论文阅读:SCI 1区 RADAR: Robust AI-Text Detection via Adversarial Learning
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
RADAR: Robust AI-Text Detection via Adversarial Learning
https://proceedings.neurips.cc/paper_files/paper/2023/file/30e15e5941ae0cdab7ef58cc8d59a4ca-Paper-Conference.pdf
https://www.doubao.com/chat/1889643784312578
Abstract(摘要)
如今,大语言模型(LLMs)发展迅速,像ChatGPT这类应用也越来越火,这使得人类和机器生成高质量文本之间的界限变得模糊不清。想象一下,你收到一篇文章,很难判断它到底是一个知识渊博的人写的,还是机器创作出来的。这种情况带来了不少问题,比如有人可能利用机器生成虚假内容、抄袭,或者误判,冤枉那些无辜的创作者。就好比在学校里,老师布置了作文作业,有些学生可能用大语言模型写作文,欺骗老师,这对其他认真写作的学生不公平;还有在新闻领域,虚假的AI生成新闻可能误导大众。
目前的AI文本检测器在面对基于大语言模型改写的文本时表现不佳。为了解决这个问题,本文提出了一个叫RADAR的新框架,通过对抗学习来训练一个强大的AI文本检测器。可以把它想象成一场比赛,有两个参赛选手,一个是改写器(paraphraser),另一个是检测器(detector)。改写器的任务是把AI生成的文本改得更像人类写的,好让检测器检测不出来;而检测器则要不断提高自己的能力,准确识别出哪些是AI生成的文本。它们会根据对方的反馈来调整自己,就像两个人在互相切磋技艺,一起进步。
论文作者用8种不同的大语言模型(比如Pythia、Dolly 2.0等)和4个数据集对RADAR进行了测试。结果显示,RADAR比现有的AI文本检测方法厉害很多,尤其是在文本被改写的情况下。比如,面对用GPT - 3.5 - Turbo改写过的文本,RADAR的检测能力比其他最好的检测器提高了31.64%。而且,研究还发现RADAR的检测能力有很强的迁移性,用经过指令微调的大语言模型训练出来的RADAR检测器,对其他大语言模型生成的文本也能有效检测,这意味着有可能基于现有的先进大语言模型训练出通用的AI文本检测器。
1 Introduction(引言)
大语言模型(LLMs)是一种非常厉害的神经网络,它在大规模的网络数据集上进行预训练。打个比方,它就像是一个知识储备极其丰富的“超级大脑”,在很多自然语言处理任务中都能表现得非常出色,比如完成文档、回答问题、翻译文章,还有根据提示创作内容等。像我们常用的聊天机器人,很多都是基于大语言模型开发的,它们能够流畅、准确地和我们对话。
但是,随着大语言模型及其相关应用越来越普及,新的问题也出现了。其中一个大问题就是很难区分哪些文本是大语言模型生成的(AI文本),哪些是人类写的。这会引发一系列麻烦,比如虚假内容泛滥,有些不良商家可能用AI生成虚假的产品宣传文案;还有学术抄袭,学生用大语言模型写论文来作弊。而且,现在的AI文本检测器不太靠谱。OpenAI发布的报告显示,他们的AI文本检测器在一些有挑战性的英文文本测试中,只能正确识别26%的AI文本,却把9%的人类写的文本误判为AI文本。另外,当遇到非英语母语者写的文本时,那些最先进的AI文本检测器的性能会大幅下降。
更糟糕的是,现有的AI文本检测器很容易被“糊弄”。有研究发现,用大语言模型来改写文本,即使原来的AI文本做了水印标记,也能轻松躲过一些检测方法。 这就好比给一个人化了妆,让警察认不出来一样。这些情况引发了人们的讨论:到底能不能设计出可靠的AI文本检测器呢?有的研究从理论上分析,认为AI文本很难检测,但也有研究表明,只要人类文本和AI文本的分布不完全一样,就有可能设计出可靠的检测器。
为了提升AI文本检测的水平,本文提出了RADAR框架,它借鉴了对抗机器学习技术。就像在一场游戏中,有两个对手,一个是改写器,一个是检测器。改写器想通过生成逼真的内容来逃避检测,检测器则努力提高检测能力。在这个框架里,改写器和检测器都是由不同的大语言模型构成的。训练的时候,改写器会根据训练语料库(由目标大语言模型从人类文本语料库生成)改写文本,希望降低被检测器识别为AI文本的概率;而检测器会从训练数据和改写器的输出中学习,对比人类文本和AI文本,提高检测性能。它们会不断地调整自己的参数,直到各自的验证损失稳定下来。比如说,改写器会把检测器的预测结果当成奖励,用近端策略优化(PPO)方法来更新自己;检测器则根据人类文本和AI文本语料库(包括改写器生成的文本),通过逻辑损失函数来更新参数。在评估阶段,训练好的检测器就可以用来判断输入文本是AI生成的可能性有多大。
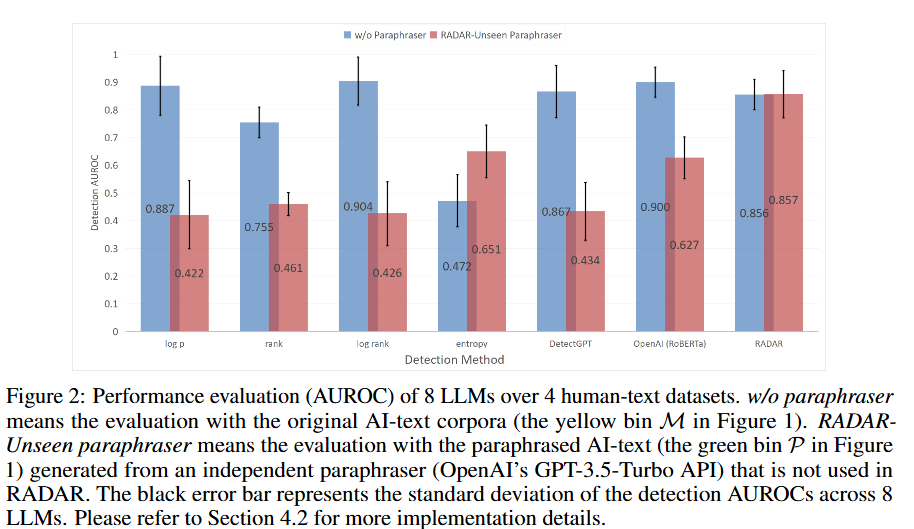
通过实验对比,在8种不同的大语言模型和4个数据集上,RADAR在检测原始AI生成文本时,和现有方法表现差不多;但在面对“没见过”的改写器改写的文本时,RADAR的检测能力明显更强。这说明RADAR确实是一个很有效的AI文本检测框架,而且它的检测能力还能在不同的大语言模型之间迁移,为训练通用的AI文本检测器带来了希望。
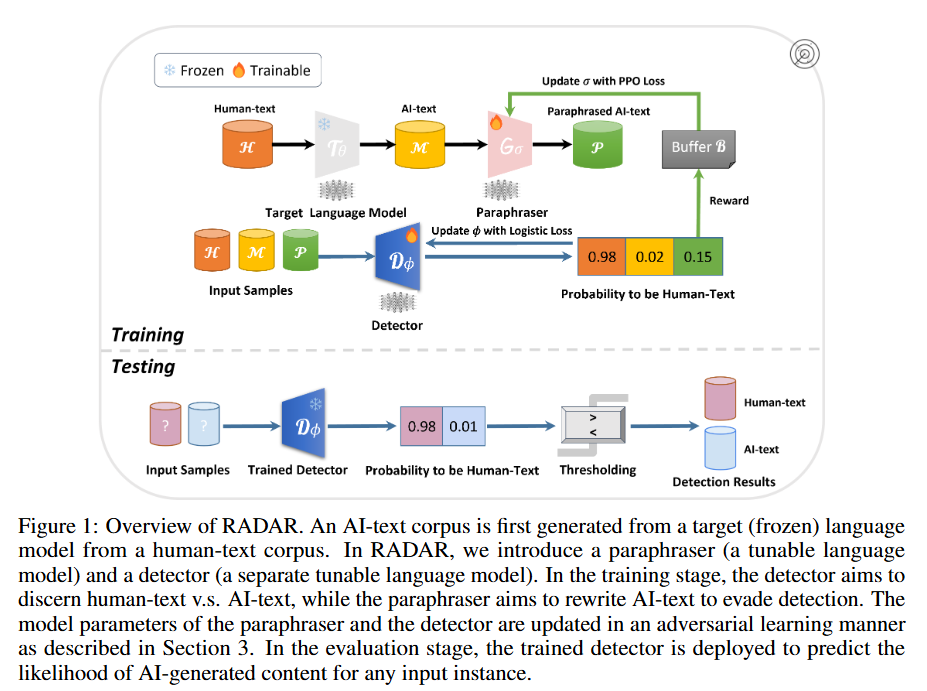
2 Related Work(相关工作)
AI文本检测
目前AI文本检测的研究主要有三种方法:
- 统计方法:这类方法是通过一些统计数据,像熵、n - gram频率和困惑度等,来设定一个标准,以此判断文本是不是AI生成的。比如说GLTR这个典型例子,它就是利用熵、概率和概率排名来检测。还有一个较新的工作是DetectGPT,它有个假设,认为机器生成的文本通常处于目标大语言模型对数概率的负曲率区域。基于这个假设,DetectGPT会用像T5这样的掩码填充语言模型去干扰输入文本,然后通过比较文本及其填充后的变体的对数概率来进行AI文本检测。打个比方,DetectGPT就像是给文本做了个“小手术”,看看手术后的变化来判断它是不是AI生成的。
- 分类方法:这种方法把AI文本检测看作是一个二分类任务,针对目标语言模型训练一个分类器。以OpenAI为例,他们用基于RoBERTa的模型来训练AI文本分类器。具体做法是,先从WebText数据集收集样本并标记为人类生成的文本,然后针对每个目标GPT - 2模型,收集其生成的样本并标记为机器生成的文本,最后对预训练的基于RoBERTa的模型进行微调,用于AI文本分类。后来,随着ChatGPT的出现,OpenAI又用多个来源的数据调整了一个叫AI - Classifier1的GPT模型。其中人类写的文本来自新的维基百科数据集、2019年收集的WebText数据集,以及训练InstructGPT时收集的一组人类示范数据。对于机器生成的文本,从维基百科和WebText数据集中采样文章并截断,用34个模型生成文章补全内容,将生成的文本与原始文章配对;对于示范数据,用模型为每个提示生成回复并与相应的人类示范配对。不过这个检测器从2023年1月发布后只能通过网页界面访问,而且从2023年7月起就下线了。
- 水印方法:这是一种事后添加水印的技术,包括基于规则的方法和基于深度学习的方法,可以应用到大语言模型上。比如在推理时,有人提出了一种软水印方案,通过把词汇表分成不同的列表,以不同方式采样下一个词,从而在生成句子的每个单词中嵌入水印。但是,很多现有的AI文本检测器在遇到改写后的文本时,检测能力会明显下降。就好比给文本加了个水印做标记,但是文本被改写后,这个标记就不太起作用了,检测器很难再识别出来。
自然语言生成中的对抗学习
生成对抗网络(GAN)在计算机视觉领域取得了成功,这启发了很多自然语言生成方面的研究。不过,文本生成是在离散词汇空间中按顺序采样的过程,很难像在计算机视觉中那样直接用反向传播进行端到端训练。目前有两种常见的解决办法:
- 用连续近似技术替代离散采样操作,比如Gumbel - Softmax方法。
- 把文本生成看作是一个决策过程,将生成器视为一种策略。例如SeqGAN,在生成过程中,它把生成的词当作状态,把要生成的下一个词当作动作,采用蒙特卡罗搜索从判别器收集奖励信号。还有Diversity - Promoting GAN,它不用分类器作为判别器,而是用单向LSTM,并将词级和句子级的奖励结合到训练中。TextGAIL提出了一种模仿学习范式,把人类写的文本的奖励视为恒定值,然后用人类文本和AI文本的奖励,通过近端策略优化(PPO)来优化生成器。这些研究在训练生成器时,通常会先用最大似然估计(MLE)对生成文本序列的概率进行热身训练。另外,也有研究是从零开始训练语言GAN。本文提出的RADAR和这些研究不同,它重点是利用可调整的改写器来训练一个强大的AI文本检测器。还有一些研究,比如通过改写技术为自然语言处理任务寻找对抗样本,以及通过对抗训练来训练强大的语言模型,它们关注的是自然语言理解的正确性,这超出了本文AI文本检测的研究范围。
5 Conclusion(结论)
本文提出了一个名为RADAR的强大AI文本检测器训练框架,它采用对抗学习的方式,同时训练一个检测器和一个改写器。目前很多AI文本检测器在面对经过大语言模型改写的文本时,检测效果都不太好,而RADAR正是针对这个问题设计的。
论文作者在8种不同的大语言模型(像Pythia、Dolly 2.0等)和4个数据集上进行了大量实验。结果表明,RADAR确实很有效,它的检测能力在不同的大语言模型之间有很强的迁移性。比如说,用经过指令微调的大语言模型(如Vicuna - 7B)训练出来的RADAR检测器,对其他大语言模型生成的文本也能很好地检测。这就好像一个优秀的运动员,不仅在自己擅长的项目中表现出色,换个类似的项目也能发挥得很好。
总的来说,本文通过这些研究和实验,为改进AI文本检测提供了新的思路和方法,让人们在区分AI生成文本和人类生成文本方面有了新的方向。