL=0
从实验组的数据中求出这个均值
c
‾
\overline{c}
c:
{
U
C
L
=
c
‾
+
3
c
‾
中心线
=
c
‾
L
C
L
=
c
‾
−
3
c
‾
\begin{cases} UCL=\overline{c}+3\sqrt{\overline{c}}\\ 中心线=\overline{c}\\LCL=\overline{c}-3\sqrt{\overline{c}} \end{cases}
⎩
⎨
⎧UCL=c+3c中心线=cLCL=c−3c
c图表的例题
例1 假定对26个硅圆片的检查得到516个缺陷,为这种情形构造一个c图表。
如果已知N个样本中有c个缺陷,那么我们令 u = c n u=\frac{c}{n} u=nc。之后可以利用u建立“缺陷密度的控制图标”
3 σ 3\sigma 3σ缺陷密度的控制图表(u图表)
目的:求n个产品的样本尺寸(也就是一组样本有n个产品,但取了多少组,我们还没有考虑)上,缺陷数量的平均数。(样本尺寸是一个数组,表示一组样品中应该有几个产品,这里用n表示)
n个样品中有de(p图表中用 D i D_i Di表示缺陷缺陷个缺陷,则每份样本(即每组中)的每一个小产品存在的缺陷数量为: u = d e n u=\frac{de}{n} u=nde
组内的平均缺陷数量为 u u u,得到每一组的 u u u后,求组间的平均缺陷数量,得到 u ‾ \overline{u} u
图表的三个参数为:KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: …verline{u}}{n}}
u图表的例题
假定一个制造商拟建立一个缺陷密度图表。检查尺寸为5个晶圆的20个不同样本,总共发现193个缺陷,试构造u图表。
首先我们已知 u = c n u=\frac{c}{n} u=nc,且 u ‾ = u m \overline{u}=\frac{u}{m} u=mu。又由 m = 20 , n = 5 , c = 193 m=20,n=5,c=193 m=20,n=5,c=193,代入可得 u ‾ = 1.93 \overline{u}=1.93 u=1.93
变量控制图
变量控制图的三种主要类型和各自的用途分别是:
1.Xbar-R图:R时极差,等于晶圆上测量的最大值减最小值
2.Xbar-S图:S是标准差
3.X-R图:测量受到限制时,每一个点只代表一次测量
以Xbar-R为例,创建变量控制图的步骤为:

创建一般的变量控制图的步骤(仅做定型的描述):

x ‾ \overline{x} x和R的控制图表
先来简单介绍一下 x ‾ \overline{x} x和R控制图表
x
‾
\overline{x}
x-R控制图是一种常用的变量控制图,用于监控过程平均值和变异性的变化。
它由两个子图组成
X
‾
−
条图和
R
−
条图。绘制
\overline{X}-条图和R-条图。 绘制
X−条图和R−条图。绘制\overline{X}$-条图:
在
X
‾
\overline{X}
X-条图上绘制样本平均值的变化趋势。
横轴表示样本序号或时间,纵轴表示样本平均值。
同时绘制上控制限(UCL)和下控制限(LCL),这些限制由过程能力和稳定性要求决定。
绘制R-条图:
在R-条图上绘制样本范围的变化趋势。
横轴表示样本序号或时间,纵轴表示样本范围。
同时绘制上控制限(UCL)和下控制限(LCL),这些限制由过程能力和稳定性要求决定。
分析控制图:
分析
X
‾
\overline{X}
X-条图和R-条图上的数据点。
如果数据点超出控制限或显示特殊模式,可能表示过程存在问题,需要进一步调查和解决。
X ‾ \overline{X} X-R控制图的作用: X ‾ \overline{X} X-R控制图可以帮助识别过程中的常见问题,如过程漂移、异常点、过度调整等,并帮助改进和稳定过程的性能,常用于控制对象的长度、重量、强度、厚度、时间等计量值。
均值控制图( X ‾ \overline{X} X图)
在真实均值和方差未知时,我们采用和属性控制图(如p图)一样的操作方法。先求每一组的均值,在求所有组的均值(如“尺寸为n的m个样本”中,组内由n个,共有m组)
每一组我们可以求得一个 X ‾ \overline{X} X,所有 X ‾ \overline{X} X合起来再求一个均值,就得到了 X ‾ ‾ \overline{\overline{X}} X。
范围(R)定义为最大和最小观测值之差: R = x m a x − x m i n R=x_{max}-x_{min} R=xmax−xmin
平均范围 R ‾ \overline{R} R为所有R的均值。
已知,如果我们已经提前猜测了这个样本应该呈正态分布,那么就可以使用很多从其他正态分布的数据中得出的一些结论。比如,可以通过一张表格"用于构造变量控制表的因子"。通过这张表可以得到各种样本尺寸对应的
d
2
d_2
d2。
d
2
d_2
d2是什么呢?首先我们定义一个变量,叫“相对范围”,符号表示设为W。这个W,它等于
R
σ
\frac{R}{\sigma}
σR。
d
2
d_2
d2就是W的均值。
由
W
=
R
σ
,
d
2
=
W
‾
W=\frac{R}{\sigma},d_2=\overline{W}
W=σR,d2=W,我们可以得到
σ
\sigma
σ的一个估计(就是在不知道真实
σ
\sigma
σ的时候,去推测它的数值):
σ
^
=
R
‾
d
2
\widehat{\sigma}=\frac{\overline{R}}{d_2}
σ
=d2R
既然我们得到了总均值 X ‾ ‾ \overline{\overline{X}} X和推测的方差 σ ^ \widehat{\sigma} σ 。于是我们计算图表的三个参数为: { U C L = x ‾ ‾ + 3 σ ^ n 中心线 = x ‾ ‾ L C L = x ‾ ‾ − 3 R d 2 n \begin{cases} UCL=\overline{\overline{x}}+\frac{3\widehat{\sigma}}{\sqrt{n}}\\中心线=\overline{\overline{x}}\\LCL=\overline{\overline{x}}-\frac{3R}{d_2 \sqrt{n}} \end{cases} ⎩ ⎨ ⎧UCL=x+n3σ 中心线=xLCL=x−d2n3R
将 σ ^ = R ‾ d 2 \widehat{\sigma}=\frac{\overline{R}}{d_2} σ =d2R代入上式,得到: { U C L = x ‾ ‾ + 3 R d 2 n 中心线 = x ‾ ‾ L C L = x ‾ ‾ − 3 R d 2 n \begin{cases} UCL=\overline{\overline{x}}+\frac{3R}{d_2 \sqrt{n}}\\中心线=\overline{\overline{x}}\\LCL=\overline{\overline{x}}-\frac{3R}{d_2 \sqrt{n}} \end{cases} ⎩ ⎨ ⎧UCL=x+d2n3R中心线=xLCL=x−d2n3R
如果我们用 A 2 = 3 d 2 n A_2=\frac{3}{d_2\sqrt{n}} A2=d2n3代入,可以得到图表的三个参数为: { U C L = x ‾ ‾ + A 2 R 中心线 = x ‾ ‾ L C L = x ‾ ‾ − A 2 R \begin{cases} UCL=\overline{\overline{x}}+A_2R\\中心线=\overline{\overline{x}}\\LCL=\overline{\overline{x}}-A_2R \end{cases} ⎩ ⎨ ⎧UCL=x+A2R中心线=xLCL=x−A2R
极差控制图(R图)
首先,R图的中心线是很明确知道的,就是 R ‾ \overline{R} R
难点就在于估算R的标准差。那R的标准差怎么算呢?
已知,如果我们已经提前猜测了这个样本应该呈正态分布,那么就可以使用很多从其他正态分布的数据中得出的一些结论。比如,可以通过一张表格"用于构造变量控制表的因子"。
通过这张表可以得到各种样本尺寸对应的
d
3
d_3
d3。
d
3
d_3
d3是什么呢?首先我们已知“相对范围”
W
=
R
σ
W=\frac{R}{\sigma}
W=σR。
d
3
d_3
d3就是W的标准差。
由
R
=
W
σ
R=W\sigma
R=Wσ、W的标准差
d
3
d_3
d3可以得到R的真实标准差的表达式应为:
σ
R
=
d
3
σ
\sigma_R=d_3\sigma
σR=d3σ
但真实标准差是未知的,我们需要通过样本数据去推测。把
σ
=
R
‾
d
2
\sigma=\frac{\overline{R}}{d_2}
σ=d2R代入,可以得到标准差的推测公式为:
σ
^
R
=
d
3
⋅
r
‾
d
2
\widehat{\sigma}_R=d_3 \cdot \frac{\overline{r}}{d_2}
σ
R=d3⋅d2r
由此得到R图的三要素为: { U C L = R ‾ + 3 σ ^ 中心线 = R ‾ L C L = R ‾ − 3 σ ^ \begin{cases} UCL=\overline{R}+3\widehat{\sigma}\\中心线=\overline{R}\\LCL=\overline{R}-3\widehat{\sigma} \end{cases} ⎩ ⎨ ⎧UCL=R+3σ 中心线=RLCL=R−3σ
如果将 σ ^ = d 3 ⋅ r ‾ d 2 \widehat{\sigma}=d_3 \cdot \frac{\overline{r}}{d_2} σ =d3⋅d2r代入,得到: { U C L = R ‾ + 3 d 3 ⋅ r ‾ d 2 中心线 = R ‾ L C L = R ‾ − 3 d 3 ⋅ r ‾ d 2 \begin{cases} UCL=\overline{R}+3d_3 \cdot \frac{\overline{r}}{d_2}\\中心线=\overline{R}\\LCL=\overline{R}-3d_3 \cdot \frac{\overline{r}}{d_2} \end{cases} ⎩ ⎨ ⎧UCL=R+3d3⋅d2r中心线=RLCL=R−3d3⋅d2r
与 X ‾ \overline{X} X图一样,有教材也提出用另外的符号去简化R图的三要素表达式。用于简化的符号如下: D 3 = 1 − 3 d 3 d 2 D_3=1-\frac{3d_3}{d_2} D3=1−d23d3, D 4 = 1 + 3 d 3 d 2 D_4=1+\frac{3d_3}{d_2} D4=1+d23d3
也就是说,三个参数可以表示为: { U C L = x ‾ ‾ + 3 R d 2 n 中心线 = x ‾ ‾ L C L = x ‾ ‾ − 3 R d 2 n \begin{cases} UCL=\overline{\overline{x}}+\frac{3R}{d_2\sqrt{n}}\\中心线=\overline{\overline{x}}\\LCL=\overline{\overline{x}}-\frac{3R}{d_2\sqrt{n}} \end{cases} ⎩ ⎨ ⎧UCL=x+d2n3R中心线=xLCL=x−d2n3R
$\overline{x}与s的控制图表
图表的三个参数为:KaTeX parse error: Expected & or \\ or \cr or \end at end of input: …a\sqrt{1-c_4^2}
当
σ
\sigma
σ未知时,
s
‾
=
1
m
∑
i
=
1
m
s
i
\overline{s}=\frac{1}{m}\sum_{i=1}^{m}s_i
s=m1i=1∑msi
此时,图表的三个参数为: { U C L = s ‾ + 3 1 − c 4 2 c 4 s ‾ 中心线 = s ‾ L C L = s ‾ − 3 1 − c 4 2 c 4 \begin{cases} UCL=\overline{s}+\frac{3\sqrt{1-c_4^2}}{c_4} \overline{s}\\中心线=\overline{s}\\LCL=\overline{s}-\frac{3\sqrt{1-c_4^2}}{c_4} \end{cases} ⎩ ⎨ ⎧UCL=s+c431−c42s中心线=sLCL=s−c431−c42
/2025.3.19编辑至此,以下内容不完善*/
操作特征和平均序列长度(OC)
下面用一道例题来体现绘制操作特征曲线(OC曲线)的过程:
overline{X}-s控制图表
相对于overline{X}-R控制图使用了极差,overlineX-s使用了标准差,适用于样本量大(如n>10)
制作步骤:
收集k个样本
以n个为标准分组,即样本容量为n
求标准差图的控制限,此时分为两种情况:sigma已知;sigma未知
求均值图的控制限
单值-移动极差控制图
(3种)计量控制图总结
判断异常点的8种常见检验模式
控制图的应用:
如何选择需要用的控制图:
3种计数控制图
累计计数控制图(CCC)
智能控制
预控制技术pro-control:在缺陷发生前防止缺陷的发生
alpha风险:
beta风险:
预控制技术流程图:
智能控制的概念和原理
预控制技术(Pro-Control)
预控制技术的定义:在缺陷发生前就防止缺陷发生。
检验步骤:
graph LR
A[]-->B[]
B-->C[]
模糊控制
模糊控制的控制回路:
模糊控制的组成核心:模糊控制器
模糊控制的特点:设计上无需基于被控对象的精确模型
预测控制
预测控制,亦称为模型预测控制(model prrdictive control)的定义:
预测控制的系统结构图:
预测控制的特点:
神经网络控制
使用神经网络控制的目的:
神经网络的特点:
神经网络PID控制的系统框图:
软测量
软测量的基本思想: