Java 中的序列化和反序列化是什么?
Java 中的序列化和反序列化是什么?
推荐答案
回答重点
序列化
是将对象转换为字节流的过程,这样对象可以通过网络传输、持久化存储或者缓存。Java 提供了 java.io.Serializable 接口来支持序列化,只要类实现了这个接口,就可以将该类的对象进行序列化。
反序列化
是将字节流重新转换为对象的过程,即从存储中读取数据并重新创建对象。
其它
- 应用场景:包括网络传输、远程调用、持久化存储(如保存到文件或数据库)、以及分布式系统中数据交换。
- Java 序列化关键类和接口:
ObjectOutputStream用于序列化,ObjectInputStream用于反序列化。类必须实现Serializable接口才能被序列化。 - transient 关键字:在序列化过程中,有些字段不需要被序列化,例如敏感数据,可以使用
transient关键字标记不需要序列化的字段。 - serialVersionUID:每个
Serializable类都应该定义一个serialVersionUID,用于在反序列化时验证版本一致性。如果没有明确指定,Java 会根据类的定义自动生成一个 UID,版本不匹配可能导致反序列化失败。 - 序列化性能问题:Java 的默认序列化机制可能比较慢,尤其是对于大规模分布式系统,可能会选择更加高效的序列化框架(如 Protobuf、Kryo)。
- 安全性:反序列化是一个潜在的安全风险,因为通过恶意构造的字节流,可能会加载不安全的类或执行不期望的代码。因此,反序列化过程需要进行输入验证,避免反序列化漏洞。
扩展知识
序列化与反序列化理解
序列化其实就是将对象转化成可传输的字节序列格式,以便于存储和传输。
因为对象在 JVM 中可以认为是 " 立体 " 的,会有各种引用,比如在内存地址 Ox1234 引用了某某对象,那此时这个对象要传输到网络的另一端时候就需要把这些引用 " 压扁 "。
因为网络的另一端的内存地址 Ox1234 可以没有某某对象,所以传输的对象需要包含这些信息,然后接收端将这些扁平的信息再反序列化得到对象。
所以,反序列化就是将字节序列格式转换为对象的过程。
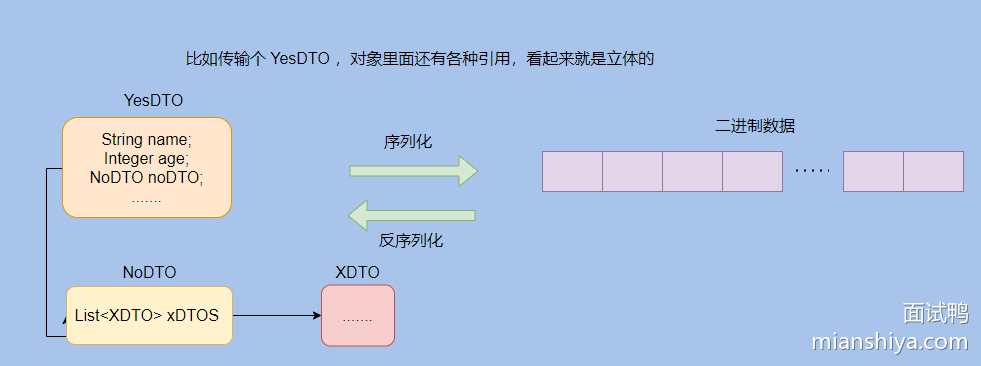
Java 序列化 Serializable 的意义
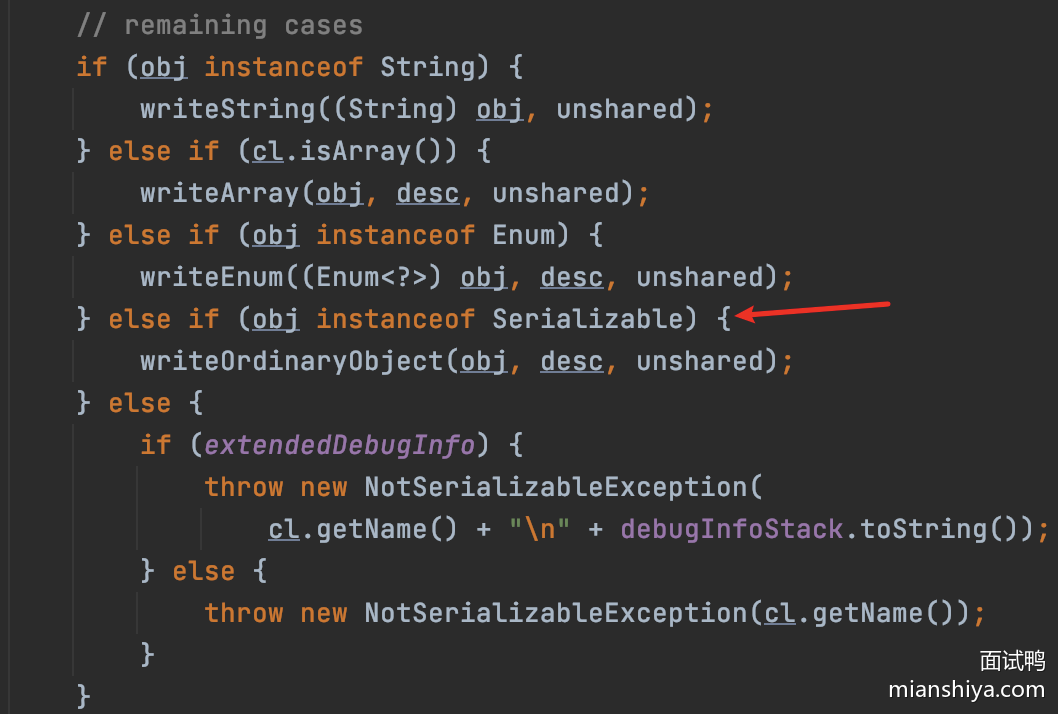
首先说一下 Serializable,这个接口没有什么实际的含义,就是起标记作用。
来看下源码就很清楚了,除了 String、数组和枚举之外,如果实现了这个接口就走 writeOrdinaryObject,否则就序列化就抛错。
serialVersionUID 又有什么用?
private static final long serialVersionUID = 1L;
想必经常会看到这样的代码,这个 ID 其实就是用来验证序列化的对象和反序列化对应的对象的 ID 是否是一致的。
所以这个 ID 的数字其实不重要,无论是 1L 还是 idea 自动生成的,只要序列化的时候对象的 serialVersionUID 和反序列化的时候对象的 serialVersionUID 一致的话就行。
如果没有显式指定 serialVersionUID,则编译器会根据类的相关信息自动生成一个,可以认为是一个指纹。
所以如果你没有定义一个 serialVersionUID 然后序列化一个对象之后,在反序列化之前把对象的类的结构改了,比如增加了一个成员变量,则此时的反序列化会失败。
因为类的结构变了,生成的指纹就变了,所以 serialVersionUID 就不一致了。
所以 serialVersionUID 就是起验证作用。
Java 序列化不包含静态变量
简单地说就是序列化之后存储的内容不包含静态变量的值,看一下下面的代码就很清晰了。

UID(serialVersionUID)
问题:什么是 UID(serialVersionUID)?
解答:serialVersionUID 是 Java 序列化机制中用来标识序列化类版本的一个唯一标识符。它的主要作用是在序列化和反序列化过程中保证版本一致性,防止反序列化时由于类版本不匹配导致的 InvalidClassException 异常。
在 Java 中,当一个对象被序列化时,Java 会将对象的类信息(包括类的结构、字段等)一起保存。serialVersionUID 就是这个类版本的一个标识符,用于确保序列化的版本与反序列化的版本兼容。
详细说明
-
定义:
serialVersionUID是一个静态常量,通常定义为private static final long serialVersionUID。- 该字段的值是一个长整型数字(
long),通常是手动指定的。
-
作用:
- 当你在进行序列化和反序列化操作时,Java 会检查该字段。如果类的
serialVersionUID和保存的序列化版本不一致,就会抛出InvalidClassException。 - 如果类的结构发生了改变(如添加、删除字段),但是
serialVersionUID没有做相应的更改,那么序列化的对象和反序列化时的类将不匹配,导致问题。
- 当你在进行序列化和反序列化操作时,Java 会检查该字段。如果类的
-
生成:
- 如果开发者不显式声明
serialVersionUID,Java 会根据类的内部结构自动生成一个serialVersionUID。这可能导致不同版本的类生成不同的serialVersionUID,进而影响兼容性。 - 一般推荐手动指定
serialVersionUID,以确保类在版本间的兼容性。
- 如果开发者不显式声明
-
使用场景:
- 适用于需要跨版本序列化和反序列化的情况。例如,如果你修改了类的字段或方法,并希望旧版本的对象可以继续反序列化,就需要确保版本号保持一致。
示例代码
import java.io.*;
public class Person implements Serializable {
private static final long serialVersionUID = 1L; // 定义 serialVersionUID
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public static void main(String[] args) {
try {
// 序列化对象
Person person = new Person("Alice", 30);
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.ser"));
out.writeObject(person);
out.close();
// 反序列化对象
ObjectInputStream in = new ObjectInputStream(new FileInputStream("person.ser"));
Person deserializedPerson = (Person) in.readObject();
in.close();
System.out.println("Name: " + deserializedPerson.getName());
System.out.println("Age: " + deserializedPerson.getAge());
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
总结
serialVersionUID是用来确保类版本兼容性的标识符。- 推荐显式定义
serialVersionUID,以避免不同版本类之间的兼容性问题。 - 如果类结构发生变化而不更新
serialVersionUID,可能导致反序列化失败。
ChatGPT:
序列化不包含静态变量
问题:序列化不包含静态变量是什么意思?
解答: 在 Java 中,序列化指的是将对象的状态(字段的值)转换为字节流,以便能够将对象存储到文件、数据库或者通过网络传输。反序列化则是将这些字节流恢复为对象的过程。
静态变量(static)是属于类的,而不是某个对象实例的。由于静态变量在所有实例间共享,所以它的值不属于某个具体对象,而是类的一个共享成员。
当对象被序列化时,静态变量不被序列化。这是因为静态变量不属于对象实例的状态,它与对象的具体数据无关,所以不需要被序列化。序列化过程中只会序列化对象实例的非静态字段。
详细说明
-
静态变量的作用:
- 静态变量是类级别的变量,不属于某个对象实例。当类加载时,静态变量会被初始化,且在所有类的实例间共享。
- 静态变量不包含在序列化过程中,因为它们的值对所有对象实例都是一样的。
-
为什么不序列化静态变量:
- 静态变量的值是类级别的,不依赖于对象的实例化状态。因此,序列化一个对象时,它的静态变量并没有必要被保存或恢复。
- 如果静态变量被序列化,它将会和对象的状态无关,可能导致不一致或混乱,尤其是在不同的 JVM 实例或版本之间。
-
静态变量与实例变量:
- 实例变量:属于某个特定的对象实例,在序列化时会被保存和恢复。
- 静态变量:属于类级别,在序列化时不会被保存和恢复,反序列化时不会改变静态变量的值。
示例代码
import java.io.*;
public class Example implements Serializable {
private static final long serialVersionUID = 1L;
private int id; // 实例变量
private static String name; // 静态变量
public Example(int id) {
this.id = id;
}
public static void main(String[] args) {
try {
// 设置静态变量值
Example.name = "StaticName";
// 创建对象
Example example = new Example(123);
// 序列化对象
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("example.ser"));
out.writeObject(example);
out.close();
// 反序列化对象
ObjectInputStream in = new ObjectInputStream(new FileInputStream("example.ser"));
Example deserializedExample = (Example) in.readObject();
in.close();
// 查看反序列化后的结果
System.out.println("Deserialized ID: " + deserializedExample.id);
System.out.println("Static name (after deserialization): " + Example.name); // 静态变量
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
输出结果
Deserialized ID: 123
Static name (after deserialization): StaticName
关键点
id是实例变量,会被序列化和反序列化。name是静态变量,不会被序列化,所以反序列化后的对象中,静态变量的值依然是 “StaticName”。
总结
- 静态变量不会被序列化,因为它是属于类的,所有对象共享一个值,不依赖于实例状态。
- 序列化只会保存对象实例的状态(即实例变量的值),静态变量的值是通过类的加载来获取的。
ChatGPT:
序列化与反序列化的个人理解
你的个人理解如下:
序列化就是将对象转化为字节流(只有字节流这一种形式嘛?)用于信息等的传输,如前端将用户提交的信息转化为字节流通过网络请求发送给后端,后端通过反序列化为对象进行逻辑操作后将信息再次序列化存入数据库,对吗?
判断:存在偏差。
修正与扩展说明
-
序列化的形式不仅限于字节流:
- 序列化确实通常是将对象转换为字节流(如 Java 的
ObjectOutputStream将对象转换为字节流)。 - 但除了字节流,还有其他序列化形式,比如 JSON、XML、Protobuf 等,这些是更加常用的数据交换格式,可以通过文本或者二进制的形式存储和传输。
- 例如:
- JSON 是一种基于文本的序列化方式,常用于前后端交互。
- Protobuf 是一种高效的二进制序列化方式,常用于高性能场景。
- 序列化确实通常是将对象转换为字节流(如 Java 的
-
前端和后端的交互场景:
- 前端通常会将对象序列化为 JSON 或 XML 格式,通过网络传输到后端。
- 后端接收到请求后会反序列化为对象,进行业务逻辑操作。
-
序列化与数据库存储:
- 数据库存储通常不会直接存储序列化后的字节流,而是存储结构化的数据。
- 一般情况下,后端将用户信息反序列化为对象后,会将其转换为数据库记录(如表中的字段值),这些数据是以关系模型或 NoSQL 文档形式存储,而不是直接存储对象序列化后的字节流。
- 如果存储对象序列化后的数据,则多用于缓存或文件存储场景(如 Redis 缓存二进制数据、Blob 存储文件等)。
-
序列化的具体应用场景:
- 网络传输:将数据转换为 JSON 或 XML 格式传输。
- 数据持久化:将对象保存到文件或数据库中。
- 远程调用:在分布式系统中,序列化和反序列化用于服务间的远程方法调用(如 RPC)。
- 缓存:将对象序列化为二进制或字符串形式存储在缓存中(如 Redis)。
修正后的示例
-
前端到后端的交互:
-
用户提交信息,前端将对象序列化为 JSON:
{ "username": "Alice", "age": 25 } -
后端接收 JSON,反序列化为对象:
class User { String username; int age; } -
后端将
User对象保存到数据库。
-
-
后端存储数据到文件:
-
将
User对象序列化为字节流:ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("user.ser")); oos.writeObject(user); oos.close(); -
反序列化恢复对象:
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("user.ser"
-