protobuf的学习
1. 认识protobuf
序列化概念回顾:
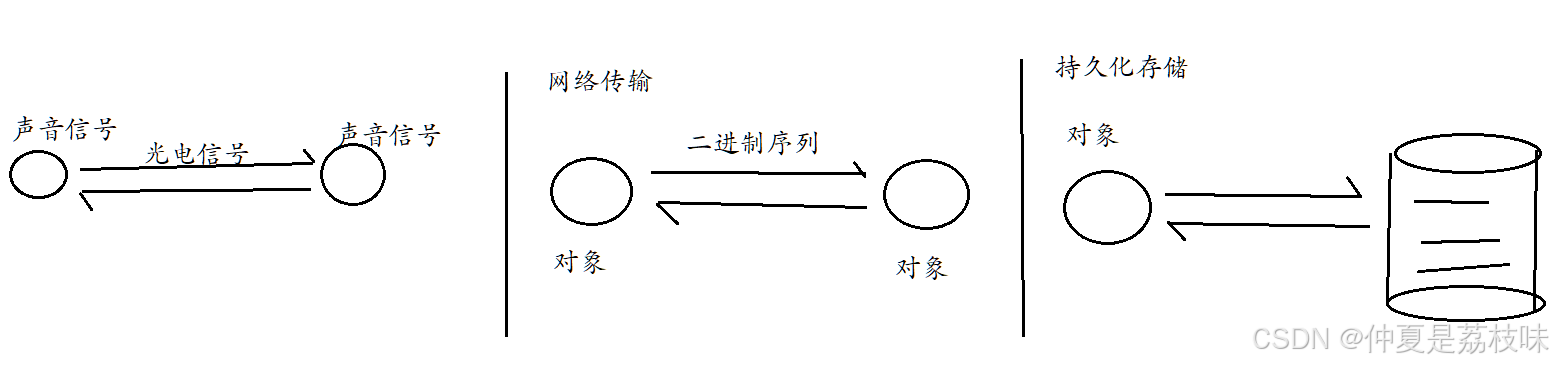
如何实现序列化:xml,json,pb(protobuf)
pb: 帮助我们实现序列化的一种手段。
PB的特点 :
语言无关、平台无关:即ProtoBuf支持Java、C++、Python等多种语言,支持多个平台高效:即比XML更小、 更快、 更为简单。
扩展性、兼容性好:你可以更新数据结构,而不影响和破坏原有的旧程序。使用特点:ProtoBuf是需要依赖通过编译生成的JAVA代码使用的
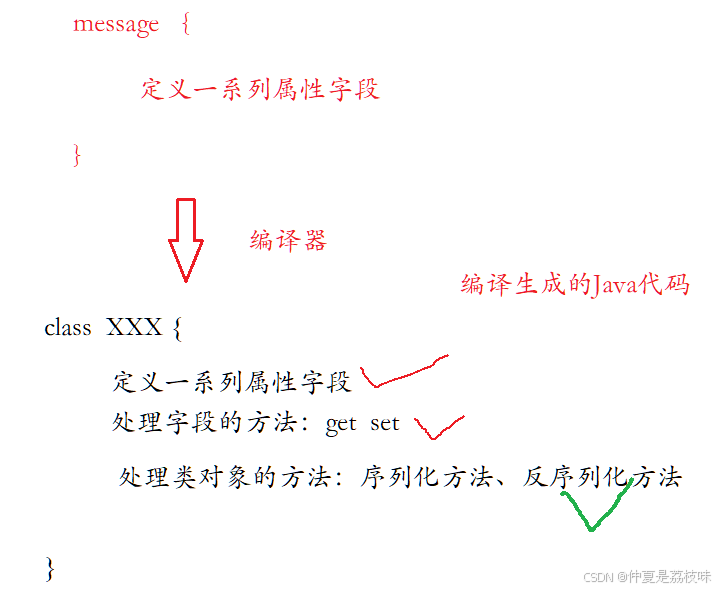
pb能够通过对message(只定义属性)就可以编译生成相关的java代码。
1.1 windows安装
Protocol Buffers v21.11,win64版本。
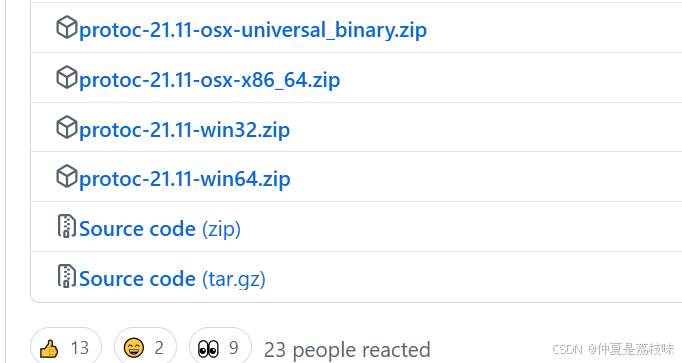
将exe文件目录配置到环境变量中。E:\anzhuangchengxu\protobf\protoc-21.11-win64\bin;
此时在w上安装好了pb的编译器。
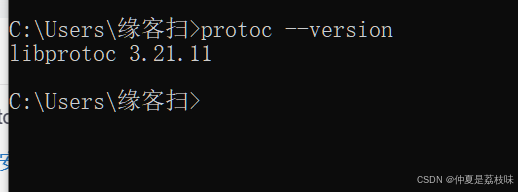
此时,确实安装成功。
1.2 在linux(ubuntu环境)安装pb
安装文件C:/Users/缘客扫/Desktop/java笔记/109期精品课/protobuf/protobuf/ProtoBuf%20安装.pdf
sudo apt-get install autoconf automake libtool curl make g++ unzip -y
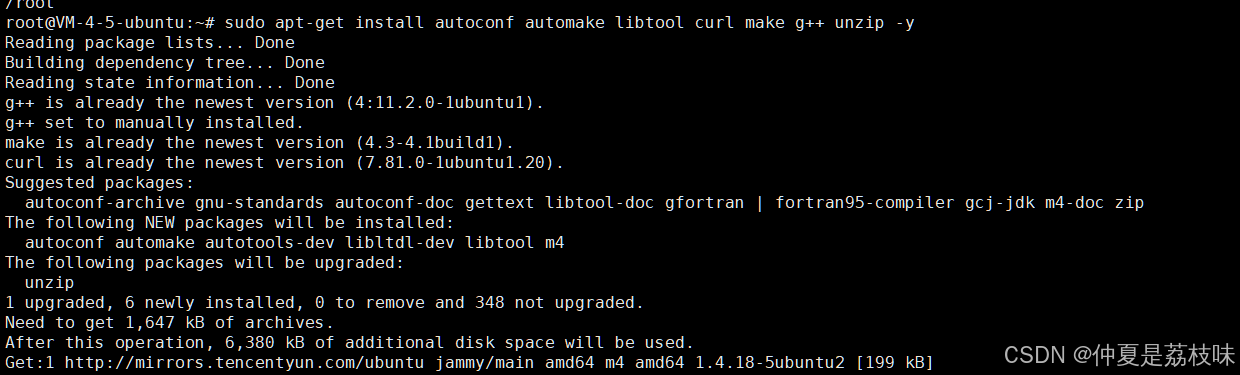
下载pb仓库:
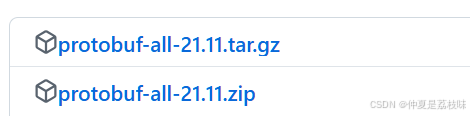
将all的连接复制使用指令wget 连接;
下载完成后获得压缩包,使用unzip 压缩包指令进行解压:
如下:

进入pb文件如下:
执行 ./autogen.sh:

修改安装⽬录,统⼀安装在 /usr/local/protobuf 下 ./configure --prefix=/usr/local/protobuf
执行make(15min)
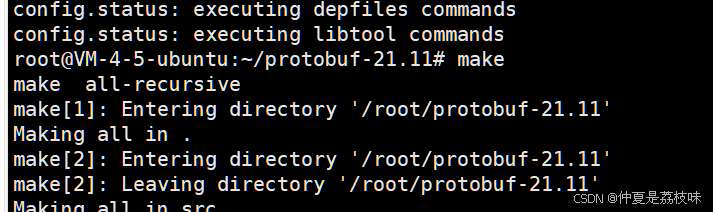
执行make check
Ubuntu 18.04 swap分区扩展_ubuntu18.04 如何查看swapfile文件路径-CSDN博客
发现中途有问题,执行下面的指令
sudo make install
检查是否安装成功:
对ProtoBuf的完整学习,将使⽤项⽬推进的⽅式,即对于ProtoBuf知识内容的展开,会对 ⼀个项⽬进⾏⼀个版本⼀个版本的升级去讲解ProtoBuf对应的知识点。
1.3 pb的使用流程
需求1:
编写第⼀版本的通讯录1.0。在通讯录1.0版本中,将实现:
• 对⼀个联系⼈的信息使⽤PB进⾏序列化,并将结果打印出来。
• 对序列化后的内容使⽤PB进⾏反序列,解析出联系⼈信息并打印出来。
• 联系⼈包含以下信息:姓名、年龄。
通过通讯录1.0,我们便能了解使⽤ProtoBuf初步要掌握的内容,以及体验到ProtoBuf的完整使⽤流 程。
下载下面的三个插件:

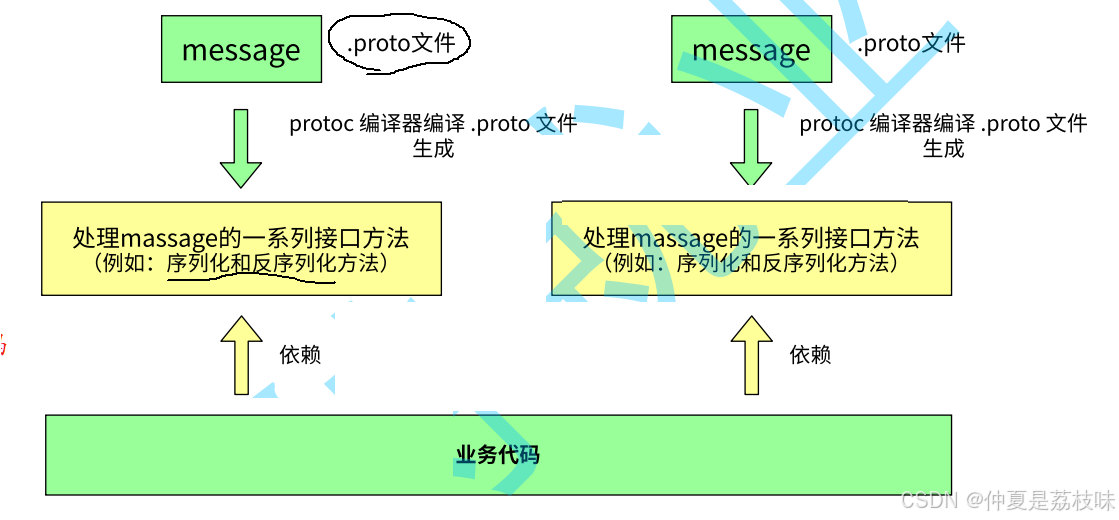
步骤1:创建.proto⽂件
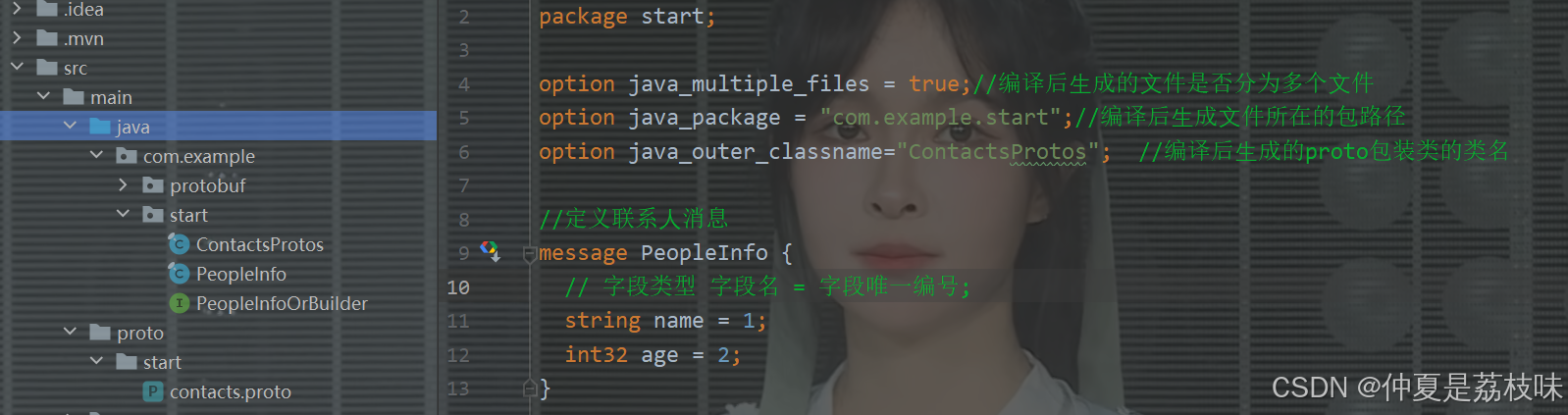
更新contacts.proto(通讯录1.0),新增姓名、年龄字段:
syntax = "proto3";
package start;
option java_multiple_files = true;//编译后⽣成的⽂件是否分为多个⽂件
option java_package = "com.example.start";//编译后⽣成⽂件所在的包路径
option java_outer_classname="ContactsProtos"; //编译后⽣成的proto包装类的类名
//定义联系⼈消息
message PeopleInfo {
string name = 1;
int32 age = 2;
}
步骤2:编译contacts.proto⽂件,⽣成JAVA⽂件 编译的⽅式有两种:
使⽤命令⾏编译;
protoc -I src/main/proto/start --java_out src/main/java contacts.proto


成功编译出java文件。
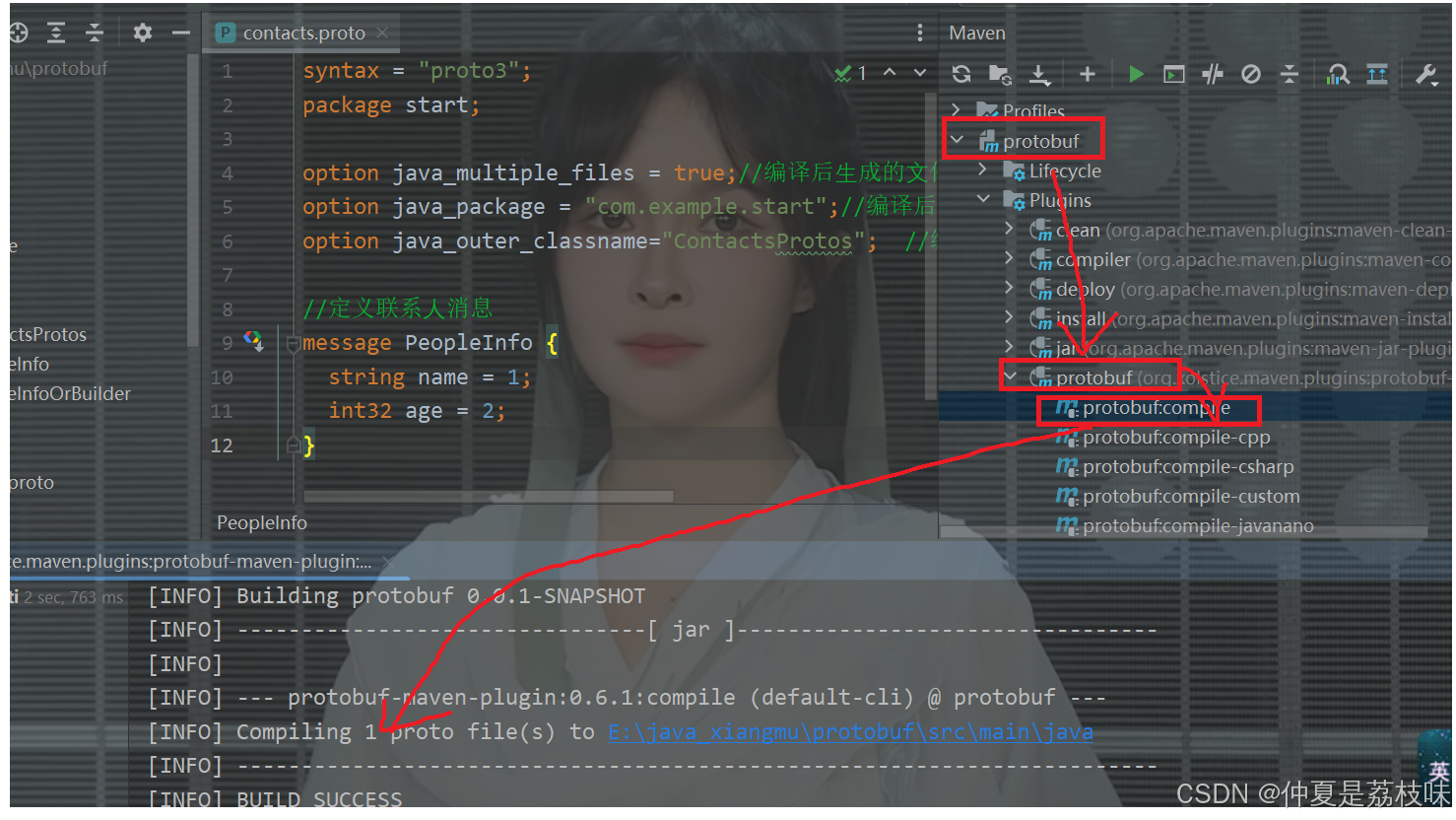
使⽤maven插件编译:加入相关依赖
<plugin>
<groupId>org.xolstice.maven.plugins</groupId>
<artifactId>protobuf-maven-plugin</artifactId>
<version>0.6.1</version>
<configuration>
<!-- 本地安装的protoc.exe的目录 -->
<protocExecutable>E:\anzhuangchengxu\protobf\protoc-21.11-win64\bin\protoc.exe</protocExecutable>
<!-- proto文件放置的目录,默认为/src/main/proto -->
<protoSourceRoot>${project.basedir}/src/main/proto</protoSourceRoot>
<!-- 生成文件的目录,默认生成到target/generated-sources/protobuf/ -->
<outputDirectory>${project.basedir}/src/main/java</outputDirectory>
<!-- 是否清空目标目录,默认值为true。这个最好设置为false,以免误删项目文件!!! -->
<clearOutputDirectory>false</clearOutputDirectory>
</configuration>
</plugin>如下图所示,显示编译成功。

如上所示,首先1步骤,进入静态方法,进行2步骤对于相关字段进行设置,第三部将构造好的类进行创建,最后使用创建好的类对象进行第四步的序列化和反序列化操作。
所谓序列化产生的结果都是二进制数据。
需求代码:
package com.example.start;
import com.google.protobuf.InvalidProtocolBufferException;
import java.util.Arrays;
public class FastStart {
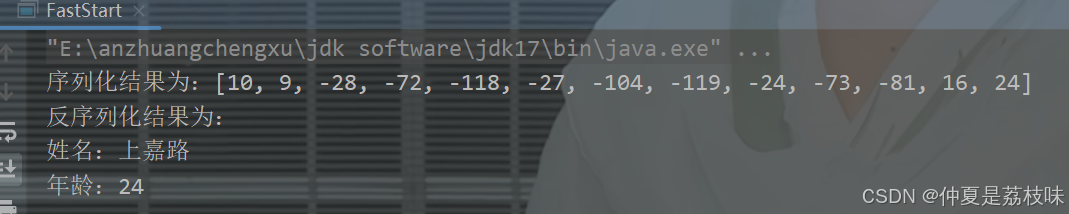
public static void main(String[] args) throws InvalidProtocolBufferException {
PeopleInfo p1 = PeopleInfo.newBuilder()
.setName("上嘉路")
.setAge(24)
.build();
// 序列化
byte[] bytes = p1.toByteArray();
System.out.println("序列化结果为:" + Arrays.toString(bytes));
// 反序列化
PeopleInfo p2 = PeopleInfo.parseFrom(bytes);
System.out.println("反序列化结果为:");
System.out.println("姓名:" + p2.getName());
System.out.println("年龄:" + p2.getAge());
}
}
2. 新增需求2.0
这个部分会对通讯录进⾏多次升级,使⽤2.x 表⽰升级的版本,最终将会升级如下内容:
• 不再打印联系⼈的序列化结果,⽽是将通讯录序列化后并写⼊⽂件中。
• 从⽂件中将通讯录解析出来,并进⾏打印。
• 新增联系⼈属性,共包括:姓名、年龄、电话信息、地址、其他联系⽅式、备注。
proto3语法中支持在多message并创建的,一支持在message中内嵌创建子message,且这样多个message中的字段编号可以相同。
代码如下:
// 首行: 语法指定行
syntax = "proto3";
package proto3;
option java_multiple_files = true; // 编译后⽣成的⽂件是否分为多个⽂件
option java_package = "com.example.proto3"; // 编译后⽣成⽂件所在的包路径
option java_outer_classname = "ContactsProtos"; // 编译后⽣成的proto包装类的类名
import "google/protobuf/any.proto";
// 定义联系人 message
message PeopleInfo {
// 字段类型 字段名 = 字段唯一编号;
string name = 1;
int32 age = 2;
message Phone {
string number = 1;
}
repeated Phone phone = 3;
}
message Contacts {
repeated PeopleInfo contacts = 1;
}
package com.example.proto3;
import com.google.protobuf.Any;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Scanner;
public class TestWrite {
public static void main(String[] args) throws IOException {
Contacts.Builder contactsBuilder = Contacts.newBuilder();
// 读取本地已存在的 contacts.bin,反序列化出通讯录对象
// Contacts contacts = Contacts.parseFrom(
// new FileInputStream("src/main/java/com/example/proto3/contacts.bin"));
// contactsBuilder = contacts.toBuilder();
try {
contactsBuilder.mergeFrom(
new FileInputStream("src/main/java/com/example/proto3/contacts.bin"));
} catch (FileNotFoundException e) {
System.out.println("contacts.bin not find, create new file");
}
// 向通讯录中新增一个联系人
contactsBuilder.addContacts(addPeopleInfo());
// 序列化通讯录,将结果写入文件中
//将序列化的东西写入到文件流中
FileOutputStream outputStream = new FileOutputStream(
"src/main/java/com/example/proto3/contacts.bin");
contactsBuilder.build().writeTo(outputStream);
outputStream.close();
}
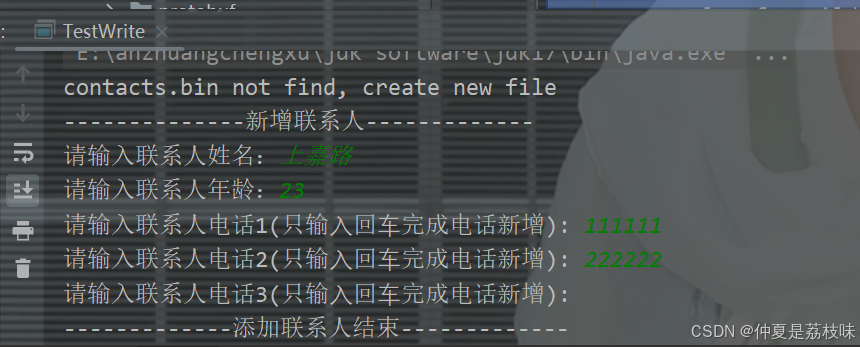
private static PeopleInfo addPeopleInfo() {
PeopleInfo.Builder builder = PeopleInfo.newBuilder();
Scanner scanner = new Scanner(System.in);
System.out.println("--------------新增联系人-------------");
System.out.print("请输入联系人姓名:");
String name = scanner.nextLine();
builder.setName(name);
System.out.print("请输入联系人年龄:");
int age = scanner.nextInt();
scanner.nextLine();
builder.setAge(age);
for (int i = 0;; i++) {
System.out.print("请输入联系人电话" + (i + 1) + "(只输⼊回⻋完成电话新增): ");
String number = scanner.nextLine();
if (number.isEmpty()) {
break;
}
PeopleInfo.Phone.Builder phoneBuilder = PeopleInfo.Phone.newBuilder();
phoneBuilder.setNumber(number);
builder.addPhone(phoneBuilder);
}
System.out.println("-------------添加联系人结束-------------");
return builder.build();
}
}
package com.example.proto3;
import com.google.protobuf.InvalidProtocolBufferException;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Map;
public class TestRead {
public static void main(String[] args) throws IOException {
// 读取文件,将读取的内容进行反序列化
Contacts contacts = Contacts.parseFrom(
new FileInputStream("src/main/java/com/example/proto3/contacts.bin"));
// 打印
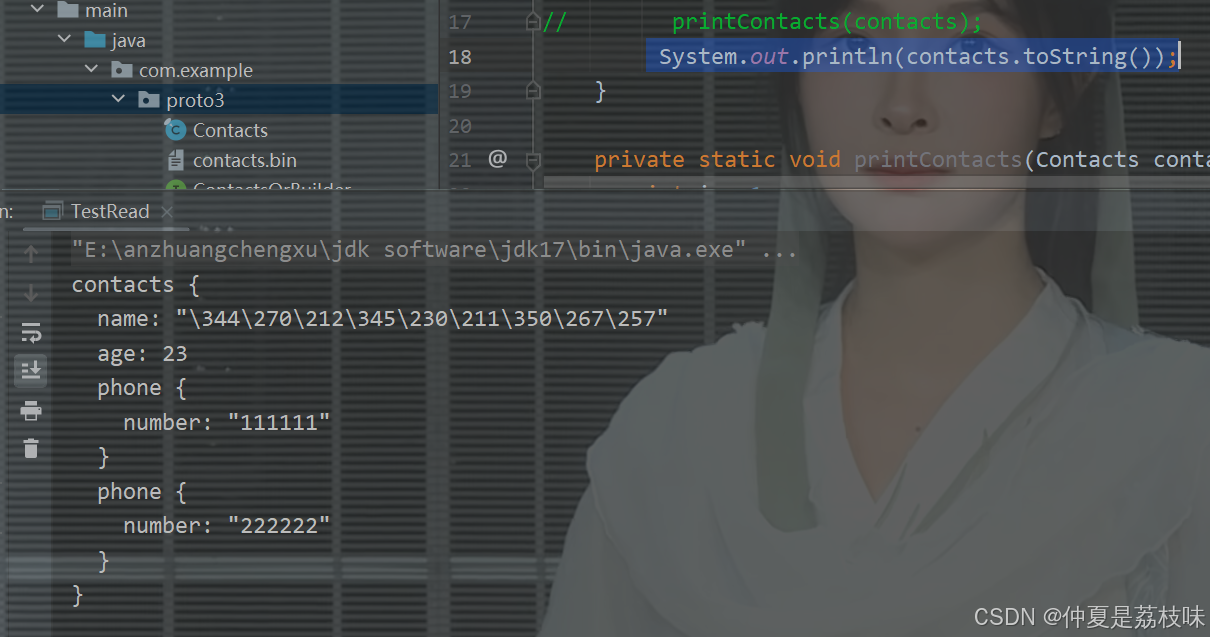
printContacts(contacts);
// System.out.println(contacts.toString());
}
private static void printContacts(Contacts contacts) throws InvalidProtocolBufferException {
int i = 1;
for (PeopleInfo peopleInfo : contacts.getContactsList()) {
System.out.println("-----------联系人" + i++ + "--------------");
System.out.println("姓名:" + peopleInfo.getName());
System.out.println("年龄:" + peopleInfo.getAge());
int j = 1;
for (PeopleInfo.Phone phone : peopleInfo.getPhoneList()) {
System.out.println("电话" + j++ + ": " + phone.getNumber());
}
}
}
也可以使用静态方法中自带的方法:
System.out.println(contacts.toString());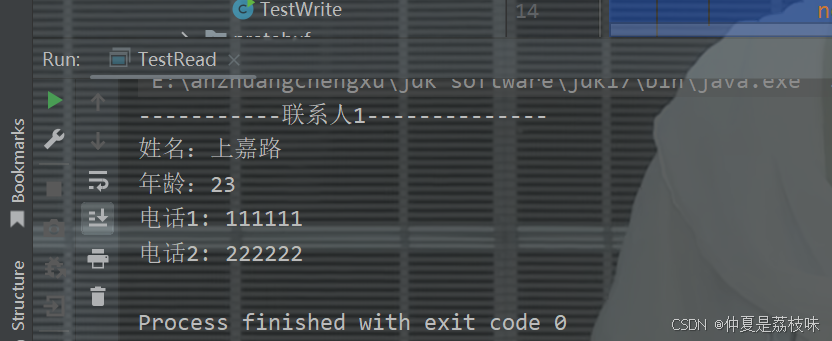
3. 新增需求2.1
手机包含类型
枚举是用驼峰命名:
添加电话的类型:
// 首行: 语法指定行
syntax = "proto3";
package proto3;
option java_multiple_files = true; // 编译后⽣成的⽂件是否分为多个⽂件
option java_package = "com.example.proto3"; // 编译后⽣成⽂件所在的包路径
option java_outer_classname = "ContactsProtos"; // 编译后⽣成的proto包装类的类名
import "google/protobuf/any.proto";
// 定义联系人 message
message PeopleInfo {
// 字段类型 字段名 = 字段唯一编号;
string name = 1;
int32 age = 2;
message Phone {
string number = 1;
// 0值必须存在,且作为第一个枚举常量的值
// 枚举值范围:32位整数范围,不要设置负数
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
PhoneType type = 2;
}
repeated Phone phone = 3;
}
message Contacts {
repeated PeopleInfo contacts = 1;
}
进行读写相关代码修改之后操作:
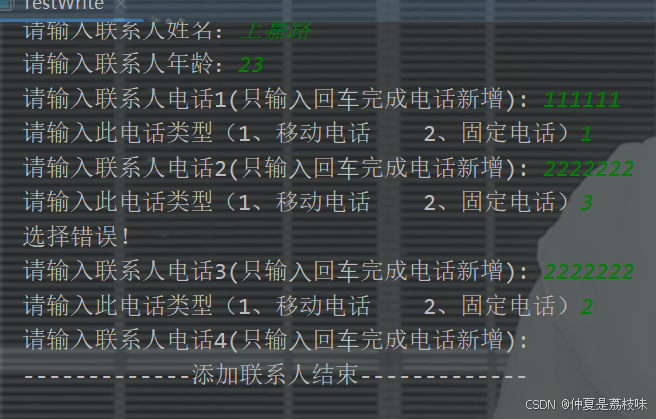
读取文件,获取相关内容:
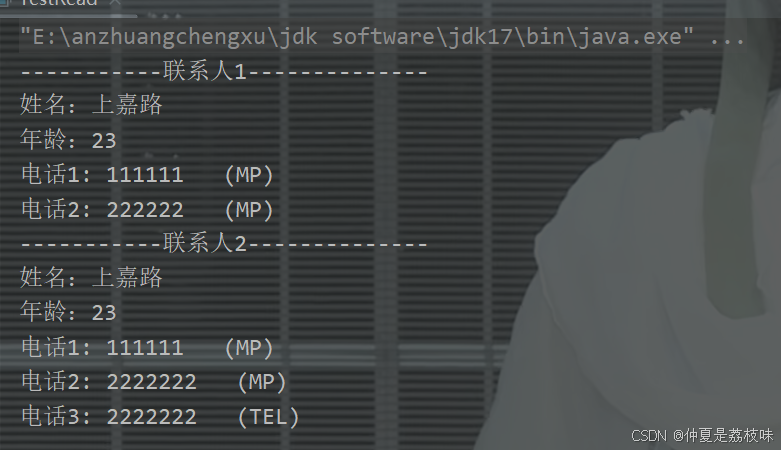
反序列化的过程中,对于输入时没有进行设置类型的参数,会直接赋予默认值的类型。
any类型的message文件:在使用的时候将any类型理解为泛型。
4. 新增需求2.2
通讯录包含地址信息
在proto文件中添加相关字段:
message Address {
string home_address = 1;
string unit_address = 2;
}写方法添加下面字段:
Address.Builder addressBuilder = Address.newBuilder();
System.out.print("请输入联系人家庭地址:");
String homeAddress = scanner.nextLine();
addressBuilder.setHomeAddress(homeAddress);
System.out.print("请输入联系人单位地址:");
String unitAddress = scanner.nextLine();
addressBuilder.setUnitAddress(unitAddress);
builder.setData(Any.pack(addressBuilder.build()));
System.out.println("-------------添加联系人结束-------------");
return builder.build();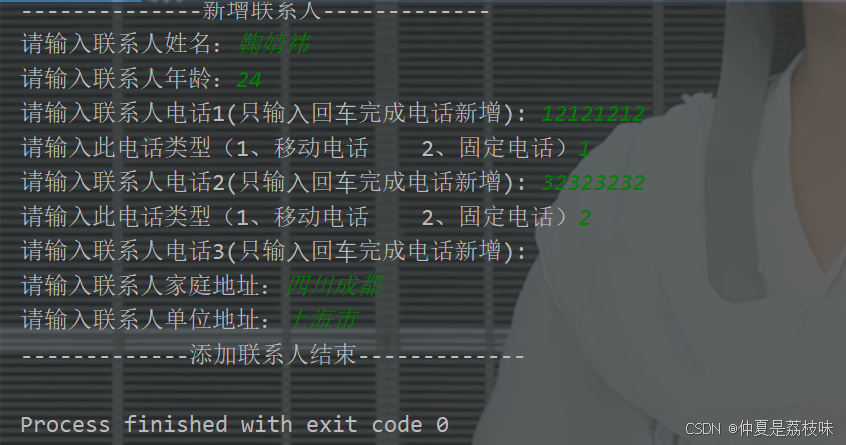
内容读取方法添加:
if (peopleInfo.hasData()
&& peopleInfo.getData().is(Address.class)) {
Address address = peopleInfo.getData().unpack(Address.class);
if (!address.getHomeAddress().isEmpty()) {
System.out.println("家庭地址:" + address.getHomeAddress());
}
if (!address.getUnitAddress().isEmpty()) {
System.out.println("单位地址:" + address.getUnitAddress());
}
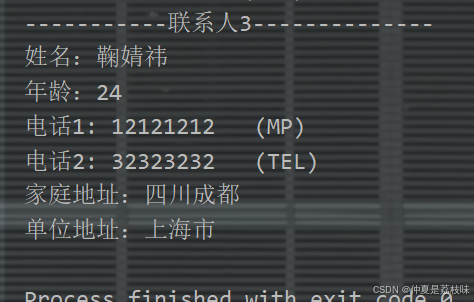
}
5. 新增需求2.3
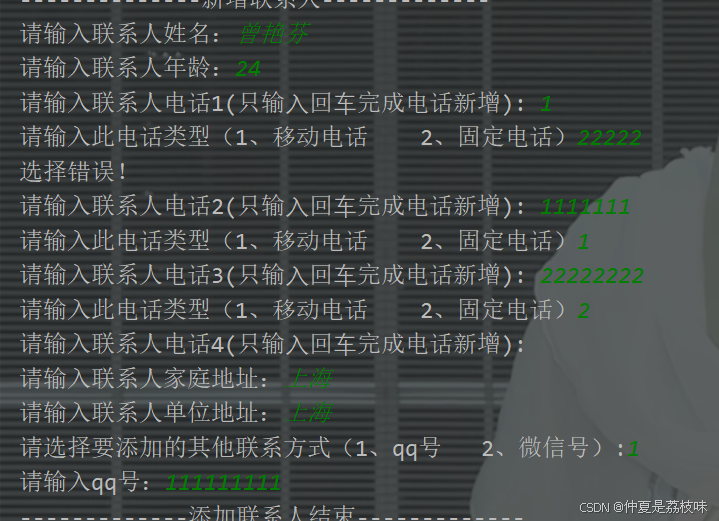
新增其他需求,其他联系方式,qq或wx,oneof字段加强多选一的行为,且不支持repeated字段。
写操作:
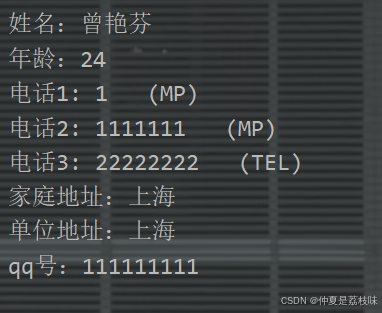
读操作:
6. 新增需求2.4
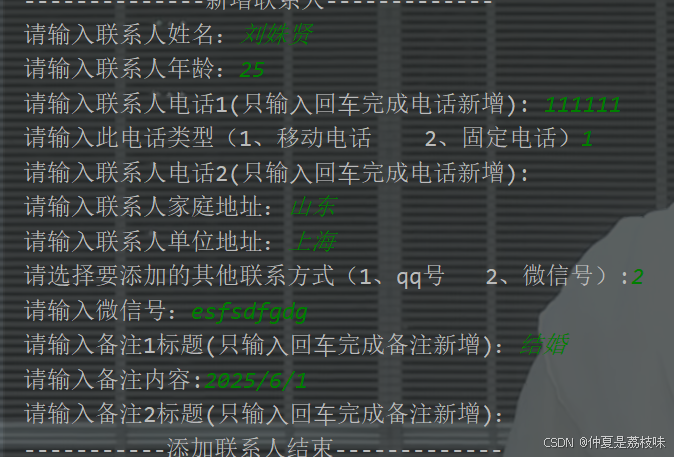
使用map类型增加备注信息。
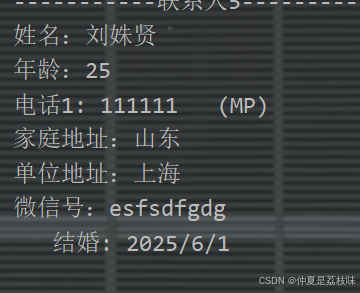
6. 默认值
• 对于字符串,默认值为空字符串。
• 对于字节,默认值为空字节。
• 对于布尔值,默认值为false。
• 对于数值类型,默认值为0。
• 对于枚举,默认值是第⼀个定义的枚举值,必须为0。
• 对于消息字段,未设置该字段。它的取值是依赖于语⾔。
• 对于设置了repeated的字段的默认值是空的(通常是相应语⾔的⼀个空列表)。
• 对于 消息字段、 oneof 字段 和 any 字段 ,都有has⽅法来检测当前字段是否被设置。
新增字段:注意新增的字段不和老字段冲突:名称和字段标号。
修改老字段:
禁⽌修改任何已有字段的字段编号。
• 若是移除⽼字段,要保证不再使⽤移除字段的字段编号。正确的做法是保留字段编号 (reserved),以确保该编号将不能被重复使⽤。不建议直接删除或注释掉字段。
• int32,uint32,int64,uint64和bool是完全兼容的。可以从这些类型中的⼀个改为另⼀个, ⽽不破坏前后兼容性。若解析出来的数值与相应的类型不匹配,可能会被截断(例如,若将64 位整数当做32位进⾏读取,它将被截断为32位)。
• sint32和sint64相互兼容但不与其他的整型兼容。
• string和bytes在合法UTF-8字节前提下也是兼容的。
• bytes包含消息编码版本的情况下,嵌套消息与bytes也是兼容的。
• fixed32与sfixed32兼容,fixed64与sfixed64兼容。
• enum 与int32,uint32,int64和uint64兼容(注意若值不匹配会被截断)。但要注意当反序 列化消息时会根据语⾔采⽤不同的处理⽅案:例如,未识别的proto3枚举类型会被保存在消息 中,但是当消息反序列化时如何表⽰是依赖于编程语⾔的。整型字段总是会保持其的值。
• oneof:
◦ 将⼀个单独的值更改为新oneof类型成员之⼀是安全和⼆进制兼容的。
◦ 若确定没有代码⼀次性设置多个值那么将多个字段移⼊⼀个新oneof类型也是可⾏的。
◦ 将任何字段移⼊已存在的oneof类型是不安全的
删除老字段:不建议直接删除老字段,若是移除老字段,要保证不再使用移除字段的字段编号。
.proto文件在进行反编译数据时,不是按照字段名来进行编译的,而是按照字段标号来进行编译相关内容的。
保留字段reserved:
如果通过删除或注释掉字段来更新消息类型,未来的⽤⼾在添加新字段时,有可能会使⽤以前已经 存在,但已经被删除或注释掉的字段编号。将来使⽤该.proto的旧版本时的程序会引发很多问题:数 据损坏、隐私错误等等。
确保不会发⽣这种情况的⼀种⽅法是:使⽤ reserved 将指定字段的编号或名称设置为保留项。当 我们再使⽤这些编号或名称时,protocolbuffer的编译器(在进行编译时)将会警告这些编号或名称不可⽤。reserved 可以一次性保留多个字段编号,期间使用逗号隔开。也可以保留字段命。
未知字段:解析结构良好的protocolbuffer已序列化数据中的未识别字段的表⽰⽅式。例如,当 旧程序解析带有新字段的数据时,这些新字段就会成为旧程序的未知字段。
7. 前后兼容性
根据上述的例⼦可以得出,pb是具有向前兼容的。为了叙述⽅便,把增加了“⽣⽇”属性的service 称为“新模块”;未做变动的client称为“⽼模块”。
• 向前兼容:⽼模块能够正确识别新模块⽣成或发出的协议。这时新增加的“⽣⽇”属性会被当作未 知字段(pb3.5版本及之后)。
• 向后兼容:新模块也能够正确识别⽼模块⽣成或发出的协议。
前后兼容的作⽤:当我们维护⼀个很庞⼤的分布式系统时,由于你⽆法同时升级所有模块,为了保证 在升级过程中,整个系统能够尽可能不受影响,就需要尽量保证通讯协议的“向后兼容”或“向前兼 容”。
选项option .proto ⽂件中可以声明许多选项,使⽤ option 标注。选项能影响proto编译器的某些处理⽅式。
选项分为⽂件级、消息级、字段级等等,但并没有⼀种选项能作⽤于所有的类型。
java_multiple_files:编译后⽣成的⽂件是否分为多个⽂件,该选项为⽂件选项。
java_package:编译后⽣成⽂件所在的包路径,该选项为⽂件选项。
java_outer_classname:编译后⽣成的proto包装类的类名,该选项为⽂件选项。
allow_alias:允许将相同的常量值分配给不同的枚举常量,⽤来定义别名。该选项为枚举选项。
8. 通讯录4.0实现---⽹络版
需求如下:
客户端:向服务端发送联系人信息,并接收服务端返回的响应。
服务端:接收到联系人信息后,将结果打印出来
客户端、服务端间的交互数据使用Protobuf来完成
代码环境:Maven项⽬+ UDP数据报套接字编程
客户端和服务器交互逻辑:
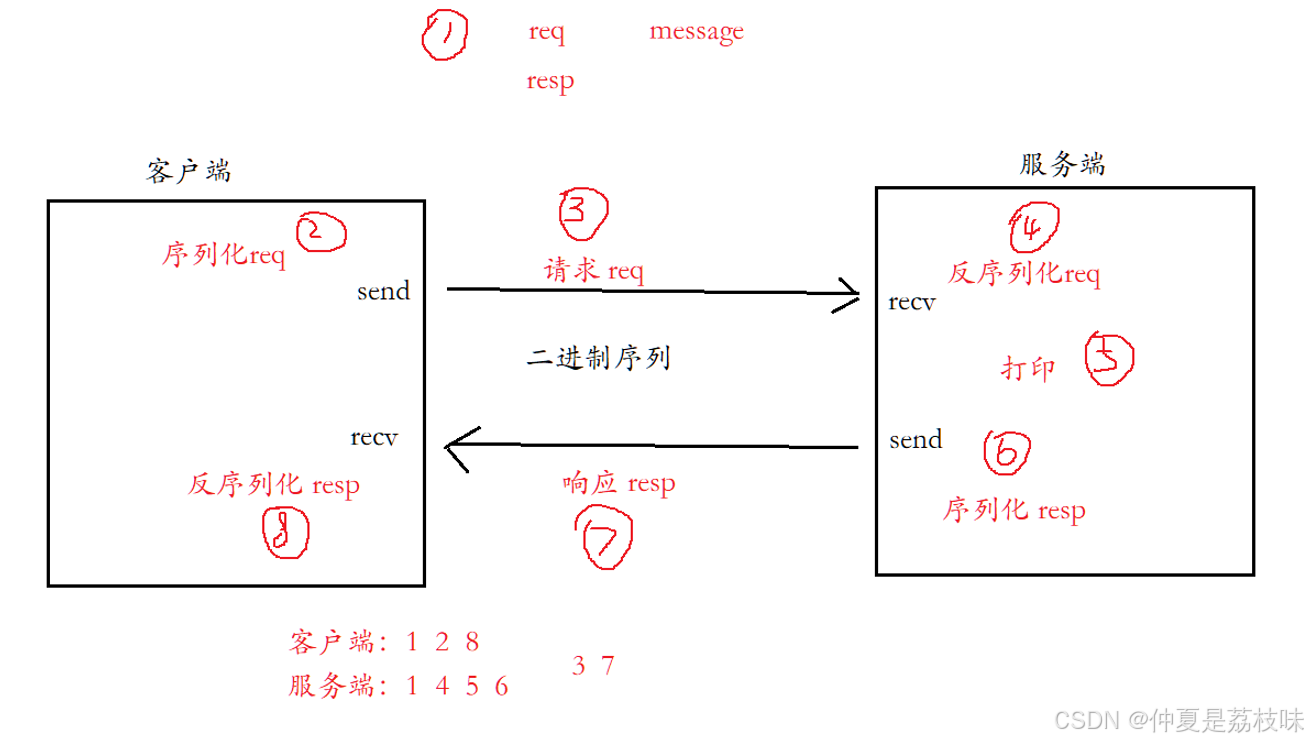
代码和结果略。
9. 总结
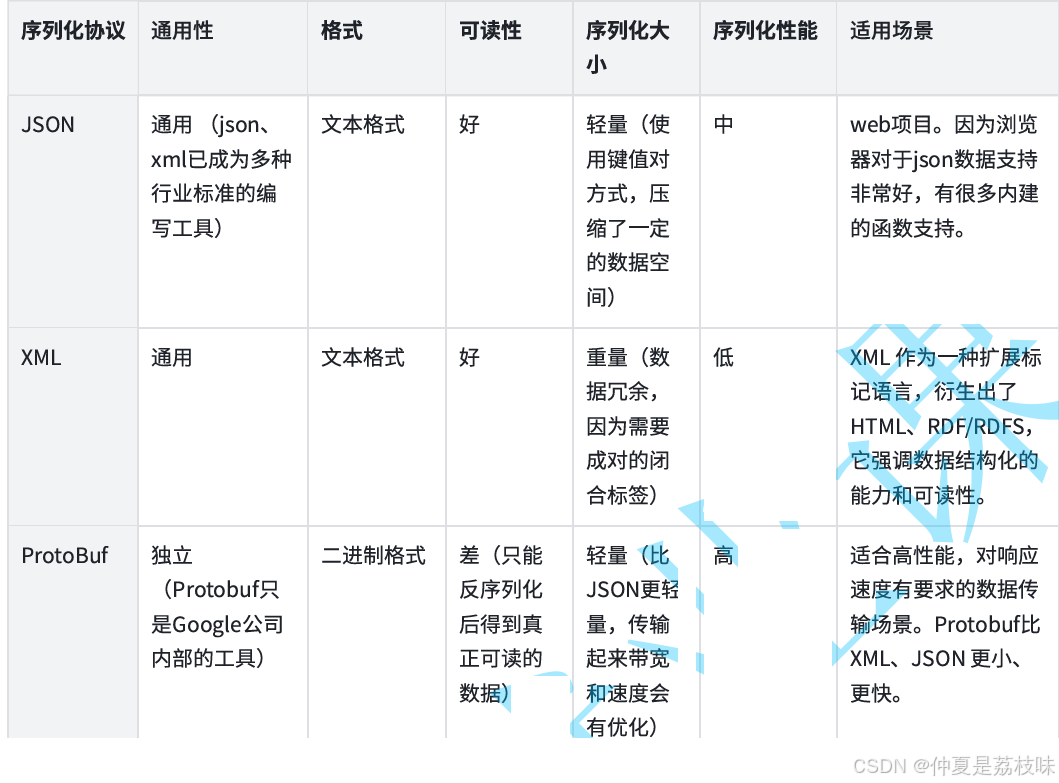
序列化能⼒对⽐
• 编解码性能:ProtoBuf>jackson>fastjson2。
• 内存占⽤:ProtoBuf>jackson~=fastjson2。
all in all:
⼩结:
1. XML、JSON、ProtoBuf都具有数据结构化和数据序列化的能⼒。
2. XML、JSON更注重数据结构化,关注可读性和语义表达能⼒。ProtoBuf更注重数据序列化,关注 效率、空间、速度,可读性差,语义表达能⼒不⾜,为保证极致的效率,会舍弃⼀部分元信息。
3. ProtoBuf的应⽤场景更为明确,XML、JSON的应⽤场景更为丰富。
ps:本文仅用来自己整理学习时的笔记。