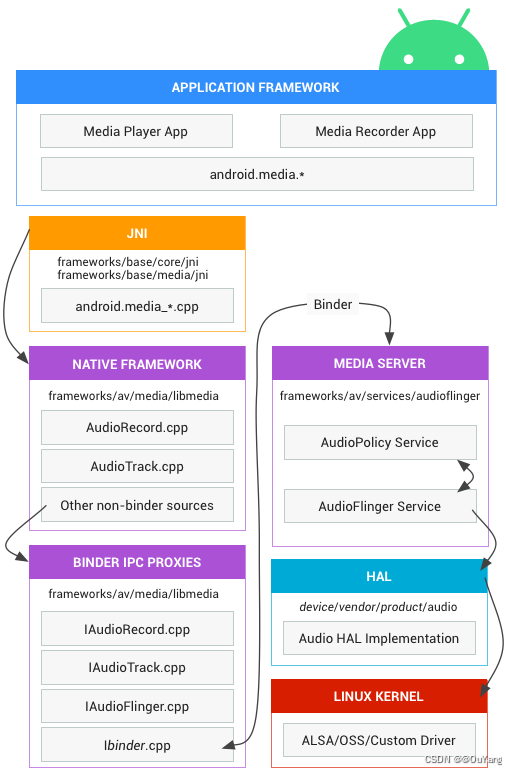
anroid10 音频系统之数据传递
1. AT端的流程
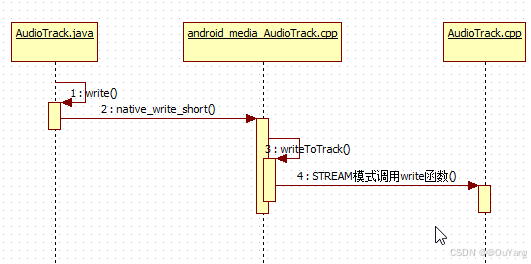
xref: /frameworks/base/media/java/android/media/AudioTrack.java
public int write(@NonNull short[] audioData, int offsetInShorts, int sizeInShorts,
@WriteMode int writeMode) {
.................................................................................
// 调用native层的write方法
final int ret = native_write_short(audioData, offsetInShorts, sizeInShorts, mAudioFormat,
writeMode == WRITE_BLOCKING);
if ((mDataLoadMode == MODE_STATIC)
&& (mState == STATE_NO_STATIC_DATA)
&& (ret > 0)) {
// benign race with respect to other APIs that read mState
mState = STATE_INITIALIZED;
}
return ret;
}
假设用例采用的是PCM16数据。它对应的JNI层函数是native_write_short。
xref: /frameworks/base/core/jni/android_media_AudioTrack.cpp
{"native_write_short", "([SIIIZ)I",(void *)android_media_AudioTrack_writeArray<jshortArray>}native_write_short对应的是android_media_AudioTrack_writeArray方法
static jint android_media_AudioTrack_writeArray(JNIEnv *env, jobject thiz,
T javaAudioData,
jint offsetInSamples, jint sizeInSamples,
jint javaAudioFormat,
jboolean isWriteBlocking) {
sp<AudioTrack> lpTrack = getAudioTrack(env, thiz);
...................................................................................
jint samplesWritten = writeToTrack(lpTrack, javaAudioFormat, cAudioData,
offsetInSamples, sizeInSamples, isWriteBlocking == JNI_TRUE /* blocking */);
envReleaseArrayElements(env, javaAudioData, cAudioData, 0);
return samplesWritten;
}调用writeToTrack方法
static jint writeToTrack(const sp<AudioTrack>& track, jint audioFormat, const T *data,
jint offsetInSamples, jint sizeInSamples, bool blocking) {
// give the data to the native AudioTrack object (the data starts at the offset)
ssize_t written = 0;
// regular write() or copy the data to the AudioTrack's shared memory?
size_t sizeInBytes = sizeInSamples * sizeof(T);
if (track->sharedBuffer() == 0) {// STREAM模式
// 调用write函数写数据
written = track->write(data + offsetInSamples, sizeInBytes, blocking);
// for compatibility with earlier behavior of write(), return 0 in this case
if (written == (ssize_t) WOULD_BLOCK) {
written = 0;
}
} else {// STATIC模式
// writing to shared memory, check for capacity
if ((size_t)sizeInBytes > track->sharedBuffer()->size()) {
sizeInBytes = track->sharedBuffer()->size();
}
// 直接把数据memcpy到共享内存,但是这种模式下要先调用write方法,然后调用play方法
memcpy(track->sharedBuffer()->pointer(), data + offsetInSamples, sizeInBytes);
written = sizeInBytes;
}
if (written >= 0) {
return written / sizeof(T);
}
return interpretWriteSizeError(written);
}AudioTrack有两种数据加载模式:MODE_STREAM和MODE_STATIC
MODE_STREAM:在这种模式下,通过write一次次把音频数据写到AudioTrack中。这和平时通过write系统调用往文件中写数据类似,但这种工作方式每次都需要把数据从用户提供的Buffer中拷贝到AudioTrack内部的Buffer中,这在一定程度上会使引入延时。为解决这一问题,AudioTrack就引入了第二种模式。
MODE_STATIC:这种模式下,在play之前只需要把所有数据通过一次write调用传递到AudioTrack中的内部缓冲区,后续就不必再传递数据了。这种模式适用于像铃声这种内存占用量较小,延时要求较高的文件。但它也有一个缺点,就是一次write的数据不能太多,否则系统无法分配足够的内存来存储全部数据。
1.1MODE_STREAM模式分析
xref: /frameworks/av/media/libaudioclient/AudioTrack.cpp
ssize_t AudioTrack::write(const void* buffer, size_t userSize, bool blocking)
{
if (mTransfer != TRANSFER_SYNC && mTransfer != TRANSFER_SYNC_NOTIF_CALLBACK) {
return INVALID_OPERATION;
}
if (isDirect()) {
AutoMutex lock(mLock);
int32_t flags = android_atomic_and(
~(CBLK_UNDERRUN | CBLK_LOOP_CYCLE | CBLK_LOOP_FINAL | CBLK_BUFFER_END),
&mCblk->mFlags);
if (flags & CBLK_INVALID) {
return DEAD_OBJECT;
}
}
if (ssize_t(userSize) < 0 || (buffer == NULL && userSize != 0)) {
// Sanity-check: user is most-likely passing an error code, and it would
// make the return value ambiguous (actualSize vs error).
ALOGE("%s(%d): AudioTrack::write(buffer=%p, size=%zu (%zd)",
__func__, mPortId, buffer, userSize, userSize);
return BAD_VALUE;
}
size_t written = 0;
//创建一个Buffer缓存
Buffer audioBuffer;
while (userSize >= mFrameSize) {
// 以帧为单位
audioBuffer.frameCount = userSize / mFrameSize;
// obtainBuffer从共享内存中得到一块空闲的数据块
status_t err = obtainBuffer(&audioBuffer,
blocking ? &ClientProxy::kForever : &ClientProxy::kNonBlocking);
if (err < 0) {
if (written > 0) {
break;
}
if (err == TIMED_OUT || err == -EINTR) {
err = WOULD_BLOCK;
}
return ssize_t(err);
}
// 空闲数据缓冲的大小是audioBuffer.size,地址在audioBuffer.i8中,数据传递通过memcpy完成
size_t toWrite = audioBuffer.size;
memcpy(audioBuffer.i8, buffer, toWrite);
buffer = ((const char *) buffer) + toWrite;
userSize -= toWrite;
written += toWrite;
// 释放缓存
releaseBuffer(&audioBuffer);
}
if (written > 0) {
mFramesWritten += written / mFrameSize;
if (mTransfer == TRANSFER_SYNC_NOTIF_CALLBACK) {
const sp<AudioTrackThread> t = mAudioTrackThread;
if (t != 0) {
// causes wake up of the playback thread, that will callback the client for
// more data (with EVENT_CAN_WRITE_MORE_DATA) in processAudioBuffer()
t->wake();
}
}
}
return written;
}申请一块空闲的数据块,然后通过memcpy复制到audioBuffer
2.AF端的流程
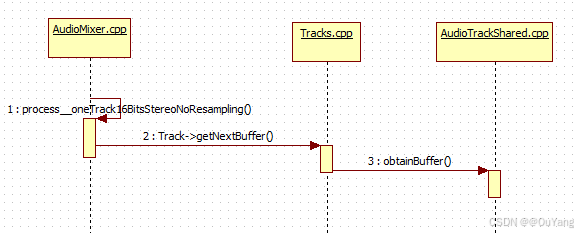
xref: /frameworks/av/media/libaudioprocessing/AudioMixer.cpp
void AudioMixer::process__oneTrack16BitsStereoNoResampling()
{
// 找到被激活的Track
const int name = mEnabled[0];
const std::shared_ptr<Track> &t = mTracks[name];
AudioBufferProvider::Buffer& b(t->buffer);
.......................................................................................
while (numFrames) {
b.frameCount = numFrames;
// BufferProvider就是Track对象,调用它的getNextBuffer获得可读数据缓冲
t->bufferProvider->getNextBuffer(&b);
const int16_t *in = b.i16;
......................................................................................
size_t outFrames = b.frameCount;
//数据处理,也就是混音
switch (t->mMixerFormat) {
......................................................................................
case AUDIO_FORMAT_PCM_16_BIT:
if (CC_UNLIKELY(uint32_t(vl) > UNITY_GAIN_INT || uint32_t(vr) > UNITY_GAIN_INT)) {
// volume is boosted, so we might need to clamp even though
// we process only one track.
do {
uint32_t rl = *reinterpret_cast<const uint32_t *>(in);
in += 2;
int32_t l = mulRL(1, rl, vrl) >> 12;
int32_t r = mulRL(0, rl, vrl) >> 12;
// clamping...
l = clamp16(l);
r = clamp16(r);
// 把数据复制给out缓冲
*out++ = (r<<16) | (l & 0xFFFF);
} while (--outFrames);
} else {
do {
uint32_t rl = *reinterpret_cast<const uint32_t *>(in);
in += 2;
int32_t l = mulRL(1, rl, vrl) >> 12;
int32_t r = mulRL(0, rl, vrl) >> 12;
*out++ = (r<<16) | (l & 0xFFFF);
} while (--outFrames);
}
break;
default:
LOG_ALWAYS_FATAL("bad mixer format: %d", t->mMixerFormat);
}
numFrames -= b.frameCount;
// 释放缓存
t->bufferProvider->releaseBuffer(&b);
}
}用它的getNextBuffer获得可读数据缓冲,混音处理把数据复制给out缓冲,最后调用releaseBuffer释放缓存
xref: /frameworks/av/services/audioflinger/Tracks.cpp
status_t AudioFlinger::PlaybackThread::Track::getNextBuffer(AudioBufferProvider::Buffer* buffer)
{
ServerProxy::Buffer buf;
size_t desiredFrames = buffer->frameCount;
buf.mFrameCount = desiredFrames;
// 获取缓存
status_t status = mServerProxy->obtainBuffer(&buf);
buffer->frameCount = buf.mFrameCount;
buffer->raw = buf.mRaw;
if (buf.mFrameCount == 0 && !isStopping() && !isStopped() && !isPaused()) {
ALOGV("%s(%d): underrun, framesReady(%zu) < framesDesired(%zd), state: %d",
__func__, mId, buf.mFrameCount, desiredFrames, mState);
mAudioTrackServerProxy->tallyUnderrunFrames(desiredFrames);
} else {
mAudioTrackServerProxy->tallyUnderrunFrames(0);
}
return status;
}调用mServerProxy的obtainBuffer获取缓存
xref: /frameworks/av/media/libaudioclient/AudioTrackShared.cpp
status_t ServerProxy::obtainBuffer(Buffer* buffer, bool ackFlush)
{
{
audio_track_cblk_t* cblk = mCblk;
int32_t front; // 读指针
int32_t rear; // 写指针
// See notes on barriers at ClientProxy::obtainBuffer()
if (mIsOut) {
flushBufferIfNeeded(); // might modify mFront
rear = getRear();
front = cblk->u.mStreaming.mFront;
} else {
front = android_atomic_acquire_load(&cblk->u.mStreaming.mFront);
rear = cblk->u.mStreaming.mRear;
}
// 计算已经填充的buffer大小
ssize_t filled = audio_utils::safe_sub_overflow(rear, front);
// pipe should not already be overfull
if (!(0 <= filled && (size_t) filled <= mFrameCount)) {
ALOGE("Shared memory control block is corrupt (filled=%zd, mFrameCount=%zu); shutting down",
filled, mFrameCount);
mIsShutdown = true;
}
if (mIsShutdown) {
goto no_init;
}
// don't allow filling pipe beyond the nominal size
size_t availToServer;
if (mIsOut) {
availToServer = filled;
mAvailToClient = mFrameCount - filled;
} else {
availToServer = mFrameCount - filled;
mAvailToClient = filled;
}
// 'availToServer' may be non-contiguous, so return only the first contiguous chunk
size_t part1;
if (mIsOut) {
front &= mFrameCountP2 - 1;
part1 = mFrameCountP2 - front;
} else {
rear &= mFrameCountP2 - 1;
part1 = mFrameCountP2 - rear;
}
if (part1 > availToServer) {
part1 = availToServer;
}
size_t ask = buffer->mFrameCount;
if (part1 > ask) {
part1 = ask;
}
// is assignment redundant in some cases?
buffer->mFrameCount = part1;
buffer->mRaw = part1 > 0 ?
&((char *) mBuffers)[(mIsOut ? front : rear) * mFrameSize] : NULL;
buffer->mNonContig = availToServer - part1;
// After flush(), allow releaseBuffer() on a previously obtained buffer;
// see "Acknowledge any pending flush()" in audioflinger/Tracks.cpp.
if (!ackFlush) {
mUnreleased = part1;
}
return part1 > 0 ? NO_ERROR : WOULD_BLOCK;
}
no_init:
buffer->mFrameCount = 0;
buffer->mRaw = NULL;
buffer->mNonContig = 0;
mUnreleased = 0;
return NO_INIT;
}3.数据同步
MODE_STREAM模式 会使用到环形缓存区来同步数据,一个生产数据,一个消费数据,这个时候使用环形缓冲区是最可靠的。音频流数据分为两个部分数据头 和数据本身,如下所示:
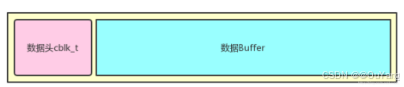
关键变量:mFront(读指针R),mRear(写指针W),mFrameCount(数据长度LEN)
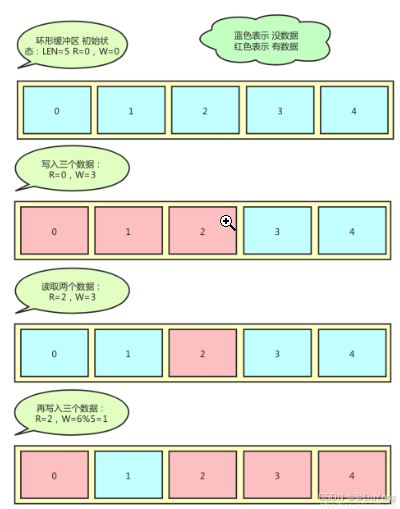
环形缓冲区的逻辑处理如下:
环形缓冲区:初始R=0,W=0,buf长度为LEN
写入一个数据流程:w=W%LEN ; buf[w] = data ; W++ ;
读取一个数据流程:r=R%LEN ; buf[r] = data ; R++;
判断 环形缓冲区为空:R==W
判断 满:W-R == LEN