LLMs基础学习(五)模型微调专题(上)
TFLOPS 是 tera floating-point operations per second 的缩写,也就是每秒万亿次浮点运算。这是衡量计算机性能的一个重要指标,尤其是在处理科学计算、人工智能等需要大量浮点运算的任务时。
文章目录
- LLMs基础学习(五)模型微调专题(上)
- 预备知识:大模型训练的四个关键阶段
- 1. 大模型需要微调的场景
- 2. 大语言模型的微调方法
- 3. 微调方法详细描述
- 一、微调技术总览
- 二、微调方法分类
- 4. 参数高校微调的办法
- 整体框架与图示说明
- 参数高效微调方法详解
- Adapter 类
- Prefix Tuning 类
- LoRA 类(低秩适配)
- 小结
LLMs基础学习(五)模型微调专题(上)
原视频链接
预备知识:大模型训练的四个关键阶段
- 预训练
- 是训练的核心与最耗时环节,消耗 99% 的资源,需超级计算机、大型 GPU 集群等大规模计算能力,以及海量文本语料数据。
- 目标是让模型学习语言基本规则、语义和上下文关系,因资源需求极高,普通开发者难以独立完成。
- 有监督微调
- 基于预训练模型,通过输入带标签的数据(如 “问题 - 正确答案” 对),让模型学习执行具体任务(如问答、文本生成)。
- 奖励建模
- 创建奖励模型,用于评估生成结果的质量,引导主模型向更优质的方向优化,建立结果质量评估标准。
- 强化学习
- 通常采用人类反馈的强化学习(RLHF),通过奖励信号进一步优化模型,使模型输出更贴近用户实际需求。
资源需求对比
- 预训练:硬件、计算成本极高,需长时间运行,依赖大规模算力支持。
- 微调阶段(有监督微调、奖励建模、强化学习):资源消耗相对轻量,仅需几块 GPU,耗时较短(几小时到几天)。
微调的核心目标
在预训练模型的通用能力基础上,针对特定任务(如写文章、回答专业问题)调整模型参数,优化模型性能,使其更精准地完成具体任务,实现从 “通用能力” 到 “专门化应用” 的升级。
小结
- 预训练是大模型的基础阶段,耗时耗资源,构建语言理解的底层能力。
- 微调则基于预训练的通用能力,通过任务专项优化,让模型更好地解决实际问题,体现 “通用→专用” 的训练逻辑。
1. 大模型需要微调的场景
- 任务复杂度高,情境学习失效
- 情境学习:通过在提示(Prompt)中加入任务示例让模型理解需求。但面对复杂任务(如多步逻辑推理、专业领域深度分析),若模型理解力不足,或小模型仅靠提示优化(Prompt Engineering)无法提升性能,需通过微调强化模型能力。
- 零样本 / 少样本推理效果差
- 零样本推理:无任务示例,依赖上下文直接推理,适用于通用场景,但专业任务(如法律条款解读)中易因语境理解不足失效。
- 少样本推理:加入 1 - 几个示例辅助输出,若仍无法满足精准性(如医学病例分析),微调成为优化必要手段。
- 领域或任务高度专业化
- 预训练模型虽通用,但若涉及专业领域(法律、医学、工程等术语知识),或需统一输出格式(如结构化数据提取)、高精准任务(医学诊断、自动化文档处理),微调可针对性注入领域知识,提升任务适配性。
- 输出结果不符用户需求
- 模型输出风格、语气不匹配(如用户需正式公文体,模型输出口语化),或需个性化、品牌化结果(企业定制回复话术),微调可校准输出特性。
- 总结性需求
当情境学习、零 / 少样本推理无法满足任务要求,或需在特定领域(如金融问答)提升准确率时,通过有监督微调,能显著增强模型在细分任务上的可靠性。
2. 大语言模型的微调方法
-
微调技术分类
- 全量微调(FFT):调整模型所有参数,理论优化充分,但资源消耗极大。大参数模型(如 12B 参数)在普通硬件易内存溢出(OOM),还可能导致模型遗忘预训练知识、损失多样性。
- 参数高效微调(PEFT):仅调整少量参数(如 LoRA 方法),固定预训练参数,大幅降低计算存储成本,部分场景泛化效果更优,解决全量微调的硬件门槛问题。
低秩适配(LoRA,Low-Rank Adaptation)
- 操作要点:冻结预训练模型的权重,在 Transformer 架构的每一层注入可训练的秩分解矩阵(降维矩阵 A 和升维矩阵 B)。在训练过程中,仅训练这些新增的矩阵,原始模型参数保持固定。
- 适用场景:适用于机器翻译、问答系统等需要大量计算资源和时间的长文本处理任务,能在保持模型性能的同时,显著减少可训练参数数量(相比使用 Adam 微调的 GPT - 3 175B,可将可训练参数数量减少 10000 倍)和 GPU 内存需求(减少 3 倍) 。
-
微调策略分类
- 有监督微调(SFT):输入带标签数据(如 “问题 - 答案” 对),让模型学习执行具体任务,例如训练模型回答专业领域问题。
- 基于人类反馈的强化学习(RLHF):通过奖励模型评估输出质量,以奖励信号引导模型优化,使结果更符合人类偏好,如提升回复的相关性。
-
资源需求对比
表格对比显示:全量微调大参数模型(如 7B 参数的 bloomz-7b1)会触发 OOM,而 PEFT-LoRA 方法结合 DeepSpeed+CPU Offloading 技术,可将 GPU 内存消耗降至 9.8GB,显著提升在消费级硬件上的可行性,平衡性能与资源消耗。
小结
梳理了大模型微调的应用场景(复杂任务、专业领域、输出适配等)及技术体系(全量 / 参数高效微调、SFT/RLHF 策略),突出参数高效微调因低成本、易部署成为主流方向,为模型优化提供理论与实践指导。
3. 微调方法详细描述
一、微调技术总览
-
全量微调(Full Fine Tuning, FFT)
- 操作核心:重新训练模型所有参数,全面适配特定任务。例如训练法律文书模型,需调整全部参数学习法律逻辑。
- 缺点:计算成本高,易引发 “灾难性遗忘”,如模型学习新任务时丢失通用能力。
- 场景:预算充足且任务精度要求极高的领域,如医疗诊断模型。
- 类比:彻底翻新整个房子,改变所有结构。
-
参数高效微调(Parameter-Efficient Fine Tuning, PEFT)
- 操作核心:仅调整部分参数(如新增低秩矩阵),固定预训练参数。如用 LoRA 方法添加可训练矩阵。
- 优势:降低计算成本,保留模型多任务性能,普通硬件即可运行。
- 场景:资源有限的场景,如小型企业开发客服机器人。
- 类比:局部改造房子,只翻新厨房或浴室。
二、微调方法分类
-
有监督微调(Supervised Fine Tuning, SFT)
- 逻辑:利用标注数据(如 “问题 - 答案”)指导模型学习。例如用电商 “咨询 - 回复” 数据训练客服模型。
- 技术细节
- 超参数调整:优化学习率、批量大小,类比烹饪调整火候。
- 迁移学习:基于预训练模型,用少量新数据微调,如通用模型转医疗领域。
- 多任务学习:同时训练相关任务(如新闻分类 + 情感分析),提升综合能力。
- 少样本学习:通过少量数据学习新任务,如法律案例生成文书。
- 任务特定微调:专注单一任务优化,如训练数学题解答模型。
-
基于人类反馈的强化学习(Reinforcement Learing with Human Feedback, RLHF)
-
逻辑:通过人类对输出的评价(评分、偏好)优化模型。如聊天机器人根据人类反馈调整回复。
-
技术细节
- 奖励建模:训练奖励模型学习人类评分标准,类比学生按老师反馈改作文。
- PPO 优化:稳定更新模型策略,类似跑步者循序渐进增加训练强度。
- 比较排名:人类对模型输出排序,模型学习优化,如品酒师筛选优质酒款。
- 偏好学习:根据人类偏好调整输出,如商家按消费者偏好优化产品。
- 结合 PEFT:减少训练参数量,类比裁缝修改衣服细节而非重做。
-
4. 参数高校微调的办法
大语言模型中参数高效微调(PEFT)的三大主流方法,结合架构图示与文字说明,深入解析各类方法的原理、模型嵌入位置及衍生技术,具体如下:
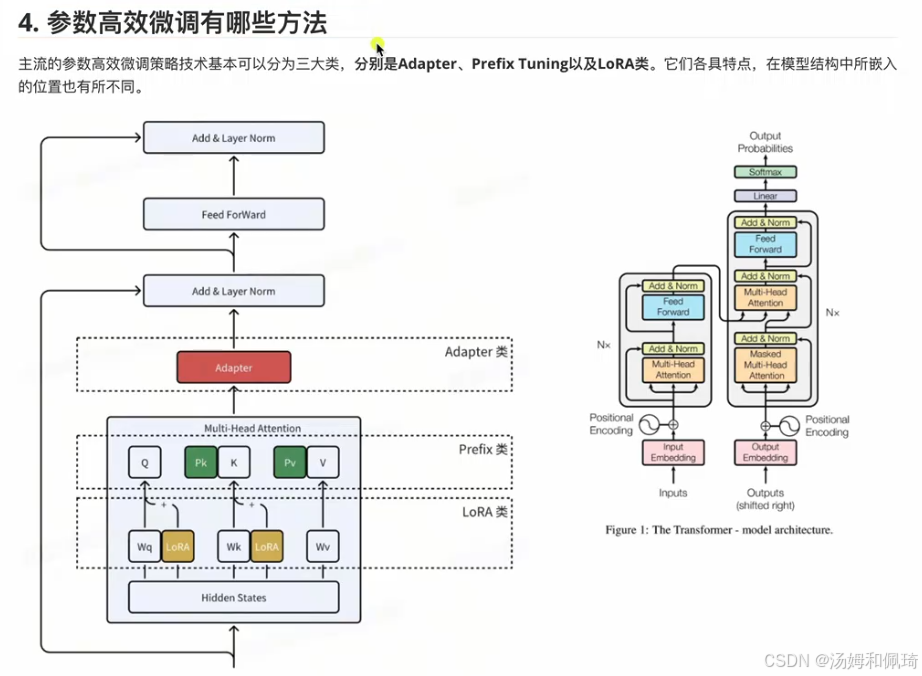
整体框架与图示说明
- 图示结构
- 左侧示意图展示三类微调方法在 Transformer 模型架构中的嵌入位置,右侧为 Transformer 基础架构(包含输入嵌入、多头注意力、前馈网络等模块),为理解方法嵌入逻辑提供参照。
- 三类方法在模型不同位置引入可训练参数,实现 “少参数微调” 目标,降低计算成本。
参数高效微调方法详解
Adapter 类
- 原理:
在预训练模型的各层之间插入小型神经网络模块(“适配器”)。微调时,仅训练适配器参数,固定原有模型参数,以少量新增参数实现任务适配。 - 模型嵌入位置:
在 Transformer 架构的层间(如多头注意力层与前馈网络层之间)嵌入 Adapter 模块,作为独立可训练单元。 - 衍生技术:
如 AdapterP、Parallel 等。AdapterP 优化适配器结构设计,提升参数利用效率;Parallel 探索并行训练适配器的方式,加速微调。
Prefix Tuning 类
- 原理:
在模型输入层或隐层添加可训练前缀标记(k 个)。微调时,仅更新前缀参数,引导模型关注特定任务信息,无需改动大量原有参数。 - 模型嵌入位置:
在多头注意力模块的输入部分,于查询(Q)、键(K)、值(V)矩阵旁引入前缀标记(如 Pk、Pv),参与注意力计算。 - 衍生技术:
典型如 P-Tuning、P-Tuning v2。P-Tuning 通过连续型前缀提升效果;P-Tuning v2 在更多层应用前缀,优化复杂任务适配能力。
LoRA 类(低秩适配)
- 原理:
引入低秩矩阵近似模拟模型权重矩阵 W 的更新。微调时,仅训练低秩矩阵参数,以小参数调整优化模型性能。 - 模型嵌入位置:
在多头注意力层的权重矩阵(如 Wq、Wk、Wv)旁添加 LoRA 低秩矩阵,修改注意力计算逻辑。 - 衍生技术:
包括 AdaLoRA、QLoRA 等。AdaLoRA 自适应调整训练方式;QLoRA 结合量化技术,减少内存消耗并保持性能。
小结
图片通过图示与文字结合,呈现了参数高效微调的三大技术路线:Adapter 类插入适配器、Prefix Tuning 类添加前缀标记、LoRA 类引入低秩矩阵。这些方法从不同位置和原理实现 “少参数训练”,在降低计算成本的同时,提升模型特定任务性能,是大语言模型高效微调的核心技术,为资源有限场景下的模型优化提供关键方案。