java构建树形结构的方式、如何组装树状结构数据
文章目录
- 思考思路
- 实现:Java构建树状结构数据
- 1. 递归方式
- 2. 利用Stream流
- 3. 基于Map(推荐)
- 3.1 基于Map方式分析
- 4. 总结
思考思路
我在考虑如何在Java中构建树状数据结构:常见的方法包括递归、父子引用和使用节点列表等。可以通过创建树节点类来表示树形结构,例如,可以定义“树节点”类为:class Node { T data; List<Node> children; Node parent; }。
我将提供详细分析,看看哪些方法在实际项目中更常见,如何构建包含父子关系和操作树的数据结构。
这个问题的答案可能会包括多个常见的实现方式。
在 Java 中构建树状结构,常见方法包括:1. 递归:从父子关系数据递归构建树;2. 使用 Map/HashMap:存储节点并根据父子关系链接它们。我可以提供代码示例,如定义TreeNode 类如下:
public class TreeNode<T> {
private T data;
private List<TreeNode<T>> children = new ArrayList<>();
public TreeNode(T data) {
this.data = data;
}
public void addChild(TreeNode<T> child) {
children.add(child);
}
}
实现:Java构建树状结构数据
目的: 在 Java 中构建树状结构数据是一个非常常见的需求,通常用于展示分层数据(如:组织架构、菜单、文件目录等),下面详细介绍几种常见的方法、代码案例及实际项目中的实践经验。比如实现这样的分层效果:

这些数据都在数据库,所以查数据库:查出所有的数据,然后再组装返回给前端解析即可,当然数据表中应该设计成这样:
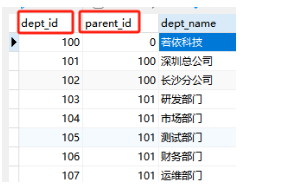
组装时只需要组装成一个 list 返回即可,前端拿到 list 解析。
1. 递归方式
原理: 递归方法基于“父子关系”的层级遍历,从根节点开始递归查找和添加子节点。适合节点层次较少的场景。
实现: 利用递归的方式进行树状结构数据的组装,代码如下:
@Data
@NoArgsConstructor
public class DeptEntity {
private Long deptId;
private Long parentId;
private String deptName;
private List<DeptEntity> children;
public DeptEntity(Long deptId, Long parentId, String deptName) {
this.deptId = deptId;
this.parentId = parentId;
this.deptName = deptName;
}
}
public class Test {
// 假数据:本来这一步是需要从数据库中查找所有的数据,然后再组装,为了方便,这里弄成假数据
public static List<DeptEntity> getData() {
List<DeptEntity> list = new ArrayList<>();
list.add(new DeptEntity(100L, 0L, "若依科技"));
list.add(new DeptEntity(101L, 100L, "深圳总公司"));
list.add(new DeptEntity(102L, 100L, "长沙分公司"));
list.add(new DeptEntity(103L, 101L, "研发部门"));
list.add(new DeptEntity(104L, 101L, "市场部门"));
list.add(new DeptEntity(105L, 102L, "运维部门"));
list.add(new DeptEntity(106L, 102L, "财务部门"));
return list;
}
public static void main(String[] args) {
recursionBuildTree();
}
// 方法1:递归
public static void recursionBuildTree() {
// 获取假数据
List<DeptEntity> data = getData();
// 留住最顶层节点
List<DeptEntity> collect = data.stream()
.filter(d -> d.getParentId() == 0L)
.collect(Collectors.toList());
//首先设置最顶层子节点
for (DeptEntity deptEntity : collect) {
deptEntity.setChildren(recursionBuildChildren(deptEntity.getDeptId(), data));
}
System.out.println(collect);
}
// 设置子节点
public static List<DeptEntity> recursionBuildChildren(Long deptId, List<DeptEntity> data) {
// 保存子节点
List<DeptEntity> children = new ArrayList<>();
// 寻找子节点
for (DeptEntity deptEntity : data) {
// 因为data是最原始数据,还是需要过滤掉最顶层节点
if (deptEntity.getParentId() == 0L) {
continue;
}
if (deptEntity.getParentId().equals(deptId)) {
children.add(deptEntity);
}
}
//递归遍历子节点
for (DeptEntity deptEntity : children) {
deptEntity.setChildren(recursionBuildChildren(deptEntity.getDeptId(), data));
}
return children;
}
}
2. 利用Stream流
1、上面的 DeptEntity 类代码不变
2、写方法:
public class Test {
// 假数据:本来这一步是需要从数据库中查找所有的数据,然后再组装,为了方便,这里弄成假数据
public static List<DeptEntity> getData() {
List<DeptEntity> list = new ArrayList<>();
list.add(new DeptEntity(100L, 0L, "若依科技"));
list.add(new DeptEntity(101L, 100L, "深圳总公司"));
list.add(new DeptEntity(102L, 100L, "长沙分公司"));
list.add(new DeptEntity(103L, 101L, "研发部门"));
list.add(new DeptEntity(104L, 101L, "市场部门"));
list.add(new DeptEntity(105L, 102L, "运维部门"));
list.add(new DeptEntity(106L, 102L, "财务部门"));
return list;
}
public static void main(String[] args) {
streamBuildTree();
}
// 方法2:Stream流
public static void streamBuildTree() {
List<DeptEntity> data = getData();
// 按照parentId分组,将数据转为Map<parentId, 属于这个parentId的数据的一个集合>
Map<Long, List<DeptEntity>> collect = data.stream()
.collect(Collectors.groupingBy(DeptEntity::getParentId));
// 开始构建树
List<DeptEntity> list = streamBuildChildren(0L, collect);
System.out.println(list);
}
// 设置子节点
public static List<DeptEntity> streamBuildChildren(Long parentId, Map<Long, List<DeptEntity>> collect) {
return Optional.ofNullable(collect.get(parentId))
.orElse(new ArrayList<>()) // 避免报空指针异常
.stream()
.peek(child -> child.setChildren(streamBuildChildren(child.getDeptId(), collect)))
.collect(Collectors.toList());
}
}
3. 基于Map(推荐)
原理: 首先将所有节点存入一个哈希表(Map),键为节点的 id。然后遍历所有节点,根据其 parentId 找到对应父节点并加入到父节点的子节点列表中。这样可以避免递归的性能问题。
好处: 在 Java 中,使用 Map 来构建树结构是一种高效的方法。该方法避免了递归的性能问题,并且可以快速查找节点,提高构建树的效率。
实现: 如下:
1、上面的 DeptEntity 类代码不变
2、写方法:
public class Test {
// 假数据:本来这一步是需要从数据库中查找所有的数据,然后再组装,为了方便,这里弄成假数据
public static List<DeptEntity> getData() {
List<DeptEntity> list = new ArrayList<>();
list.add(new DeptEntity(100L, 0L, "若依科技"));
list.add(new DeptEntity(101L, 100L, "深圳总公司"));
list.add(new DeptEntity(102L, 100L, "长沙分公司"));
list.add(new DeptEntity(103L, 101L, "研发部门"));
list.add(new DeptEntity(104L, 101L, "市场部门"));
list.add(new DeptEntity(105L, 102L, "运维部门"));
list.add(new DeptEntity(106L, 102L, "财务部门"));
return list;
}
public static void main(String[] args) {
mapBuildTree();
}
// 方法3:基于Map 1
public static void mapBuildTree() {
// 获取假数据
List<DeptEntity> data = getData();
// 存放根节点
List<DeptEntity> roots = new ArrayList<>();
// 存放所有子节点
Map<Long, List<DeptEntity>> childMap = new HashMap<>();
// 1.初始化childMap,确保不会出现null
for (DeptEntity deptEntity : data) {
childMap.put(deptEntity.getDeptId(), new ArrayList<>());
}
// 2.构建树结构
for (DeptEntity deptEntity : data) {
// 根节点
if (deptEntity.getParentId() == null || deptEntity.getParentId() == 0) {
roots.add(deptEntity);
} else {
// 非根节点,加入到父节点的children列表
childMap.get(deptEntity.getParentId()).add(deptEntity);
}
}
// 3.统一赋值children
for (DeptEntity deptEntity : data) {
deptEntity.setChildren(childMap.get(deptEntity.getDeptId()));
}
System.out.println(roots);
}
}
基于 Map 的方式还有一个,如下:
public class DeptEntity {
private Long deptId;
private Long parentId;
private String deptName;
private List<DeptEntity> children = new ArrayList<>();
// 构造方法
public DeptEntity(Long deptId, Long parentId, String deptName) {
this.deptId = deptId;
this.parentId = parentId;
this.deptName = deptName;
}
// Getter & Setter
public Long getDeptId() { return deptId; }
public Long getParentId() { return parentId; }
public String getDeptName() { return deptName; }
public List<DeptEntity> getChildren() { return children; }
// 加一个这个方法
public void addChild(DeptEntity child) {
this.children.add(child);
}
}
public class Test {
// 假数据:本来这一步是需要从数据库中查找所有的数据,然后再组装,为了方便,这里弄成假数据
public static List<DeptEntity> getData() {
List<DeptEntity> list = new ArrayList<>();
list.add(new DeptEntity(100L, 0L, "若依科技"));
list.add(new DeptEntity(101L, 100L, "深圳总公司"));
list.add(new DeptEntity(102L, 100L, "长沙分公司"));
list.add(new DeptEntity(103L, 101L, "研发部门"));
list.add(new DeptEntity(104L, 101L, "市场部门"));
list.add(new DeptEntity(105L, 102L, "运维部门"));
list.add(new DeptEntity(106L, 102L, "财务部门"));
return list;
}
public static void main(String[] args) {
mapBuildTree();
}
// 方法3:基于Map 2
public static void mapBuildTree() {
// 获取假数据
List<DeptEntity> data = getData();
List<DeptEntity> roots = new ArrayList<>();
Map<Long, DeptEntity> childMap = new HashMap<>();
// 1.将所有节点存入Map中
for (DeptEntity deptEntity : data) {
childMap.put(deptEntity.getDeptId(), deptEntity);
}
// 2.构建树结构
for (DeptEntity deptEntity : data) {
// 根节点
if (deptEntity.getParentId() == null || deptEntity.getParentId() == 0) {
roots.add(deptEntity);
} else {
// 非根节点,加入到父节点的children列表
DeptEntity parent = map.get(deptEntity.getParentId());
if (parent != null) {
parent.addChild(deptEntity);
}
}
}
System.out.println(roots);
}
}
3.1 基于Map方式分析
1、代码分析:
- 先将所有节点存入
Map<Long, DeptEntity>,便于快速查找。 - 遍历 data:
1、如果 parentId 为 null 或 0,表示它是根节点,加入 roots 列表。
2、否则,在 map 中查找 parentId 对应的父节点,并将该节点加入父节点的 children 列表。
2、优势分析:
(1)时间复杂度:遍历列表 data 两次,因此时间复杂度为 O(n),相比递归构建树(可能达到 O(n²))效率更高。
(2)空间复杂度:使用了 Map<Long, DeptEntity>,其空间复杂度是 O(n),额外开销较小。
(3)避免递归问题:采用 Map 直接查找父节点,避免递归调用,避免栈溢出问题,特别适用于深度较大的树结构。
3、适合场景:
✅ 数据量大,如百万级别的分类、菜单、组织架构等。
✅ 层级较深,如文件目录、权限管理系统。
✅ 频繁查询,构建后可以缓存树,提高性能。
4、不适合场景:
❌ 数据量特别小(<100),可以直接使用递归方法,代码更简洁。
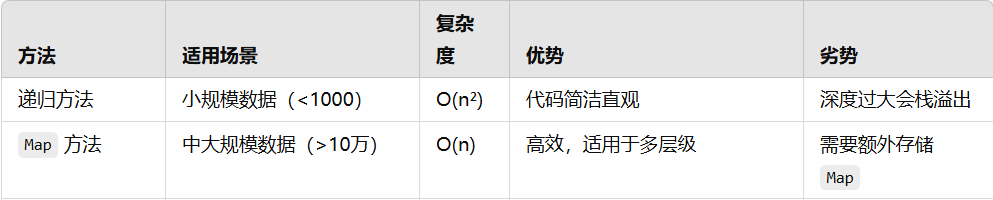
4. 总结
至此,文章结束,主页还有更多精彩文章哦!!!