CUDA编程(6):CUDA流、并发内核执行、重叠核函数执行与内核传输、流回调
目录
1 流和事件概述
2 在默认流中重叠主机和设备计算
3 用非默认CUDA流重叠多个核函数的执行
4 用非默认 CUDA 流重叠核函数的执行与数据传递
4.1 不可分页主机内存与异步的数据传输函数
4.2 重叠核函数执行与数据传输的例子
5 流回调
参考文献:
1 流和事件概述
CUDA 程序的并行层次主要有两个,一个是核函数内部的并行,一个是核函数外部的
并行。我们之前讨论的都是核函数内部的并行。核函数外部的并行主要指:
- 核函数计算与数据传输之间的并行。
- 主机计算与数据传输之间的并行。
- 不同的数据传输(回顾一下 cudaMemcpy 函数中的第 4 个参数)之间的并行。
- 核函数计算与主机计算之间的并行。
- 不同核函数之间的并行。
一个 CUDA 流指的是由主机发出的在一个设备中执行的 CUDA 操作(即和 CUDA 有关的操作,如主机-设备数据传输和核函数执行)序列。一个 CUDA 流中各个操作的次序是由主机控制的,按照主机发布的次序执行。然而,来自于两个不同 CUDA 流中的操作不一定按照某个次序执行,而有可能并发或交错地执行。
任何 CUDA 操作都存在于某个 CUDA 流中,要么是默认流(default stream),也称为空流
(null stream),要么是明确指定的非空流。在之前的章节中,我们没有明确地指定 CUDA 流,
那里所有的 CUDA 操作都是在默认的空流中执行的。
非默认的 CUDA 流(也称为非空流)是在主机端产生与销毁的。一个 CUDA 流由类型为 cudaStream_t 的变量表示,它可由如下 CUDA 运行时 API 函数产生:
cudaError_t cudaStreamCreate(cudaStream_t*);
cudaError_t cudaStreamDestroy(cudaStream_t);
cudaStream_t stream_1;
cudaStreamCreate(&stream_1); // 注意要传流的地址
cudaStreamDestroy(stream_1);为了检查一个 CUDA 流中的所有操作是否都在设备中执行完毕,CUDA 运行时 API 提
供了如下两个函数:
cudaError_t cudaStreamSynchronize(cudaStream_t stream);
cudaError_t cudaStreamQuery(cudaStream_t stream);函数 cudaStreamSynchronize 会强制阻塞主机,直到 CUDA 流 stream 中的所有操作都执行完毕。函数 cudaStreamQuery 不会阻塞主机,只是检查 CUDA 流 stream 中的所有操作是否都执行完毕。若是,返回 cudaSuccess,否则返回 cudaErrorNotReady。
2 在默认流中重叠主机和设备计算
虽然同一个 CUDA 流中的所有 CUDA 操作都是顺序执行的,但依然可以在默认流中
重叠主机和设备的计算。下面让我们通过数组相加的例子进行讨论。在数组相加的 CUDA 程序中与 CUDA 操作有关的语句如下:
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice);
sum<<<grid_size, block_size>>>(d_x, d_y, d_z, N);
cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost);从设备的角度来看,以上 4 个 CUDA 操作语句将在默认的 CUDA 流中按代码出现的顺序依
次执行。从主机的角度来看,数据传输是同步的(synchronous),或者说是阻塞的(blocking),意思是主机发出命令
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);之后,会等待该命令执行完毕,再往前走。在进行数据传输时,主机是闲置的,不能进行其他
操作。不同的是,核函数的启动是异步的(asynchronous),或者说是非阻塞的(non-blocking),意思是主机发出命令
sum<<<grid_size, block_size>>>(d_x, d_y, d_z, N);之后,不会等待该命令执行完毕,而会立刻得到程序的控制权。主机紧接着会发出从设备到主机传输数据的命令
cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost);然而,该命令不会被立即执行,因为这是默认流中的 CUDA 操作,必须等待前一个 CUDA 操作(即核函数的调用)执行完毕才会开始执行。
根据上述分析可知,主机在发出核函数调用的命令之后,会立刻发出下一个命令。在上面的例子中,下一个命令是进行数据传输,但从设备的角度来看必须等待核函数执行完毕。如果下一个命令是主机中的某个计算任务,那么主机就会在设备执行核函数的同时去进行一些计算。这样,主机和设备就可以同时进行计算。设备完全不知道在它执行核函数时,主机偷偷地做了些计算。
下面的程序是如何在默认流中重叠主机和设备的计算。该程序由数组相加的程序修改而成。在 timing 函数中,当选择条件 overlap 为真时,将在调用核函数之后调用一个主机端的函数。当选择条件 overlap 为假时,将在调用核函数之前调用主机端的函数。
void timing
(
const real *h_x, const real *h_y, real *h_z,
const real *d_x, const real *d_y, real *d_z,
const int ratio, bool overlap
)
{
float t_sum = 0;
float t2_sum = 0;
for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
if (!overlap)
{
cpu_sum(h_x, h_y, h_z, N / ratio);
}
gpu_sum<<<grid_size, block_size>>>(d_x, d_y, d_z);
if (overlap)
{
cpu_sum(h_x, h_y, h_z, N / ratio);
}
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
if (repeat > 0)
{
t_sum += elapsed_time;
t2_sum += elapsed_time * elapsed_time;
}
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
const float t_ave = t_sum / NUM_REPEATS;
const float t_err = sqrt(t2_sum / NUM_REPEATS - t_ave * t_ave);
printf("Time = %g +- %g ms.\n", t_ave, t_err);
}3 用非默认CUDA流重叠多个核函数的执行
虽然在一个默认流中就可以实现主机计算和设备计算的并行,但是要实现多个核函数之间的并行必须使用多个 CUDA 流。这是因为,同一个 CUDA 流中的 CUDA 操作在设备中是顺序执行的,故同一个 CUDA 流中的核函数也必须在设备中顺序执行,虽然主机在发出每一个核函数调用的命令后都立刻重新获得程序控制权。
在使用的多个 CUDA 流中,其中一个可以是默认流。此时各个流之间并不完全独立,
我们不讨论这种情况。我们仅讨论使用多个非默认流的情况。使用非默认流时,核函数的
执行配置中必须包含一个流对象。一个名为 my_kernel 的核函数只能用如下 3 种调用方式
之一:
my_kernel<<<N_grid, N_block>>>(函数参数);
my_kernel<<<N_grid, N_block, N_shared>>>(函数参数);
my_kernel<<<N_grid, N_block, N_shared, stream_id>>>(函数参数);如果用第一种调用方式,说明核函数没有使用动态共享内存,而且在默认流中执行;如果用第二种调用方式,说明核函数在默认流中执行,但使用了 N_shared 字节的动态共享内存;如果用第三种调用方式,则说明核函数在编号为stream_id 的 CUDA 流中执行,而且使用了 N_shared 字节的动态共享内存。在使用非空流但不使用动态共享内存的情况下,必须使用上述第三种调用方式,并将 N_shared 设置为零:
my_kernel<<<N_grid, N_block, 0, stream_id>>>(函数参数);下面的就是用多个流重叠多个核函数执行代码
#include "error.cuh"
#include <math.h>
#include <stdio.h>
#ifdef USE_DP
typedef double real;
#else
typedef float real;
#endif
const int NUM_REPEATS = 10;
const int N1 = 1024;
const int MAX_NUM_STREAMS = 30;
const int N = N1 * MAX_NUM_STREAMS;
const int M = sizeof(real) * N;
const int block_size = 128;
const int grid_size = (N1 - 1) / block_size + 1;
cudaStream_t streams[MAX_NUM_STREAMS];
void timing(const real *d_x, const real *d_y, real *d_z, const int num);
int main(void)
{
real *h_x = (real*) malloc(M);
real *h_y = (real*) malloc(M);
for (int n = 0; n < N; ++n)
{
h_x[n] = 1.23;
h_y[n] = 2.34;
}
real *d_x, *d_y, *d_z;
CHECK(cudaMalloc(&d_x, M));
CHECK(cudaMalloc(&d_y, M));
CHECK(cudaMalloc(&d_z, M));
CHECK(cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice));
for (int n = 0 ; n < MAX_NUM_STREAMS; ++n)
{
CHECK(cudaStreamCreate(&(streams[n])));
}
for (int num = 1; num <= MAX_NUM_STREAMS; ++num)
{
timing(d_x, d_y, d_z, num);
}
for (int n = 0 ; n < MAX_NUM_STREAMS; ++n)
{
CHECK(cudaStreamDestroy(streams[n]));
}
free(h_x);
free(h_y);
CHECK(cudaFree(d_x));
CHECK(cudaFree(d_y));
CHECK(cudaFree(d_z));
return 0;
}
void __global__ add(const real *d_x, const real *d_y, real *d_z)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n < N1)
{
for (int i = 0; i < 100000; ++i)
{
d_z[n] = d_x[n] + d_y[n];
}
}
}
void timing(const real *d_x, const real *d_y, real *d_z, const int num)
{
float t_sum = 0;
float t2_sum = 0;
for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
for (int n = 0; n < num; ++n)
{
int offset = n * N1;
add<<<grid_size, block_size, 0, streams[n]>>>
(d_x + offset, d_y + offset, d_z + offset);
}
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
if (repeat > 0)
{
t_sum += elapsed_time;
t2_sum += elapsed_time * elapsed_time;
}
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
const float t_ave = t_sum / NUM_REPEATS;
const float t_err = sqrt(t2_sum / NUM_REPEATS - t_ave * t_ave);
printf("%g\n", t_ave);
}
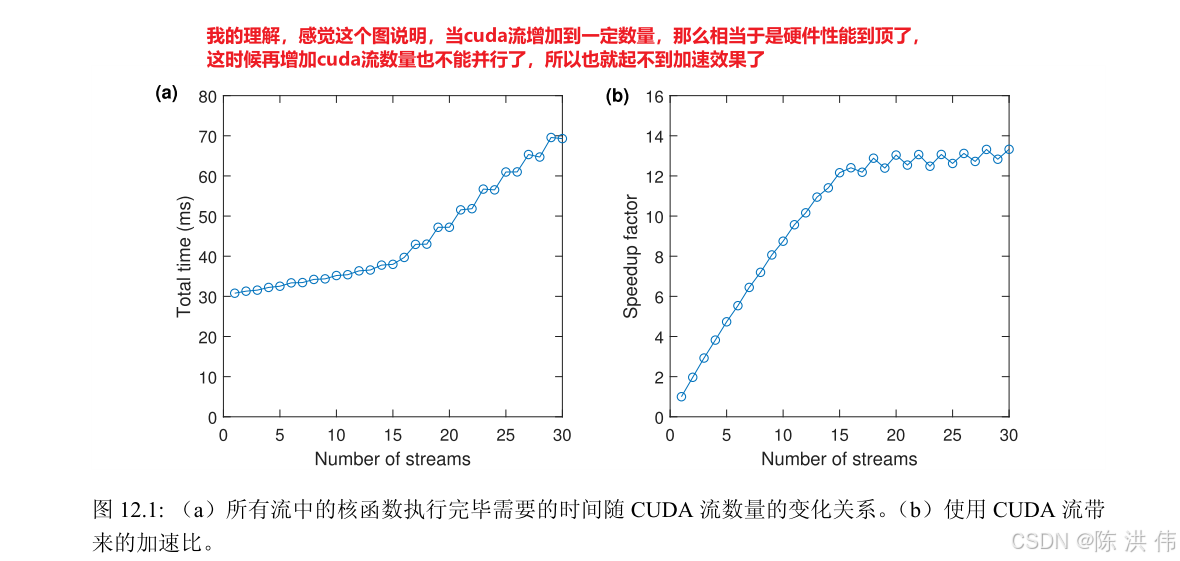
4 用非默认 CUDA 流重叠核函数的执行与数据传递
4.1 不可分页主机内存与异步的数据传输函数
要实现核函数执行与数据传输的并发(重叠),必须让这两个操作处于不同的非默认流,而且数据传输必须使用 cudaMemcpy 函数的异步版本,即 cudaMemcpyAsync 函数。异步传输由 GPU 中的 DMA(direct memory access)直接实现,不需要主机参与。如果用同步的数据传输函数,主机在向一个流发出数据传输的命令后,将无法立刻获得控制权,必须等待数据传输完毕。也就是说,主机无法同时去另一个流调用核函数。这样核函数与数据传输的重叠也就无法实现。异步传输函数的原型为
cudaError_t cudaMemcpyAsync
(
void *dst,
const void *src,
size_t count,
enum cudaMemcpyKind kind,
cudaStream_t stream
);也就是说,cudaMemcpyAsync 只比 cudaMemcpy 多一个参数。该函数的最后一个参数就是所在流的变量。
在使用异步的数据传输函数时,需要将主机内存定义为不可分页内存(non-pageable memory)或者固定内存(pinned memory)。不可分页内存是相对于可分页内存(pageable memory)的。操作系统有权在一个程序运行期间改变程序中使用的可分页主机内存的物理地址。相反,若主机中的内存声明为不可分页内存,则在程序运行期间,其物理地址将保持不变。如果将可分页内存传给 cudaMemcpyAsync 函数,则会导致同步传输,达不到重叠核函数执行与数据传输的效果。主机内存为可分页内存时,数据传输过程在使用 GPU 中的 DMA 之前必须先将数据从可分页内存移动到不可分页内存,从而必须与主机同步。主机无法在发出数据传输的命令后立刻获得程序的控制权,从而无法实现不同 CUDA 流之间的并发。
相关介绍可以看以前的博客
虚拟内存、内存分段、分页、CUDA编程中的零拷贝_cuda零拷贝内存-CSDN博客
不可分页主机内存的分配可以由以下两个 CUDA 运行时 API 函数中的任何一个实现:
cudaError_t cudaMallocHost(void** ptr, size_t size);
cudaError_t cudaHostAlloc(void** ptr, size_t size, size_t flags);注意,第二个函数的名字中没有字母 M。若函数 cudaHostAlloc 的第三个参数取默认
值 cudaHostAllocDefault,则以上两个函数完全等价。由以上函数分配的主机内存必须由如下函数释放:cudaError_t cudaFreeHost(void* ptr);如果不小心用了 free 函数释放不可分页主机内存,会出现运行错误。
4.2 重叠核函数执行与数据传输的例子
我们说过,在编写 CUDA 程序时要尽量避免主机与设备之间的数据传输,但这种数据传输一般来说是无法完全避免的。假如在一段 CUDA 程序中,我们需要先从主机向设备传输一定数量的数据(我们将此 CUDA 操作简称为 H2D),然后在 GPU 中使用所传输的数据做一些计算(我们将此 CUDA 操作简称为 KER,意为核函数执行),最后将一些数据从设备传输至主机(我们将此 CUDA 操作简称为 D2H)。下面,我们首先从理论上分析使用 CUDA 流可能带来的性能提升。
要利用多个流提升性能,就必须创造出在逻辑上可以并发执行的 CUDA 操作。一个方
法是将以上 3 个 CUDA 操作都分成若干等份,然后在每个流中发布一个 CUDA 操作序列。例如,使用两个流时,我们将以上 3 个 CUDA 操作都分成两等份。在理想情况下,它们的执行流程可以如下:
Stream 1:H2D -> KER -> D2H
Stream 2: H2D -> KER -> D2H
注意,这里的每个 CUDA 操作所处理的数据量只有使用一个 CUDA 流时的一半。我们注意到,两个流中的 H2D 操作不能并发地执行(受硬件资源的限制),但第二个流的 H2D 操作可以和第一个流的 KER 操作并发地执行,第二个流的 KER 操作也可以和第一个流的 D2H 操作并发地执行。如果 H2D、KER、和 D2H 这 3 个 CUDA 操作的执行时间都相同,那么就能有效地隐藏一个 CUDA 流中两个 CUDA 操作的执行时间,使得总的执行效率相比使用单个 CUDA 流的情形提升到 6/4 = 1:5 倍。
下面的代码是一个使用 CUDA 流重叠核函数执行和数据传输的例子。该程序一共计算 2 22 个数据对的和。当使用 num 个 CUDA 流时,每个 CUDA 流处理 N1 = N / num 对数据。
#include "error.cuh"
#include <math.h>
#include <stdio.h>
#ifdef USE_DP
typedef double real;
#else
typedef float real;
#endif
const int NUM_REPEATS = 10;
const int N = 1 << 22;
const int M = sizeof(real) * N;
const int MAX_NUM_STREAMS = 64;
cudaStream_t streams[MAX_NUM_STREAMS];
void timing
(
const real *h_x, const real *h_y, real *h_z,
real *d_x, real *d_y, real *d_z,
const int num
);
int main(void)
{
real *h_x, *h_y, *h_z;
CHECK(cudaMallocHost(&h_x, M));
CHECK(cudaMallocHost(&h_y, M));
CHECK(cudaMallocHost(&h_z, M));
for (int n = 0; n < N; ++n)
{
h_x[n] = 1.23;
h_y[n] = 2.34;
}
real *d_x, *d_y, *d_z;
CHECK(cudaMalloc(&d_x, M));
CHECK(cudaMalloc(&d_y, M));
CHECK(cudaMalloc(&d_z, M));
for (int i = 0; i < MAX_NUM_STREAMS; i++)
{
CHECK(cudaStreamCreate(&(streams[i])));
}
for (int num = 1; num <= MAX_NUM_STREAMS; num *= 2)
{
timing(h_x, h_y, h_z, d_x, d_y, d_z, num);
}
for (int i = 0 ; i < MAX_NUM_STREAMS; i++)
{
CHECK(cudaStreamDestroy(streams[i]));
}
CHECK(cudaFreeHost(h_x));
CHECK(cudaFreeHost(h_y));
CHECK(cudaFreeHost(h_z));
CHECK(cudaFree(d_x));
CHECK(cudaFree(d_y));
CHECK(cudaFree(d_z));
return 0;
}
void __global__ add(const real *x, const real *y, real *z, int N)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n < N)
{
for (int i = 0; i < 40; ++i)
{
z[n] = x[n] + y[n];
}
}
}
void timing
(
const real *h_x, const real *h_y, real *h_z,
real *d_x, real *d_y, real *d_z,
const int num
)
{
int N1 = N / num;
int M1 = M / num;
float t_sum = 0;
float t2_sum = 0;
for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
for (int i = 0; i < num; i++)
{
int offset = i * N1;
CHECK(cudaMemcpyAsync(d_x + offset, h_x + offset, M1,
cudaMemcpyHostToDevice, streams[i]));
CHECK(cudaMemcpyAsync(d_y + offset, h_y + offset, M1,
cudaMemcpyHostToDevice, streams[i]));
int block_size = 128;
int grid_size = (N1 - 1) / block_size + 1;
add<<<grid_size, block_size, 0, streams[i]>>>
(d_x + offset, d_y + offset, d_z + offset, N1);
CHECK(cudaMemcpyAsync(h_z + offset, d_z + offset, M1,
cudaMemcpyDeviceToHost, streams[i]));
}
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
if (repeat > 0)
{
t_sum += elapsed_time;
t2_sum += elapsed_time * elapsed_time;
}
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
const float t_ave = t_sum / NUM_REPEATS;
const float t_err = sqrt(t2_sum / NUM_REPEATS - t_ave * t_ave);
printf("%d %g\n", num, t_ave);
}
5 流回调
流回调是一种特别的技术,有点像是事件的函数,这个回调函数被放入流中,当其前面的任务都完成了,就会调用这个函数,但是比较特殊的是,在回调函数中,需要遵守下面的规则
- 回调函数中不可以调用CUDA的API
- 不可以执行同步
流函数有特殊的参数规格,必须写成下面形式参数的函数;
void CUDART_CB my_callback(cudaStream_t stream, cudaError_t status, void *data) {
printf("callback from stream %d\n", *((int *)data));
}然后使用:
cudaError_t cudaStreamAddCallback(cudaStream_t stream,cudaStreamCallback_t callback, void *userData, unsigned int flags);
#include <cuda_runtime.h>
#include <stdio.h>
#include "freshman.h"
#define N_REPEAT 10
#define N_SEGMENT 16
void CUDART_CB my_callback(cudaStream_t stream,cudaError_t status,void * data)
{
printf("call back from stream:%d\n",*((int *)data));
}
void sumArrays(float * a,float * b,float * res,const int size)
{
for(int i=0;i<size;i+=4)
{
res[i]=a[i]+b[i];
res[i+1]=a[i+1]+b[i+1];
res[i+2]=a[i+2]+b[i+2];
res[i+3]=a[i+3]+b[i+3];
}
}
__global__ void sumArraysGPU(float*a,float*b,float*res,int N)
{
int idx=blockIdx.x*blockDim.x+threadIdx.x;
if(idx < N)
//for delay
{
for(int j=0;j<N_REPEAT;j++)
res[idx]=a[idx]+b[idx];
}
}
int main(int argc,char **argv)
{
// set up device
initDevice(0);
double iStart,iElaps;
iStart=cpuSecond();
int nElem=1<<24;
printf("Vector size:%d\n",nElem);
int nByte=sizeof(float)*nElem;
float * a_h,*b_h,*res_h,*res_from_gpu_h;
CHECK(cudaHostAlloc((float**)&a_h,nByte,cudaHostAllocDefault));
CHECK(cudaHostAlloc((float**)&b_h,nByte,cudaHostAllocDefault));
CHECK(cudaHostAlloc((float**)&res_h,nByte,cudaHostAllocDefault));
CHECK(cudaHostAlloc((float**)&res_from_gpu_h,nByte,cudaHostAllocDefault));
cudaMemset(res_h,0,nByte);
cudaMemset(res_from_gpu_h,0,nByte);
float *a_d,*b_d,*res_d;
CHECK(cudaMalloc((float**)&a_d,nByte));
CHECK(cudaMalloc((float**)&b_d,nByte));
CHECK(cudaMalloc((float**)&res_d,nByte));
initialData(a_h,nElem);
initialData(b_h,nElem);
sumArrays(a_h,b_h,res_h,nElem);
dim3 block(512);
dim3 grid((nElem-1)/block.x+1);
//asynchronous calculation
int iElem=nElem/N_SEGMENT;
cudaStream_t stream[N_SEGMENT];
for(int i=0;i<N_SEGMENT;i++)
{
CHECK(cudaStreamCreate(&stream[i]));
}
cudaEvent_t start,stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start,0);
for(int i=0;i<N_SEGMENT;i++)
{
int ioffset=i*iElem;
CHECK(cudaMemcpyAsync(&a_d[ioffset],&a_h[ioffset],nByte/N_SEGMENT,cudaMemcpyHostToDevice,stream[i]));
CHECK(cudaMemcpyAsync(&b_d[ioffset],&b_h[ioffset],nByte/N_SEGMENT,cudaMemcpyHostToDevice,stream[i]));
sumArraysGPU<<<grid,block,0,stream[i]>>>(&a_d[ioffset],&b_d[ioffset],&res_d[ioffset],iElem);
CHECK(cudaMemcpyAsync(&res_from_gpu_h[ioffset],&res_d[ioffset],nByte/N_SEGMENT,cudaMemcpyDeviceToHost,stream[i]));
CHECK(cudaStreamAddCallback(stream[i],my_callback,(void *)(stream+i),0));
}
//timer
CHECK(cudaEventRecord(stop, 0));
int counter=0;
while (cudaEventQuery(stop)==cudaErrorNotReady)
{
counter++;
}
printf("cpu counter:%d\n",counter);
iElaps=cpuSecond()-iStart;
printf("Asynchronous Execution configuration<<<%d,%d>>> Time elapsed %f sec\n",grid.x,block.x,iElaps);
checkResult(res_h,res_from_gpu_h,nElem);
for(int i=0;i<N_SEGMENT;i++)
{
CHECK(cudaStreamDestroy(stream[i]));
}
cudaFree(a_d);
cudaFree(b_d);
cudaFree(a_h);
cudaFree(b_h);
cudaFree(res_h);
cudaFree(res_from_gpu_h);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return 0;
}
参考文献:
《CUD C编程权威指南》 程润伟 机械工业出版社
GitHub - Tony-Tan/CUDA_Freshman
《CUDA编程:基础与实践》 樊哲勇 清华大学出版社
GitHub - brucefan1983/CUDA-Programming: Sample codes for my CUDA programming book